L'apprentissage automatique dans la négociation : théorie, modèles, pratique et algo-trading - page 1180
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Ivan Negreshniy, je ne comprends pas, j'ai créé le modèle dans CatBoost, mais comment est-il censé être connecté, est-ce le pont/canal de EA à python, où les valeurs des prédicteurs seront passées, et dans la direction opposée le résultat des calculs sera reçu - une classe concrète ?
D'après ce que j'ai compris, CatBoost permet de décharger un code du modèle que je ne comprends pas, mais je vais le joindre pour l'estimation du professionnel, à moins qu'il puisse être intégré dans MQL d'une manière ou d'une autre et ne pas utiliser python alors ? Et, CatBoost a des bibliothèques en C++, ils ne peuvent pas les faire fonctionner en MQL et n'utilisent pas python et les commandes de la console ?
Ce qui n'est pas clair, c'est que le pont est nécessaire pour l'automatisation de bout en bout du travail avec les données et les modèles directement à partir d'Expert Advisor, y compris la création, la configuration, la formation, etc. Et ce que CatBoost déverse dans les fichiers est la sérialisation d'un modèle particulier, qui ne peut être utilisé que pour les calculs.
Bien sûr, vous pouvez créer un EA basé sur ces fichiers dans l'éditeur, mais il ne sera pas très différent d'un EA habituel avec une logique rigide, et si c'est le but, IMHO, il est beaucoup plus facile de l'atteindre par une formation utilisant des modèles, ce que j'ai suggéré . https://www.mql5.com/ru/forum/270216
Comme tout y est formé et généré automatiquement, et que le code de chaque arbre est converti en une fonction logique distincte, qui peut être plus facile à analyser et plus rapide à exécuter, si vous la complétez, nous pourrons comparer plus tard.
Cela demande beaucoup de travail pour moi en premier lieu.
La plupart des prédicteurs regroupent des indicateurs et les adaptent à l'ATR quotidien. Le reste du travail sur les séries temporelles est constitué de prédicteurs de caractérisation.
J'ai deux questions
1) Veuillez expliquer ce que cela signifie - un tas d'indicateurs et leur intégration dans l'agenda ATR.
2) Pourquoi catbust ? Êtes-vous sûr qu'il est meilleur que les autres boosts ?
Ce qui n'est pas clair ici, c'est que le pont est nécessaire pour l'automatisation de bout en bout du travail avec les données et les modèles directement à partir de l'EA, y compris la création, la configuration, la formation, etc,
Je vois, c'est-à-dire qu'il s'agit principalement de la possibilité de créer votre propre interface pour travailler avec la bibliothèque MoD, non ? Cela équivaut au fait que je prévois maintenant de faire la même interface mais en activant un fichier exe et en lui envoyant des commandes. En général, oui c'est intéressant de le faire via python, mais je n'ai pas ces connaissances, malheureusement.
et ce que CatBoost déverse dans les fichiers est la sérialisation d'un modèle spécifique, qui ne peut être utilisé que pour les calculs.
Bien sûr, nous pouvons créer un EA basé sur ces fichiers dans l'éditeur, mais il ne sera pas très différent d'un EA habituel avec une logique rigide, et si c'est le but, alors IMHO, il est beaucoup plus facile de l'atteindre par la formation avec l'aide de modèles, que j'ai suggéré. https://www.mql5.com/ru/forum/270216
Si vous comprenez ce code, peut-être pouvez-vous me dire comment le traduire en une forme lisible, par exemple en donnant à chaque règle une description finie, comme je le fais pour les feuilles après avoir traité les modèles à partir de R
Je n'arrive pas à comprendre l'algorithme de cryptage dans ce code - pouvez-vous faire sa description/interprétation (peut-être contre rémunération) ?
Et si c'est l'objectif, IMHO, il est beaucoup plus facile de l'atteindre par l'apprentissage de modèles, ce que j'ai suggéré . https://www.mql5.com/ru/forum/270216
Comme là, tout est formé et généré automatiquement, et le code de chacun des arbres est converti en une fonction logique distincte, qui peut être plus facile à analyser et plus rapide à exécuter, si vous le faites, nous pourrons comparer plus tard.
L'objectif n'est pas seulement d'obtenir un modèle, mais d'obtenir des feuilles, de les évaluer et de générer ensuite de nouveaux modèles sur la base de ces feuilles.
Je lisais ce sujet et je ne comprends pas bien, le processus de construction automatique de filets a été créé sur la base d'indicateurs nus et de balisage, l'information est transférée au modèle, alors que j'ai un post-traitement des indicateurs, plus j'utilise certains de mes indicateurs, que je ne veux pas mettre à la lumière, donc il s'avère que la méthode n'est pas disponible, et encore - vous ne pouvez pas obtenir des feuilles de celui-ci ...
J'ai deux questions
1) Veuillez expliquer ce que signifieregrouper des indicateurs et les intégrer dans l'ATR quotidien.
2) Pourquoi catbust ? Etes-vous sûr que c'est mieux que les autres boosts ? ou les échafaudages ?
1. c'est ma vision du marché, c'est-à-dire que le prix a un plan de mouvement, qui est défini par l'ATR en début de journée, puis en fonction des obstacles (niveaux de résistance (niveaux de prise/révision des décisions de trading par les acteurs du marché), qui sont, entre autres, des indicateurs), ce plan est mis en œuvre ou non. Les prédicteurs décrivent ces obstacles par rapport au plan de mouvement. Voici donc à quoi cela ressemble graphiquement - une grille le long de la plage ATR avec différents indicateurs à l'intérieur.
