トレーディングにおける機械学習:理論、モデル、実践、アルゴトレーディング - ページ 1929 1...192219231924192519261927192819291930193119321933193419351936...3399 新しいコメント Vladimir Perervenko 2020.07.28 17:47 #19281 mytarmailS: こじんごっこ御意プレーン版ご覧の通り、値がかなり異なっていますので、ご自身で確認してみてください。私のモデルではということで、1列だけですが、特に問題ではありません。===================UPD umap_tranformを 実行するたびに、それらは異なるはずです。 注意してなかった。お久しぶりです...。 Forester 2020.07.28 18:50 #19282 mytarmailS: こじんごっこ御意プレーン版ご覧の通り、値がかなり異なっていますので、ご自身で確認してみてください。私のモデルではということで、1列だけですが、特に問題ではありません。===================UPD男、 umap_tranform を実行するたびに異なる、このようなことはないはずです。 通常、(内蔵RNGの)Seedは、再現性のためにある値に設定されています。そうでない場合は、ランダムが使用されます。このパッケージにもSeedがあるかもしれませんので、確認してみてください。 mytarmailS 2020.07.28 19:10 #19283 elibrarius: 通常、再現性を高めるためには、(内蔵のHSSの)Seedをある値に設定します。そうでない場合は、ランダムが使用されます。このパッケージにもSeedがあるかもしれませんので、確認してみてください。 私はそう思いますが、ポイントは、RMSがなければ常に同じであるべきで、「umap」アナログパッケージでは、結果は常に同じであるということです。 mytarmailS 2020.07.28 19:16 #19284 アレクセイ・ヴャジミキンを学んでほしいという一心で、あなたのために、R-ku)install.packages("TTR","uwot") clos <- d$X.CLOSE. get.ind <- function(x,n=5){ all_to.all_colums <- function(x,names){ cb <- combn(ncol(x),2) res <- matrix(ncol = 0,nrow = nrow(x)) for(i in 1:ncol(cb)){ j1 <- cb[1,i] j2 <- cb[2,i] res <- cbind(res, x[,j1] - x[,j2] ) colnames(res) <- paste0(names, 1:ncol(res)) } return(res)} library(TTR) aroon <- aroon(x,n) BBands <- BBands(x,n) ; BBands <- all_to.all_colums( BBands, names = "BBands") CCI <- CCI(x,n) CMO <- CMO(x,n) DEMA <- diff(c(0,DEMA(x,n))) Donchian <- DonchianChannel(x,n) ; Donchian <- all_to.all_colums( Donchian, names = "Donchian") MACD <- MACD(x,n) moment <- momentum(x,n) PBands <- PBands(x,n) ; PBands <- all_to.all_colums( PBands, names = "PBands") RSI <- RSI(x,n) SAR <- diff(c(0,SAR(cbind(x,x,n)))) SMA <- diff(c(0,SMA(x,n))) stoch <- stoch(x,n) TDI <- TDI(x,n) VHF <- VHF(x,n) WPR <- WPR(x,n) ind <- cbind.data.frame(aroon,BBands,CCI,CMO,DEMA,Donchian, MACD,moment,PBands, RSI,SAR,SMA,stoch,TDI,VHF,WPR) return(ind) } get.target <- function(x, change){ zz <- TTR::ZigZag(x,change = change,percent = F) zz <- c(diff(zz),0) ; zz[zz>=0] <- 1 ; zz[zz<0] <- -1 return(zz) } X <- get.ind(clos) Y <- as.factor(get.target(clos,change = 0.001)) library(uwot) train.idx <- 100:8000 test.idx <- 8001:10000 UM <- umap(X = X[train.idx,], y = Y[train.idx], approx_pow = TRUE, n_components = 3, ret_model = TRUE, n_threads = 4 L, scale = T) predict.train <- umap_transform(X = X[train.idx,], model = UM, n_threads = 4 L, verbose = TRUE) predict.test <- umap_transform(X = X[test.idx,], model = UM, n_threads = 4 L, verbose = TRUE) library(car) scatter3d(x = predict.train[,1], y = predict.train[,2], z = predict.train[,3], groups = Y[train.idx], grid = F, surface = F, ellipsoid = F, bg.col = "black",surface.col = c(2,3)) という2つの関数があります。get.indиget.target1つ目の指標は日付のセットを作成し、2つ目の指標はジグザグのターゲットを作成します。終値が 10kのデータをロードして、変数closeに 書き込むだけです。でumapを取得し、ターゲット https://github.com/jlmelville/uwot Aleksey Vyazmikin 2020.07.28 20:51 #19285 mytarmailS: を学んでほしいという一心で、あなたのために。)にりつはいはんやи1つ目の指標は日付のセットを作成し、2つ目の指標はジグザグのターゲットを作成します。終値が 10kのデータをロードして、変数closeに 書き込むだけです。でumapを取得し、ターゲット https://github.com/jlmelville/uwot お会いできてとてもうれしいです、ありがとうございます もっとコメントが欲しいです :) ここで問題になるのは、ファイルからの予測値と結果のターゲットをどのように同期させるかです。 mytarmailS 2020.07.28 20:59 #19286 Aleksey Vyazmikin: はじめまして、ありがとうございます。もっとコメントが欲しいです :)ここで問題になるのは、ファイルからターゲットに予測値を同期させる方法です。 ターゲットは価格を使って構築されているので、すでに同期しており、同じシーンを使ってプレディクターが構築されていれば、それも同期しているということです) あるいは、質問の意味がわからない。 コメントなしで理解できるような変数名にしてみました fxsaber 2020.07.28 21:10 #19287 オタクからの質問です。 3つの変数A,B,Cがあります。何らかの条件が彼らから手書きで書かれている。例えば、こんな感じです。 (A > B) && (A - B < C) && (A + 3 * C > 2 * B) この状態を自動的に再現したい。探すまでもなく、すでに知っているのだから。しかし、例えば、A,B,Cをそこに設定し(多項式かHCか-私はゼロを知っているのでわからない)、元の条件を得るとき、この条件を高い確率でヒットさせる組み合わせの重み係数が数十個必要である。 そのような原状を重みを介して再現するために、求められる関数はどのような入力重みをいくつ持っているのかに興味があるのですが? Aleksey Vyazmikin 2020.07.28 21:25 #19288 そこで、クラスタにどのように木を学習させたか、その方法をお伝えし、お見せします。 その結果、以下のようなクラス認識モデルが得られた。 ヒストリーの精度は0.9196756とかなり高く、クラスタのロジックはかなり再現性が高い。 そして、各クラスタに対してモデルを学習させました クラスター1 クラスター2 クラスター3 クラスター4 すべてのクラスターでAccuracyが0.53程度となっています。 そして、クラスターに分割していない状態のモデルはこんな感じです。 精度0.5293815はクラスタとほぼ同じです。 クラスタのモデルと1本の木のモデルを全標本で比較すると、クラスタの木はターゲット1や-1の一般化されたサンプル情報を持つ葉が多く、理論的にも良いことがわかる。 テストの結果を見てみよう - まずはトレーニング期間を見てみよう クラスタ分割を行わないモデル。 クラスタに分割されたモデル。 クラスタリングなしのモデルの方が精度が高いが、クラスタ上のモデルの方が取引量が多く、より良い財務パフォーマンスを実現できることがわかる。 では、トレーニング以外のサンプルも見てみましょう。 そして、これが私たちのクラスターです。 そして、クラスターを使用しないモデル。 4月以降に相場が乱高下したときに、多くのトレードが不利に働いたということです。 クラスターがなかったら、クラスター・モデルの葉を個別に、降順ヒストグラムで見てみることにしました。 合計6つの不採算リーフ(ターゲット削除ゼロ-エントリー禁止です)で、正しいクラスタにいないことが判明? Aleksey Vyazmikin 2020.07.28 21:29 #19289 mytarmailS: まあ、ターゲットは価格に基づいているので、すでに同期していますし、プレディクターが同じシーンに基づいていれば、プレディクターも同じです)あるいは、質問の意味がわからない。