")
OpenCL :: Exploring the 1st Dimension (part2 the wrong benchmark and the correction)

Okay so what we'll do here is that same as before but use a double type this time
We change our kernel code to this :
string kernel="__kernel void bench(__global double* _tangent," "int iterations){" "double sum=(double)0.0;" "double of=(double)_tangent[get_global_id(0)];" "for(int i=0;i<iterations;i++){" "sum+=((double)tanh(of-sum))/((double)iterations);" "}" "_tangent[get_global_id(0)]=sum;}";
We create a double array with its size matching the amount of our kernels and we are ever vigilant to instantiate that carefully , so we drop back down to 5 kernels and deploy this :
//buffer double tangents[]; ArrayResize(tangents,kernels_to_deploy,0); double range=5.2; for(int i=0;i<ArraySize(tangents);i++){ double r=(((double)MathRand())/((double)32767.0)*range)-2.6; tangents[i]=r; } int tangents_id=CLBufferCreate(ctx,kernels_to_deploy*8,CL_MEM_READ_WRITE); //loop and setup args bool args_set=true; for(int i=0;i<kernels_to_deploy;i++){ ResetLastError(); if(!CLSetKernelArgMem(KERNELS[i].handle,0,tangents_id)){ Print("Cannot assign buffer to kernel("+i+") error #"+IntegerToString(GetLastError())); args_set=false; }else{ CLSetKernelArg(KERNELS[i].handle,1,iterations); } } if(args_set){ Print("All arguments for all kernels set!"); }else{ Print("Cannot setup kernel args!"); }
We create the buffer and then we must attach it to all kernels right ? Let's see if we can do that !
But , do not forget we must unload the buffer too , so add this after the unload loop
(we move the tangents id out of the loop , now in a normal distribution this will be wrapped and managed inside a structure but we are testing so there is no need for this to be able to land the lunar mission!)
CLBufferFree(tangents_id); CLProgramFree(prg);
We add it there so , we run it and with one run we figure out 2 things !
2023.05.02 20:49:49.762 blog_kernel_times_benchmark (USDJPY,H1) All arguments for all kernels set! 2023.05.02 20:49:49.776 blog_kernel_times_benchmark (USDJPY,H1) Time to load and unload 5 kernels = 94ms
Nice , now let's do 50 kernels , we want to gauge for any deployment delays
2023.05.02 20:50:51.875 blog_kernel_times_benchmark (USDJPY,H1) Deployed all kernels! 2023.05.02 20:50:51.875 blog_kernel_times_benchmark (USDJPY,H1) All arguments for all kernels set! 2023.05.02 20:50:51.891 blog_kernel_times_benchmark (USDJPY,H1) Time to load and unload 50 kernels = 93ms
Lovely , and 5000 kernels ?
Okay slight delay there but it seems okay
2023.05.02 20:52:03.356 blog_kernel_times_benchmark (USDJPY,H1) All arguments for all kernels set! 2023.05.02 20:52:03.373 blog_kernel_times_benchmark (USDJPY,H1) Time to load and unload 5000 kernels = 110ms
Lets get to the point now , finally !
We must rapidly light up the kernels set their offset and work loads and setup an interval of 1ms , jesus , and also we must not enter this portion of the timer function again otherwise we'll run into trouble . So . Bool indication kernelsRunning=false; 😊
If that is true then we move into a timer loop where we are just collecting completion notices and storing them.
Let's also add a completed indication in our kernel_info object , and i'll remove the handle from the setup since i did not use it , that would be a nice function mql5 , CLExecuteKernelList , like the CommandQueue in the original OpenCL api .
When all is complete we will tally the times ,but we'll deal with that later , so first we drop down to 5 kernels again.
this is how our class looks like now :
class kernel_info{ public: bool completed; int offset;//kernel offset in work int handle;//handle of kernel ulong start_microSeconds;//kernel execution call time ulong end_microSeconds;//kernel completed indication kernel_info(void){reset();} ~kernel_info(void){reset();} void reset(){ completed=false; offset=-1; handle=INVALID_HANDLE; start_microSeconds=0; end_microSeconds=0; } void setup(ulong _start,int _offset){ start_microSeconds=_start; offset=_offset; } void stop(ulong _end){ end_microSeconds=_end; } };
We gate the existing timer commands with
if(!kernelsRunning)
{
} And we are very careful here , we must anticipate the unloading of the kernels upon the test ending or the test not starting at all so :
We add an exitNow variable at the top , set to true if the test fails or the test ends .
all the contexts become variables of the global scope ...
