Bayes'sche Regression - Hat jemand einen EA mit diesem Algorithmus erstellt? - Seite 40
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Und ich möchte mich immer wieder mit dem Thema der vermeintlich normalverteilten inkrementellen Zitate beschäftigen.
Wenn jemand dafür ist, werde ich Argumente nennen, warum dieser Prozess nicht normal sein kann. Und diese Argumente werden für jeden verständlich sein und gleichzeitig mit den CPT übereinstimmen. Und diese Argumente sind so trivial, dass es keinen Zweifel geben sollte.
Und was wird die Wahrscheinlichkeit ausdrücken, die Prognose für den nächsten Balken oder den Bewegungsvektor der nächsten Balken?
Die Wahrscheinlichkeit gibt die Vorhersage für den nächsten Tick (Inkrement) an. Ich möchte es einfach:
- die Werte der zukünftigen Ybayes-Ticks berechnen, für die die Wahrscheinlichkeit nach der Bayes-Formel maximal ist.
- Vergleichen Sie Ybayes mit den tatsächlich eingehenden Yreal-Zecken. Erfassen und verarbeiten Sie die Statistiken.
Wenn die Differenz der Werte in einem vernünftigen Bereich liegt, werde ich den Code veröffentlichen und fragen, was als nächstes zu tun ist. Regression? Vektor? Skalpieren?
Die Wahrscheinlichkeit drückt die Vorhersage des nächsten Ticks (Inkrement) aus. Ich möchte es einfach:
Warum auf Zecken heruntergehen? Sie können lernen, die Richtung der Ticks in 5 Minuten mit einer Genauigkeit von 70 % vorherzusagen, aber 100 Ticks im Voraus wissen Sie, dass die Genauigkeit abnehmen wird.
Versuchen Sie es in Schritten von einer halben oder einer Stunde im Voraus. Das ist auch für mich interessant, vielleicht kann ich in irgendeiner Weise helfen.
Die Wahrscheinlichkeit drückt die Vorhersage des nächsten Ticks (Inkrement) aus. Ich möchte es einfach:
- die Werte der zukünftigen Ybayes-Ticks berechnen, für die die Wahrscheinlichkeit nach der Bayes-Formel maximal ist.
- Vergleichen Sie Ybayes mit den tatsächlich eingehenden Yreal-Zecken. Erfassen und verarbeiten Sie die Statistiken.
Wenn die Differenz der Werte in einem vernünftigen Bereich liegt, werde ich den Code posten und fragen, was als Nächstes zu tun ist. Regression? Vektor? Kurve? Skalpieren?
Was ist falsch an ARIMA? In Paketen wird die Anzahl der Diffs (Inkremente von Inkrementen) automatisch in Abhängigkeit vom Eingabestrom berechnet. Viele Feinheiten im Zusammenhang mit der Stationarität sind in dem Paket versteckt.
Wenn Sie wirklich so tief gehen wollen, dann etwas ARCH?
Ich habe es einmal versucht. Das Problem ist folgendes. Der Zuwachs kann leicht berechnet werden. Wenn wir jedoch das Konfidenzintervall dieses Inkrements zum Inkrement selbst addieren, wird es entweder KAUFEN oder VERKAUFEN lauten, da der vorherige Kurswert innerhalb des Konfidenzintervalls liegt.
Ja, der klassische Ansatz ist, wie SanSanych schreibt, Datenanalyse, Datenanforderungen und Systemfehler.
Aber in diesem Thema geht es um Bayes, und ich versuche, in Bayes'schen Begriffen zu denken, wie der Soldat im Schützengraben, der die nachträgliche (nach der Erfahrung) Wahrscheinlichkeit berechnet. Ich habe oben ein Beispiel für einen Soldaten genannt.
Eine der wichtigsten Fragen ist, was als A-priori-Wahrscheinlichkeit zu betrachten ist. Mit anderen Worten: Wen sollen wir hinter den Vorhang der Zukunft, rechts von der Nullleiste, stellen? Gauß? Laplace? Wiener? Was schreiben professionelle Mathematiker hier (für mich ein dunkler "Wald")?