コメントなしで理解できるような変数名にしてみました 予測値と終値を 持つデータセットを取得し、Rの指標生成のバリアントを使用する代わりに終値の列の仕様でロードするにはどうすればよいですか? 私の理解では,ターゲットがZZトップスなので,予測変数のあるサンプルの一部がフィルタリングされるはずで,ここで,予測変数をフィードするために,予測変数のあるテーブルもフィルタリングする必要がある,というか? Maxim Dmitrievsky 2020.07.28 21:45 #19290 fxsaber: オタクからの質問です。3つの変数A,B,Cがあります。何らかの条件が彼らから手書きで書かれている。例えば、こんな感じです。この状態を自動的に再現したい。探すまでもなく、すでに知っているのだから。しかし、例えば、A,B,Cをそこに設定し(多項式かHCか-私はゼロを知っているのでわからない)、元の条件を得るとき、この条件を高い確率でヒットさせる組み合わせの重み係数が数十個必要である。そのような原状を重みを介して再現するために、求められる関数はどのような入力重みをいくつ持っているのかに興味があるのですが?かわりに(A > B) && (A - B < C) && (A + 3 * C > 2 * B)NSの入力は値A,B,Cをn回(1000とする)、出力はこれらの値を0;1として計算した式の答えである。試してみてください。そして、分類の誤差と、モデルがどの程度状態を再現しているかを見てください。種類を正確に見て解釈するならば、木を通して行うことができます。 バリエーション2(最初のものがうまくいかなかった場合) - A, B, A-B, C, A+3*C, 2B - 変数、すべて最初のバリエーションと同じようにツリーに入れる。そして、上のアレクセイの写真のように、その構造を見ることができます。 1...192219231924192519261927192819291930193119321933193419351936...3399 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
こじんごっこ
御意
プレーン版
ご覧の通り、値がかなり異なっていますので、ご自身で確認してみてください。
私のモデルでは
ということで、1列だけですが、特に問題ではありません。
===================UPD
umap_tranformを 実行するたびに、それらは異なるはずです。
注意してなかった。お久しぶりです...。
こじんごっこ
御意
プレーン版
ご覧の通り、値がかなり異なっていますので、ご自身で確認してみてください。
私のモデルでは
ということで、1列だけですが、特に問題ではありません。
===================UPD
男、 umap_tranform を実行するたびに異なる、このようなことはないはずです。
通常、再現性を高めるためには、(内蔵のHSSの)Seedをある値に設定します。そうでない場合は、ランダムが使用されます。このパッケージにもSeedがあるかもしれませんので、確認してみてください。
私はそう思いますが、ポイントは、RMSがなければ常に同じであるべきで、「umap」アナログパッケージでは、結果は常に同じであるということです。
を学んでほしいという一心で、あなたのために、R-ku)
という2つの関数があります。
get.indи
get.target1つ目の指標は日付のセットを作成し、2つ目の指標はジグザグのターゲットを作成します。
終値が 10kのデータをロードして、変数closeに 書き込むだけです。
でumapを取得し、ターゲット
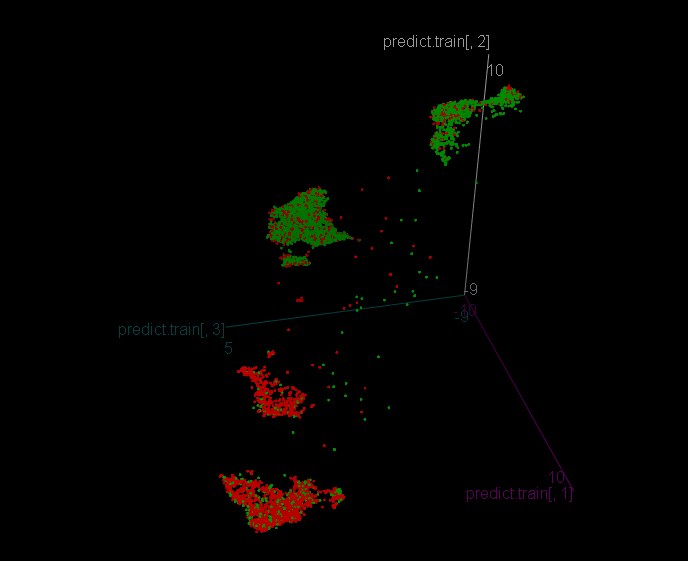
https://github.com/jlmelville/uwotを学んでほしいという一心で、あなたのために。)
にりつはいはんや
и
1つ目の指標は日付のセットを作成し、2つ目の指標はジグザグのターゲットを作成します。
終値が 10kのデータをロードして、変数closeに 書き込むだけです。
でumapを取得し、ターゲット
https://github.com/jlmelville/uwotお会いできてとてもうれしいです、ありがとうございます
もっとコメントが欲しいです :)
ここで問題になるのは、ファイルからの予測値と結果のターゲットをどのように同期させるかです。
はじめまして、ありがとうございます。
もっとコメントが欲しいです :)
ここで問題になるのは、ファイルからターゲットに予測値を同期させる方法です。
ターゲットは価格を使って構築されているので、すでに同期しており、同じシーンを使ってプレディクターが構築されていれば、それも同期しているということです)
あるいは、質問の意味がわからない。
コメントなしで理解できるような変数名にしてみました
オタクからの質問です。
3つの変数A,B,Cがあります。何らかの条件が彼らから手書きで書かれている。例えば、こんな感じです。
この状態を自動的に再現したい。探すまでもなく、すでに知っているのだから。しかし、例えば、A,B,Cをそこに設定し(多項式かHCか-私はゼロを知っているのでわからない)、元の条件を得るとき、この条件を高い確率でヒットさせる組み合わせの重み係数が数十個必要である。
そのような原状を重みを介して再現するために、求められる関数はどのような入力重みをいくつ持っているのかに興味があるのですが?
