Neuronale Netze. Fragen an die Experten. - Seite 5
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Einverstanden. Das ist es, was ich wissen wollte: Wie ist das Verhältnis zwischen Fehler und Gewinn, vorzugsweise auf OOS....))
Zu joo sagten Sie, dass das nichtige Ergebnis auf eine Datennormalisierung zurückzuführen sein könnte, worauf ich antwortete, dass es keine gibt.
Ich stimme Leo zu, dass es nicht immer das Fehlerkriterium ist, das den endgültigen Gewinn bestimmt, aber bei der Aufgabe, die ich jetzt vor mir habe, ist es der Fehler, der zählt. Ich werde die Vorhersage des Netzes heute Abend veröffentlichen, um die Meinung anderer über die Qualität der Vorhersage und mögliche Verbesserungen einzuholen)
Хорошо, чуть позже (часа через 2-3), попробую обоснованно показать, каким образом профит (или что то другое, не важно, что мы хотим получить от сети) зависит от фитнес функции.
А гарантию того, что мы получим профит в будующем, конечно, никто дать никогда не сможет. А вот к чему стремится должна сетка, пожалуй, мы должны определять для неё однозначно.
Sie brauchen Ihre Zeit nicht zu verschwenden, denn der Unterschied zwischen "wollen" und "bekommen" ist überhaupt nicht philosophisch, auch wenn er in den philosophischen Begriffen "subjektiv" und "objektiv" formuliert ist.
Die Tatsache, dass die Ergebnisse der Anpassung umgekehrt proportional zum quadratischen Fehler sind, wissen wir auch ohne Sie.
Unzweifelhaft muss das Netz auf einen Gewinn aus dem OOS abzielen. Sonst hat es keinen Sinn.
То, что результаты на подгонке обратно пропорциональны среднеквадратичной ошибке - это мы и без Вас знаем.
Verwenden Sie auch den mittleren quadratischen Fehler (Root Mean Square Error)? Sie sind der Vater der emc-Vernetzung. :)
Reschetow schrieb(a) >>
Das Netz muss auf jeden Fall einen Gewinn aus dem OOS anstreben. Sonst hat es keinen Sinn.
Das ist verständlich. Eine andere Frage ist, wie sie sich darum bemühen sollte.
Вы тоже что ли используете среднеквадратичную ошибку? Отец эмкуэльных сетей Вы наш. :)
Это и ежу понятно. Другой вопрос, как она должна к этому стремится.
Ich verwende den mittleren quadratischen Fehler nicht für den Handel, da er nur die Qualität der Anpassung charakterisiert.
Daher sollte der Fehler in der Stichprobe in keiner Weise dazu tendieren
Wie versprochen, poste ich ein Bild und eine Erklärung dazu. Netzwerk: MLP mit einer versteckten Schicht. 2000 Punkte in der Ausbildung. 1000 auf dem Probenehmer) erhielt ich Strom und vor der EMA vom ersten Bild und vor dem Schließen vom ersten und zweiten Bild. Das ist alles! Warum alles und so wenig? Denn die Erhöhung der Anzahl der Neuronen, Schichten, Eingänge usw. hat keinerlei Einfluss auf das Ergebnis. Das ist es, was mir Angst macht.) Und was als Vorhersage gezeigt wird, kann man, na ja, eine sehr einfache Formel, die von Hand berechnet wird. Warum ist das für mich so unklar. Was sollte ich ändern? Kann man es besser machen?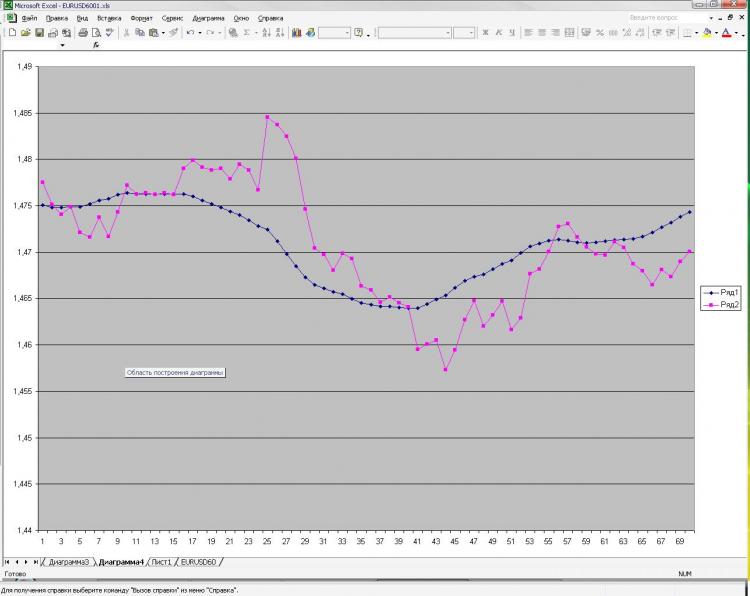
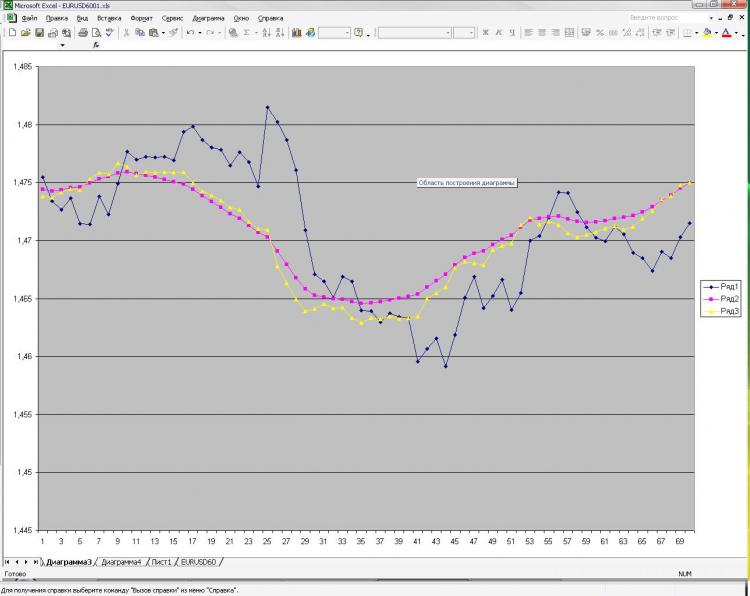
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?
Sie haben das Problem der Angleichung beschrieben. Zwei "Referenzpunkte" reichen nicht aus, um die Form zu beschreiben. Dazu liefern Sie jeweils einen weiteren Stützpunkt, der nicht nur die Krümmung, sondern auch eine gerade Linie beschreibt. Versuchen Sie mindestens 3 Punkte aus jedem Satz von Eingabeparametern. D.h. drei EMA-Punkte und drei Klauselpunkte, also 6 Eingangsneuronen, mit 6 bis 12 Neuronen in der versteckten Schicht. Eine größere Anzahl von Neuronen in der versteckten Schicht ist für dieses Problem nicht sinnvoll.
Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
Geben Sie mir hier ein Beispiel, ich werde es in Statistica ausprobieren