
Машинное обучение в торговых системах на сетке и мартингейле. Есть ли рыба?

Введение
Мы уже изрядно потрудились и исследовали различные подходы применения машинного обучения для поиска закономерностей на валютном рынке. Вы уже имеете представление как обучать модели и внедрять их в продакшн. Но существует большое количество подходов к торговле, и практически каждый можно улучшить за счет современных алгоритмов машинного обучения. Одними из самых популярных является сетка и/или мартингейл. Перед написанием статьи я провел небольшой разведочный анализ на предмет присутствия в интернете информации на эту тему. К моему удивлению, такой подход по каким-то причинам совершенно не затронут в глобальной сети. Также на мои вопросы участникам комьюнити о перспективности такого решения большинство ответило, что они даже не представляют, как подойти к этой теме, но сама идея вызывает интерес. Хотя, казалось бы, ничего сложного в этом нет.
Давайте проведем ряд экспериментов для собственного успокоения чтобы, во-первых, доказать, что это не так сложно, как может показаться на первый взгляд. И во-вторых, чтобы выяснить, применим ли такой подход и является ли он эффективным.
Разметка сделок
Основной задачей является правильная разметка сделок. Давайте вспомним, как это делалось для одиночных позиций в предыдущих статьях. Задавался случайный или детерминированный горизонт сделок, например, 15 баров. Если рынок вырос за эти 15 баров, то сделка размечалась на покупку, наоборот — на продажу. С сеткой ордеров логика будет аналогичной, но следует учесть совокупную прибыль\убыток по группе открытых позиций. Это можно проиллюстрировать на простом примере. Автор статьи рисовал как мог, поэтому просьба не пинать за это.
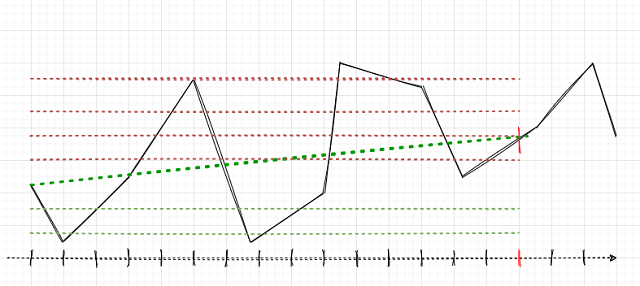
Предположим, что горизонт сделки равен 15 (пятнадцати) барам (отмечен вертикальным красным штрихом на условной шкале времени). Если используется одиночная позиция, то она будет размечена на покупку (наклонная зеленая штрих-пунктирная линия), поскольку от точки до точки рынок вырос. Рынок — это черная ломанная кривая, если кто-то не понял.
При такой разметке не будут учитываться промежуточные колебания рынка. Если применить сетку ордеров (красные и зеленые горизонтальные линии), то следует посчитать совокупную прибыль по всем сработавшим отложенным ордерам плюс ордер, открытый в самом начале (можно открыть одну позицию сразу и разместить сетку в том же направлении, но можно не открывать позицию и ограничиться только сеткой отложенных ордеров). Такая разметка будет продолжаться в скользящем окне на всю глубину истории обучения, а задачей МО (машинного обучения) является обобщение всего разнообразия ситуаций и эффективное предсказание на новых данных (если это возможно).
В таком случае может быть несколько вариантов выбора направления торговли и разметки данных, выбор одного из них является философской и экспериментальной задачей одновременно.
- Выбор по максимальной совокупной прибыли. Если сетка на продажу дает больше прибыли, то размечается именно она.
- Взвешенный выбор между количеством открытых ордеров и совокупной прибылью. Если средняя прибыль на каждый открытый ордер сетки выше, чем при противоположной стороне, то выбирается именно эта сторона.
- Выбор по максимальному количеству сработавших ордеров. Поскольку мы хотим, чтобы робот торговал именно сетку, то резонно остановиться на таком подходе. Если количество сработавших ордеров максимально и совокупная позиция в прибыли, то выбирается эта сторона. Под стороной здесь подразумевается направление сетки (продажа или покупка).
Пожалуй, для начала достаточно этих трех критериев. Я бы хотел остановиться на первом, поскольку он наиболее простой и нацелен на максимальную прибыль.