We remove some stuff from the old section , don't worry i saved it as it was in the source file ,... so our timer looks like this now :
bool exitNow=false; if(!kernelsRunning) { EventKillTimer(); ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); //amount of kernels int kernels_to_deploy=5; tangents_id=INVALID_HANDLE; if(ctx!=INVALID_HANDLE){ string kernel="__kernel void bench(__global double* _tangent," "int iterations){" "double sum=(double)0.0;" "double of=(double)_tangent[get_global_id(0)];" "for(int i=0;i<iterations;i++){" "sum+=((double)tanh(of-sum))/((double)iterations);" "}" "_tangent[get_global_id(0)]=sum;}"; string errors=""; prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); //kernels to deploy will match the size of the "work" int iterations=1000;//iterations stays ArrayResize(KERNELS,kernels_to_deploy,0); bool deployed=true; for(int i=0;i<kernels_to_deploy;i++){ KERNELS[i].handle=CLKernelCreate(prg,"bench"); if(KERNELS[i].handle==INVALID_HANDLE){deployed=false;} } if(deployed){ Print("Deployed all kernels!"); //buffer double tangents[]; ArrayResize(tangents,kernels_to_deploy,0); double range=5.2; for(int i=0;i<ArraySize(tangents);i++){ double r=(((double)MathRand())/((double)32767.0)*range)-2.6; tangents[i]=r; } tangents_id=CLBufferCreate(ctx,kernels_to_deploy*8,CL_MEM_READ_WRITE); //loop and setup args bool args_set=true; for(int i=0;i<kernels_to_deploy;i++){ ResetLastError(); if(!CLSetKernelArgMem(KERNELS[i].handle,0,tangents_id)){ Print("Cannot assign buffer to kernel("+i+") error #"+IntegerToString(GetLastError())); args_set=false; }else{ CLSetKernelArg(KERNELS[i].handle,1,iterations); } } if(args_set){ Print("All arguments for all kernels set!"); // }else{ Print("Cannot setup kernel args!"); exitNow=true; } }else{ Print("Cannot deploy all kernels!"); exitNow=true; } //release }else{Alert(errors);exitNow=true;} } else{ Print("Cannot create ctx"); exitNow=true; } } //if exit if(exitNow){ if(tangents_id!=INVALID_HANDLE){CLBufferFree(tangents_id);} for(int i=0;i<ArraySize(KERNELS);i++){ if(KERNELS[i].handle!=INVALID_HANDLE){CLKernelFree(KERNELS[i].handle);} } if(prg!=INVALID_HANDLE){CLProgramFree(prg);} if(ctx!=INVALID_HANDLE){CLContextFree(prg);} Print("DONE"); ExpertRemove(); }
Okay , now ... let's think ...

Let's handle the completion first , that is the easy part
Upon all completing , for now , we exit and stop the timer.
Note we have not "launched" anything yet, we might get a myriad of errors when we do.!
else if(!Busy&&kernelsRunning){ Busy=true; //loop and check completion bool still_running=false; for(int i=0;i<ArraySize(KERNELS);i++){ if(!KERNELS[i].completed){ if(CLExecutionStatus(KERNELS[i].handle)==CL_COMPLETE){ KERNELS[i].completed=true; }else{still_running=true;} } } //if nothing is still running bounce if(!still_running){ EventKillTimer(); exitNow=true; } if(!exitNow){Busy=false;} }
It looks simple enough and correct , i think :
- we go into the list of kernels
- if something has finished we set it to completed
- if not we light up the still running flag
- exit the loop
- if nothing is still running kill the timer
- light up exit now
- dont shut off busy indication
Op , forgot to measure the end time ! add this under completed
KERNELS[i].stop(GetMicrosecondCount()); and this is the execution call :
//light the fuse uint offsets[]={0}; uint works[]={1}; for(int i=0;i<ArraySize(KERNELS);i++){ offsets[0]=i; CLExecute(KERNELS[i].handle,1,offsets,works); KERNELS[i].setup(GetMicrosecondCount(),i); } kernelsRunning=true; EventSetMillisecondTimer(1);
Let's see what happens , i can't see anything now , it exited though . So .. that was with 1000 iterations on 5 kernels
Now the task is to grow the execution time of each kernel above the timer interval ... pffft ..
