OpenCL: test di implementazione interna in MQL5 - pagina 29
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
...
--
Fai 512 e vedi cosa ottieni. Non abbiate paura di scricchiolare il programma, lo renderà solo migliore. :) Quando l'hai fatto, pubblicalo qui.
OK! A 512 passaggi e 144000 battute:
Bene e se 60 è ottimale, allora in generale va bene:
//---
Cioè, sul portatile più debole presentato in questo thread, questo è il risultato. Così molto promettente.
//---
Sfortunatamente, non sono in grado di discutere liberamente l'argomento, dato che non sono nemmeno entrato nell'articolo di joo e nelle reti neurali, mentre non ho mai scavato su OpenCL. Non posso usare questo o quel codice senza capire ogni singola linea di codice. Voglio sapere tutto. ))) Sto ancora lavorando sul motore del programma di trading. C'è così tanto da fare che la mia testa è già in subbuglio. )))
Aumentato CountBars di un fattore 30 (a 4.320.000), ha deciso di verificare la resistenza della pietra al carico.
Non importa: funziona, si scalda, ma non suda troppo. La temperatura sale lentamente, ma ha già raggiunto la saturazione.
La linea rossa è la temperatura, la linea verde è il carico dei core.
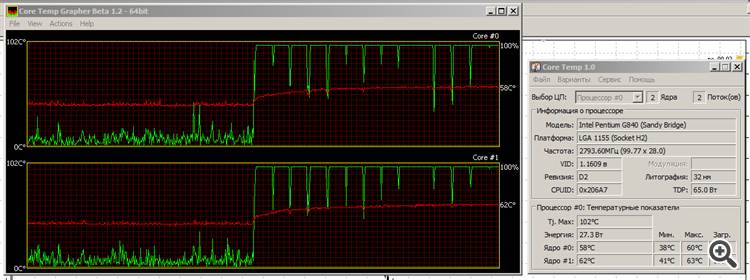
Ecco perché amo l'esemplare Sandy Bridge di Intel: è "verde". Sì, la grafica non è il massimo, ma vedremo cosa diventerà Ivy Bridge......
Ecco perché amo il modello Sandy Bridge di Intel: è "verde". Sì, la grafica non è il massimo, ma vedremo cosa diventerà Ivy Bridge...Oh. Questo sì che è un vero test di stress. :) Il mio sarebbe probabilmente già morto.
Poi cosa un Haswell e poi un Rockwell un po' più tardi... )))
Un esempio di implementazione della felce di Barnsley in OpenCL.
Il calcolo è basato sull'algoritmo Chaos Game(esempio) e utilizza un generatore di numeri casuali con una base di generazione che dipende dall'ID del thread e restituisce get_global_id(0) per creare traiettorie uniche.
Man mano che si scala, il numero di punti richiesto per mantenere la qualità dell'immagine cresce quadraticamente, quindi questa implementazione assume che ogni istanza del kernel disegni un numero fisso di punti che cadono all'interno dell'area visibile.
Il numero di fili stimati è specificato alla linea 191:
il numero di punti è nella linea 233:
UPD
IFS-fern.mq5 - analogo della CPU
In scala=1000:
Ho fatto tre strati di neuroni 16x7x3. In realtà, l'ho fatto l'altro ieri e l'ho debuggato oggi. Prima i risultati non andavano bene quando controllavo con la CPU - non descriverò qui i motivi, almeno non ora - ho troppo sonno. :)
Caratteristiche temporali :
Domani farò Optimizer per questa griglia. Poi mi occuperò di caricare dati reali e di finire il tester fino a calcoli realistici verificabili con MT5-tester. Poi mi occuperò del generatore MLP+cl-code delle griglie per la loro ottimizzazione.
Non pubblico il codice sorgente per avidità, ma l'ex5 è incluso per coloro che vorrebbero testarlo sul loro hardware.
Sono stabile come sotto Putin:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
A proposito, fai attenzione: per il runtime della CPU la differenza tra il tuo sistema e il mio (basato su Pentium G840) non è così grande.
La vostra RAM è veloce? Ho 1333 MHz.
Un'altra cosa: è interessante che entrambi i core siano caricati sulla CPU durante i calcoli. Il forte calo di carico alla fine è dopo la fine dei calcoli. Che cosa significherebbe?
Sono stabile come sotto Putin:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
1. A proposito, nota la differenza tra il tuo sistema e il mio (basato su Pentium G840) nel tempo di esecuzione della CPU.
2. La vostra RAM è veloce? Ho 1333 MHz.
1. Ho ripristinato il mio overclock nel mio tempo libero. Una volta ho avuto un crash davvero brutto (ho scoperto più tardi che il cavo di alimentazione del disco era caduto), così ho premuto il pulsante "MemoryOK" sulla scheda madre in cerca di un miracolo. Dopo di che, ancora non funzionava, solo le impostazioni CMOS sono state riportate a quelle di default. Ora, ho overcloccato il processore a 3840 MHz di nuovo, quindi ora funziona in modo più intelligente.
2. Ancora non riesco a capirlo. :) In particolare, il benchmark a cui Renat ha mostrato il link, mostra 1600MHz. I Windows mostrano addirittura 1033MHz :)))), nonostante il fatto che la memoria stessa sia 2GHz, ma mia madre può tirare fino a 1866 (in senso figurato).
Un'altra cosa: è interessante che ho entrambi i core caricati quando calcolo sulla CPU. Il forte calo di carico alla fine è dopo la fine dei calcoli. Cosa significherebbe?
Quindi forse non è affatto sulla GPU? Il driver è attivo, ma... La mia unica spiegazione è che il calcolo è fatto su CPU-OpenCL, solo, ovviamente, su tutti i core disponibili e usando istruzioni SSE vettoriali. :)
La seconda variante è che conta contemporaneamente su CPU e CPU. Non so come questo supporto (CPU-LPU) sia implementato dal driver, ma in linea di principio non escludo anche una tale variante di avvio dell'elaborazione di opentCL.
Questa è la mia speculazione, semmai. O come va di moda scrivere ora - "IMHO". ;)
Ne dubito. Soprattutto perché ho solo due core. Da dove viene allora il profitto 25x?
Se avete Intel Math Kernel Library o Intel Performance Primitives (non li ho scaricati), è possibile... in alcuni casi. Ma è improbabile, visto che pesano centinaia di meg.
Dovrò vedere cosa ha da dire Google al riguardo.
Mathemat: Inoltre, è interessante notare che i miei calcoli sulla CPU hanno entrambi i core caricati.
No, intendevo il puro calcolo della CPU senza alcun OpenCL. Il carico è appena sotto il 100% dove ogni nucleo ha valori di carico comparabili. Ma quando si esegue codice OpenCL, sale al 100%, il che può essere facilmente spiegato dal funzionamento della GPU.