トレーディングにおける機械学習:理論、モデル、実践、アルゴトレーディング - ページ 3009 1...300230033004300530063007300830093010301130123013301430153016...3399 新しいコメント Forester 2023.04.09 12:39 #30081 СанСаныч Фоменко #: しかし最も重要なことは、利用可能な特徴の予測力が将来も変わらないか、あるいは弱く変化するという理論的な 証明がなければならない。スチームローラー全体において、これが最も重要なことである。 そうでなければ、彼はここにいるのではなく、熱帯の島々にいるはずだ。) 予測能力の安定性は「教師-特性」のペアの特性です。 予測能力の安定性は「教師-特性」ペアの特性である。 サンサニッチ・フォメンコ#: 1.分類誤差が20%以下の教師-特性のペアを持っている人はいますか? 簡単です。何十ものデータセットを生成することができます。今ちょうどTP=50とSL=500について調べているところだ。教師のマークアップには平均10%の誤差がある。20%ならプラマイモデルでしょう。 だからポイントは分類の誤差ではなく、すべての損益を足した結果にある。 ご覧の通り、トップモデルの誤差は9.1%で、8.3%の誤差でもそこそこ稼げます。 チャートはOOSのみを示しています。Walking Forwardで週に1回再トレーニングを行い、5年間で合計264回の再トレーニングを行った結果です。 分類誤差9.1%で、50/500=0.1、つまり10%のはずのモデルが0で機能したのは興味深いことです。1%はスプレッド(バーごとの最小値。) mytarmailS 2023.04.09 13:10 #30082 まず、モデルの内部がゴミだらけであることに気づかなければならない......。 訓練された木製のモデルを、中のルールとそのルールの統計に分解すると のようにする: len freq err condition pred 315 3 0.002 0.417 X[,1]>7.49999999999362e-05 & X[,2]<=-0.00026499999999996 & X[,4]<=0.000495000000000023 1 483 3 0.000 0.000 X[,1]<=0.000329999999999941 & X[,8]>0.000724999999999976 & X[,9]>0.000685000000000047 1 484 3 0.002 0.273 X[,1]>0.000329999999999941 & X[,8]>0.000724999999999976 & X[,9]>0.000685000000000047 -1 555 3 0.001 0.333 X[,5]<=0.000329999999999941 & X[,7]>0.000309999999999921 & X[,8]<=-0.000144999999999951 -1 687 3 0.001 0.250 X[,2]<=-0.00348499999999996 & X[,7]<=-0.000854999999999939 & X[,9]<=-4.99999999999945e-05 1 734 3 0.003 0.000 X[,7]>-0.000854999999999939 & X[,8]>0.000724999999999865 & X[,9]<=0.000214999999999965 1 1045 3 0.003 0.231 X[,1]<=-0.000310000000000032 & X[,4]>0.000105000000000022 & X[,4]<=0.000164999999999971 -1 1708 3 0.000 0.000 X[,3]>0.00102499999999994 & X[,6]<=0.000105000000000022 & X[,7]<=-0.000650000000000039 1 1709 3 0.002 0.250 X[,3]>0.00102499999999994 & X[,6]<=0.000105000000000022 & X[,7]>-0.000650000000000039 -1 1984 3 0.001 0.000 X[,1]<=0.000329999999999941 & X[,8]>0.000724999999999976 & X[,9]>0.000674999999999981 1 2654 3 0.003 0.000 X[,4]<=0.00205000000000011 & X[,5]>0.0014550000000001 & X[,9]<=0.00132999999999994 1 2655 3 0.000 0.000 X[,4]<=0.00205000000000011 & X[,5]>0.0014550000000001 & X[,9]>0.00132999999999994 -1 2656 3 0.001 0.200 X[,3]<=0.00245499999999998 & X[,4]>0.00205000000000011 & X[,5]>0.0014550000000001 -1 2657 3 0.000 0.000 X[,3]>0.00245499999999998 & X[,4]>0.00205000000000011 & X[,5]>0.0014550000000001 1 2852 3 0.000 0.000 X[,2]<=-0.001135 & X[,8]>-0.000130000000000075 & X[,8]>0.00128499999999998 -1 2979 3 0.001 0.200 X[,1]>0.000930000000000097 & X[,1]>0.00129000000000012 & X[,8]<=-0.000275000000000025 -1 のように、ルール errの 誤差の出現頻度依存性を分析します。 となります。 、関数の関数の ルールは非常によく機能するが、そのようなルールは非常にまれで、それに関する統計の信憑性を疑うことに意味がある。 