そこで、クラスタにどのように木を学習させたか、その方法をお伝えし、お見せします。
その結果、以下のようなクラス認識モデルが得られた。
ヒストリーの精度は0.9196756とかなり高く、クラスタのロジックはかなり再現性が高い。
そして、各クラスタに対してモデルを学習させました
クラスター1
クラスター2
クラスター3
クラスター4
すべてのクラスターでAccuracyが0.53程度となっています。
そして、クラスターに分割していない状態のモデルはこんな感じです。
精度0.5293815はクラスタとほぼ同じです。
クラスタのモデルと1本の木のモデルを全標本で比較すると、クラスタの木はターゲット1や-1の一般化されたサンプル情報を持つ葉が多く、理論的にも良いことがわかる。
テストの結果を見てみよう - まずはトレーニング期間を見てみよう
クラスタ分割を行わないモデル。
クラスタに分割されたモデル。
クラスタリングなしのモデルの方が精度が高いが、クラスタ上のモデルの方が取引量が多く、より良い財務パフォーマンスを実現できることがわかる。
では、トレーニング以外のサンプルも見てみましょう。
そして、これが私たちのクラスターです。
そして、クラスターを使用しないモデル。
4月以降に相場が乱高下したときに、多くのトレードが不利に働いたということです。
クラスターがなかったら、クラスター・モデルの葉を個別に、降順ヒストグラムで見てみることにしました。
合計6つの不採算リーフ(ターゲット削除ゼロ-エントリー禁止です)で、正しいクラスタにいないことが判明?
まあ、ターゲットは価格に基づいているので、すでに同期していますし、プレディクターが同じシーンに基づいていれば、プレディクターも同じです)
あるいは、質問の意味がわからない。
コメントなしで理解できるような変数名にしてみました
予測値と終値を 持つデータセットを取得し、Rの指標生成のバリアントを使用する代わりに終値の列の仕様でロードするにはどうすればよいですか?
私の理解では,ターゲットがZZトップスなので,予測変数のあるサンプルの一部がフィルタリングされるはずで,ここで,予測変数をフィードするために,予測変数のあるテーブルもフィルタリングする必要がある,というか?
オタクからの質問です。
3つの変数A,B,Cがあります。何らかの条件が彼らから手書きで書かれている。例えば、こんな感じです。
この状態を自動的に再現したい。探すまでもなく、すでに知っているのだから。しかし、例えば、A,B,Cをそこに設定し(多項式かHCか-私はゼロを知っているのでわからない)、元の条件を得るとき、この条件を高い確率でヒットさせる組み合わせの重み係数が数十個必要である。
そのような原状を重みを介して再現するために、求められる関数はどのような入力重みをいくつ持っているのかに興味があるのですが?
かわりに
NSの入力は値A,B,Cをn回(1000とする)、出力はこれらの値を0;1として計算した式の答えである。試してみてください。そして、分類の誤差と、モデルがどの程度状態を再現しているかを見てください。
種類を正確に見て解釈するならば、木を通して行うことができます。
バリエーション2(最初のものがうまくいかなかった場合) - A, B, A-B, C, A+3*C, 2B - 変数、すべて最初のバリエーションと同じようにツリーに入れる。そして、上のアレクセイの写真のように、その構造を見ることができます。