Aide pour le 6ème degré de Poly !
- Calcul des différences, exemples.
- Filtres numériques adaptatifs
- League of Trading Systems. Continuez à faire du bon travail.
L'indicateur i-regr peut effectuer des régressions polynomiales arbitraires à n'importe quel degré. Je n'ai jamais essayé d'aller au-delà du 3ème degré, mais le code est là pour que vous puissiez le consulter. Le 6e degré tuera probablement votre processeur, mais vous pouvez essayer.
L'indicateur i-regr peut effectuer des régressions polynomiales arbitraires à n'importe quel degré. Je n'ai jamais essayé d'aller au-delà du 3ème degré, mais le code est là pour que vous puissiez le consulter. Le 6ème degré va probablement tuer votre CPU, mais vous pouvez essayer.
Merci rocketman ! Cela n'a pas tué mon processeur du tout - je vais travailler avec cela pendant un certain temps en utilisant et voir ce que je peux faire.
Mise à jour :
i-regr ne semble pas avoir un haut degré de précision - cela pourrait être dû à la méthode gauss (i-regr) et à la méthode des moindres carrés (excel) utilisée pour résoudre. Je ne sais pas - je cherche toujours, quelqu'un a de meilleures procédures de poly ?
i-regr travaille sur la valeur Close[] de chaque barre, ce qui fait probablement une différence (je suppose que vous avez égalisé les longueurs des motifs dans MT4 et excel).
Vous pouvez facilement changer cela en remplaçant Close[] par Open/High/Low ou par toute autre expression analytique, par exemple une fonction de poids.
Cependant, je ne pense pas que vous puissiez faire un profit avec cela, c'est juste comme n'importe quel autre indicateur de tendance de repeinture.
Bonjour dennisj2,
Êtes-vous sûr d'avoir vraiment besoin de votre formule ?
Peut-être que vous devriez d'abord chercher d'autres filtres comme Kalman, Ehlers, Gauss, Jurik (JMA), DEMA. La plupart d'entre eux sont dérivés des filtres de fréquence (physiques) passe-bas et la plupart d'entre eux ont trouvé leur chemin dans le code mt4.
Peut-être qu'un JMA (il existe de nombreuses variantes) avec une période plus longue correspond à ce que vous recherchez ?
C'est maintenant que ma quête commence.
Maintenant que j'ai identifié une application pratique, je cherche à apprendre (ou, dans mon cas, à réapprendre) les mathématiques derrière la formule de la ligne de tendance poly. Bonne chance avec ça. La réduction des moindres carrés et les matrices ajoutées à la formule extrêmement complexe et aux calculs de coefficients nécessaires introduits par l'équation polynomiale sont beaucoup trop difficiles (pour moi) à traduire en code. J'ai donc pensé que le plus simple serait d'appeler Excel (très probablement à partir de c++), de fournir un tableau de valeurs de données (x,y), de calculer l'intercept (valeur de la ligne de tendance) du polynôme (x,y) en utilisant LINEST(), et de renvoyer cette valeur à mon application de bureau (une application logicielle propriétaire fermée avec une fonctionnalité d'appel limitée).
L'assemblage de la formule à l'aide de LINEST() est devenu un obstacle important. Il est assez facile de fournir les données, mais comment puis-je calculer les intercepts (x,y) qui apparaissent si parfaitement sur le graphique ? Chaque nouvelle mesure modifie la formule et utilise des coefficients nouvellement calculés ? Pourquoi cela se produit-il ? J'ai passé des heures et des heures (et même plus) à chercher des solutions sur Internet et (comme un homme) j'ai finalement décidé de demander des instructions.
J'ai les valeurs sources (des années et des années). Ce qui me manque, c'est a) la méthode pour générer l'interception poly(x,y), b) en appelant Excel en externe pour c) renvoyer le poly(x,y) basé sur les données (x,y) fournies.
Si quelqu'un a un article ou un traitement très spécifique de ce sujet, ou même s'il est prêt à donner un coup de main, je vous en serai éternellement reconnaissant.
dj
Il y a beaucoup d'articles sur l'algèbre avec des exemples en grec, mais c'est vraiment du vaudou.
Par exemple, il y a un article de wikipedia sur la régression linéaire qui n'a aucun sens pour moi, pourtant je pourrais coder une version de régression linéaire de votre ligne en ce moment même parce qu'ailleurs j'ai appris à utiliser la formule suivante
y=a+bx
Pourtant, cette formule n'est mentionnée nulle part dans l'article de wikipedia, comment cela peut-il avoir un sens ?
J'ai aussi appris en utilisant cette formule
a == pente
b= interception
le calcul de la pente et de l'interception est connu et il s'agit d'une procédure assez simple consistant à calculer les sommes des valeurs, à élever au carré certaines d'entre elles, etc.