To do that we need to output our findings to a file !
int f=FileOpen("OCL\\kernel_bench.txt",FILE_WRITE|FILE_TXT); if(f!=INVALID_HANDLE){ for(int i=0;i<ArraySize(KERNELS);i++){ ulong micros=KERNELS[i].end_microSeconds-KERNELS[i].start_microSeconds; if(KERNELS[i].completed){ FileWriteString(f,"K["+IntegerToString(i)+"] completed in ("+IntegerToString(micros)+")microSeconds\n"); } else { FileWriteString(f,"K["+IntegerToString(i)+"] not completed\n"); } } FileClose(f); }
We add this to the exit block and we wait and see.
and voilla
K[0] completed in (87334)microSeconds K[1] completed in (87320)microSeconds K[2] completed in (87300)microSeconds K[3] completed in (87279)microSeconds K[4] completed in (87261)microSeconds
now , what do these mean ? nothing they must be below our execution threshold i thing . lets see
One microsecond is ... 1000000th of a second , or , one second is 1000000 microseconds so what we see here is 87 milliseconds and we are accessing the interval at 1 ms , okay . I don't trust it because there may be a delay for the loop too .
So ... let's make the calcs heavier (more iterations) i'm sending one million iterations . now , these will end at the same time more or less
I'm also shutting mt5 down and restarting it for each run , don't know if theres any caching going on but i want to avoid it.
-i think i must keep the test going for as long at the status of the kernels is running or in line to be executed or smth-
It appears to be stuck or smth ... i expected an 80 second run , its been 5 minutes now...15 minutes okay , something broker . letsssss add some cases there ... @#%!#!%$@^
//loop and check completion bool still_running=false; int running_total=0; int completed_total=0; int queued_total=0; int submitted_total=0; int unknown_total=0; for(int i=0;i<ArraySize(KERNELS);i++){ if(!KERNELS[i].completed){ ENUM_OPENCL_EXECUTION_STATUS status=CLExecutionStatus(KERNELS[i].handle); if(status==CL_COMPLETE){ completed_total++; KERNELS[i].completed=true; KERNELS[i].stop(GetMicrosecondCount()); }else if(status==CL_RUNNING){running_total++;still_running=true;} else if(status==CL_QUEUED){queued_total++;} else if(status==CL_SUBMITTED){submitted_total++;} else if(status==CL_UNKNOWN){unknown_total++;} }else{ completed_total++; } } string message="Running("+IntegerToString(running_total)+")\n"; message+="Completed("+IntegerToString(completed_total)+")\n"; message+="Queued("+IntegerToString(queued_total)+")\n"; message+="Submitted("+IntegerToString(submitted_total)+")\n"; message+="Unknown("+IntegerToString(unknown_total)+")\n"; Comment(message);
changing the async waiting loop to this ... lets see why the f*** it fails...
Okay i was a bit naive earlier , i assume that it will complete anyway so , lets not let it exit if its queued or submitted or unkown and lets drop to 1000 iterations again.
Loop now changes to this :
//loop and check completion bool still_running=false; int running_total=0; int completed_total=0; int queued_total=0; int submitted_total=0; int unknown_total=0; for(int i=0;i<ArraySize(KERNELS);i++){ if(!KERNELS[i].completed){ ENUM_OPENCL_EXECUTION_STATUS status=CLExecutionStatus(KERNELS[i].handle); if(status==CL_COMPLETE){ completed_total++; KERNELS[i].completed=true; KERNELS[i].stop(GetMicrosecondCount()); }else if(status==CL_RUNNING){running_total++;still_running=true;} else if(status==CL_QUEUED){queued_total++;still_running=true;} else if(status==CL_SUBMITTED){submitted_total++;still_running=true;} else if(status==CL_UNKNOWN){unknown_total++;still_running=true;} }else{ completed_total++; } } string message="Running("+IntegerToString(running_total)+")\n"; message+="Completed("+IntegerToString(completed_total)+")\n"; message+="Queued("+IntegerToString(queued_total)+")\n"; message+="Submitted("+IntegerToString(submitted_total)+")\n"; message+="Unknown("+IntegerToString(unknown_total)+")\n"; Comment(message); //if nothing is still running bounce if(!still_running){ EventKillTimer(); exitNow=true; }
Dropped to 1000 iterations i think i saw it go through the kernels one by one . lets add x10 iterations and see.
