Cosa inserire nell'ingresso della rete neurale? Le vostre idee... - pagina 52
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Se si guarda l'immagine, sì, è calda e morbida, ma nel codice va bene.
Le parentesi nell'immagine sono sbagliate. Dovrebbe essere così.
Ola ke tal. Ho pensato di proporre le mie idee.
Il mio ultimo modello consiste nel raccogliere i prezzi normalizzati di 10 simboli e quindi addestrare una rete di ricorrenze. Per l'input 20 barre del mese, della settimana e del giorno.
Questa è l'immagine che ottengo. La differenza rispetto alla formazione separata è che il profitto totale è 3 volte inferiore e il drawdown.... wow, il drawdown nel periodo di controllo è appena dell'1%.
Mi sembra che questo risolva il problema della scarsità di dati.
Ola ke tal. Ho pensato di proporre le mie idee.
Il mio ultimo modello consiste nel raccogliere i prezzi normalizzati di 10 simboli e quindi addestrare una rete di ricorrenze. Ci sono 20 barre del mese, della settimana e del giorno per ogni input.
Questa è l'immagine che ottengo. La differenza rispetto alla formazione separata è che il profitto totale è 3 volte inferiore e il drawdown.... wow, il drawdown nel periodo di controllo è appena dell'1%.
Mi sembra che questo risolva il problema della scarsità di dati.
Penso che lei abbia un livello di conoscenza estremamente elevato dell'argomento.
Temo che non capirò nulla. Per favore, dimmi cos'è questa bellezza sul grafico: è Python?
Un'architettura LSTM? È possibile mostrare una cosa del genere su MT5?
prezzi normalizzati di 10 simboli
Anche qui, come sono stati normalizzati i prezzi. Che cos'è "ante" In generale, tutto ciò che non è un segreto commerciale, per favore condividetelo)
Penso che lei abbia un livello di padronanza estremamente elevato dell'argomento.
Temo che non capirò nulla. Per favore, dimmi cos'è questa bellezza sul grafico: è Python?
Un'architettura LSTM? È possibile mostrare una cosa del genere su MT5?
Anche in questo caso, come si normalizzano i prezzi. Cos'è "ante" In generale, tutto ciò che non è un segreto commerciale, per favore condividetelo).
Naturalmente si tratta di python. In µl5 per selezionare i dati in base a una condizione, bisogna fare un'enumerazione e tutto ciò che è iff iff iff iff. In python basta una riga per selezionare i dati in base a qualsiasi condizione. Non sto parlando della velocità del lavoro. È troppo comodo. Mcl5 è necessario per aprire operazioni con una rete già pronta.
La normalizzazione è la più comune. Meno la media, divisa per la deviazione standard. Il segreto commerciale qui è il periodo di normalizzazione, è importante affrontarlo in modo che i prezzi siano intorno allo zero per 10 anni. Ma non in modo che all'inizio dei 10 anni siano sotto lo zero e alla fine siano sopra lo zero. Non è questo il modo di confrontare...
Due periodi di prova - ante e test. L'ante prima del periodo di formazione è di 6 mesi. È molto conveniente. L'ante è sempre lì. E il test è il futuro, non esiste. Cioè, c'è, ma solo nel passato. E nel futuro non c'è. Cioè, non c'è.
Quale pensate sia più importante: l'architettura o i dati di input?
Secondo lei, cosa è più importante: l'architettura o i dati di input?
Penso che i dati in ingresso. Qui sto provando con 6 caratteri, non 10. E non sto superando il periodo di controllo agosto-dicembre 2023. Separatamente, è anche difficile. E il passaggio a 10 caratteri può essere legittimamente scelto in base ai risultati dell'addestramento. La rete è sempre ricorrente in 1 strato di 32 stati, viene utilizzato solo il full-link.
Alcuni riassunti:
Mi sono reso conto che avevo appena trovato un modello algoritmico mentre analizzavo vari dati di input, rispondendo in parte alla domanda del mio ramo: "Cosa dare in ingresso alla rete neurale?". Ma la rete neurale si è rivelata inutile. Né MLP, né RNN, né LSTM, né BiLSTM, né CNN, né Q-learning, né tutte queste combinazioni e miscele.
