L'apprendimento automatico nel trading: teoria, modelli, pratica e algo-trading - pagina 1258
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
un sacco di formule ((
Bene ) c'è un link al pacchetto R. Io non uso R, ma capisco le formule.
se usi R, provalo )
Bene ) c'è un link al pacchetto R. Io non uso R, ma capisco le formule.
Se usi R, provalo )
L'articolo di questa mattina è ancora aperto: https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71
Il fatto più deludente è che non sono riuscito a trovare un'implementazione Python di questo algoritmo. Gli autori crearono un pacchetto R(BayesTrees) che aveva alcuni problemi evidenti - soprattutto la mancanza di una funzione "predict" - e fu creata un'altra implementazione, più usata, chiamata bartMachine.
Se hai esperienza nell'implementazione di questa tecnica o conosci una libreria Python, per favore lascia un link nei commenti!
Quindi il primo pacchetto è inutile perché non può prevedere.
Il secondo link ha di nuovo delle formule.
Ecco un albero ordinario facile da capire. Tutto è semplice e logico. E senza formule.
Forse non sono ancora arrivato ai libs. Gli alberi sono solo un caso speciale di un enorme argomento bayesiano, per esempio ci sono molti esempi di libri e video qui
Ho usato l'ottimizzazione bayesiana degli iperparametri di NS secondo gli articoli di Vladimir. Funziona bene.Come gli alberi... ci sono le reti neurali bayesiane
Inaspettatamente!
NS lavora con le operazioni matematiche + e * e può costruire qualsiasi indicatore al suo interno, dai MA ai filtri digitali.
Ma gli alberi sono divisi in parti destre e sinistre da semplici if(x<v){ramo sinistro}se{ramo destro}.
O è anche if(x<v){diramazione a sinistra}se{diramazione a destra}?
Ma se ci sono molte variabili da ottimizzare, è oooo lungo.
Inaspettatamente!
NS lavora con le operazioni matematiche + e * e può costruire qualsiasi indicatore al suo interno - da MA a filtri digitali.
Gli alberi sono divisi in parti destre e sinistre da semplici if(x<v){ramo sinistro}se{ramo destro}.
O il baisian NS è anche if(x<v){ramo di sinistra}else{ramo di destra}?
è lento, è per questo che sto tirando fuori qualche conoscenza utile da esso finora, dà una comprensione di alcune cose
No, nella NS bayesiana, i pesi sono semplicemente ottimizzati campionando i pesi dalle distribuzioni, e l'output è anche una distribuzione che contiene un mucchio di scelte, ma ha una media, varianza, ecc. In altre parole, è una sorta di cattura di molte varianti che non sono effettivamente nel set di dati di allenamento, ma sono, a priori, assunti. Più campioni sono immessi in tale NS, più si avvicina ad una regolare, cioè gli approcci bayesiani sono inizialmente per insiemi di dati non molto grandi. Questo è quello che so finora.
Cioè tali NS non hanno bisogno di serie di dati molto grandi, i risultati convergeranno a quelli convenzionali. Ma dopo l'addestramento l'output non sarà una stima puntuale, ma una distribuzione di probabilità per ogni campione.
è lento, è per questo che sto tirando fuori qualche conoscenza utile da esso finora, dà una comprensione di alcune cose
No, nella NS bayesiana, i pesi sono semplicemente ottimizzati campionando i pesi dalle distribuzioni, e l'output è anche una distribuzione che contiene un mucchio di scelte, ma ha una media, varianza, ecc. In altre parole, è una sorta di cattura di molte varianti che non sono in realtà nel set di dati di allenamento, ma sono, a priori, assunti. Più campioni sono immessi in tale NS, più si avvicina ad una regolare, cioè gli approcci bayesiani sono inizialmente per insiemi di dati non molto grandi. Questo è quello che so finora.
Cioè tali NS non hanno bisogno di serie di dati molto grandi, i risultati convergeranno a quelli convenzionali. Ma l'output dopo l'addestramento non sarà una stima puntuale, ma una distribuzione di probabilità per ogni campione.
Corri come se fossi in velocità, una cosa alla volta, un'altra alla volta... ed è inutile.
