C'è uno schema nel caos? Proviamo a trovarlo! Apprendimento automatico sull'esempio di un campione specifico. - pagina 25
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
A TP=SL, sarà circa il 50%. A TP = 2*SL, sarà del 33%, ecc.
Il profitto medio di 1 operazione è sempre molto basso. Circa 0,00005. Ma sarà speso in spread, slippage, swap, che non sono presi in considerazione nel markup dell'insegnante (lo spread è preso in considerazione, ma il minimo per barra, quello reale sarà più alto).
E questo usando TP=SL=0,00400. Cioè con un rischio di 400 otteniamo un profitto di 5 pts, cioè il vantaggio dell'1%.
Vorrei prendere almeno 10 pts dal movimento di 50 pts, ma lì tutte le opzioni sono plum.
Ma questo è tutto con i miei chip e obiettivi. Forse ci sono opzioni migliori.
Questa strategia fornisce il 43% di operazioni redditizie su EURUSD dal 2008 al 2023, con un rapporto TP/SL di 61,8, e il 39% delle operazioni redditizie è sufficiente per raggiungere il pareggio. Non ho ancora controllato i numeri, potrei sbagliarmi da qualche parte, e queste sono ovviamente condizioni ideali. Tuttavia, c'è una prospettiva di apprendimento qui, il che significa che si può tirare fuori una percentuale più alta a spese del MO.
Per quanto riguarda i predittori, hai preso i miei predittori dal mio articolo? Sono spesso presenti nei modelli che ho io, tra gli altri.
Aggiunta: Sì, non ho tenuto conto del fatto che ci sono operazioni redditizie, ma non chiuse dal TP, e quindi il profitto sarà minore.Questa strategia fornisce il 43% di operazioni redditizie su EURUSD dal 2008 al 2023, con un rapporto TP/SL di 61,8 in condizioni ideali, e il 39% delle operazioni redditizie è sufficiente per raggiungere il pareggio. Non ho ancora controllato i numeri, potrei sbagliarmi da qualche parte, e queste sono ovviamente condizioni ideali. Tuttavia, c'è una prospettiva di apprendimento qui, che significa che è possibile tirare fuori una percentuale più alta a spese del MO.
Per quanto riguarda i predittori, hai preso i miei predittori dal mio articolo? Si trovano spesso nei modelli che ho io, tra gli altri.
Non sono sicuro di quale sia la tua strategia. Sembra che ricevi un segnale per entrare una volta al giorno. Penso che sia molto poco parlare della significatività statistica dei risultati.
Ho addestrato i tuoi 5000+ predittori sul tuo dataset. Non danno più degli stessi 5 punti, quindi penso che non siano migliori dei miei semplici delta prezzo e zigzag, che danno anch'essi 5 punti.
Per ora controllerò altre idee. Se non daranno risultati, proverò i tuoi predittori per generare il mio modello.
Non capisco bene quale sia la vostra strategia. Sembra un segnale per entrare una volta al giorno.
La strategia è la seguente:
All'apertura della giornata calcoliamo l'intervallo limite previsto per il movimento del prezzo, a questo scopo possiamo usare l'ATR(3) alla fine dell'ultimo giorno, io uso una formula leggermente diversa. Posticipiamo questo intervallo dall'inizio dell'apertura del giorno corrente (barra) - lo consideriamo al 100%.
Quando si raggiunge un livello significativo al di sopra o al di sotto dell'apertura (mi sono fermato a 23,6 perché spesso si rivela tale su diversi strumenti secondo le mie osservazioni), apriamo una posizione con TP sul prossimo livello significativo (io uso 61,8) e mettiamo SL sul prezzo di apertura del giorno.
Se abbiamo chiuso al take profit, entriamo di nuovo quando appare un segnale.
È meglio chiudere alla fine della giornata (23:45) se i take profit non hanno funzionato, ma in realtà sto aspettando il TP/SL.
Ora il markup iniziale funziona in questo modo: se abbiamo chiuso in profitto, mettiamo 1, se abbiamo chiuso in perdita -1.
