¿Hay algún patrón en el caos? ¡Intentemos encontrarlo! Aprendizaje automático a partir de una muestra concreta. - página 21
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
He recortado dos años más esta muestra y la media en el examen ya ha pasado a ser de -485 (era de 1214) y el número de modelos que superaron el límite de 3000 puntos ha pasado a ser de 884 (era de 277 la última vez).
Sin embargo, los resultados en la muestra del examen se han deteriorado, pasando de una media de 2115 a 186 puntos, es decir, de forma significativa. ¿A qué se debe esto? ¿Hay menos ejemplos en la muestra de tren similares a los de la muestra de prueba?
El número medio de árboles ha pasado de 10 a 7.
El punto cero del gráfico ha desplazado la distribución del equilibrio hacia el centro.
¿En qué se basa la afirmación de que el resultado debe ser similar a la prueba? Supongo que las muestras no son homogéneas: no hay un número comparable de ejemplos similares en ellas, y creo que las distribuciones de probabilidad sobre los cuantos difieren un poco.
Traine. Hablo de datos en los que hay buenos patrones. Si introduces 1000 variantes de la tabla de multiplicar en el entrenamiento, las nuevas variantes que nunca coincidan con la traine (pero dentro de los límites de la traine) también computarán bastante bien. Un árbol dará la variante más cercana, un bosque aleatorio hará la media de las cien más cercanas y lo más probable es que dé una respuesta más precisa que la de un árbol.
Si se pueden encontrar predictores con regularidad para el mercado, entonces OOS también será similar a una traza. Pero no como ahora que más de la mitad de los modelos son negativos y un tercio positivos. Todos los modelos exitosos se volvieron así por casualidad, a partir de una semilla aleatoria.
La semilla sólo debería cambiar ligeramente el éxito del modelo y, en general, todos deberían tener éxito. Ahora resulta que no se encuentran patrones (ni sobreentrenamiento ni infraentrenamiento).
Sólo interviene para controlar la detención del entrenamiento, es decir, si no hay mejora en la prueba mientras se entrena en el tren, entonces se detiene el entrenamiento y se eliminan los árboles hasta el punto en el que se produjo la última mejora en el modelo de prueba.
Entonces queda claro por qué las pruebas también son buenas. Es esencialmente ajustarse a la prueba. He dejado de hacerlo para 1 entrenamiento. Hago valving hacia delante, pego todos los OOCs juntos, luego elijo los mejores hiperparámetros del modelo (profundidad, número de árboles, etc) de entre las muchas variantes de OOCs pegados. Supongo que el examen será más o menos el mismo que el pegado seleccionado de todos los OOC. En esa variante más de 5 años, tengo re-entrenamiento una vez a la semana - eso es cientos de OOS de formación y trozos.
Aparentemente no indiqué claramente la muestra que utilicé - esta es la sexta (última) muestra del experimento descrito aquí, por lo que sólo hay 61 predictores.
estrategias primitivas, especialmente en zonas de mercado plano.Bueno, usted eligió estos 61 de entre más de 5000. Mi número total es menor y el número de seleccionados es menor. Y al añadir 1 a la vez, después de 3-4 seleccionados, más adición de signos sólo empeora el resultado en el OOS.
En general, puedo añadir más predictores, porque ahora sólo con 3 TFs se utilizan, con algunas excepciones - Creo que un par de miles más se puede añadir, pero si todos se utilizará correctamente en la formación es dudoso, dado que 10000 variantes de semillas para 61 predictores dar tal spread....
Y, por supuesto, hay que preseleccionar los predictores, lo que acelerará el entrenamiento.
Si todos son más o menos iguales, es poco probable que se encuentre algo que mejore seriamente el resultado. Puedes probar con datos completamente nuevos o indicadores únicos.
El cribado preliminar también es un trabajo largo, añadir uno a uno es muchas veces más largo, incluso hasta 3 características, y si es hasta 10, son muchos días. Pero no tiene sentido, después de 3-4 características no suele haber mejoras. Pero de vez en cuando hay, pero el aumento es pequeño. Los avances no se encontraron allí (en mis experimentos, alguien puede encontrar).
Es lógico que los valores atípicos son valores atípicos, sólo creo que estos son ineficiencias, que deben ser aprendidas mediante la eliminación de ruido blanco. En otras áreas, las estrategias primitivas simples a menudo funcionan, especialmente en áreas de mercado planas.