Same , 100k iterations ... same . okay is there a problem with the decimal precision or something and we can't hit 1 million ?
There we go , yes , there is one unknown left and 4 completed kernels with one million iterations , but why ?
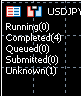
It get's stuck there but fortunately it does not seem to cause any issues on the device !
But why it hangs there ? , although , the times of 1000 10000 and 100000 were almost instant so let's do a little change if we are not hitting the time above the interval we need , let's not compound the operations in the kernel just calculate a ton of s*** and then pass it.
I don't think it matters (if it does and you know it let me know)
So we remove the += but now the problem is it will be serving the tanh value from its cache .... so .... lets turn this to an addition ... :P
"sum=tanh(of)+((double)iterations)/((double)100.0);"
this is the calc now , let's run again for 1 million iterations ... aaand yes there was a precision issue or something .
Now , let's inspect the times .
K[0] completed in (370644)microSeconds K[1] completed in (479982)microSeconds K[2] completed in (604963)microSeconds K[3] completed in (729959)microSeconds K[4] completed in (839271)microSeconds
theres definately a queue action going on here . Let's increase the kernels to 50.
stuck again . 19 completed 31 unknown . Okay we must see what the error is .
Added an error check on execution , no bueno . The issue is not there so it must be coming up on unknown if we assume it goes from submitted->queued->running->unknown or completed .
Let's see what the docs say about it :
Air , interesting ... 😊 okay . lets error gate the status too .
2023.05.02 22:14:21.458 blog_kernel_times_benchmark (USDJPY,H1) Unknown status for kernel(44) #5101 2023.05.02 22:14:21.458 blog_kernel_times_benchmark (USDJPY,H1) ----: unknown OpenCL error 65536
unknown error ...kay #5101 is .... internal error , okay very enlightening ...
That's telling us this will not work obviously so we won't be able to benchmark this way and in a way the "api" is correct as its asking us why on earth are we trying to do what its supposed to do itself .
I'll take a break here but i'll publish the blogs , them being incomplete (for now) may give someone an idea or two .
Im also attaching the 2 sources i used so far.
---- okay -----
I'm doing this wrong . I think the time test can occur with one kernel and multiple items .I overdid it a bit there so
What changes :
- We go back to the original idea .
- And we just slap a time measurement on the whole thing.

Because , what you read on this page is what the OpenCL wrapper does , so all we need to do is prod it or poke it or whatever you wanna call it until it folds .
We will be measuring how many work groups (which operate in one compute unit) it takes for the time measurement to fold once twice etc .
And in this case by "fold" we mean the opposite , like , when we observe there is an obvious increase in computation time we'll know the number we are sending in for processing means something , or , a threshold we just crossed means something .
Wouldn't it be easier if you could prod your GPU and ask it "Yo , how many cores do you have that i can use simultaneously , how many items do they get and how much memory is in there?" and it actually answered ? Yes it would be , you , mq , khronos and me have probably thought of this .
In my case i'm waiting to see when or where the 192cores and 32warp figures will pop up in the calculations .
So , the benchmark 2 will look like this :
We use the 1D
We still keep logging the group id ! to keep tabs on groups created
We'll increase the iterations per loop but try to not mess it up like earlier
<note , the previous attempt may be okay but there's things i'am not familiar with happening or something i neglected is breaking it>
Alright this will be our new kernel no ins and outs other than the group id :
string kernel="__kernel void memtests(__global int* group_id," "int iterations){" "float sum=(float)0.0;" "float inc=(float)-2.6;" "float step=(float)0.01;" "for(int i=0;i<iterations;i++){" "sum=((float)tanh(inc));" "inc+=step;" "if(inc>2.6&&step>0.0){step=-0.01;}" "if(inc<-2.6&&step<0.0){step=0.01;" "}" "group_id[get_global_id(0)]=get_group_id(0);}";
I hope the && applies there
scratch : local id , global id their arrays their buffers their handles the tangents too :
void OnTimer(){ EventKillTimer(); int ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); if(ctx!=INVALID_HANDLE){ string kernel="__kernel void memtests(__global int* group_id," "int iterations){" "float sum=(float)0.0;" "float inc=(float)-2.6;" "float step=(float)0.01;" "for(int i=0;i<iterations;i++){" "sum=((float)tanh(inc));" "inc+=step;" "if(inc>2.6&&step>0.0){step=-0.01;}" "if(inc<-2.6&&step<0.0){step=0.01;}" "}" "group_id[get_global_id(0)]=get_group_id(0);}"; string errors=""; int prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); int ker=CLKernelCreate(prg,"memtests"); if(ker!=INVALID_HANDLE){ int items=1;//262400; int iterations=1000; int group_ids[];ArrayResize(group_ids,items,0); ArrayFill(group_ids,0,items,0); int group_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); CLSetKernelArgMem(ker,0,group_id_handle); CLSetKernelArg(ker,1,iterations); uint offsets[]={0}; uint works[]={items}; long msStarted=GetTickCount(); CLExecute(ker,1,offsets,works); while(CLExecutionStatus(ker)!=CL_COMPLETE) { ENUM_OPENCL_EXECUTION_STATUS status=CLExecutionStatus(ker); Comment(EnumToString(status)); Sleep(10); } ENUM_OPENCL_EXECUTION_STATUS status=CLExecutionStatus(ker); Comment(EnumToString(status)); long msEnded=GetTickCount(); long msDiff=msEnded-msStarted; if(msEnded<msStarted){msDiff=UINT_MAX-msStarted+msEnded;} Print("Kernel finished"); CLBufferRead(group_id_handle,group_ids,0,0,items); //get number of groups int groups_created=group_ids[0]; for(int i=0;i<ArraySize(group_ids);i++){ if(group_ids[i]>groups_created){groups_created=group_ids[i];} } int f=FileOpen("OCL\\bench2.txt",FILE_WRITE|FILE_TXT); for(int i=0;i<items;i++){ FileWriteString(f,"GROUP.ID["+IntegerToString(i)+"]="+IntegerToString(group_ids[i])+"\n"); } FileClose(f); int compute_units=CLGetInfoInteger(ker,CL_DEVICE_MAX_COMPUTE_UNITS); int kernel_local_mem_size=CLGetInfoInteger(ker,CL_KERNEL_LOCAL_MEM_SIZE); int kernel_private_mem_size=CLGetInfoInteger(ker,CL_KERNEL_PRIVATE_MEM_SIZE); int kernel_work_group_size=CLGetInfoInteger(ker,CL_KERNEL_WORK_GROUP_SIZE); int device_max_work_group_size=CLGetInfoInteger(ctx,CL_DEVICE_MAX_WORK_GROUP_SIZE); Print("Kernel local mem ("+kernel_local_mem_size+")"); Print("Kernel private mem ("+kernel_private_mem_size+")"); Print("Kernel work group size ("+kernel_work_group_size+")"); Print("Device max work group size("+device_max_work_group_size+")"); Print("Device max compute units("+compute_units+")"); Print("------------------"); Print("Work Items ("+IntegerToString(items)+") Iterations("+IntegerToString(iterations)+")"); Print("Work Groups ("+IntegerToString(groups_created+1)+")"); Print("Milliseconds ("+IntegerToString(msDiff)+")"); CLKernelFree(ker); CLBufferFree(group_id_handle); }else{Print("Cannot create kernel");} CLProgramFree(prg); }else{Alert(errors);} CLContextFree(ctx); } else{ Print("Cannot create ctx"); } ExpertRemove(); }




")

![[iVISTscalp5]: A Laboratory for Market Behavior Research Through Time](https://c.mql5.com/6/1005/splash-preview-770124.jpg "[iVISTscalp5]: A Laboratory for Market Behavior Research Through Time")