Quando ho diviso il campione, ho fatto in modo che il target fosse sfalsato di 300 pips, quindi se il profitto è inferiore a 300 pips, è zero.
Penso che questo sia molto poco per parlare della significatività statistica dei risultati.
Ho preso i dati del 2008. Sì, non ci sono molti dati, ma dipende da come li si guarda, perché se si considera che il livello di 23,6 non è casuale e il suo attraversamento è significativo per il mercato, allora sarà come eventi simili che possono essere confrontati l'uno con l'altro, a differenza della situazione quando si generano entrate su ogni barra - ci sono molti eventi simili, il che complica solo l'apprendimento.
Penso quindi che abbia senso allenarsi in questo modo, ma gli eventi che influenzano la decisione dei partecipanti al mercato dovrebbero essere diversi nelle varie strategie. E, ancora, scambiare insiemi di modelli.
Ho addestrato gli oltre 5000 predittori sul vostro set di dati. Non danno più degli stessi 5 punti, quindi penso che non siano migliori dei miei semplici delta prezzo e zigzag, che danno anch'essi 5 punti.
Per ora controllerò altre idee. Se non daranno risultati, proverò i tuoi predittori per generare il mio modello.
Stai parlando del primo campione o del secondo? Se si tratta del primo, avevo una matrice di aspettativa di circa 30 punti per le varianti buone.
Posso provare ad addestrare il tuo campione su CatBoost, se lo carichi, naturalmente.
Ecco la strategia:
All'apertura della giornata calcoliamo l'intervallo limite previsto per il movimento del prezzo, a questo scopo possiamo utilizzare l'ATR(3) alla fine dell'ultimo giorno, io utilizzo una formula leggermente diversa. Posticipiamo questo intervallo dall'inizio dell'apertura del giorno corrente (barra) - lo consideriamo al 100%.
Quando raggiungiamo un livello significativo sopra/sotto l'apertura (io mi sono fermato a 23,6 perché spesso si rivela tale su diversi strumenti secondo le mie osservazioni) apriamo una posizione con TP sul prossimo livello significativo (io uso 61,8) e mettiamo SL sul prezzo di apertura del giorno.
Se abbiamo chiuso al take profit, entriamo di nuovo quando appare un segnale.
È meglio chiudere a fine giornata (23:45) se i take profit non hanno funzionato, ma in realtà sto aspettando il TP/SL ora.
Ora il markup iniziale funziona in questo modo: se abbiamo chiuso in profitto, mettiamo 1, se abbiamo chiuso in perdita -1.
Quando ho diviso il campione, ho fatto in modo che il target fosse sfalsato di 300 pips, quindi se il profitto è inferiore a 300 pips, è zero.
Ho preso i dati dal 2008. Sì, non ci sono molti dati, ma dipende da come li si guarda, perché se consideriamo che il livello di 23,6 non è casuale e il suo attraversamento è significativo per il mercato, allora si tratta di eventi simili che possono essere confrontati tra loro.
Ora l'obiettivo è più o meno chiaro.
Hai una stima del risultato in pips o solo win/loss? Sembra la seconda. È meglio stimare in punti.
In modo che il modello che dà il 75% non funzioni in realtà 50/50.
a differenza della situazione in cui gli input sono generati su ogni barra - ci sono molti eventi di questo tipo, che complicano solo l'apprendimento.
Vorrei aggiungere il diradamento - barre simili, se il prezzo non è andato di 100...1000 pts, allora salta.
Stai parlando del primo campione o del secondo? Se stai parlando del primo, allora avevo una matrice di aspettativa di circa 30 pips per le varianti buone.
Il secondo su H1. Beh, il primo non era migliore (ma ho fatto meno ricerche, non ho selezionato le caratteristiche, per esempio).
Posso provare ad addestrare il tuo campione su CatBoost, se lo carichi, ovviamente.
Ne ho centinaia. E non mi piace nessuno di loro per mettere in commercio. Se cambio il TP o lo SL o qualcos'altro, si tratta di una nuova variante. Quindi non ha senso.
