OpenCL: interne Implementierungstests in MQL5 - Seite 29
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
...
--
Machen Sie 512 und sehen Sie, was Sie bekommen. Haben Sie keine Angst, das Programm zu knacken, es wird dadurch nur noch besser. :) Wenn Sie es getan haben, posten Sie es hier.
OK! Bei 512 Durchgängen und 144000 Takten:
Na ja, und wenn 60 optimal ist, dann ist das im Allgemeinen in Ordnung:
//---
Das heißt, auf dem schwächsten Laptop, der in diesem Thread vorgestellt wurde, ist dies das Ergebnis. Das ist sehr vielversprechend.
//---
Leider bin ich nicht in der Lage, das Thema frei zu diskutieren, da ich mich noch nicht einmal mit dem Joo-Artikel und den neuronalen Netzen beschäftigt habe, während ich mich nie mit OpenCL beschäftigt habe. Ich kann diesen oder jenen Code nicht verwenden, ohne jede einzelne Zeile des Codes zu verstehen. Ich möchte alles wissen. ))) Ich arbeite noch an der Engine des Handelsprogramms. Es gibt so viel zu tun, dass mir schon jetzt der Kopf schwirrt. )))
Ich habe die Anzahl der Balken um den Faktor 30 erhöht (auf 4.320.000) und beschlossen, die Belastbarkeit des Steins zu überprüfen.
Das macht nichts: Es funktioniert, es wird warm, aber es schwitzt nicht zu sehr. Die Temperatur steigt langsam an, hat aber bereits die Sättigung erreicht.
Die rote Linie ist die Temperatur, die grüne Linie ist die Belastung der Kerne.
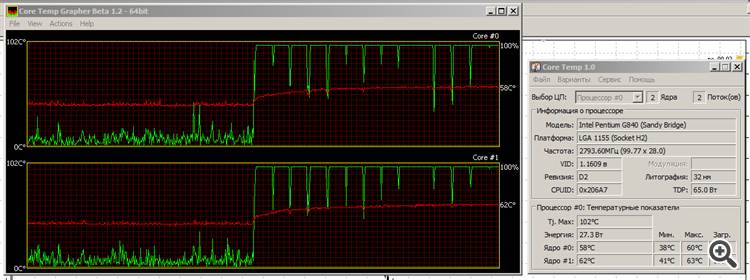
Deshalb liebe ich Intels Sandy Bridge-Exemplar: Es ist "grün". Ja, die Grafik ist nicht großartig, aber wir werden sehen, was aus Ivy Bridge wird......
Deshalb liebe ich Intels Sandy Bridge-Modell: Es ist "grün". Ja, die Grafik ist nicht toll, aber wir werden sehen, was aus Ivy Bridge wird...Oh. (kichert) Das ist ein echter Stresstest. :) Meiner wäre jetzt wahrscheinlich schon tot.
Dann ein Haswell und etwas später ein Rockwell... )))
Ein Beispiel für eine Barnsley-Farn-Implementierung in OpenCL.
Die Berechnung basiert auf dem Chaos-Game-Algorithmus(Beispiel) und verwendet einen Zufallszahlengenerator mit einer Generierungsbasis, die von der Thread-ID abhängt und get_global_id(0) zurückgibt, um eindeutige Trajektorien zu erstellen.
Bei der Skalierung steigt die Anzahl der Punkte, die zur Aufrechterhaltung der Bildqualität erforderlich sind, quadratisch an. Daher geht diese Implementierung davon aus, dass jede Kernelinstanz eine feste Anzahl von Punkten zeichnet, die in den sichtbaren Bereich fallen.
Die Anzahl der geschätzten Fäden wird in Zeile 191 angegeben:
die Anzahl der Punkte steht in Zeile 233:
UPD
IFS-fern.mq5 - CPU analog
Bei Maßstab=1000:
Ich habe drei Schichten von 16x7x3 Neuronen gemacht. Eigentlich habe ich es vorgestern gemacht, heute debuggt. Davor passten die Ergebnisse nicht, wenn ich sie mit der CPU überprüfte - ich werde hier nicht die Gründe beschreiben, warum, zumindest nicht jetzt - ich bin zu müde. :)
Zeitliche Merkmale :
Morgen werde ich einen Optimierer für dieses Gitter erstellen. Dann werde ich mich damit beschäftigen, reale Daten zu laden und den Tester mit realistischen Berechnungen, die mit dem MT5-Tester überprüfbar sind, fertigzustellen. Dann werde ich mich mit dem Generator MLP+cl-Codes von Gittern für deren Optimierung beschäftigen.
