Aprendizaje automático en el trading: teoría, práctica, operaciones y más - página 851
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
2 clases
Cargado 1 núcleo
Ajuste , rfeControl = rfeControl(number = 1,repeats = 1) - redujo el tiempo a 10-15 minutos. Cambios en los resultados - 2 pares de predictores intercambiados, pero en general similares a los que había por defecto.
Pues ahí tienes, tus 10 minutos en un núcleo son mis 2 en 4 y dos minutos que no recuerdo.
Nunca espero algo durante horas, si 10-15 minutos no funcionaron, entonces algo está mal, así que pasar más tiempo no servirá de nada. Cualquier optimización a la hora de construir un modelo que dure horas es un completo fracaso en la comprensión de la ideología de la modelización, que dice que el modelo debe ser lo más burdo posible y de ninguna manera lo más exacto posible.
Ahora sobre la selección de predictores.
¿Por qué hace esto y por qué? ¿Qué problema intenta resolver?
Lo más importante en la selección es tratar de resolver el problema del reciclaje. Si no es así, la selección puede acelerar el aprendizaje reduciendo el número de predictores. Pero la reducción del número es mucho más eficaz si se aíslan los componentes principales. No afectan a nada, pero pueden reducir el número de predictores en un orden de magnitud y, en consecuencia, aumentar la velocidad de ajuste del modelo.
Así que para empezar: ¿por qué lo necesita?
He encontrado otro paquete interesante para filtrar los predictores. Se llama FSelector. Ofrece una docena de métodos para filtrar los predictores, incluida la entropía.
Tomé un archivo con predictores y un objetivo de aquí -https://www.mql5.com/ru/forum/86386/page6#comment_2534058
La evaluación del predictor por cada método la mostré en el gráfico del final.
El azul es bueno, el rojo es malo (para el corrplot los resultados se han escalado a [-1:1], para la evaluación exacta ver los resultados de cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable), etc.)
Puede ver que X3, X4, X5, X19, X20 son bien evaluados por casi todos los métodos, puede empezar con ellos, y luego tratar de añadir/eliminar más.
Sin embargo, los modelos en rattle no pasaron la prueba con estos 5 predictores en Rat_DF2, de nuevo el milagro no se produjo. Es decir, incluso con los predictores restantes, tiene que ajustar los parámetros del modelo, hacer una validación cruzada, añadir/eliminar predictores usted mismo.
Hice lo mismo con CORElearn utilizando los datos de los artículos de Vladimir.
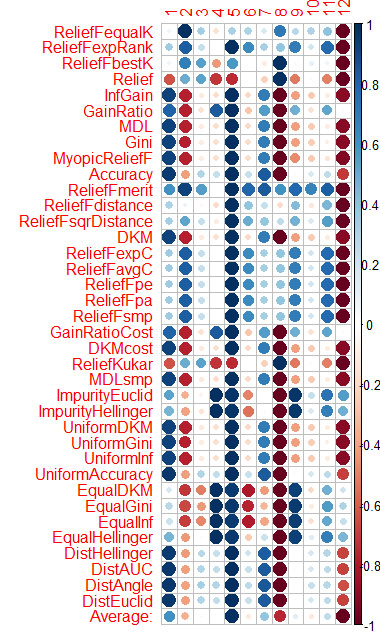
He calculado la media de las columnas (la fila inferior es Promedio) y he ordenado por ella. Es más fácil percibir la importancia total de esta manera.
Tardó 1,6 minutos, y eso que funcionaron 37 algoritmos. La velocidad es mucho mejor que la de Caret (16 minutos), con resultados similares.
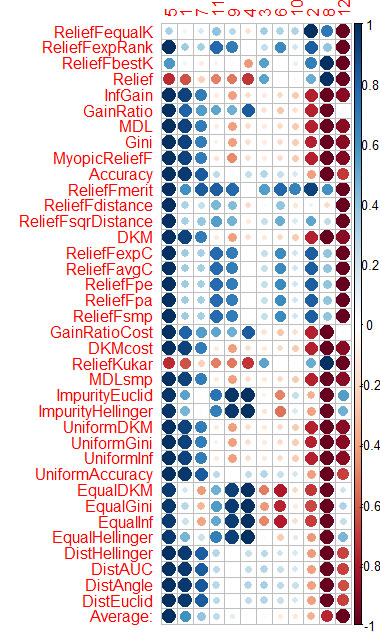
Hice lo mismo con CORElearn utilizando los datos de los artículos de Vladimir.
He calculado la media por columnas (la media de la fila inferior) y la he ordenado. Es más fácil percibir la importancia total de esta manera.
Ha tardado 1,6 minutos y ha utilizado 37 algoritmos.
Entonces, ¿cuál es el resultado final? Has respondido a la pregunta sobre la importancia de los predictores o no, porque no entiendo nada de estas imágenes.
Para mí ahora no hay ningún problema a la hora de construir y seleccionar un modelo, selecciono predictores, luego construyo 10 modelos sobre ellos, entonces la información mutua selecciona el que mejor funciona. ¿Sabes cómo hacerlo? ¡¡¡Es un reto mental!!! ¡¡¡¡¡Muy bien, quien lo resuelva es el mejor !!!!!
Me las arreglé para conseguir un conjunto de modelos. Y, en realidad, vporez: ¿Cuál de los modelos está funcionando y por qué??????
O mejor dicho, todos funcionan, pero sólo uno de ellos puede marcar. ¿Y explicar por qué?
Entonces, ¿cuál es el resultado final? Has respondido a la pregunta sobre la importancia de los predictores o no, porque no entiendo nada de estas imágenes.
Para mí ahora no hay ningún problema a la hora de construir y seleccionar un modelo, selecciono predictores, luego construyo 10 modelos sobre ellos, entonces la información mutua selecciona el que mejor funciona. ¿Sabes cómo hacerlo? ¡¡Es un reto mental!! ¡¡¡¡¡Muy bien, quien lo resuelva es el mejor !!!!!
Me las arreglé para conseguir un conjunto de modelos. Y, en realidad, vporez: ¿Cuál de los modelos está funcionando y por qué??????
O mejor dicho, todos funcionan, pero sólo uno de ellos puede marcar. ¿Y explicar por qué?
Vtreat ordena los predictores de forma muy similar (primero los importantes)
5 1 7 11 4 10 3 9 6 2 12 8
Y aquí está la clasificación por media en CORElearn
5 1 7 11 9 4 3 6 10 2 8 12
No creo que me moleste con más paquetes de selección de predictores.
Así que Vtreat es suficiente. Excepto que no se tiene en cuenta la interacción de los predictores. Probablemente también.
Se me saltan las lágrimas cuando veo que sigues recogiendo la importancia de los predictores de algunas piezas de la historia del mercado. ¿Por qué? Es una profanación de los métodos estadísticos.
Se ha comprobado en la práctica que si se introduce el predictor número 2 en el NS, el error pasa del 30% a casi el 50%.
y en el OOS, ¿cómo cambia el error?
¿Cómo cambia el error en el OOS?
de manera similar. Al igual que en los artículos de Vladimir, los datos proceden de ahí.
¿y si está en un OOS diferente?
En la práctica, he comprobado que si se introduce el predictor número 2 en el NS, el error pasa del 30% a casi el 50%.
Escupir en los predictores, y alimentar la serie de tiempo normalizado a la NS. El NS encontrará los predictores por sí mismo - +1-2 capas, y ahí lo tienes