In uno di questi esperimenti ho ottimizzato 2 ingressi su 3 neuroni. Come risultato, uno dei set superiori ha mostrato la seguente immagine
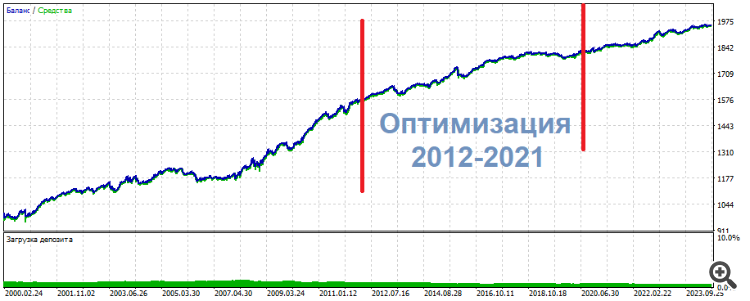
* ******* **************
UPD Ecco un altro set, la stessa cosa: al centro l'ottimizzazione, ai lati i risultati. Quasi lo stesso, solo più uniforme
**********************
I trade non sono pips o scalp. Piuttosto intraday.
Quindi, le mie conclusioni soggettive per il momento attuale:
Non ho mai visto risultati peggiori di quelli ottenuti con gli indicatori di smoothing in vita mia. È come se una persona vedente diventasse cieca. Poco fa vedeva una sagoma chiara e ora non riesce a capire cosa: una macchia negli occhi. Nessuna informazione.
La mia opinione, per come la vedo io
La rete neurale è applicabile solo a modelli statici e stazionari che non hanno nulla a che fare con la determinazione dei prezzi.
Che tipo di pre-elaborazione e normalizzazione fate? Avete provato a standardizzare?
I van Butko #: La rete neurale ricorda il percorso. Non più di questo.
Provate i trasformatori, dicono che facciano bene....
I van Butko #: Gli oscillatori sono il male!
Beh, non tutto è così univoco. È solo che NS è comodo per lavorare con funzioni continue, ma abbiamo bisogno di un'architettura che lavori con funzioni parziali/intervallate, quindi NS sarà in grado di prendere gli intervalli degli oscillatori come informazioni significative.
Che tipo di pre-elaborazione e normalizzazione fate? Avete provato a standardizzare?
Provate i trasformatori, dicono che facciano bene....
Beh, non tutto è così chiaro. È solo che NS è comodo per lavorare con funzioni continue, ma abbiamo bisogno di un'architettura che lavori con funzioni parziali/intervallate, quindi NS sarà in grado di prendere gli intervalli degli oscillatori come informazioni significative.
1. E quando come: se nella finestra dei dati, alcuni incrementi, porto l'intervallo -1..1. Non ho sentito parlare di standardizzazione 2.
Accettato, grazie 3. Sono d'accordo, non ho una prova completa del contrario.
Per questo scrivo dal mio campanile, come vedo e immagino approssimativamente. Il semplice smoothing è una cancellazione di fatto dell'informazione. Non generalizzazione. Cancellazione appunto. Pensate a una fotografia: appena ne degradate il contenuto, l'informazione è irrimediabilmente persa. E ripristinarla con l'intelligenza artificiale è un'impresa artistica, non un vero e proprio restauro. È un ridisegno arbitrario.
"Smoothing: quando un numero è il risultato di due unità informative indipendenti: il pattern -1/1, ad esempio, e il pattern -6/6. Il valore medio di ciascuno sarà lo stesso, ma in origine c'erano due modelli. Possono avere o meno un significato, possono significare segnali opposti.
E qui ci sono mashki, oscillatori e così via: cancellano/ offuscano stupidamente il "quadro" iniziale del mercato. E in questo "imbrattamento" spaventiamo il NS, facendogli cercare all'infinito di lavorare come dovrebbe. La generalizzazione e lo smoothing sono fenomeni eterogenei estremamente ostili.
Alcuni riassunti:
Mi sono reso conto che avevo appena trovato un modello algoritmico mentre analizzavo i vari dati di input, rispondendo in parte alla domanda del mio ramo "Cosa dare in ingresso alla rete neurale?". Ma la rete neurale si è rivelata inutile. Né MLP, né RNN, né LSTM, né BiLSTM, né CNN, né Q-learning, né tutti questi combinati e mescolati.
In uno di questi esperimenti ho ottimizzato 2 ingressi su 3 neuroni. Come risultato, uno dei set superiori ha mostrato la seguente immagine
* ******* **************
UPD Ecco un altro set, la stessa cosa: al centro l'ottimizzazione, ai lati i risultati. Quasi lo stesso, solo più uniforme
**********************
I trade non sono né pips né scalp.
Le mie conclusioni sono soggettive al momento:
Non ho mai visto risultati peggiori di quelli ottenuti con gli indicatori di smoothing in vita mia. È come se una persona vedente diventasse cieca. Poco fa vedeva una sagoma chiara e ora non riesce a capire cosa: una macchia negli occhi. Nessuna informazione.
Il mio imho, per come la vedo io
non è un pifferaio debole.
È il momento di cucire le borse?