Ich habe mich für Gauß entschieden, weil ich eine Vorstellung von der Normalverteilung habe und an sie glaube. Wenn es nicht "schießt", dann ist es möglich, andere Gesetze zu nehmen und Gauß anstelle der Bayes-Formel zu ersetzen, oder zusammen mit Gauß als Produkt zweier Wahrscheinlichkeiten. Versuchen Sie, ein Bayes'sches Netz zu erstellen, wenn ich es richtig verstehe.
Natürlich schaffe ich das nicht allein. Ich möchte das Problem mit Gauß lösen, das ich unter dem Strauß formuliert habe. Wenn jemand bereit ist, sich mir auf freiwilliger Basis anzuschließen, dann bitte. Hier ist ein tatsächliches Problem.
Gegeben: МТ4 Generator für Zufallszahlen.
Bedarf: Schreiben Sie MQL4-Code als Funktion FP(), die MT4[]-Array, das durch den Standard-RNG gebildet wird, in ND[]-Array mit Normalverteilung umwandelt.
Vasily (ich kenne meinen Vatersnamen nicht) Sokolov zeigte mir die Transformationsformeln unter https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
Der Altruismus und die Freundlichkeit wird eine grafische Darstellung der Ergebnisse sein, obwohl ich die Charts der berechneten Arrays direkt im MT4-Fenster zoomen kann. Ich habe es in meinen Projekten getan.
Ich verstehe, dass viele Leute hier dieses Problem mit ein paar Klicks in Mathepaketen lösen können, aber ich möchte in einer Sprache sprechen, die von Händlern, Programmierern, Wirtschaftswissenschaftlern und Philosophen allgemein verstanden wird: MQL4.
Ja, der klassische Ansatz ist, wie SanSanych schreibt, Datenanalyse, Datenanforderungen und Systemfehler.
Aber in diesem Thema geht es um Bayes, und ich versuche, in Bayes'schen Begriffen zu denken, wie der Soldat im Schützengraben, der die nachträgliche (nach der Erfahrung) Wahrscheinlichkeit berechnet. Ich habe oben ein Beispiel für einen Soldaten genannt.
Eine der wichtigsten Fragen ist, was als A-priori-Wahrscheinlichkeit zu betrachten ist. Mit anderen Worten: Wen sollen wir hinter den Vorhang der Zukunft, rechts von der Nullleiste, stellen? Gauß? Laplace? Wiener? Was schreiben professionelle Mathematiker hier (für mich ein dunkler "Wald")?
Ich wähle Gauß, weil ich eine Vorstellung von der Normalverteilung habe und an sie glaube. Wenn es nicht "schießt", dann ist es möglich, andere Gesetze zu nehmen und Gauß anstelle der Bayes-Formel zu ersetzen, oder zusammen mit Gauß als Produkt zweier Wahrscheinlichkeiten. Versuchen Sie, ein Bayes'sches Netz zu erstellen, wenn ich es richtig verstehe.
Natürlich schaffe ich das nicht allein. Ich möchte das Problem mit Gauß lösen, das ich unter dem Strauß formuliert habe. Wenn jemand bereit ist, sich mir auf freiwilliger Basis anzuschließen, dann bitte. Hier ist ein tatsächliches Problem.
Gegeben: МТ4 Generator für Zufallszahlen.
Bedarf: Schreiben Sie MQL4-Code als Funktion FP(), die MT4[]-Array, das durch den Standard-RNG gebildet wird, in ND[]-Array mit Normalverteilung umwandelt.
Vasily (ich kenne meinen Vatersnamen nicht) Sokolov zeigte mir die Transformationsformeln unter https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
Allerdings kann ich und ich kann Charts von berechneten Arrays direkt im MT4-Fenster skalieren. Ich habe es in meinen Projekten getan.
