Gibt es ein Muster in diesem Chaos? Lassen Sie uns versuchen, es zu finden! Maschinelles Lernen am Beispiel einer bestimmten Stichprobe. - Seite 18
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Der Zufallswert ist festgelegt :) Es scheint, dass dieser Seed auf eine knifflige Art und Weise berechnet wird, d.h. alle Prädiktoren, die für die Modellerstellung zulässig sind, sind wahrscheinlich beteiligt, und eine Änderung ihrer Anzahl ändert auch das Auswahlergebnis.
Der Startwert ist fest. Und bei jedem Aufruf der HSC wird eine neue Zahl ermittelt. Deshalb wird bei einer unterschiedlichen Anzahl von Prädiktoren und der Anzahl von DSTs nicht derselbe Prädiktor gewählt wie bei der vollen Anzahl von Prädiktoren.
Warum passt das, oder besser gesagt, woran sehen Sie das? Ich neige zu der Annahme, dass sich die Teststichprobe mehr von der Prüfung unterscheidet als die Prüfung vom Zug, d. h. es gibt unterschiedliche Wahrscheinlichkeitsverteilungen der Prädiktoren.
Nun, man nimmt die besten Prüfungsvarianten und hofft, dass sie auch im Test gut sind. Sie wählen die Prädiktoren auf der Grundlage der besten Prüfung aus. Aber sie sind nur für die Prüfung die besten.
Was ist die "err_"-Metrik?
err_ oob - Fehler auf OOB (Sie haben es Prüfung), err_trn - Fehler auf Zug. Durch die Formel erhalten wir einen gemeinsamen Fehler für beide Stichprobenorte.
Übrigens, in der Diskussion haben wir Test und Prüfung vertauscht. Ursprünglich hatten wir Zwischenprüfungen im Test und Endprüfungen in der Prüfung geplant. Aber der Kontext macht klar, was was ist, auch wenn sie die Namen geändert haben.
Die Startnummer ist fest vorgegeben. Bei jedem Aufruf des DST erscheint eine neue Zahl. Daher wird bei einer unterschiedlichen Anzahl von Prädiktoren und DSTs nicht auf denselben Prädiktor fallen wie bei voller Anzahl von Prädiktoren.
Nee, die Varianten werden dort reproduziert, wenn die zum Training verwendeten Prädiktoren in der gleichen Anzahl belassen werden.
Nun, man nimmt die besten Prüfungsvarianten, in der Hoffnung, dass sie im Test gut sind. Die Prädiktoren werden nach der besten Prüfung ausgewählt. Aber sie sind nur für die Prüfung die besten.
So kam es, dass diese Variante die ausgewogenste war - mit einem anständigen Gewinn bei Test und Prüfung. Unten im Bild ist das ursprünglich ausgewählte Modell - "Was" und das beste ausgewogene Modell nach 10k Training - "Became". Im Allgemeinen ist das Ergebnis besser, und es werden weniger Prädiktoren verwendet, so dass das Rauschen eliminiert wird. Und hier stellt sich die Frage, wie man dieses Rauschen vor dem Training vermeiden kann.
Die Logik sieht so aus, dass das Training beim Test aufhört, so dass dort eher ein positives Ergebnis zu erwarten ist als in der Stichprobe, die überhaupt nicht am Training teilnimmt, so dass die Betonung auf letzterem liegt.
err_ oob - Fehler bei OOB (Sie haben es geprüft), err_trn - Fehler bei trn. Durch die Formel erhalten wir einige Fehler, die für beide Stichproben gemeinsam sind.
Ich meine, ich weiß nicht, wie "err" gezählt wird - ist es Accuracy? Und warum Prüfung und nicht Test, denn bei dem grundlegenden Ansatz Prüfung werden wir nicht wissen.
Übrigens, wir haben in der Diskussion Test und Prüfung vertauscht. Ursprünglich war geplant, Zwischentests auf Test und Abschlusstests auf Klausur zu setzen. Aber durch den Kontext ist klar, was was ist, auch wenn sie die Namen geändert haben.
Ich habe nichts geändert (vielleicht habe ich mich irgendwo beschrieben?) - es ist einfach so, wie es ist - auf train - Ausbildung, test - Kontrolle der Beendigung der Ausbildung, und exam - Abschnitt, der nicht in irgendeine Art von Ausbildung eingebunden ist.
Ich bewerte nur die Wirksamkeit des Ansatzes durch den Durchschnitt aller Modelle, einschließlich des durchschnittlichen Gewinns - es ist wahrscheinlicher, als die Kanten mit einem guten Ergebnis erhalten werden.
