L'apprendimento automatico nel trading: teoria, modelli, pratica e algo-trading - pagina 436
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Funziona, grazie! Interessante come funziona...
Cerca 1 opzione più simile o fa una media su più opzioni? Apparentemente trova 1 migliore. Penso che dovrei andare per 10 o anche 100 varianti e cercare la previsione media (il numero esatto dovrebbe essere determinato dall'ottimizzatore).
Sì, qui mostra 1 migliore, non mi sono preoccupato di molte varianti, puoi provare a rifare se capisci la mia scrittura)
Non sono mai stato in grado di imparare come fare trading in profitto usando solo i prezzi. Ma il modello del modello l'ha fatto, quindi la scelta è ovvia :)
Una cosa è trovare un "modello", un'altra cosa è che dia un vantaggio statistico. IMHO ne dubito molto per qualche motivo. Infatti la ricerca di modelli tramite convoluzione (prodotto, differenza) lungo tutta la lunghezza di una serie storica con media è come fare una regressione in NS con UN NEURONE, cioè il modello lineare più semplice con segni estremamente stupidi, una fetta di prezzo com'è.
Una cosa è trovare un "modello", un'altra cosa è trovare un vantaggio statistico. IMHO ne dubito molto. Infatti la ricerca di modelli tramite convoluzione (prodotto, differenza) su tutta la lunghezza delle serie storiche con media, è come fare la regressione in NS con UN NEURONE, cioè il modello lineare più semplice, con segni estremamente smussati, una fetta di prezzo com'è.
Se si tratta di un singolo neurone, allora con un numero di ingressi pari alla lunghezza del pattern, (pattern di 30 barre = 30 ingressi NSb di 500 barre = 500 ingressi NS).
A mio avviso, molti neuroni negli strati interni del NS sono analoghi alla memoria, 10 - 50 - 100 neuroni supplementari sono corrispondentemente 10 - 50 - 100 varianti memorizzate di segnali di input. E confrontando il modello con 375000 varianti della storia (M1 per un anno) abbiamo una memoria assolutamente precisa e completa, invece di 10 -50 - 100 varianti più frequenti. Poi da questa memoria il cercatore di modelli identifica N risultati più simili e ottiene la previsione media, mentre la rete neurale aumenta i pesi delle connessioni tra i neuroni con ogni modello simile.
Inoltre non è chiaro perché dovremmo usare la convoluzione, presumo che tu proponga di convolvere il modello ricercato con ogni variante della storia, come risultato otteniamo la 3a sequenza temporale - e come aiuta a determinare la somiglianza del modello e la variante da controllare?Se si tratta di un neurone, allora con il numero di ingressi uguale alla lunghezza del modello, (modello di 30 barre = 30 ingressi NS di 500 barre = 500 ingressi NS).
Un'altra cosa che non è chiara è perché la convoluzione dovrebbe essere applicata, presumo che tu proponga di convolvere il modello cercato con ogni variante dalla storia, come risultato otteniamo la terza sequenza temporale - e come aiuta a definire la similarità del modello e della variante testata?
Sì, mostra 1 meglio qui, non mi sono preoccupato di molte varianti, puoi provare a rifarlo se capisci la mia scrittura )
guardando la foto, c'è qualcosa che non va...
Ecco un esempio casuale
La tua linea di previsione blu va molto ripidamente verso il basso, con un debole movimento di una variante simile...
Qui c'è solo questa variante con photoshop ed è risultata non così ripida e più logica come idea.
mentre guardo la foto, c'è qualcosa che non va...
Ecco un esempio casuale
La tua linea di previsione blu scende molto ripidamente, con un debole movimento di una variante simile...
Qui c'è solo questa variante con photoshop ed è risultata non così ripida e più logica come idea.
L'ho notato :) in certe situazioni non conta correttamente l'angolo per qualche motivo, è iniziato quando l'ho riscritto da una versione a singolo timeframe a una multi-timeframe, e non ho ancora capito dov'è il difetto
A proposito, è possibile che non l'abbia contato correttamente... non ho pensato a controllare con photoshop. L'angolo tra i grafici precedenti e le previsioni dovrebbe essere lo stesso
Esattamente.