La imagen de abajo es rentable, pero en 5 años solo hubo 2 periodos en 2017 con fuerte crecimiento (aparentemente había una fuerte tendencia predecible), el modelo ganó más dinero en estos 2 periodos. Y sería bueno tener un crecimiento uniforme en el tiempo. Me gustaría apagar un modelo de este tipo después de un mes de inactividad.
Usted puede, por supuesto, hacer una EA - a la espera de cisnes blancos. Pero yo preferiría el comercio activo.
Si se recortan dos años más de esta muestra, la media en el Examen ya es de -485 (era de -1214), y el número de modelos que superan el límite de 3000 puntos es de 884 (era de 277 la última vez).
Sin embargo, los resultados en la muestra de examen se han deteriorado, pasando de una media de 2115 a 186 puntos, es decir, de forma significativa. ¿A qué se debe esto? ¿Hay menos ejemplos en la muestra de tren similares a los de la muestra de prueba?
El número medio de árboles disminuyó de 10 a 7.
El punto cero del gráfico ha desplazado la distribución del equilibrio hacia el centro.
Puedes postear los archivos del primer post, yo también quiero probar una idea.
Traine. Hablo de datos en los que hay buenos patrones. Si envías 1000 variantes de la tabla de multiplicar para entrenar, las nuevas variantes que nunca coincidan con la traza (pero dentro de los límites de la traza) también estarán bien calculadas. 1 árbol dará la variante más cercana, un bosque aleatorio hará la media de cien más cercanas y lo más probable es que dé una respuesta más precisa que a partir de 1 árbol.
Si se pueden encontrar predictores con regularidad para el mercado, entonces OOS también será similar a una traza. Pero no como ahora que más de la mitad de los modelos son negativos y un tercio positivos. Todos los modelos exitosos se volvieron así por accidente, a partir de una semilla aleatoria.
La semilla sólo debería cambiar ligeramente el éxito del modelo y en general todos deberían tener éxito. Ahora resulta que no se encuentran patrones (ni sobreentrenamiento ni infraentrenamiento).
Nadie discute que con buenos datos lo más probable es que todo funcione perfectamente. Pero, no se pueden conseguir esos datos, así que hay que pensar qué se puede exprimir de lo que se tiene.
El hecho de que sea posible obtener modelos eficaces de forma aleatoria, que serán eficaces con nuevos datos, me hace preguntarme cómo reducir esta aleatoriedad, es decir, si existe alguna métrica regular para los segmentos cuánticos, sobre la que se haya construido el modelo de forma coherente. Es decir, estamos hablando de métricas adicionales aparte de la codicia en el blanco. Si se pueden establecer tales dependencias, entonces también se pueden construir modelos con una mayor probabilidad de éxito. Por supuesto, esto debería funcionar en muestras diferentes.
Entonces también entiendo por qué las pruebas son buenas. Es esencialmente ajustarse a la prueba. He dejado de hacer eso para 1 estudio. Hago valving forwards, pego todos los OOCs juntos, luego elijo los mejores hiperparámetros del modelo (profundidad, número de árboles, etc) de entre las muchas variantes de OOCs pegados. Supongo que el examen será más o menos el mismo que el pegado seleccionado de todos los OOC. En esa variante a lo largo de 5 años, he reentrenado una vez a la semana - eso son cientos de OOS entrenados y troceados.
Lo principal es no separar la última sección del examen.
¿Ajustar hiperparámetros y evaluar el resultado en qué? Creo que es el mismo ajuste con un elemento de promedio, si seguimos su lógica.
La lógica en CatBoost es que si es imposible mejorar el modelo (por Logloss), entonces no tiene sentido seguir entrenando. En este caso no hay garantías de que el modelo resulte bueno, por supuesto.
Pues esos 61 que has elegido de entre más de 5000. Tengo tanto el número total como el número de seleccionados. Y cuando se añade 1 a la vez, después de 3-4 seleccionados, la adición adicional de características sólo empeora el resultado en OOS.
No, no las elegí - las saqué del modelo cuando entrenaba con todos los predictores.
Mira, generalmente considero el predictor como un conjunto de segmentos cuánticos. Y, por esta razón selecciono segmentos cuánticos, en general puedo incluso descomponer todos los predictores en binarios - el resultado es ligeramente peor, pero comparable. Quizás para los predictores binarios descompuestos se requiera un método especial de entrenamiento.
