L'apprendimento automatico nel trading: teoria, modelli, pratica e algo-trading - pagina 169
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
se si tolgono le spine, niente...
Ma c'è anche il vetro, T&S, OI...ecc...
non sarete pagati.
Capisco, grazie.
Se fai diversi trade in un minuto, non sopravviverai sul forex... e anche se per miracolo hai una possibilità su 1.000.000, non c'è garanzia di essere pagato.
Beh, ci sono di nuovo le condizioni di trading.
Se non siete in grado di usarlo, neanche R-ka vi aiuterà. Una cosa è essere un consulente NS, un'altra cosa è essere un utente. Sono cose molto diverse...
Non credo che qualcuno lo sia, si chiama rendere assurdo ed era destinato al moderatore per capire l'assurdità delle sue affermazioni, Reshetov non c'entra niente...
Hai deciso di calcolare la media in excel e scrivi qualcosa sul forum mql, sei un parassita perché puoi farlo in mt5, mql non ha aiutato la comunità mql, capito?
Sei un parassita Michael, perché usi JProjection, è così... :)
R non c'entra niente, che differenza fa in cosa scrivere? è una questione di convenienza, niente di più.... Reshetov ha scritto il suo JProjected in Java, banditelo, non è mql, non è utile, questo come-si-chiama - parasite!!!!
è una parola sola.
Reshetov realizza i suoi programmi con l'aspettativa che i risultati vengano utilizzati in MT. Ha scritto molti consiglieri, ha tirato fuori migliaia di idee e tutto funziona per MT, quindi ha fatto molto come divulgatore, molto.
Puoi scrivere tutto quello che vuoi nel rondone di Dio, ma hai bisogno che la comunità sia in grado di usarlo in MT, altrimenti non sei utile alla comunità. Una comunità che è stata curata e nutrita, che è stata ampliata investendo enormi quantità di denaro.
Se hai un'idea praticabile, non è difficile tradurla in MCL. E il fatto che scriva qui e non sui forum di R è comprensibile - R è senza fondo, una comunità altamente specializzata non è facile da trovare. E per la comunità di MT è una risorsa indiscutibile.
Convalida incrociata su campioni aggiuntivi in un periodo di tempo diverso.
Supponiamo che io abbia un anno di dati di allenamento. Voglio addestrare 12 modelli - uno usando i dati di gennaio e un altro usando i dati di febbraio
Questo è un montaggio.
Prendiamo come esempio dei dati semplici e chiari e modelliamoli... Formazione. Puntini blu - tendenza. Punti rossi-validazione.
n1;n2;obiettivo
1;0;1
1;1;2
1;0;1
1;1;2
1;0;1
1;0;1
1;1;2
1;0;1
1;0;1
1;0;1
In alto a sinistra 50% di tendenza, 50% di validità. In alto a destra - con miscelazione.
Per OOS (in basso) aumentiamo il campione aggiungendo stupidamente il campione precedente. Poiché in realtà non conosciamo il futuro,
introduciamo un punto con il valore 1,5. Finché il test (OOS) corrisponde al punto di allenamento, tutto va bene.
A 1,5, il modello inciampa... Tralasciando i piccoli vantaggi dell'uso della convalida e della primitività
Nella vita reale abbiamo più o meno la stessa immagine...
Questa è l'opinione ufficiale del proprietario della risorsa.
Da qui
Per favore, basta con le accuse.
Ogni lingua ha il suo posto. R è ottimo per la ricerca interattiva. È il mio secondo giorno di esplorazione (ho letto il libro prima) e sembra davvero un potente debugger con visualizzazione delle interiora.
Lavorare con R ha subito rivelato le nostre debolezze:
Abbiamo rilasciato la prima piattaforma di trading algoritmico in MQL nel 2001. Ogni volta abbiamo aumentato le sue possibilità, ma il toolkit matematico non era così buono. Abbiamo sviluppato l'analisi, l'accesso ai dati, il tester, i calcoli distribuiti, e poi siamo arrivati al punto di vendere i prodotti.
E poi è diventato chiaro che la maggior parte delle soluzioni erano bloccate in un circolo vizioso di analisi, indicatori e adattamento. Dobbiamo lasciare che gli sviluppatori arrivino al prossimo livello di capacità matematica.
Ecco perché qualche tempo fa abbiamo iniziato ad estendere le librerie matematiche in MQL5 e abbiamo anche rilasciato in beta Alglib, Fuzzy e Stat. Essi vi permetteranno di trasferire facilmente alcuni modelli da altri sistemi a MQL5 e aumentare la classe delle soluzioni analitiche create per lapiattaforma Metatrader 5.
Nei prossimi 2 mesi vedrete i progressi che faremo nello sviluppo dell'ambiente matematico.
Diamo il benvenuto alle discussioni e agli articoli su pacchetti matematici complessi. Scrivi e invia richieste di articoli a Rashid Umarov. Il nostro compito è quello di incoraggiare ed educare i trader a tecniche più sofisticate, non di recintare noi stessi nel nostro mondo MQL5.
Naturalmente, difendiamo e continueremo a difendere la nostra lingua e la nostra piattaforma dagli attacchi, ma stiamo anche lavorando per svilupparle. Quindi tutto andrà bene.
PS.
Enfasi mia
Nel mondo reale abbiamo un quadro come questo...
Non capisco bene la sua conclusione.
Il modello funziona solo finché funziona su dati conosciuti? Cioè, quando si fa una previsione su nuovi dati inizierà a inciampare comunque, indipendentemente dal tipo di ripartizione (con/senza miscelazione)?
L'unico modo per risparmiare è non scambiare.
Lo faccio non solo per selezionare i parametri del modello, ma anche per selezionare gli indicatori e i loro parametri. Scarico 10000 indicatori con diversi parametri e lag da mt5, poi uso la genetica per cercare sia gli indicatori usati in questa lista che i parametri del modello (alberi nella foresta, strati nel neurone, ecc.). Si può dire che questo è il mio modo di trovare le dipendenze costanti.
Se prendo un set di indicatori standard con parametri standard in MT5, allora non avrò nessun modello crossvalidato con loro, sia esso neuronka o alberi. Trovare un set di indicatori su cui i modelli daranno risultati positivi in tale convalida incrociata è un risultato che richiede molto lavoro e tempo. Un risultato positivo è un criterio certo che ci sono correlazioni costanti tra tutti i predittori nello spazio e nel tempo. Qualunque sia l'intervallo preso per l'allenamento, il modello troverà le stesse dipendenze e si baserà su di esse.
L'immagine qui sotto è un esempio di tale convalida incrociata. Ogni linea nera è il risultato (crescita dell'equilibrio) del commercio di ogni singolo modello nell'insieme. La linea rossa è il risultato del trading della maggior parte dei modelli dell'ensemble. Circa 1/3 dei modelli non può ottenere alcun profitto, anche se la genetica ha impiegato più di un giorno per cercare tutte le varianti, cioè questo è uno dei migliori risultati che si possono trovare, anche se il risultato non è nemmeno molto buono. Se si compone qualsiasi indicatore standard per libero, tutto questo ventaglio nero andrà giù e la linea rossa andrà giù fuori dallo schermo.
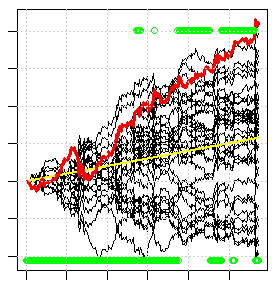
Alla ricerca di soluzioni... in queste realtà.
------------------------------------------------------------------------
Il drawdown sul lato sinistro dello schermo non è male, il modello non descrive questa zona...