Und dann ist da noch die Frage, wie man diesen Lärm vermeiden kann, bevor man mit dem Training beginnt.
Offensichtlich kann man das nicht. Das ist die Aufgabe, das Rauschen herauszufiltern und aus den richtigen Daten zu lernen.
Ich meine, dass ich nicht weiß, wie "err" betrachtet wird - ist es Accuracy?
Es ist ein Weg, um einen kombinierten/zusammengefassten Fehler in einem Training mit einem Test zu erhalten. Jede Art von Fehler kann summiert werden. Und (1-Genauigkeit) und RMS und AvgRel und AvgCE usw.
Ich habe nichts geändert(vielleicht habe ich mich irgendwo beschrieben?) - so ist es - auf Zug - Training, Test - Kontrolle der Beendigung des Trainings, und Prüfung - Abschnitt, der nicht an irgendeiner Art von Training beteiligt ist.
Auf den Bildern sah es für mich so aus, als ob Prüfung gleichbedeutend mit Test ist
Zum Beispiel hier.
Und in der obigen Tabelle sind die Prüfungsergebnisse besser als die Testergebnisse. Das ist sicherlich möglich, aber es sollte umgekehrt sein.
Offensichtlich nicht. Darin liegt die Herausforderung, das Rauschen zu durchbrechen und aus den richtigen Daten zu lernen.
Nein, es muss einen Weg geben, sonst ist alles nutzlos/zufällig.
Dies ist ein Weg, um den kombinierten/zusammengefassten Fehler in einem Training mit einem Test zu erhalten. Jede Art von Fehler kann summiert werden. Und (1-Genauigkeit) und RMS und AvgRel und AvgCE usw.
Verstanden, aber das funktioniert bei meinen Daten nicht - es sollte zumindest eine Korrelation geben :)
Aus den Bildern schien mir, dass exam den Test meinte
Zum Beispiel hier
Und in der Tabelle oben sind die Prüfungsergebnisse besser als der Test.
Ja, es stellt sich heraus, dass das Examen eher mehr Geld für Modellbauer bringt - ich verstehe die Situation selbst nicht ganz.
Leider ist mir jetzt aufgefallen, dass ich irgendwann die Gesamtstichprobe (Zeilen) verwechselt habe und jetzt sind die Beispiele von 2022 im Zug :(.
Ich werde alles neu machen - ich denke, ich werde das Ergebnis in ein paar Wochen haben - mal sehen, ob sich das Gesamtbild ändert.
Leider ist mir jetzt aufgefallen, dass ich irgendwann die Gesamtstichprobe (Zeilen) durcheinander gebracht habe, und jetzt enthält der Zug Beispiele aus dem Jahr 2022 :(
Ich werde es noch einmal machen - ich denke, ich werde das Ergebnis in ein paar Wochen haben - mal sehen, ob sich das Gesamtbild ändert.
Es macht keinen Unterschied, ob es durch eine Prüfung oder einen Test bewertet wurde. Die Hauptsache ist, dass die Bewertungsseite weder bei der Ausbildung noch bei der ersten Bewertung verwendet wurde.
2 Wochen. Ich bin erstaunt über Ihr Durchhaltevermögen. Ich ärgere mich auch über 3 Stunden Berechnungen..... Und ich habe insgesamt schon 5 Jahre mit MO verbracht, also ungefähr genauso viel wie du.
Kurzum, wir werden im Ruhestand etwas verdienen )))) Vielleicht.
Leider habe ich jetzt festgestellt, dass ich irgendwann die Gesamtstichprobe (Zeilen) vertauscht habe und der Zug nun mit Beispielen aus dem Jahr 2022 bestückt ist :(
Ich habe alles in 1 sequentielles Array geklebt. Und dann trenne ich die richtige Menge davon ab. Auf diese Weise gerät nichts durcheinander.
Es macht keinen Unterschied, ob sie durch eine Prüfung oder einen Test bewertet wurde. Die Hauptsache ist, dass die Bewertungsseite weder bei der Ausbildung noch bei der Erstbewertung verwendet wurde.
Ich frage mich, ob es besser ist, das Abschlusstraining wie bei Maxim durchzuführen - also eine prähistorische Stichprobe zur Kontrolle zu nehmen - oder ob es besser ist, die gesamte verfügbare Stichprobe zu nehmen und die Anzahl der Bäume zu begrenzen, wie es im Durchschnitt bei den besten Modellen der Fall ist.
2 Wochen... Ich bin erstaunt über dein Durchhaltevermögen. Ich finde 3 Stunden Berechnungen auch lästig..... Und habe insgesamt schon 5 Jahre mit MO verbracht, etwa so viel wie du.
