トレーディングにおける機械学習:理論、モデル、実践、アルゴトレーディング - ページ 27 1...202122232425262728293031323334...3399 新しいコメント Alexey Burnakov 2016.06.29 10:10 #261 mytarmailS:こんにちは。アイデアはある、調べたい、でも実装するためのツールがわからない...。数ポイント先、例えば3や5を予測できるアルゴリズムが必要だ(できればニューラルネットワークが望ましい) アリマ СанСаныч Фоменко 2016.06.29 11:00 #262 mytarmailS:こんにちは。アイデアはある、調べたい、でも実装するためのツールがわからない...。数ポイント先、例えば3ポイントや5ポイント先まで予測できるようなアルゴリズムが必要です(できればニューラルネットワークが望ましい)。私は分類の仕事しかしたことがないので、それがどのように見えるべきかを理解することも、誰かにそれを行う方法を助言することも、Rのパッケージを推奨することもできません。p.s. Alexeyの素晴らしい記事 これらは、既存の傾向を外挿するパッケージで、例えば、予測などです。スプラインの違いがとても興味深いです。 Alexey Burnakov 2016.06.29 11:49 #263 サンサニッチ・フォメンコ 予測など、既存の傾向を外挿するパッケージです。スプラインの違いがとても興味深いです。 これはより正しい答えです )いろいろな方法を試してみるべきでしょう。 Dr. Trader 2016.06.29 12:25 #264 サンサニッチ・フォメンコかなりしっかりしているように見えます。では、役に立つ結果はないのか?最初に少量の初期データでアルゴリズムを実行したときは、肯定的な結果が出ず、y-aware pcaとsimple pcaの両方で50%程度の誤差が出ました。現在、mt5からより完全なデータセットを入手しました。ほとんどすべての標準的な指標とそのすべてのバッファ、いくつかの指標は異なるパラメータで数回繰り返されています。私はいくつかの指標に対してExpert Advisorを作成し、より収益性の高い取引のために指標のパラメータを最適化するために使用しています。このようなデータでは、単純なpcaではまだ50%の誤差があるが、yを考慮したfronttestでは40%まで顕著に誤差が減少している。y-awareアルゴリズムは、生データを取得するだけで、10件中6件が正しく動作する分類器を作ることができるのが面白いですね。結論 - もっと生データが必要だ。しかし、いいところはここで止まってしまいます。95%の精度を得るためには73個の標準部品が必要です。成分における予測変数の負荷量は、高いものから低いものへと変動しており、明確なリーダーを持たない。つまり、ある予測因子を選択するための指標が全くないのである。モデルはどうにか動くが、結果を改善するために何をすべきか、予測器の効用をどう引き出すかは不明である。部品の重要性最初の5つの成分の予測変数の負荷量。 mytarmailS 2016.06.29 13:13 #265 アレクセイ・ブルナコフ アリマ しかし、arimaは時系列に基づいて決定を下すので、私のデータセット、つまり述語を持つ行列に対して決定を下し、数本先の出力を予測するモデルが必要です。 mytarmailS 2016.06.29 13:20 #266 Dr.トレーダー- あなたの粘り強さには心から敬意を表しますが、私の考えでは、これは行き止まりで、量より質に向かう必要があります。 Alexey Burnakov 2016.06.29 13:22 #267 mytarmailS: しかし、arimaは時系列で判断するので、私のデータセット、つまり述語を持つ行列から判断し、数バー先の予測を出力するモデルが必要です。 複数の出力ニューロンを持つニューロネットを、それぞれが異なる計画地平に対応するように訓練することを妨げるものはいない。同時に、その結果を観察するのも面白いでしょう。 mytarmailS 2016.06.29 13:35 #268 アレクセイ・ブルナコフ 複数の出力ニューロンを持つニューラルネットワークを、それぞれが異なる計画地平に対応するように訓練することは、誰にも妨げられない。同時に、その結果を観察するのも面白いでしょう。 私はすでにそれをしました、ニューラルネットワークは、私がそれを設定したターゲットでより大きな地平線上で学習しない СанСаныч Фоменко 2016.06.29 13:41 #269 Dr.トレーダー最初に少量の初期データでアルゴリズムを実行したときは、肯定的な結果が出ず、y-aware pcaとsimple pcaの両方で50%程度の誤差が出ました。現在、mt5からより完全なデータセットを入手しました。ほとんどすべての標準的な指標とそのすべてのバッファ、いくつかの指標は異なるパラメータで数回繰り返されています。私はいくつかの指標に対してExpert Advisorを作成し、より収益性の高い取引のために指標のパラメータを最適化するために使用しています。このようなデータでは、単純なpcaではまだ50%の誤差があるが、yを考慮したfronttestでは40%まで顕著に誤差が減少している。y-awareアルゴリズムは、生データを取得するだけで、10件中6件が正しく動作する分類器を作ることができるのが面白いですね。結論 - もっと生データが必要だ。しかし、いいところはここで止まってしまいます。95%の精度を得るためには73個の標準部品が必要です。成分における予測変数の負荷量は、高いものから低いものへと変動しており、明確なリーダーを持たない。つまり、ある予測因子を選択するための指標が全くないのである。モデルはどうにか動くが、結果を改善するために何をすべきか、予測器の効用をどう引き出すかは不明である。コンポーネントの重要性最初の5成分に対する予測因子の負荷量。 最初の10個(のようなもの)を一段上げて、残りを捨てたらどうでしょう? СанСаныч Фоменко 2016.06.29 13:44 #270 mytarmailS: すでにそうなっています。ニューラルネットワークは、私が設定したターゲットでは、より大きな地平で学習しません。学習しないのはいいことだ、ノイズで学習しているのだから。でも、もしそうなら、それは聖杯で、本物についているはず...。ノイズを排除するために、ここは忙しい。だからこそ、何かが残ることを期待して、多くの予測物質を摂取するのです。 1...202122232425262728293031323334...3399 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
こんにちは。
アイデアはある、調べたい、でも実装するためのツールがわからない...。数ポイント先、例えば3や5を予測できるアルゴリズムが必要だ(できればニューラルネットワークが望ましい)
こんにちは。
アイデアはある、調べたい、でも実装するためのツールがわからない...。数ポイント先、例えば3ポイントや5ポイント先まで予測できるようなアルゴリズムが必要です(できればニューラルネットワークが望ましい)。
私は分類の仕事しかしたことがないので、それがどのように見えるべきかを理解することも、誰かにそれを行う方法を助言することも、Rのパッケージを推奨することもできません。
p.s. Alexeyの素晴らしい記事
予測など、既存の傾向を外挿するパッケージです。スプラインの違いがとても興味深いです。
かなりしっかりしているように見えます。
では、役に立つ結果はないのか?