Ich verstehe, dass viele Händler dieses Problem mit ein paar Klicks mit mathematischen Paketen lösen können, aber ich möchte die MQL4-Sprache verwenden, die für Händler, Programmierer, Ökonomen und Philosophen allgemein zugänglich ist.
Hier ist ein Generator mit verschiedenen Verteilungen, einschließlich der Normalverteilung:
https://www.mql5.com/ru/articles/273
Kurze Verteilungsanalyse in R:
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189Wir schätzten die Parameter der Normalverteilung anhand der verfügbaren Eröffnungskursinkremente der Clock-Bars und zeichneten sie auf, um die Häufigkeit und Dichte für die ursprüngliche Reihe und die Normalreihe mit denselben Verteilungen zu vergleichen. Wie Sie selbst mit bloßem Auge sehen können, ist die ursprüngliche Reihe von Inkrementen von Stundenbalken weit davon entfernt, normal zu sein.
Übrigens befinden wir uns nicht in einem Tempel Gottes. Es ist nicht notwendig und sogar schädlich zu glauben.
Hier ist eine merkwürdige Zeile aus dem obigen Beitrag, die das widerspiegelt, was ich oben geschrieben habe
-2,515e-02 -6,800e-04 0,000e+00 -3,400e-076,900e-04 6,849e-02
Soweit ich es verstanden habe, sind 50% aller Inkremente auf der Uhr kleiner als 7 Pips! Und die anständigeren Zuwächse befinden sich in den dicken Schwänzen, d.h. auf der anderen Seite von Gut und Böse.
Wie wird die TS also aussehen? Das ist das Problem, nicht der Bayesianer und andere, andere, andere....
Oder sollte es anders verstanden werden?
Hier ist eine merkwürdige Zeile aus dem obigen Beitrag, die das widerspiegelt, was ich oben geschrieben habe
-2,515e-02 -6,800e-04 0,000e+00 -3,400e-076,900e-04 6,849e-02
Soweit ich das in den Quadranten verstanden habe, sind 50 % aller Inkremente auf dem Stundentag weniger als 7 Pips! Und die anständigeren Zuwächse befinden sich in den dicken Schwänzen, d.h. auf der anderen Seite von Gut und Böse.
Wie wird die TS also aussehen? Das ist das Problem, nicht der Bayesianer und andere, andere, andere....
Oder sollte es anders verstanden werden?
SanSanych, ja!
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')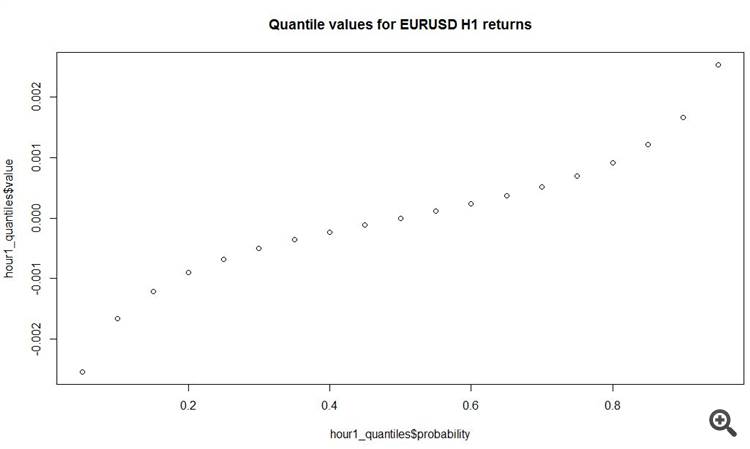
Interessant ist auch, dass der durchschnittliche absolute Zuwachs auf stündlichen Bars 11 Pips beträgt! Insgesamt.
Du wirst es lange machen müssen, denn du brauchst Rückverwandlung und... Und das gefällt Box-Cox gar nicht)))) Es ist nur schade, dass Sie nicht die Möglichkeit haben
Es ist nur schade, dass es keinen großen Einfluss auf das Endergebnis hat, wenn man keine normalen Prädiktoren hat...