Natürlich will man immer schneller zu Ergebnissen kommen. Ich versuche, die Hardware so zu belasten, dass meine Berechnungen nicht mit anderen Dingen kollidieren - ich benutze oft nicht den Hauptarbeitsrechner. Parallel dazu kann ich andere Ideen in Code umsetzen - ich komme schneller auf Ideen, als ich Zeit habe, sie im Code zu überprüfen.
Kurzum, wir werden im Ruhestand etwas verdienen )))) Vielleicht.
Ich stimme zu - die Aussicht ist traurig. Wenn ich keine Fortschritte in meiner Forschung sehen würde, wenn auch nur langsam, hätte ich die Arbeit wahrscheinlich schon beendet.
Ich habe alles in eine sequentielle Anordnung geklebt. Und dann trenne ich aus dieser Anordnung die richtige Menge heraus. Auf diese Weise gerät nichts durcheinander.
Ja, ich konvertierte die Probe in eine binäre Datei, und in dem Skript habe ich ein Kontrollkästchen aus Versehen, offenbar, verantwortlich für das Mischen der Probe - so ist es kein Problem, und CatBoost erfordert 3 separate Proben - sie haben nicht die Auswahl auf den Bereich der Zeilen, obwohl sie eine eingebaute Kreuzvalidierung haben.
Ich frage mich auch, ob es besser ist, das abschließende Training wie Maxim durchzuführen - indem man eine prähistorische Stichprobe zur Kontrolle nimmt - oder ob es besser ist, die gesamte verfügbare Stichprobe zu nehmen und die Anzahl der Bäume zu begrenzen, wie es im Durchschnitt bei den besten Modellen der Fall ist.
Für mich sind Pre-Training und Tests eine Gelegenheit, die im Durchschnitt besten Hyperparameter (Anzahl der Bäume usw.) und Prädiktoren auszuwählen. Und auch ohne Test kann man sie im Training trainieren und sofort in den Handel einsteigen.
Die Idee des prähistorischen Samplings wird funktionieren, wenn sich die Muster nicht ändern, vielleicht. Aber es besteht ein Risiko, dass sie sich ändern. Daher ziehe ich es vor, kein Risiko einzugehen und auf zukünftige Stichproben zu setzen.
Eine andere Frage ist, wie lange diese prähistorische Stichprobe zurückliegt: sechs Monate oder 15 Jahre? Vor sechs Monaten könnte es funktionieren, aber der Markt vor 15 Jahren ist nicht derselbe wie heute. Aber das ist nicht sicher. Vielleicht gibt es Muster, die schon seit Jahrzehnten funktionieren.Ich werde die Ergebnisse beschreiben, die mit demselben Algorithmus erzielt wurden, den ich hier beschrieben habe, aber mit unvermischter Stichprobe, d. h. in chronologischer Reihenfolge.
Das Einzige, was ich geändert habe, ist, dass das Training von 10000 Modellen nicht mehr auf der gesamten Stichprobe mit den ausgeschlossenen Prädiktoren durchgeführt wurde, sondern auf einer neu gebildeten Stichprobe, in der die Spalten mit den ausgeschlossenen Prädiktoren entfernt wurden, was den Trainingsprozess beschleunigt hat (offensichtlich dauert das Pumpen einer großen Datei sehr lange). Dank dieser Änderungen war ich in der Lage, durchgängig 6 Schritte des Prädiktoren-Screenings durchzuführen.
Abbildung 1: Histogramm des Gewinns bei der Stichprobenprüfung nach dem Training von 100 Modellen auf alle Prädiktoren der Stichprobe.
Abbildung 2: Histogramm des Gewinns bei der Prüfungsstichprobe nach dem Training von 10k Modellen auf ausgewählte Prädiktoren der Stichprobe - Schritt 1.
Abbildung3: Histogramm des Gewinns bei der Prüfungsstichprobe nach dem Training von 10k Modellen mit ausgewählten Stichprobenprädiktoren - Schritt 2.
Abbildung 4: Histogramm der Gewinne für die Prüfungsstichprobe nach dem Training von 10k Modellen auf ausgewählten Stichprobenprädiktoren - Schritt 3.
Abbildung 5: Histogramm der Gewinne für die Prüfungsstichprobe nach dem Training von 10k Modellen für ausgewählte Stichprobenprädiktoren - Schritt 4.
Abbildung 6: Gewinnhistogramm für die Prüfungsstichprobe nach dem Training von 10k Modellen mit ausgewählten Stichprobenprädiktoren - Schritt 5.