Разметка сделок в коде
Давайте теперь вспомним, как происходила разметка сделок в предыдущих статьях.
def add_labels(dataset, min, max): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if future_pr + MARKUP < curr_pr: labels.append(1.0) elif future_pr - MARKUP > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index).reset_index(drop=True) return dataset
Этот код необходимо обобщить на случай обычной сетки и сетки с применением мартингейла. Замечательной особенностью будет являться то, что можно исследовать сетки с различным количеством ордеров, с различными расстояниями между ордерами и даже применять мартингейл (увеличение лота).
Для этого добавим глобальные переменные, которые можно будет перебирать и оптимизировать впоследствии.
GRID_SIZE = 10 GRID_DISTANCES = np.full(GRID_SIZE, 0.00200) GRID_COEFFICIENTS = np.linspace(1, 3, num= GRID_SIZE)
Переменная GRID_SIZE содержит количество ордеров в обе стороны.
Переменная GRID_DISTANCES задает расстояние между ордерами. Расстояние можно выбрать как фиксированное, так и разное для всех ордеров. Это поможет увеличить гибкость ТС.
Переменная GRID_COEFFICIENTS содержит множители лота для каждого ордера. Если их сделать одинаковыми, то будет использоваться обычная сетка. Если разными, то это будет мартингейл или антимартингейл, или любое другое название, применимое для сетки с разными множителями лота.
Для тех, кто слабо знаком с библиотекой numpy:
- np.full заполняет массив заданным количеством одинаковых значений
- np.linspace заполняет массив заданным количеством значений, равномерно распределенных между двумя вещественными числами. В приведенном выше примере GRID_COEFFICIENTS будет содержать следующее.
array([1. , 1.22222222, 1.44444444, 1.66666667, 1.88888889, 2.11111111, 2.33333333, 2.55555556, 2.77777778, 3. ])
Соответственно, множитель первого лота будет равняться единице, т.е. базовому лоту, заданному в настройках ТС. И дальше по возрастанию от 1 до 3 для остальных ордеров сетки. Для того чтобы использовать сетку с фиксированным множителем для всех ордеров, следует вызвать np.full.
Учет сработавших и несработавших ордеров может выглядеть определенным трюкачеством, поэтому следует создать какую-нибудь структуру данных. Я решил создать словарь для учета ордеров и позиций для каждого конкретного случая (семпла). Вместо этого можно было бы воспользоваться объектом Data Class или pandas Data Frame, либо структурированным numpy массивом. Последнее решение, пожалуй, оказалось бы самым быстрым, но здесь это некритично.
На каждой итерации добавления семпла в обучающую выборку будет создаваться словарь, хранящий информацию о сетке ордеров. Здесь, наверное, следует расшифровать. Словарь grid_stats содержит всю необходимую информацию о текущей сетке ордеров с момента её открытия до момента закрытия.
def add_labels(dataset, min, max, distances, coefficients): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) all_pr = dataset['close'][i:i + rand + 1] grid_stats = {'up_range': all_pr[0] - all_pr.min(), 'dwn_range': all_pr.max() - all_pr[0], 'up_state': 0, 'dwn_state': 0, 'up_orders': 0, 'dwn_orders': 0, 'up_profit': all_pr[-1] - all_pr[0] - MARKUP, 'dwn_profit': all_pr[0] - all_pr[-1] - MARKUP } for i in np.nditer(distances): if grid_stats['up_state'] + i <= grid_stats['up_range']: grid_stats['up_state'] += i grid_stats['up_orders'] += 1 grid_stats['up_profit'] += (all_pr[-1] - all_pr[0] + grid_stats['up_state']) \ * coefficients[int(grid_stats['up_orders']-1)] grid_stats['up_profit'] -= MARKUP * coefficients[int(grid_stats['up_orders']-1)] if grid_stats['dwn_state'] + i <= grid_stats['dwn_range']: grid_stats['dwn_state'] += i grid_stats['dwn_orders'] += 1 grid_stats['dwn_profit'] += (all_pr[0] - all_pr[-1] + grid_stats['dwn_state']) \ * coefficients[int(grid_stats['dwn_orders']-1)] grid_stats['dwn_profit'] -= MARKUP * coefficients[int(grid_stats['dwn_orders']-1)] if grid_stats['up_profit'] > grid_stats['dwn_profit'] and grid_stats['up_profit'] > 0: labels.append(0.0) continue elif grid_stats['dwn_profit'] > 0: labels.append(1.0) continue labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index).reset_index(drop=True) return dataset
Переменная all_pr содержит цены с текущей до будущей, она необходима для расчета самой сетки. Для построения сетки мы хотим знать диапазоны цены от первого бара до последнего, их содержат записи словаря 'up_range' и 'dwn_range'. Переменные 'up_profit' и 'dwn_profit' будут содержать итоговый профит от применения сетки на покупку или продажу на текущем участке истории. Эти значения инициализируются профитом, полученным от одной сделки, открытой изначально по рынку. Затем они будут суммироваться со сделками, которые были открыты по сетке, если отложенные ордера сработали.