Si fa crollare il modello e la fila dove gli estremi erano più simili, è semplice. Per esempio, avete una riga {0,0,0,1,2,3,1,1,1} e volete trovare un pattern {1,2,3} in essa, la convoluzione vi darà {0,0,0,3,8,14,11,8, 6} (contati a occhio) 14 al massimo dove si trova la "testa" del nostro pattern. Naturalmente è auspicabile normalizzare i vettori prima della convoluzione, altrimenti ci saranno degli estremi in luoghi con grandi numeri.
Perché complicare le cose in questo modo? Perché dovremmo cercare un estremo sulla convoluzione se possiamo cercare {0,0,0,1,2,3,1,1,1} specificamente nella riga {1,2,3}? A parte l'aumento della complessità e del tempo di calcolo, non vedo alcun vantaggio.
Perché complicare le cose in questo modo? Perché dovremmo cercare un estremo sulla convoluzione se possiamo cercare {0,0,0,1,2,3,1,1,1} specificamente nella serie {1,2,3}? A parte la complicazione e il tempo di calcolo più lungo, non vedo alcun vantaggio.
Hmmm... cosa intende per "ricerca specifica"? Per favore datemi un esempio di algoritmo più veloce della convoluzione.
Si possono usare due operazioni: la lunghezza della differenza vettoriale e il prodotto scalare, la lunghezza della differenza, credetemi è 3-10 volte più lenta, la differenza dei componenti, la quadratura, la somma, l'estrazione della radice, e la convoluzione è per moltiplicare e aggiungere.
Dovete prendere ogni pezzo di una fila di lunghezza 3 come un vettore e confrontarlo per "somiglianza" con il nostro {1,2,3}
Hmmm... cosa intende per "ricerca specifica"? Per favore datemi un esempio di un algoritmo più veloce della convoluzione.
Il più semplice è quello di spostare gradualmente la larghezza della finestra dell'esempio ricercato attraverso la sequenza e trovare la somma dei valori abs. dei delta:
0,0,0 e 1,2,3 errore = (1-0)+(2-0)+(3-0)=6
0,0,1 e 1,2,3 errore = (1-0)+(2-0)+(3-1)=5
0,1,2 e 1,2,3 errore = (1-0)+(2-1)+(3-2)=3
1,2,3 e 1,2,3 errore = (1-1)+(2-2)+(3-3)=0
2,3,1 e 1,2,3 errore = (2-1)+(3-2)+Abs(1-3) =4
Dove l'errore minimo è la massima somiglianza.
Notato :) in certe situazioni, non conta correttamente l'angolo per qualche motivo, è iniziato dopo che ho riscritto da una versione single-timeframe a una multi-timeframe, e non ho mai capito dov'è il difetto
A proposito, è possibile che io abbia contato in modo sbagliato... Non sono riuscito a controllare con Photoshop. Dovrei ottenere lo stesso angolo tra i grafici precedenti e le previsioni.
Non sono ancora sicuro che sia corretto considerare i grafici simili con una differenza così grande negli angoli di pendenza. Usando lo stesso esempio:
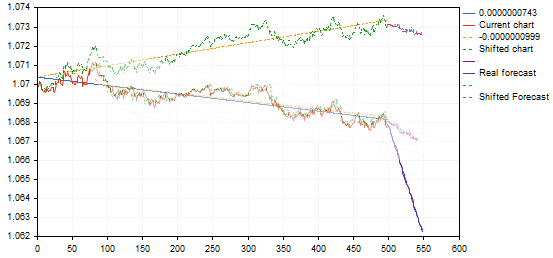
la variante trovata dà un pullback dal punto di tendenza superiore o la fine della tendenza, trasferendola al grafico del modello darà una previsione per una continuazione della tendenza in calo, piuttosto che un'inversione - essenzialmente un segnale inverso. C'è qualcosa che non va qui.... forse non abbiamo bisogno di queste trasformazioni affini....? E la semplice correlazione (errore minimo) è sufficiente?