Si todos son más o menos iguales, es poco probable que ya se pueda encontrar algo que mejore seriamente el resultado. Puedes probar con datos completamente nuevos, o indicadores únicos.
¿Qué quieres decir con "más o menos lo mismo", supongo que estás hablando de métricas o qué? Por supuesto, puede probar con datos diferentes, por ejemplo, con una herramienta distinta.
La preselección también es un trabajo largo, añadir una a una lleva muchas veces más tiempo, incluso hasta 3 características, y si son hasta 10 lleva muchos días. pero no tiene sentido, después de 3-4 características no suele haber mejoras. Pero de vez en cuando hay, pero el aumento es pequeño. Los avances no se encontraron allí (en mis experimentos, alguien puede encontrar).
La variante de la que hablas es un juego largo, por eso no lo juego (bueno, no tengo automatización completa). Pero, no estoy de acuerdo que no hay efecto - he hecho abandonos en grupos, con la reducción de los grupos - el resultado fue positivo. Pero sigo atribuyendo estas acciones al ajuste o al azar - no hay justificación para la elección de los predictores.
La figura inferior es rentable, pero en 5 años sólo hubo 2 períodos en 2017 con un fuerte crecimiento (aparentemente había una fuerte tendencia predecible), el modelo hizo la mayor cantidad de dinero en estos 2 períodos. Y estaría bien tener un crecimiento uniforme en el tiempo. Yo apagaría tal modelo después de un mes de inactividad.
Por supuesto, usted puede hacer un Asesor Experto - a la espera de cisnes blancos. Pero yo preferiría el comercio activo.
Es por eso que estoy a favor de la utilización de conjuntos de modelos, ya que entiendo que cada uno puede coger sus propios patrones no frecuentes.
Bueno, en general, el objetivo es que el error en la traine y la prueba sea aproximadamente el mismo. Aquí tu Exam va hacia el traine y el test es decir hacia arriba, y ellos hacia el test es decir hacia abajo. El sobreentrenamiento va hacia abajo.
¿Y en qué métrica son similares?
Mira, por ejemplo, tomamos la métrica de Precisión, restamos este indicador en la muestra de prueba del tren, - obtenemos delta (eje y), y por x miramos el beneficio en la muestra de examen.
¿No hay una dependencia especial, o qué?
A continuación se muestran dos métricas para cada muestra - los datos se toman a medida que se añaden nuevos árboles al modelo.
Éstas son las características de este modelo
Y aquí están las métricas de otro modelo, con pérdidas en dos muestras
Estas son las características del modelo
Es incómodo responder en el estilo del foro, haciendo clic en responder muchas veces. Abajo mis respuestas están resaltadas en color.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> Vi hace tiempo cómo se construyen los cuantos, variantes básicas. Primero se ordena la columna
1) por rango, paso par (por ejemplo, de 0 a 1 con paso de valor exactamente por 0,1 totalizando 10 cuantos 0,1, 0,2, 0,3 ... 0,9)
2) por percentil, es decir, por el número de ejemplos. Si dividimos por 10 cuantos, entonces en cada cuanto ponemos el 10% del número de todas las filas, si hay muchos dobles, entonces algunos cuantos serán más del 10%, porque los dobles no deben caer en otros cuantos, por ejemplo, si los dobles son el 30% de la muestra, entonces en este cuanto caerán todos. Dependiendo del número de muestras en cada cuanto, la distribución podría ser 0,001, 0,12,0,45,0,51,0,74, .... 0,98.
3) existe una combinación de ambos tipos
Así que no hay nada super inteligente en la construcción de cuantos. Yo mismo he hecho estos dos métodos de cuantificación. Y como siempre he hecho algo de la manera que creo que es mejor. Tal vez cometí un error. Y suelo hacer cálculos sin cuantificación, pero sobre datos flotantes.
Si haces que todos los predictores sean binarios, sólo habrá 2 quantums, uno tiene todos 0's y el otro tiene todos 1's.
¿Ajustas hiperparámetros y evalúas el resultado sobre qué? Creo que es el mismo ajuste con un elemento promediador, si sigues tu lógica.
> Miro gráficos de balance y drawdowns. Todavía no he podido automatizar la selección. Sí, el ajuste es para un mejor encolado OOS. Pero no el modelo en sí (es decir, no la traza), sino la selección de los mejores hiperparámetros del modelo.