Je sais aussi que la formule d'une régression quadratique (2e degré) est y=ax^2 + bx + c.
Je pense donc qu'elles sont liées, ce qui devrait signifier que l'équation pour une régression du 3ème degré est
y=ax^3 + bx^2 + cx + d
Donc je pense que la régression du 6ème degré serait
y=ax^6 + bx^5 + cx^4 + dx^3 + ex^2 + fx + g
mais si a est la pente et b l'ordonnée à l'origine, qu'est-ce que c et qu'est-ce que d, etc ? C'est la seule raison pour laquelle je n'ai pas pu coder votre ligne, je ne sais pas quels sont les coefficients ou comment les calculer.
UPDATE : ok j'ai appris quelque chose d'autre qui me perturbe maintenant.
dans un autre article le polynôme quadratique est décrit comme
ax^2 + bx + c = 0
Cela signifie-t-il que nous n'avons pas besoin de connaître les mathématiques de la pente et de l'interception et que nous pouvons résoudre le quadratique pour trouver les valeurs de a, b et c ?
Mais comment ax^2 + bx + c = 0
est-il lié à
y=ax^2 + bx + c ?
Elles semblent similaires mais comment se fait-il que l'une soit y= et l'autre =0 ?
SDC,
la pente en un point peut être calculée par la dérivation première d'une fonction.
Une fonction linéaire comme y=ax+b a en tout point la même pente : a.
En général, la dérivation d'une fonction linéaire ax^n + bx^n-1 + .... + z = y est simplement : nax^(n-1) + (n-1)bx^n-2 ... = y' - la dernière constante de la fonction originale devient 0, toujours !
Donc ax + b = y => y' = a ( <= 1*a^(1-1) ; b=0 )et la fonction quadratique devient y' = 2ax + b ( <= 2ax^(2-1) + 1bx^(1-1) ; c=0 ).
Mais je pense que pour comprendre l'idée des filtres, il vaut mieux penser (et lire) à des fréquences de filtrage. Peu importe qu'il s'agisse de sons, d'images, de citations ou...
On veut toujours se débarrasser du bruit - en général - les fréquences à court terme. Et l'utilisation de fonctions linéaires n'est qu'une approche parmi d'autres.
Merci d'avoir essayé de m'expliquer cela mais je ne sais pas pourquoi ces équations signifient ce qu'elles signifient. Si je sais comment calculer les coefficients individuellement de manière procédurale, je peux les utiliser et brancher les valeurs, mais c'est à peu près tout.
Je comprends le concept des filtres, je voulais juste savoir comment coder la ligne de l'OP.
Mais pour ce qui est de faire ça, quand vous dites,
"Donc ax + b = y => y' = a ( <= 1*a^(1-1) ; b=0 )et la fonction quadratique devient y' = 2ax + b ( <= 2ax^(2-1) + 1bx^(1-1) ; c=0 )."
Je n'ai pas la moindre idée de ce dont vous parlez ou même de la pertinence de ce que vous dites, donc je ne ferai probablement pas de codage poly-ligne dans un avenir proche.
SDC:
Il existe de nombreux articles sur l'algèbre avec des exemples en grec, mais en réalité, c'est du vaudou.
SDC - vous êtes maintenant au même niveau que moi - la formule de régression linéaire que j'ai trouvée fonctionne - et il y a deux formules distinctes que j'ai trouvées et qui produisent des résultats identiques. Ces formules sont excellentes si la régression linéaire (une ligne de tendance droite) est ce que nous recherchons.
Tout d'abord, quelques documents de référence :
Microsoft : http://office.microsoft.com/en-us/excel-help/linest-HP005209155.aspx
IntegralCalc : https://www.youtube.com/watch?v=1pawL_5QYxE&noredirect=1
Étant donné l'équation de régression linéaire y = mx + b :
Où y = prix, (par exemple, Close[x])
et x = indice (par exemple, Bar[x])
et m = Pente (le coefficient appliqué à chaque paire (x,y))
et b = Intersection en Y (la valeur de base de l'intersection en Y appliquée à chaque paire (x,y))
Méthode A : A partir d'IntegralCalcMéthode B : A partir de Microsoft (où x(overbar) et y(overbar) sont des moyennes)


Même la formule de la ligne de tendance de régression polynomiale au nième degré est relativement facile à appliquer :
Étant donné la formule : y = m1*x1 + m2*x2 + m3*x3 + .... + b
Où les variables x, y, m et b ont la même définition que celle décrite dans l'équation linéaire.
Il semble que j'ai tout, alors que manque-t-il ?