Теперь необходимо пройтись в цикле по всем GRID_DISTANCES и проверить, сработали ли отложенные лимитные ордера. Если ордер лежит в диапазоне up_range или dwn_range, то значит он сработал. В этом случае инкрементируются соответствующие счетчики up_state и dwn_state, которые хранят уровень последнего активированного ордера. На следующей итерации к этому уровню прибавляется расстояние до нового ордера сетки, и если этот ордер лежит в диапазоне цен, значит он тоже сработал.
Ко всем сработавшим ордерам записывается дополнительная информация. Например, прибавляется профит отложенного ордера к совокупному. Для позиций на покупку он считается по следующей формуле. Здесь из последней цены (на которой предполагается закрытие позиции) вычитается цена открытия позиции и прибавляется расстояние до выбранного отложенного ордера в серии, все это умножается на коэффициент увеличения лота для данного ордера в сетке. Для ордеров на продажу все наоборот. В дополнение, считается накопленный маркап.
grid_stats['up_profit'] += (all_pr[-1] - all_pr[0] + grid_stats['up_state']) \ * coefficients[int(grid_stats['up_orders']-1)] grid_stats['up_profit'] -= MARKUP * coefficients[int(grid_stats['up_orders']-1)]
Следующий блок кода делает проверку прибыли по сеткам на покупку и продажу. Если прибыль с учетом накопленных маркапов больше нуля и максимальна, то добавляется соответствующий семпл в обучающую выборку. Если ни одно условие не выполнено, то добавляется метка 2.0, семплы помеченные этой меткой удаляются из обучающего датасета как неинформативные. Эти условия можно изменить впоследствии, в зависимости от желаемых вариантов построения сетки, описанных выше.
Апгрейдим тестер для работы с сеткой ордеров
Для корректного расчета прибыли, полученной от торговли сеткой, следует модифицировать тестер стратегий. Я решил сделать его наиболее приближенным к тестеру MetaTrader 5 в том плане, что тестер последовательно проходит по истории котировок в цикле и открывает и закрывает сделки как будто это реальная торговля. В этом случае улучшается понимание кода и исключается подглядывание. Я остановлюсь на основных моментах кода для того, чтобы вы его тоже поняли. Старую версию тестера приводить не стал, но вы можете посмотреть на нее заглянув в листинги предыдущих статей. Предполагаю, что для большинства читающих приведенный ниже код является темным лесом, и они побыстрее хотели бы заполучить Грааль, не вдаваясь ни в какие подробности. Тем не менее, ключевые моменты следует пояснить.
def tester(dataset, markup, distances, coefficients, plot=False): last_deal = int(2) all_pr = np.array([]) report = [0.0] for i in range(dataset.shape[0]): pred = dataset['labels'][i] all_pr = np.append(all_pr, dataset['close'][i]) if last_deal == 2: last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5: last_deal = 1 up_range = all_pr[0] - all_pr.min() up_state = 0 up_orders = 0 up_profit = (all_pr[-1] - all_pr[0]) - markup report.append(report[-1] + up_profit) up_profit = 0 for d in np.nditer(distances): if up_state + d <= up_range: up_state += d up_orders += 1 up_profit += (all_pr[-1] - all_pr[0] + up_state) \ * coefficients[int(up_orders-1)] up_profit -= markup * coefficients[int(up_orders-1)] report.append(report[-1] + up_profit) up_profit = 0 all_pr = np.array([dataset['close'][i]]) continue if last_deal == 1 and pred < 0.5: last_deal = 0 dwn_range = all_pr.max() - all_pr[0] dwn_state = 0 dwn_orders = 0 dwn_profit = (all_pr[0] - all_pr[-1]) - markup report.append(report[-1] + dwn_profit) dwn_profit = 0 for d in np.nditer(distances): if dwn_state + d <= dwn_range: dwn_state += d dwn_orders += 1 dwn_profit += (all_pr[0] + dwn_state - all_pr[-1]) \ * coefficients[int(dwn_orders-1)] dwn_profit -= markup * coefficients[int(dwn_orders-1)] report.append(report[-1] + dwn_profit) dwn_profit = 0 all_pr = np.array([dataset['close'][i]]) continue y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.figure(figsize=(12,7)) plt.plot(report) plt.plot(lr.predict(X)) plt.title("Strategy performance") plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
Исторически сложилось, что сеточников интересует только кривая баланса, а кривая эквити игнорируется. Давайте будем придерживаться этой традиции и не станем переусложнять и без того сложный тестер, будем выводить только график баланса. А кривую эквити всегда можно посмотреть в терминале MetaTrader 5.