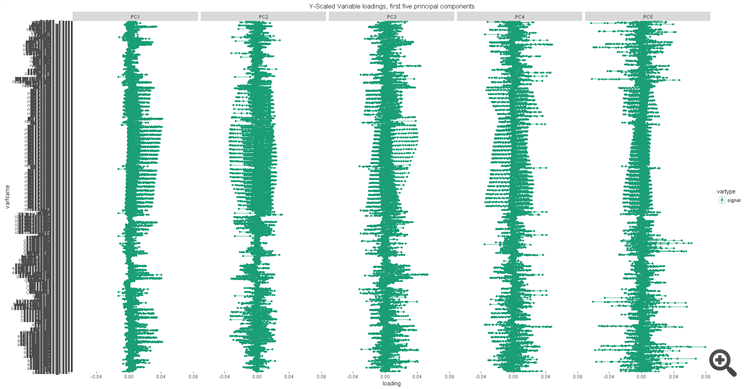
最初に少量の初期データでアルゴリズムを実行したときは、肯定的な結果が出ず、y-aware pcaとsimple pcaの両方で50%程度の誤差が出ました。現在、mt5からより完全なデータセットを入手しました。ほとんどすべての標準的な指標とそのすべてのバッファ、いくつかの指標は異なるパラメータで数回繰り返されています。私はいくつかの指標に対してExpert Advisorを作成し、より収益性の高い取引のために指標のパラメータを最適化するために使用しています。このようなデータでは、単純なpcaではまだ50%の誤差があるが、yを考慮したfronttestでは40%まで顕著に誤差が減少している。y-awareアルゴリズムは、生データを取得するだけで、10件中6件が正しく動作する分類器を作ることができるのが面白いですね。結論 - もっと生データが必要だ。
しかし、いいところはここで止まってしまいます。95%の精度を得るためには73個の標準部品が必要です。成分における予測変数の負荷量は、高いものから低いものへと変動しており、明確なリーダーを持たない。つまり、ある予測因子を選択するための指標が全くないのである。モデルはどうにか動くが、結果を改善するために何をすべきか、予測器の効用をどう引き出すかは不明である。
部品の重要性
最初の5つの成分の予測変数の負荷量。
アリマ
しかし、arimaは時系列で判断するので、私のデータセット、つまり述語を持つ行列から判断し、数バー先の予測を出力するモデルが必要です。
複数の出力ニューロンを持つニューラルネットワークを、それぞれが異なる計画地平に対応するように訓練することは、誰にも妨げられない。同時に、その結果を観察するのも面白いでしょう。
最初に少量の初期データでアルゴリズムを実行したときは、肯定的な結果が出ず、y-aware pcaとsimple pcaの両方で50%程度の誤差が出ました。現在、mt5からより完全なデータセットを入手しました。ほとんどすべての標準的な指標とそのすべてのバッファ、いくつかの指標は異なるパラメータで数回繰り返されています。私はいくつかの指標に対してExpert Advisorを作成し、より収益性の高い取引のために指標のパラメータを最適化するために使用しています。このようなデータでは、単純なpcaではまだ50%の誤差があるが、yを考慮したfronttestでは40%まで顕著に誤差が減少している。y-awareアルゴリズムは、生データを取得するだけで、10件中6件が正しく動作する分類器を作ることができるのが面白いですね。結論 - もっと生データが必要だ。
しかし、いいところはここで止まってしまいます。95%の精度を得るためには73個の標準部品が必要です。成分における予測変数の負荷量は、高いものから低いものへと変動しており、明確なリーダーを持たない。つまり、ある予測因子を選択するための指標が全くないのである。モデルはどうにか動くが、結果を改善するために何をすべきか、予測器の効用をどう引き出すかは不明である。
コンポーネントの重要性
最初の5成分に対する予測因子の負荷量。
すでにそうなっています。ニューラルネットワークは、私が設定したターゲットでは、より大きな地平で学習しません。
学習しないのはいいことだ、ノイズで学習しているのだから。でも、もしそうなら、それは聖杯で、本物についているはず...。
ノイズを排除するために、ここは忙しい。だからこそ、何かが残ることを期待して、多くの予測物質を摂取するのです。