Sembra che tu abbia un sacco di tempo libero, come alcuni signori, hai bisogno di lavorare, lavorare sodo, e sforzarti di crescere nella carriera, invece di correre dalle reti neurali alle basi.
Credetemi, nessuno in nessuna normale casa di intermediazione vi darà soldi per verbali o articoli scientifici, solo l'equità confermata dai primi broker del mondo.Non ho fretta, ma studio costantemente dal semplice al complesso
Se non hai un lavoro, posso offrirti, per esempio, di riscrivere qualcosa in mql.
Io lavoro per il padrone di casa come tutti gli altri, è strano che tu non lavori, tu stesso sei un padrone di casa, un erede, un ragazzo d'oro, un uomo normale se perde il lavoro in 3 mesi per strada, è morto in sei mesi.
Se non c'è niente di MO nel commercio, allora vai a fare una passeggiata, penseresti che i poveri bastardi siano gli unici mendicanti qui).
Li ho mostrati tutti in IR, onestamente, nessun segreto infantile, come tutti gli sfigati qui, l'errore nel test è 10-15%, ma il mercato è in continuo cambiamento, il commercio non va, chiacchiere vicino a zero
In breve, vai via, Vasya, non mi interessa piagnucolare
Non fate altro che lamentarvi, nessun risultato, scavate forchette nell'acqua e basta, ma non avete il coraggio di ammettere che state perdendo il vostro tempo
Dovresti entrare nell'esercito o almeno lavorare in un cantiere con uomini fisicamente, miglioreresti il tuo carattere.è lento, è per questo che sto tirando fuori qualche conoscenza utile da esso finora, dà una comprensione di alcune cose
No, nella NS bayesiana, i pesi sono semplicemente ottimizzati campionando i pesi dalle distribuzioni, e l'output è anche una distribuzione che contiene un mucchio di scelte, ma ha una media, varianza, ecc. In altre parole, è una sorta di cattura di molte varianti che non sono effettivamente nel set di dati di allenamento, ma sono, a priori, assunti. Più campioni sono immessi in tale NS, più si avvicina ad una regolare, cioè gli approcci bayesiani sono inizialmente per insiemi di dati non molto grandi. Questo è quello che so finora.
Cioè tale NS non ha bisogno di serie di dati molto grandi, i risultati convergeranno a quelli convenzionali.
Ecco dai commenti https://www.mql5.com/ru/forum/226219 all'articolo di Vladimir sull'ottimizzazione bayesiana, come si traccia la curva su più punti. Ma allora non hanno nemmeno bisogno di NS/foreste - si può semplicemente cercare la risposta proprio su questa curva.
Un altro problema - se un ottimizzatore non riesce ad imparare, insegnerà a NS delle sciocchezze incomprensibili.
 campione insegnato
campione insegnato 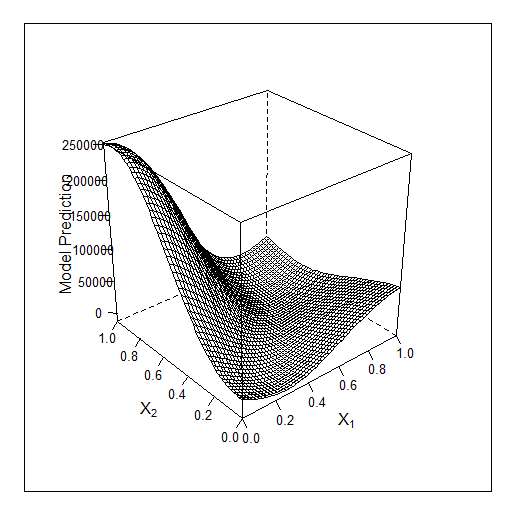
Qui per 3 caratteristiche Bayes lavoro
Sono i cretini nel thread che non lo rendono affatto divertente.
piagnucolando con se stessi.
Cosa c'è da dire? Si raccolgono solo link e diversi abstract scientifici per impressionare i nuovi arrivati, SanSanych ha scritto tutto nel suo articolo, non c'è molto da aggiungere, ora ci sono diversi venditori e scrittori di articoli che hanno imbrattato tutto con i loro forconi per vergogna e disgusto. Si chiamano "matematici", si chiamano "quantistici" .....
Vuoi matematica provare a leggere questohttp://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf
E non capirete che non siete un matematico, ma un fallito.