¿Qué quieres decir con "más o menos lo mismo", supongo que te refieres a alguna métrica o qué? Por supuesto, puedes probar con otros datos, tomar otra herramienta por ejemplo.
> Todas las que se hacen sobre precios y mashups.
Sobre una vieja pregunta.
¿En qué se basa la afirmación de que el resultado debe ser similar al tren? Estoy suponiendo que las muestras no son homogéneas - no hay un número comparable de ejemplos similares, y creo que las distribuciones de probabilidad de los cuantos son ligeramente diferentes.
> Ejemplos aquí https://www.mql5.com/ru/articles/3473
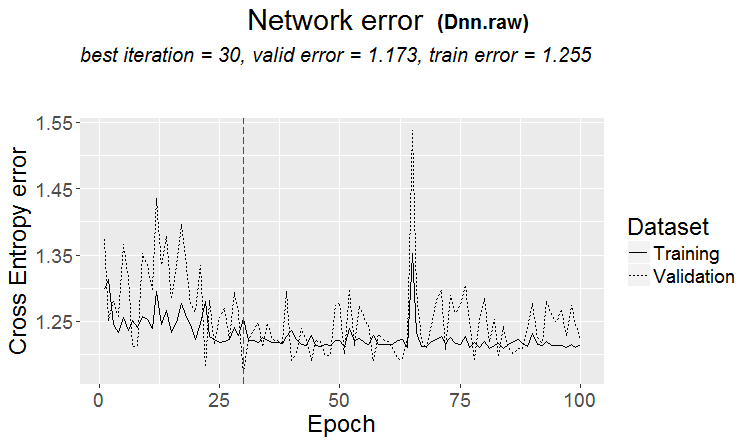
Una buena variante es cuando se encuentra un patrón: el ternario y el test tienen casi el mismo error
En los mercados más a menudo ocurre algo como esto: un buen test, pero después de algún paso de entrenamiento (en la figura después del 3er paso) empieza el reentrenamiento y el error del test empieza a crecer. Las imágenes se refieren a redes neuronales, pero también ocurre algo parecido con bosques y boosts, cuando el modelo se sobreentrena.
¿En qué métrica se parecen?
Pero eso no significa que tus métricas sean malas.
Así que no hay nada superinteligente en la construcción cuántica. Yo mismo he hecho estos dos métodos de cuantificación. Y como siempre he hecho algo de la manera que creo que es mejor. Tal vez cometí un error. Y normalmente hago cálculos sin cuantificación, pero usando datos flotantes.
Por supuesto que hay diferentes métodos, ahora utilizo unas 900 tablas de cuantificación.
La cuestión no está en el método, sino en elegir el rango del predictor en el que el valor medio del objetivo binario es mayor que en la muestra (ahora pongo un mínimo del 5% más criterios sobre el número de ejemplos - también un mínimo del 5%), lo que indica información útil en el predictor. Si no hay tal información, se puede esperar que aparezca en algunas divisiones, pero creo que es menos probable.
De hecho, sucede que hay 1-2 parcelas de este tipo, rara vez hay realmente muchos. Y aquí usted puede tomar solamente estos diagramas, o apenas tomar los predictores con tales diagramas, eligiendo la mejor tabla del quántum.
Personalmente, he visto que los predictores, al menos los míos, no tienen transiciones suaves de probabilidad, sino que sucede de forma discontinua y cambia a la desviación opuesta, es decir, era +5 e inmediatamente se convirtió en -5. Incluso creo que si estas probabilidades están ordenadas, el modelo será más fácil de entrenar, ya que se entrenan sobre rangos. Por eso tiene sentido excluir las zonas no informativas y separar las conflictivas.
Si haces que todos los predictores sean binarios, sólo habrá 2 cuantos, uno tiene todos 0 y otro tiene todos 1.
En realidad habrá uno - 0,5 :) Pero, de esta manera puedes descomponer el predictor en rangos útiles (que contengan información potencialmente útil).
> Mirando gráficos de balance y drawdowns. Automatizar la selección no ha funcionado todavía. Sí el ajuste - para el mejor encolado OOS. Pero no el modelo en sí (es decir, no la traza), sino la selección de los mejores hiperparámetros del modelo.
Bueno, es comprensible, pero no canónico - las métricas del modelo también son importantes, creo.
