Is there a pattern to the chaos? Let's try to find it! Machine learning on the example of a specific sample.
Actually, I suggest downloading the file from the link. There are 3 csv files in the archive:
- train.csv - the sample on which you need to train.
- test.csv - auxiliary sample, it can be used during training, including merged with train.
- exam.csv - a sample that does not participate in training in any way.
The sample itself contains 5581 columns with predictors, the target in 5583 column "Target_100", columns 5581, 5582, 5584, 5585 are auxiliary, and contain:
- 5581 column "Time" - date of the signal
- 5582 column "Target_P" - direction of the trade "+1" - buy / "-1" - sell
- 5584 column "Target_100_Buy" - financial result from buying
- 5585 column "Target_100_Sell" - financial result from selling.
The goal is to create a model that will "earn" more than 3000 points on exam.csv sample.
The solution should be without peeking into exam, i.e. without using data from this sample.
To maintain interest - it is desirable to tell about the method that allowed to achieve such a result.
Samples can be transformed in any way you want, including changing the target, but you should explain the essence of the transformation, so that it is not a pure fitting to the exam sample.
Training what is called out of the box with CatBoost, with the settings below - with Seed brute force gives this probability distribution.
FOR %%a IN (*.) DO ( catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_8\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 8 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 16 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_24\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 24 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 32 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_40\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 40 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 48 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_56\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 56 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 64 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_72\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 72 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 80 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
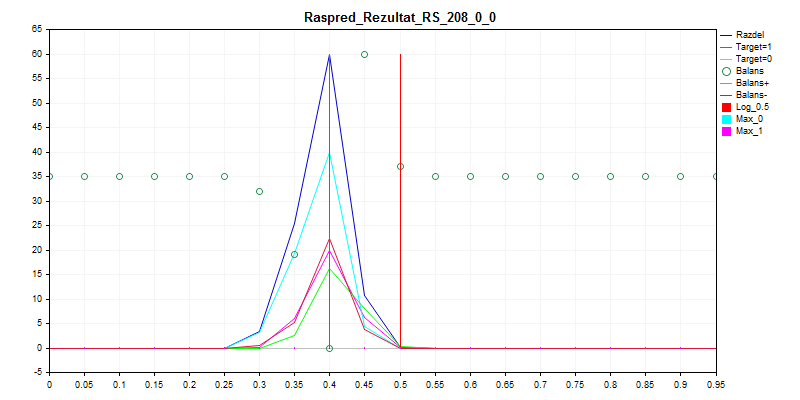
1. Sampling train

2. Sample test
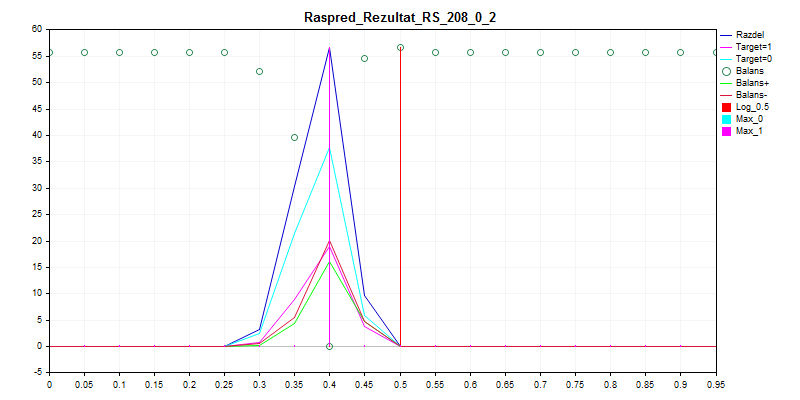
3. Exam sample
As you can see, the model prefers to classify all almost everything by zero - so there is less chance to make a mistake.
The last 4 columns
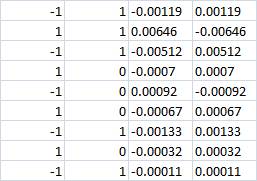
With 0 class apparently the loss should be in both cases? I.e. -0.0007 in both cases. Or if the buy|sell bet is still made, will we make a profit in the right direction?
Last 4 columns
With 0 class apparently the loss should be in both cases? I.e. -0.0007 in both cases. Or if the buy|sell bet is still made, will we make a profit in the right direction?
With zero grade - do not enter the trade.
I used to use 3 targets - that's why the last two columns with fin results instead of one, but with CatBoost I had to switch to two targets.
The 1/-1 direction is selected by a different logic, i.e. the MO is not involved in the direction selection? You just have to learn 0/1 trade/no trade (when direction is rigidly chosen)?
Yes, the model only decides whether to enter or not. However, within the framework of this experiment it is not forbidden to learn a model with three targets, for this purpose it is enough to transform the target taking into account the direction of entry.
If the class is zero - do not enter the transaction.
Earlier I used to use 3 targets - that's why the last two columns with financial result instead of one, but with CatBoost I had to switch to two targets.
Yes, the model only decides whether to enter or not. However, within the framework of this experiment it is not prohibited to teach the model with three targets, for this purpose it is enough to transform the target taking into account the direction of entry.
If the class is zero - do not enter the transaction.
Earlier I used to use 3 targets - that's why the last two columns with financial result instead of one, but with CatBoost I had to switch to two targets.
Yes, the model only decides whether to enter or not. However, within the framework of this experiment it is not prohibited to teach the model with three targets, for this purpose it is enough to transform the target taking into account the direction of entry.
Catbusta has multiclass, it's strange to abandon 3 classes
I.e. if at 0 class(do not enter) the correct direction of the transaction will be chosen, then there will be profit or not?
There will be no profit (if you do revaluation, there will be a small percentage of profit at zero).
It is possible to redo the target correctly only by breaking "1" into "-1" and "1", otherwise it is a different strategy.
There is, but there is no integration in MQL5.
There is no model unloading into any language at all.
Probably, it is possible to add a dll library, but I can't figure it out on my own.
There will be no profit (if you do a revaluation there will be a small percentage of profit at zero).
Then there is little point in financial result columns. There will also be errors of 0 class forecast (instead of 0 we will forecast 1). And the price of the error is unknown. That is, the balance line will not be built. Especially since you have 70% of class 0. I.e. 70% of errors with unknown financial result.
You can forget about 3000 points. If it does, it will be unreliable.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Actually, I suggest downloading the file from the link. There are 3 csv files in the archive:
The sample itself contains 5581 columns with predictors, the target in 5583 column "Target_100", columns 5581, 5582, 5584, 5585 are auxiliary, and contain:
The goal is to create a model that will "earn" more than 3000 points on exam.csv sample.
The solution should be without peeking into exam, i.e. without using data from this sample.
To maintain interest - it is desirable to tell about the method that allowed to achieve such a result.
Samples can be transformed in any way you like, including changing the target sample, but you should explain the nature of the transformation so that it is not a pure fit to the exam sample.