Ora l'obiettivo è più o meno chiaro.
Hai una stima del risultato in punti o solo vittoria/perdita? Sembra la seconda. È meglio stimare in punti.
In modo che un modello del 75% non funzioni davvero 50/50.
Ho una valutazione in denaro :) Più l'obiettivo, come era una volta. Il target può essere spostato in seguito, se si vogliono più punti.
Nella strategia specifica ora tutto è take profit. Ho fatto un lotto calcolato, infatti si è scoperto che lo spread peggiora la proporzione in modo significativo, ma va bene, ma ci sarà stabilità senza emissioni di entrate super redditizie - il rischio è quasi lo stesso ovunque. Se poi si utilizzano le pause, si potrà migliorare il risultato.
Vorrei aggiungere lo sfoltimento - barre simili, se il prezzo non è andato di 100...1000 pts, allora salta.
E poi valutare su ogni barra, ben modello da applicare?
Il secondo su H1. Beh, il primo non era migliore (ma ho fatto meno ricerche, non ho selezionato i chip per esempio).
Ho centinaia di loro. E nessuno di essi mi piace inserire nel trade. Se cambio il TP o lo SL o qualcos'altro, si tratta di una nuova variante. Quindi non ha senso.
Il punto è che se esiste lo stesso algoritmo per creare un campione, sarà possibile confrontare i predittori.
E poi per stimare ad ogni barra, bene il modello da applicare?
Sì, se sono passati almeno XX pip, come nell'allenamento. Ma ci saranno distorsioni - solo le prime barre da 100 a 120 (200-220, ecc) se up e 999-979 (899-979) funzionerà più spesso.
Il punto è che se esiste lo stesso algoritmo per creare un campione, sarà possibile confrontare i predittori.
Non voglio davvero 5000+, ci vorrebbe molto tempo per contarli. Ma come ricerca di predittori significativi potrebbe essere necessario controllarli.
Buon pomeriggio!
Ho un approccio che può risolvere questo problema, ma preferibilmente i file di esempio dovrebbero essere senza predittori. Cioè non sono necessari più di 5000 predittori, ma solo il grafico del movimento stesso. Non è importante che sia composto da OHLC o da una sola variabile. Tuttavia, ho provato il metodo esistente su una variabile del campione, ovvero sulla colonna 5584, che ho convertito in un grafico utilizzando la formula D(i)=D(i-1)+ Target_100_Buy . Per tutti e tre i file ho ottenuto questi grafici:
1) train: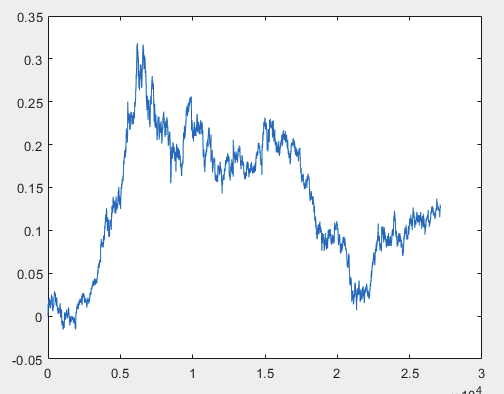
2)test: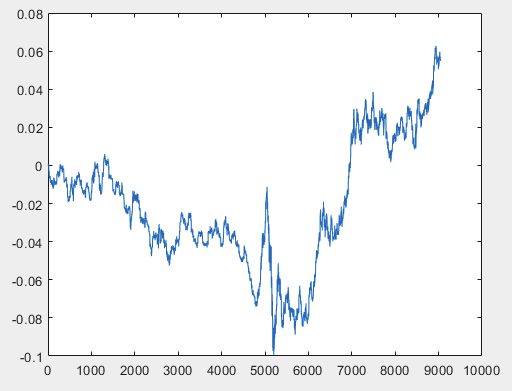
3)esame: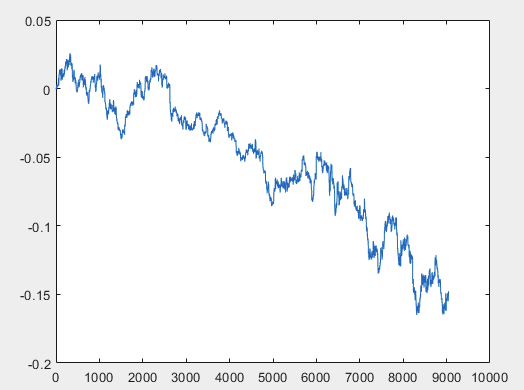
Non so se l'ho fatto correttamente o meno, ma se topikstarter crea nuovi campioni senza predittori, testerò il metodo su nuovi dati e vi dirò dell'approccio.