> Todo lo que se hace en precios y mashups.
En teoría sí, y que si se utilizan redes neuronales, pero en realidad - no - dependencias demasiado complejas deben buscarse con diferentes cálculos, para esto simplemente no tienen la potencia de cálculo de los usuarios normales.
En una vieja pregunta.
> Ejemplos aquí https://www.mql5.com/ru/articles/3473
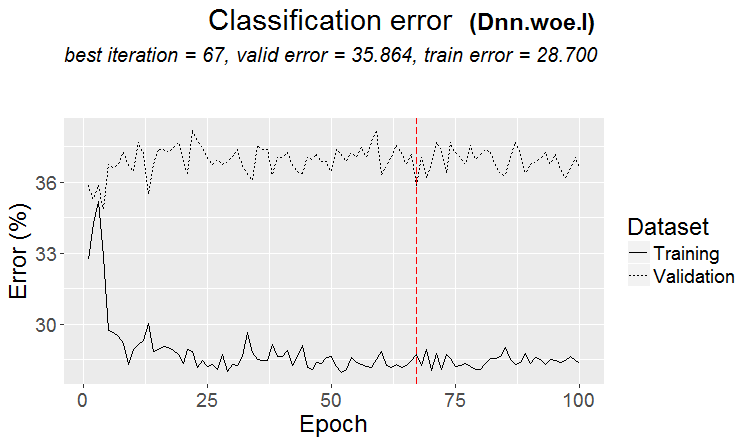
Una buena variante es cuando se encuentra un patrón: ternario y test tienen casi el mismo error
En los mercados más a menudo ocurre algo como esto: un buen test, pero después de algún paso de entrenamiento (en la figura después del 3º) empieza el reentrenamiento y el error del test empieza a crecer. Las imágenes se refieren a redes neuronales, pero también ocurre algo parecido con bosques y boosts, cuando el modelo se sobreentrena.
La regularidad siempre se encuentra - ese es el principio - la cuestión es si esta regularidad seguirá apareciendo o no.
No sé qué tipo de muestra tenías. He tenido casos en los que la prueba aprende más rápido que el entrenamiento, pero lo más frecuente es que ocurra al revés y que haya un delta notable entre ambos. En condiciones ideales, la diferencia será pequeña, por supuesto.
Puedo decir con seguridad que los modelos están poco entrenados simplemente porque las muestras no son muy similares y el entrenamiento se detiene cuando no hay mejora.
Algún día os enseñaré cómo se ve gráficamente la muestra reentrenada: son dos protuberancias separadas por esquinas....
Reduzca más la muestra de entrenamiento a la mitad.
Solo hay 306 modelos, el beneficio medio por examen es de -2791 puntos.
Pero tengo este modelo
Con estas características
La expectativa de estera ciertamente ha caído, pero Recall ha crecido el doble - debido a esto y a un gráfico con un gran número de acuerdos.
Se utilizaron tales predictores:
Y hay 9 menos de ellos que en la muestra - Voy a tratar de tomar sólo ellos y entrenar en toda la muestra (en todas las líneas de tren).
Las divisiones se hacen sólo hasta el quantum. Todo dentro del quantum se consideran los mismos valores y no se dividen más. No entiendo por qué buscas algo en quantum, su propósito principal es acelerar los cálculos (el propósito secundario es cargar/generalizar el modelo para que no haya más divisiones, pero puedes limitar la profundidad de los datos flotantes) Yo no lo uso, sólo hago modelos sobre datos flotantes. Hice la cuantificación en 65000 partes - el resultado es absolutamente el mismo que el modelo sin cuantificación.
Personalmente, vi que los predictores, al menos los míos, no tienen transiciones suaves de probabilidad, sino que sucede abruptamente y cambia a la desviación opuesta, es decir, era +5 e inmediatamente se convirtió en -5.
También me he dado cuenta de algo así. Aumentar la profundidad en 1 cambia drásticamente la rentabilidad, a veces en + a veces en -.
De hecho, habrá un - 0,5 :) Pero, de esta manera será posible dividir el predictor en rangos útiles (que contengan información potencialmente útil).
Habrá 1 división que dividirá los datos en 2 sectores - uno tiene todos 0's, el otro tiene todos 1's. No sé a qué se llama cuanta, creo que cuanta es el número de sectores obtenidos tras la cuantificación. Tal vez es el número de divisiones, como usted quiere decir.