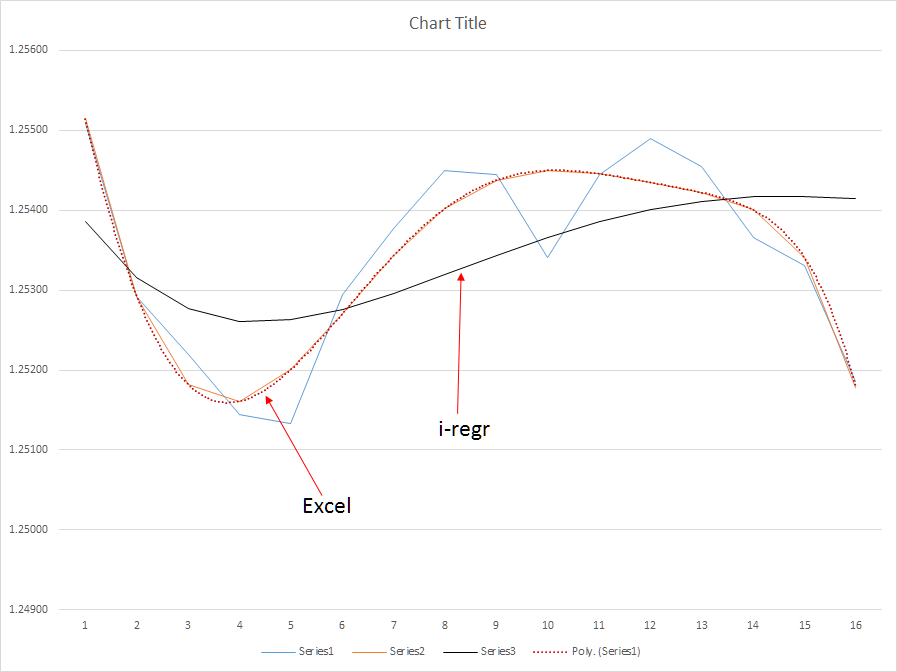
Ce qui manque, c'est le calcul de m (pente) et de b (ordonnée à l'origine) pour une régression polynomiale ; l'équation linéaire pour calculer ces valeurs ne s'applique pas à une régression polynomiale. D'après ce que j'ai appris, la régression polynomiale nécessite une formule qui calcule les moindres carrés sur la base d'un système d'équations polynomiales utilisant une matrice. Regardez les exemples de graphiques ci-dessus. Dans le premier graphique, les lignes poly(6) sont absolument immaculées - les sommets et les creux sont clairement indiqués. Grâce à ces données, je serai en mesure de conserver mes transactions plus longtemps que je ne le fais aujourd'hui, ce qui me permettra de doubler, voire de tripler, le nombre moyen de pips par transaction.
Dans le deuxième graphique, je montre les résultats de la méthode poly(6) par rapport à la méthode i-regr qui utilise une matrice de Gauss pour résoudre les coefficients de pente - et, inutile de le dire, c'est assez inutile en raison de la latence importante de la méthode. D'autre part, une moyenne mobile simple est encore pire - la SMA est beaucoup trop sensible lors des corrections intermédiaires du marché qui pourraient provoquer une réaction excessive de mon EA.
Je suis prêt à payer quelqu'un pour développer un véritable indicateur de régression polynomiale - mais, les résultats doivent absolument refléter les résultats qu'Excel produit. La fonction LINEST() est une boîte noire où beaucoup de vaudou est utilisé pour calculer les coefficients. Tout simplement, j'ai besoin de comprendre ce voodoo.
Mise à jour : j'ai joint un fichier montrant la méthode mise en œuvre dans Excel.
i-regr travaille sur la valeur Close[] de chaque barre, ce qui fait probablement une différence (je suppose que vous avez égalisé les longueurs des motifs dans MT4 et excel).
Vous pouvez facilement changer cela en remplaçant Close[] par Open/High/Low ou par toute autre expression analytique, par exemple une fonction de poids.
Cependant, je ne crois pas que vous puissiez faire un profit avec cela, c'est juste comme n'importe quel autre indicateur de tendance de repeinture.
Grazi -
J'ai utilisé l'i-regr et j'ai comparé les résultats ci-dessus - l'algorithme Poly(6) par rapport à l'i-regr montre que l'i-regr a une latence nettement supérieure à celle du poly(6) sur la base du même ensemble de données - la latence est la mort sur ce marché. Mes EA ne traitent pas l'oscillation intraday, mais attendent plutôt la tendance. Donc, vous vous trompez - je profite de mes EAs et, avec un indicateur réactif plus lent, mes EAs captureront plus du marché qu'ils ne le font aujourd'hui. Plus précisément, une fois que j'aurai intégré un véritable algorithme poly(6), je serai en mesure de maintenir des positions ouvertes plus longtemps et de prédire les changements de tendance 3-4 périodes plus tôt, améliorant ainsi mes points d'entrée.
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation