L'Apprentissage Automatique dans le trading : théorie, modèles, pratique et trading algo - page 3091
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
A la page 8 pour l'instant. Et il s'agit encore d'une introduction)))
Il semble qu'il s'agira d'une comparaison par Sharpe (mais ils écrivent que vous pouvez utiliser n'importe quel autre indicateur) sur la validation croisée.
Si j'ai bien compris, 4 paramètres doivent être optimisés
Il convient toutefois de noter que ces valeurs peuvent dépendre de la mesure de performance et de la valeur seuil sélectionnées.
Besoin d'une optimisation multicritères Pareto avant-arrière multicritères
Si j'ai bien compris, il y a 4 paramètres à optimiser
Il convient toutefois de noter que ces valeurs peuvent dépendre de la mesure de performance choisie et de la valeur du seuil
Trop court pour comprendre ce que sont ces paramètres. Voici plus d'informations tirées de l'article page 13 (si le package reproduit entièrement les méthodes de l'article, mais peut-être quelque chose d'autre a été ajouté/soustrait)
Statistiques d'overfit
Le cadre introduit à la section 2 nous permet de caractériser la fiabilité
bilité dubacktest d'une stratégie en termes de quatre analyses complémentaires :
1. Probabilité d'overfitting du backtest (PBO) : La probabilité que laconfiguration de modèle
sélectionnée comme optimale dans le SI soit moins performante que la me-
diane des N configurations de modèle OOS.
2. Dégradation de la performance: Ceci détermine dans quelle mesure une plus grande per-
formance dans le SI conduit à une plus faible performance OOS, un événement associé
aux effets de mémoire discutés dans Bailey et al. [1].
3. Probabilité de perte: probabilité que le modèle sélectionné comme
optimaleIS produise une perte OOS.
4. Dominance stochastique: Cette analyse détermine si la procédure
utilisée pour sélectionner une stratégie IS est préférable au choix aléatoire
d'une configuration de modèle parmi les N alternatives.
Chaque élément est examiné plus en détail ci-dessous.
C'est trop court pour comprendre ce que sont ces paramètres. Voici plus d'informations tirées de l'article page 13 (si le paquet reproduit entièrement les méthodes de l'article, mais peut-être que quelque chose d'autre a été ajouté/soustrait).
le paquet est tout simplement horrible, je n'ai jamais vu un tel partak depuis des années
le code est terrible
la documentation est pratiquement inutile
Je ne comprends pas comment il s'est retrouvé dans le CRAN.
Je n'arrive toujours pas à comprendre, est-ce qu'il y a un système de trading qui est investigué divisé en lots ou est-ce qu'il y a plusieurs TS (dans cette bibliothèque) ?
Je n'arrive toujours pas à comprendre, s'il y a un système de trading étudié divisé en lots ou s'il s'agit de plusieurs TS (dans cette bibliothèque).
Sélection du meilleur modèle parmi un ensemble de modèles obtenus avec différents paramètres/hyperparamètres. L'entrée est une matrice, où chaque colonne est une prévision d'un des modèles.
Ou peut-être pas. Je n'ai pas encore compris non plus.Sélection du meilleur modèle parmi l'ensemble des modèles obtenus à différents paramètres/hyperparamètres. L'entrée est une matrice où chaque colonne est une prédiction de l'un des modèles.
J'ai déjà trouvé la solution.
Je ne comprends pas comment travailler avec le résultat
Je donne une colonne (un TS)
résultat
Je donne 5 colonnes (5 CT)
J'obtiens également une ligne.
Il devrait y avoir 5 lignes, ou si c'est le résultat de la meilleure TS, il devrait y avoir un index de la meilleure...
Je tuerais cet auteur
Sélection du meilleur modèle parmi l'ensemble des modèles obtenus à différents paramètres/hyperparamètres. L'entrée est une matrice où chaque colonne est une prédiction de l'un des modèles.
Ou peut-être pas. Je n'ai pas encore compris cela non plusOn peut l'interpréter comme le fait de prendre les rendements des bénéfices TS de différentes sections du marché (paramètres/hyperparamètres ) ? ???
différentes sections du marché == paramètres/hyperparamètres?
Il peut être interprété comme la prise en compte des rendements des bénéfices de TC provenant de différentes parties du marché (paramètres/hyperparamètres ) ? ???
Exactement les retours de bénéfices.
différentes parties du marché == paramètres/hyperparamètres?
Si j'ai bien compris, il s'agit de paramètres : différentes périodes de MA, SL, etc.
Je reçois également une ligne
Il devrait y avoir 5 lignes, ou si c'est le meilleur TC, il devrait y avoir un index des meilleurs...
En conséquence, vous obtenez l'évaluation globale du modèle (et probablement du prédicteur et des données cibles)
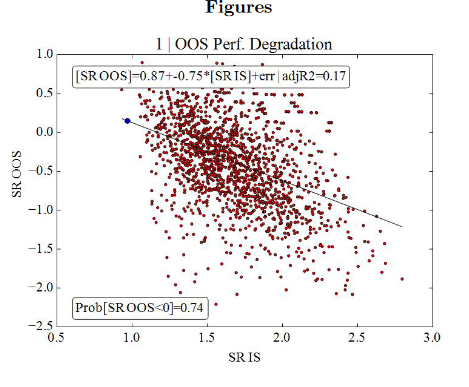
Un mauvais modèle donne de tels résultats (seulement 17% de résultats OOS supérieurs à 0).
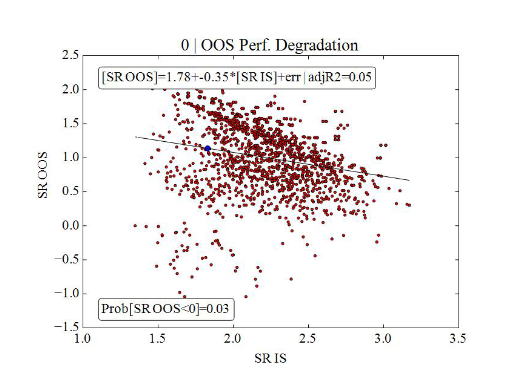
Un bon modèle - 95% des résultats OOS supérieurs à 0
Ce sont les rapatriés qui sont arrivés.
Vous savez, il y a des gains et des pertes, n'est-ce pas ?
Nous prenons donc les déclarations de retour des États lorsque le poste est ouvert.
Si je comprends bien, ce sont les paramètres : différentes périodes de MA, SL, etc.
Au lieu de différents réglages du TS, je vais simplement prendre le trading sur différentes zones, je pense que cela peut être assimilé.