Abbildung 7: Gewinnhistogramm für die Prüfungsstichprobe nach dem Training von 10k Modellen auf ausgewählten Stichprobenprädiktoren - Schritt 6.
Abbildung 8: Tabelle mit den Merkmalen der Modelle, die ausgewählt wurden, um nachfolgende Stichproben mit einer abnehmenden Anzahl von Prädiktoren (Merkmalen) zu bilden.
Betrachten wir das Modell mit den folgenden Merkmalen, das im sechsten Schritt der Prädiktorenauswahl erhalten wurde.
Abbildung 9: Merkmale des Modells.
Abbildung 10. Visualisierung des Modells über die Stichprobenprüfung als Verteilung der Klassifizierungswahrscheinlichkeit - x-Achse - vom Modell ermittelte Wahrscheinlichkeiten und y - Prozentsatz aller Stichproben.
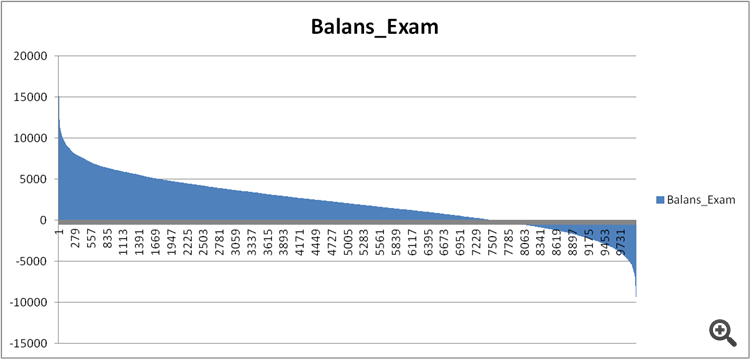
Abbildung 11. Gleichgewicht des Modells auf der Prüfungsstichprobe.
Vergleichen wir nun die Prädiktoren in den einigermaßen guten und den extrem schlechten Modellen, die in Schritt 6 der Prädiktorenauswahl ermittelt wurden.
Abbildung 12. Vergleich der Merkmale der Modelle.
Können wir nun sehen, welche Prädiktoren sich so schlecht auf das finanzielle Ergebnis auswirken und die Ausbildung verderben?
Abbildung 13. Gewichtung der Prädiktoren in den beiden Modellen.
Abbildung 13 zeigt, dass fast alle verfügbaren Prädiktoren verwendet werden, außer einem, aber ich bezweifle, dass dies die Ursache des Problems ist. Es geht also nicht so sehr um die Verwendung, sondern eher um die Reihenfolge der Verwendung bei der Erstellung des Modells?
Ich habe zwei Tabellen miteinander verglichen, wobei ich anstelle eines Index eine Ordnungszahl für die Signifikanz zugewiesen habe, und habe gesehen, wie unterschiedlich diese Signifikanz in den Modellen eingestuft wird.
Abbildung 14: Tabelle zum Vergleich der Signifikanz (Verwendung) der Prädiktoren in den beiden Modellen.
Brunnen und Histogramm zur besseren Veranschaulichung - Abweichungen im Minus bedeuten, dass der Prädiktor des zweiten (unrentablen) Modells später verwendet wurde, und Plus - früher.
Abbildung 15. Abweichungen der Signifikanz der Prädiktoren in den Modellen.
Es ist zu erkennen, dass es starke Abweichungen gibt. Vielleicht ist das der Fall, aber wie kann man das herausfinden/beweisen? Vielleicht ist ein komplexer Ansatz für den Vergleich der Modelle mit der Benchmark erforderlich - hat jemand eine Idee?
Gibt es eine Art Confounding-Index zur Beschreibung der Gesamtverzerrung, vielleicht unter Berücksichtigung der Signifikanz der Prädiktoren für das erste Modell - d. h. mit einem abnehmenden Koeffizienten?
Welche Schlussfolgerungen können gezogen werden?
Meine Vermutung ist die folgende:
1. Die Ergebnisse waren in der vergangenen Stichprobe viel besser. Ich nehme an, dass dies auf die Informationen zurückzuführen ist, die durch die Vermischung der Chronologie der Stichprobe über Ereignisse aus der Zukunft "durchsickerten". Die Frage ist, ob die Modelle mit einer durcheinandergewürfelten Stichprobe oder einer normalen Stichprobe stabiler sein werden.
2. Es ist notwendig, eine Struktur der Signifikanz der Prädiktoren für ihre weitere Anwendung in den Modellen aufzubauen, d.h. neben den Zahlen ist es notwendig, eine Logik festzulegen, sonst ist die Streuung der Ergebnisse der Modelle selbst bei einer kleinen Anzahl von Prädiktoren zu groß.