Maxim Dmitrievsky 2023.04.09 13:14 #30083 mytarmailS #:まず、その模型の内部がゴミだらけであることに気づかなければならない......。訓練された木製のモデルを、中にあるルールとそのルールの統計に分解すると。のようなものだ:そして、ルール errの 誤差のサンプル中の出現頻度freqへの 依存性を分析する。次のようになる。 最近の投稿の暗闇に一筋の光が差し込んだようだ。モデルの誤差を適切に解析すれば、面白いものが見つかる。我々は非常に迅速かつ任意のgpu、smsと登録なしで受け入れます。 mytarmailS 2023.04.09 13:22 #30084 Maxim Dmitrievsky #: 最近の記事の暗闇に一筋の光を モデルエラーをきちんと解析すれば、面白いものが見つかる。gpu、sms、登録なしで非常に迅速に受け付けます。 もしあれば、それについての記事があるでしょう。 Maxim Dmitrievsky 2023.04.09 13:33 #30085 mytarmailS #:もしあれば、それについての記事があるだろう。 ノーム、前回の記事も同じような内容だったよ。でも、あなたのやり方がより速いなら、それはプラスだよ。 mytarmailS 2023.04.09 14:02 #30086 Maxim Dmitrievsky #: ノーム、前回の記事も同じような内容だった。でも、あなたのやり方がより速いのなら、それはプラスだよ。 どういう意味ですか? Maxim Dmitrievsky 2023.04.09 14:28 #30087 mytarmailS #:より速くというのは? スピードという意味で。 mytarmailS 2023.04.09 14:41 #30088 Maxim Dmitrievsky #: スピードに関しては 5kmで約5~15秒 Maxim Dmitrievsky 2023.04.09 14:44 #30089 mytarmailS #:5キロのサンプルで約5~15秒。 つまり、最初からTCを取得するまでの全プロセスです。 2つのモデルを何度も再トレーニングしているので、とても速いとは言えませんが、許容範囲です。 そして最後には、何が除外されたのか正確にはわかりません。 mytarmailS 2023.04.09 14:51 #30090 Maxim Dmitrievsky #:つまり、最初からTCを獲得するまでの全過程だ。2つのモデルを何度も再トレーニングしているので、あまり速くはないが、許容範囲だ。最終的に、何を選別したのかはわからない。 5kのトレーニング。 60kを検証。 モデルのトレーニング - 1-3秒 ルール抽出 - 5-10秒 各ルール(2~3万ルール)の妥当性チェック 60k 1-2 分 もちろん全ては概算であり、特徴量とデータ数に依存する。 1...300230033004300530063007300830093010301130123013301430153016...3399 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
しかし最も重要なことは、利用可能な特徴の予測力が将来も変わらないか、あるいは弱く変化するという理論的な 証明がなければならない。スチームローラー全体において、これが最も重要なことである。
そうでなければ、彼はここにいるのではなく、熱帯の島々にいるはずだ。)
予測能力の安定性は「教師-特性」ペアの特性である。
1.分類誤差が20%以下の教師-特性のペアを持っている人はいますか?
簡単です。何十ものデータセットを生成することができます。今ちょうどTP=50とSL=500について調べているところだ。教師のマークアップには平均10%の誤差がある。20%ならプラマイモデルでしょう。
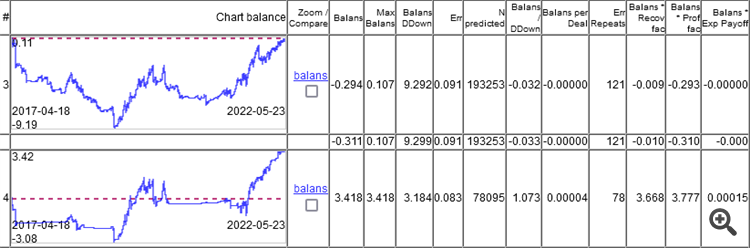
だからポイントは分類の誤差ではなく、すべての損益を足した結果にある。
ご覧の通り、トップモデルの誤差は9.1%で、8.3%の誤差でもそこそこ稼げます。
チャートはOOSのみを示しています。Walking Forwardで週に1回再トレーニングを行い、5年間で合計264回の再トレーニングを行った結果です。
分類誤差9.1%で、50/500=0.1、つまり10%のはずのモデルが0で機能したのは興味深いことです。1%はスプレッド(バーごとの最小値。)
まず、モデルの内部がゴミだらけであることに気づかなければならない......。
訓練された木製のモデルを、中のルールとそのルールの統計に分解すると
のようにする:
のように、ルール errの 誤差の出現頻度依存性を分析します。
となります。
、関数の関数の
ルールは非常によく機能するが、そのようなルールは非常にまれで、それに関する統計の信憑性を疑うことに意味がある。
まず、その模型の内部がゴミだらけであることに気づかなければならない......。
訓練された木製のモデルを、中にあるルールとそのルールの統計に分解すると。
のようなものだ:
そして、ルール errの 誤差のサンプル中の出現頻度freqへの 依存性を分析する。
次のようになる。
最近の記事の暗闇に一筋の光を
もしあれば、それについての記事があるでしょう。
もしあれば、それについての記事があるだろう。
ノーム、前回の記事も同じような内容だった。でも、あなたのやり方がより速いのなら、それはプラスだよ。
どういう意味ですか?
より速くというのは?
スピードに関しては
5kmで約5~15秒
5キロのサンプルで約5~15秒。
つまり、最初からTCを取得するまでの全プロセスです。
2つのモデルを何度も再トレーニングしているので、とても速いとは言えませんが、許容範囲です。
そして最後には、何が除外されたのか正確にはわかりません。
つまり、最初からTCを獲得するまでの全過程だ。
2つのモデルを何度も再トレーニングしているので、あまり速くはないが、許容範囲だ。
最終的に、何を選別したのかはわからない。
5kのトレーニング。
60kを検証。
モデルのトレーニング - 1-3秒
ルール抽出 - 5-10秒
各ルール(2~3万ルール)の妥当性チェック 60k 1-2 分
もちろん全ては概算であり、特徴量とデータ数に依存する。