Bene, e il profitto effettivo per ciascuno dei campioni dopo l'addestramento del comitato di reti neurali (ce ne sono 10 in totale). Il profitto è espresso in numero di punti, con spread=0 e commissioni=0:
1) addestramento: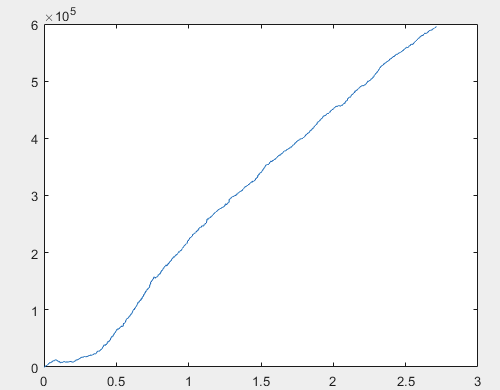
2) test: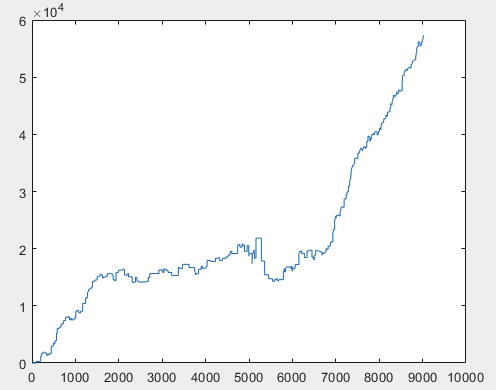
3) esame: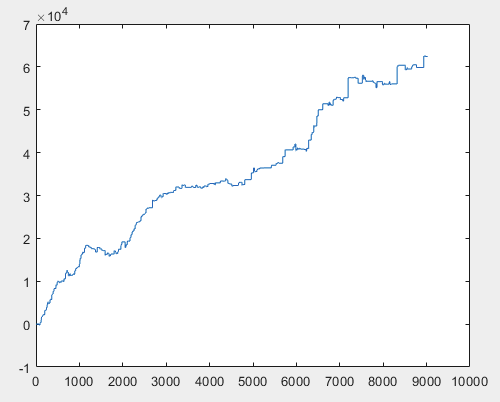
Penso che il risultato di 60000+ pips sia abbastanza accettabile.
Suggerisco a topikstarter di creare nuovi campioni, solo del segnale più "caotico".
Il metodo sarà applicato al nuovo segnale e i risultati saranno mostrati, così come l'approccio sarà descritto in una certa misura.
Saluti, RomFil!
P.S. Il futuro non è noto, ma un metodo per controllarlo si può sempre trovare ... :)
Buon pomeriggio!
Ho un approccio che può risolvere questo problema, ma preferibilmente i file di esempio dovrebbero essere senza predittori. Cioè non sono necessari più di 5000 predittori, ma solo il grafico del movimento stesso. Non è importante che sia composto da OHLC o da una sola variabile. Tuttavia, ho provato il metodo esistente su una variabile del campione, ovvero sulla colonna 5584, che ho convertito in un grafico utilizzando la formula D(i)=D(i-1)+ Target_100_Buy . Per tutti e tre i file, i grafici sono i seguenti:
Non capisco cosa abbiate fatto e perché sia necessario un nuovo campione se il vostro approccio funziona con i prezzi puri.
Le colonne dell'elenco sottostante sono il risultato dell'evento che si è verificato, cioè non dovrebbero partecipare alla formazione. Al massimo 5582 - ma lì credo sia facile da prevedere, quindi verrà recuperato dal modello così com'è.
5581 Ausiliario
5582 Ausiliario
5583 Etichetta
5584 Ausiliario
5585 Ausiliario
Non capisco cosa avete fatto e perché sia necessario un nuovo campione se il vostro approccio funziona con i prezzi puri.
Le colonne dell'elenco sottostante sono il risultato di un evento che si è verificato, cioè non dovrebbero partecipare all'addestramento. Al massimo 5582 - ma credo sia facile da prevedere, quindi verrà recuperato dal modello.
5581 Ausiliario
5582 Ausiliario
5583 Etichetta
5584 Ausiliario
5585 Ausiliario
"Che cosa ho fatto?":
Il treno campione ha una dimensione di circa 1 GB. Ci vuole molto tempo per caricarlo nell'area di lavoro. Ho un i5-3570 con 24 GB di RAM e un SSD veloce e Excel impiega diversi minuti per aprire questo file. Per questo motivo ho deciso di accorciarlo. Ero troppo pigro per trovare gli apici per oltre 5000 colonne. Ho preso la colonna 5584 5586 e ho applicato un segnale a tutte le righe, ad esempio BUY (onestamente non ricordo quale, forse SELL). In questo modo, questa colonna ha formato un grafico secondo la formula di cui sopra. Cioè il primo passo era zero, poi 0,00007, poi 0,00007-0,00002=0,00005, poi 0,00005+0,00007=0,00012, ecc. In altre parole, dalla colonna 5584 5586 ho formato un grafico di movimento senza vincoli, per così dire un grafico di movimento relativo. Come se fosse un grafico Close, cioè alla fine di ogni passo del grafico il prezzo dell'asset cambia del valore corrispondente.
P.S. Ho barato sul numero di colonna ... Ho preso il più recente 5586 (l'ho appena cercato in Excel) con il segnale SELL.
"... perché un nuovo campione":
Per mostrare e raccontare in una certa misura l'approccio sul suo esempio. Se si indicano i numeri delle colonne in cui è possibile prendere i prezzi OHLC o solo i prezzi delle clausole, sarà sufficiente.
Per il resto:
I dati dei file di esempio non vengono utilizzati affatto. Sulla base delle colonne 5584 5586 di ciascun file, viene realizzato un grafico come descritto sopra. E l'approccio viene già applicato a questi grafici ottenuti.
Bene, dato che topikstarter non vuole fornire nuovi campioni, suggerisco a chiunque sia interessato di postare i propri ... :)
Saluti, RomFil!
Buon pomeriggio!
Ho un approccio che può risolvere questo problema, ma preferibilmente i file di esempio dovrebbero essere senza predittori. Cioè non sono necessari più di 5000 predittori, ma solo il grafico del movimento stesso. Non è importante che sia composto da OHLC o da una sola variabile. Tuttavia, ho provato il metodo esistente su una variabile del campione, ovvero la colonna 5584, che ho convertito in un grafico utilizzando la formula D(i)=D(i-1)+ Target_100_Buy . Per tutti e tre i file, i grafici sono i seguenti:
La ripetibilità della funzione target è allenata? Ad esempio, se ha avuto successo 20 volte, avrà successo 21 volte?
Quanti valori inserire come predittori?
Ecco i target più semplici per comprare e per vendere con TP/SL=50 pts
M5 per circa 5 anni.
Il markup è su ogni barra M5, cioè molto probabilmente l'operazione dell'ultimo segnale (5 minuti fa) non è ancora terminata. Non sono sicuro che sia corretto impilarli. L'impilamento andrebbe bene per un obiettivo con un solo trade in un momento - anche 100 nello stesso momento potrebbero non essere completati durante la notte.
P.S. - Io non li ho addestrati. Falliscono sempre con il mio set di predittori.