Ich veröffentliche den Quellcode nicht, weil ich gierig bin, aber ex5 ist für diejenigen enthalten, die es auf ihrer Hardware testen möchten.
Ich bin so stabil, wie ich es unter Putin war:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
Übrigens, Achtung: Bei der CPU-Laufzeit ist der Unterschied zwischen Ihrem System und meinem (basierend auf einem Pentium G840) nicht so groß.
Ist Ihr RAM schnell? Ich habe 1333 MHz.
Und noch etwas: Es ist interessant, dass beide Kerne der CPU während der Berechnungen belastet werden. Der starke Belastungsabfall am Ende liegt nach dem Ende der Berechnungen. Was würde das bedeuten?
Ich bin so stabil wie unter Putin:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
1. übrigens, beachten Sie den Unterschied zwischen Ihrem System und meinem (Pentium G840-basiert) in der CPU-Ausführungszeit.
2. ist Ihr RAM schnell? Ich habe 1333 MHz.
1. ich habe in meiner Freizeit meine Übertaktung wiederhergestellt. Ich hatte einmal einen wirklich schlimmen Absturz (ich fand später heraus, dass sich das Netzkabel der Festplatte aus dem Steckplatz gelöst hatte), also drückte ich auf der Suche nach einem Wunder die "MemoryOK"-Taste auf dem Motherboard. Danach funktionierte er immer noch nicht, nur die CMOS-Einstellungen wurden auf die Standardwerte zurückgesetzt. Jetzt habe ich den Prozessor wieder auf 3840 MHz übertaktet, also funktioniert er jetzt besser.
2. Ich kann es immer noch nicht herausfinden. :) Insbesondere der Benchmark, zu dem Renat den Link gezeigt hat, zeigt 1600MHz. Das Windows zeigt sogar 1033MHz an :)))), trotz der Tatsache, dass der Speicher selbst 2GHz ist, aber meine Mutter kann bis zu 1866 (bildlich) ziehen.
Eine weitere Sache: Es ist interessant, dass ich beide Kerne belastet habe, wenn ich auf der CPU rechne. Der starke Belastungsabfall am Ende liegt nach dem Ende der Berechnungen. Was würde das bedeuten?
Vielleicht liegt es also gar nicht an der GPU? Der Treiber läuft, aber... Meine einzige Erklärung ist, dass die Berechnung auf CPU-OpenCL durchgeführt wird, natürlich nur auf allen verfügbaren Kernen und unter Verwendung von SSE-Vektorbefehlen. :)
Ich weiß nicht, wie diese (CPU-LPU) Unterstützung durch den Treiber implementiert ist, aber prinzipiell schließe ich auch eine solche Variante des opentzl-Verarbeitungsstarts nicht aus.
Dies ist allenfalls eine Spekulation von mir. Oder wie es jetzt in Mode ist - "IMHO" zu schreiben. ;)
Das bezweifle ich. Vor allem, weil ich nur zwei Kerne habe. Woher kommt dann der 25-fache Gewinn?
Wenn Sie Intel Math Kernel Library oder Intel Performance Primitives haben (ich habe sie nicht heruntergeladen), ist es möglich... in einigen Fällen. Aber das ist unwahrscheinlich, denn sie wiegen Hunderte von Meg.
Ich muss abwarten, was Google dazu zu sagen hat.
Mathematik: Interessanterweise sind bei meinen CPU-Berechnungen auch beide Kerne belastet.
Nein, ich meinte reine CPU-Berechnungen ohne OpenCL. Die Last liegt knapp unter 100 %, wobei jeder Kern vergleichbare Lastwerte aufweist. Bei der Ausführung von OpenCL-Code steigt sie jedoch auf 100 % an, was sich leicht durch den GPU-Betrieb erklären lässt.