Captures d'écran de la plateforme MetaTrader
Si-9.18, M1, 2018.08.30
JSC ''Otkritie Broker'' ;, MetaTrader 5, Real
Pour la mémoire
2. CatBoost - j'ai eu un peu d'aide pour le mettre en place. De plus, il est évident que cela fonctionne plus rapidement que mon approche précédente de création de modèles en R et en même temps c'était plus efficace, il y a de la documentation et des commandes via DOS :) Par rapport à d'autres outils, par exemple Deductor Studio, il est plus stable et les modèles sortent mieux, de plus le dernier est payant, ici tout est gratuit.
Vous pourriez être intéressé, je suis tombé sur
Je veux construire un système sur l'optimisation d'arbres, ou plutôt en construisant des arbres avec l'optimiseur... sujet intéressant, mais je ne sais pas par où commencer :))
https://explained.ai/
Merci de vous inquiéter !
La barrière de la langue rend la lecture atroce, et les traducteurs rendent le texte soit bête, soit drôle... hélas.
traduire un mot à la fois, en utilisant le plugin google translator pour chrome.
J'utilise le pluginImTranslator dans chrome, il fonctionne bien quand on traduit un paragraphe à la fois, quand on sélectionne des mots et qu'on fait un clic droit sur le menu contextuel
pas besoin de cliquer sur google
Quel type de plugin est-ce ? Il fonctionnait dans Chrome, puis s'est arrêté, et je ne sais pas comment le configurer.
Je vois, c'est-à-dire qu'il s'agit avant tout d'une opportunité de créer votre propre interface pour travailler avec la bibliothèque MoD, n'est-ce pas ? Cela équivaut au fait que j'envisage maintenant de créer la même interface, mais en activant un fichier exe et en lui envoyant des commandes. En général, oui c'est intéressant de le faire via python, mais je n'ai pas ces connaissances, malheureusement.
Si vous comprenez ce code, pouvez-vous me dire comment le traduire sous une forme lisible, par exemple en donnant à chaque règle une description finie, comme je le fais pour les feuilles après avoir traité les modèles à partir de R
Je n'arrive pas à comprendre l'algorithme de cryptage dans ce code - pouvez-vous faire sa description/interprétation (peut-être contre rémunération) ?
L'objectif n'est pas seulement d'obtenir un modèle, mais d'obtenir des feuilles, de les évaluer, puis de générer de nouveaux modèles sur la base de ces feuilles.
J'ai lu ce thème et je ne comprends pas bien, le processus de construction automatique de filets a été créé par vous sur la base d'indicateurs nus et de balisage, l'information est transférée au modèle, dans mon cas, il y a un post-traitement des indicateurs, plus j'utilise certains indicateurs personnalisés, que je ne veux pas rendre public, donc il s'avère que la méthode n'est pas disponible, et encore - vous ne pouvez pas obtenir des feuilles de celui-ci ...
Je ne comprends pas pourquoi mai besoin d'édition manuelle des divisions et des feuilles de décider des arbres, oui, j'ai tous les embranchements est automatiquement converti en un opérateur logique, mais honnêtement, je ne me souviens pas que j'ai moi-même jamais corrigé.
Et en général, ça vaut la peine de creuser le code de CatBoost, comment puis-je en être sûr ?
Par exemple, j'ai testé ci-dessus sur python mon réseau de neurones avec formation par table de multiplication par deux, et maintenant je l'ai pris pour tester les arbres et les forêts (DecisionTree, RandomForest, CatBoost)
et voici le résultat - évidemment, ce n'est pas en faveur de CatBoost, comme deux fois deux font zéro cinq... :)
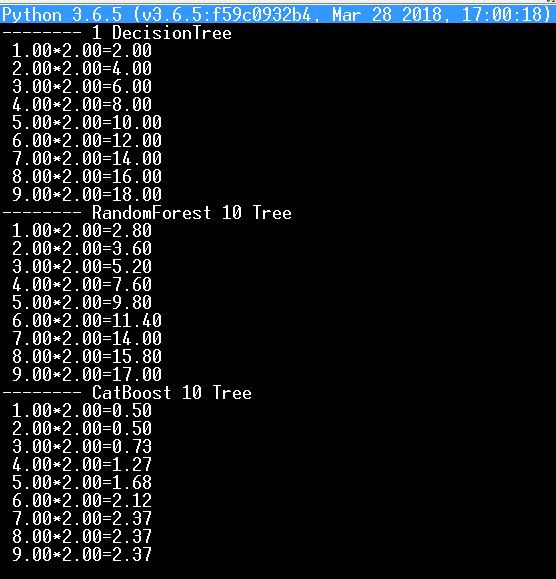
il est vrai que si vous prenez des milliers d'arbres, les résultats s'améliorent.Je ne comprends pas pourquoi l'édition manuelle des divisions et des feuilles des arbres de décision est nécessaire, oui j'ai toutes les branches converties automatiquement en opérateurs logiques, mais franchement je ne me souviens pas, que je les ai jamais corrigées moi-même.
Et en général, ça vaut la peine de creuser le code CatBoost, comment puis-je en être sûr ?
Par exemple, j'ai testé ci-dessus sur python mon réseau de neurones avec apprentissage par table de multiplication par deux, et maintenant je l'ai pris pour tester les arbres et forêts (DecisionTree, RandomForest, CatBoost)
et voici le résultat - clairement, ce n'est pas en faveur de CatBoost, comme deux fois deux font zéro cinq... :)
allez, c'est impossible que forest ou boosting ne puissent pas gérer la table de multiplication
Pas moyen, il n'y a pas moyen qu'une forêt ou un boosting ne puisse pas gérer la table de multiplication.