В цикле пробегаем по всем ценам и добавляем их в массив all_pr. Дальше существует три варианта, помеченные маркером. Поскольку тестер рассматривался в предыдущих статьях, объясню только варианты закрытия сетки ордеров при возникновении противоположного сигнала. Так же, как и при разметке сделок, переменная up_range хранит диапазон пройденных цен на момент закрытия открытых позиций. Далее вычисляется прибыль первой позиции, которая была открыта по рынку. Затем в цикле проверяется наличие сработавших отложенных ордеров, и если они сработали, то их результат добавляется к графику баланса. То же самое происходит для ордеров\позиций на продажу. Таким образом, график баланса отражает все закрытые позиции, не суммарную прибыль по группам.
Тестируем новые методы работы с сетками ордеров
Этап подготовки данных для машинного обучения выглядит привычным образом. Сначала мы получаем цены и набор признаков, затем размечаем данные (создаем метки на покупку и на продажу), а потом проверяем разметку в кастомном тестере.
# Get prices and labels and test it pr = get_prices(START_DATE, END_DATE) pr = add_labels(pr, 15, 15, GRID_DISTANCES, GRID_COEFFICIENTS) tester(pr, MARKUP, GRID_DISTANCES, GRID_COEFFICIENTS, plot=True)
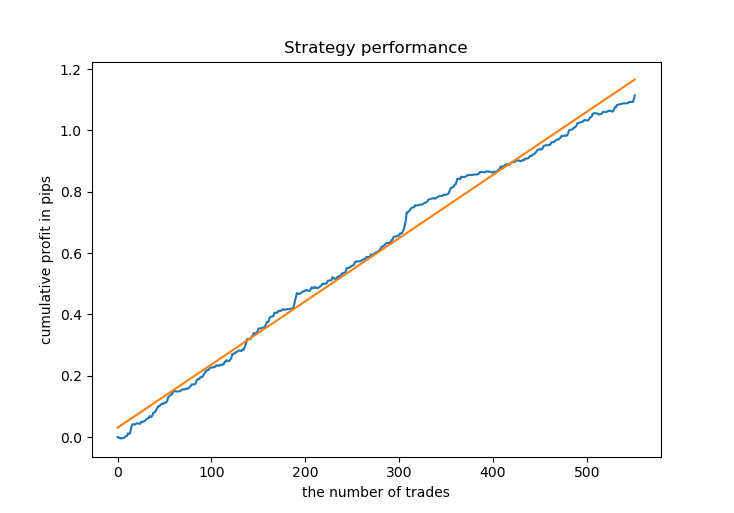
Теперь необходимо обучить модель CatBoost и протестировать её на новых данных. Я решил оставить обучение на синтетических данных, генерируемых моделью гауссовских смесей, поскольку это работает хорошо.
# Learn and test CatBoost model gmm = mixture.GaussianMixture( n_components=N_COMPONENTS, covariance_type='full', n_init=1).fit(pr[pr.columns[1:]]) res = [] for i in range(10): res.append(brute_force(10000)) print('Iteration: ', i, 'R^2: ', res[-1][0]) res.sort() test_model(res[-1])
В данном примере мы обучим десять моделей на 10000 сгенерированных семплах и выберем лучшую через оценку R^2. Процесс обучения выглядит следующим образом.
Iteration: 0 R^2: 0.8719436661855786 Iteration: 1 R^2: 0.912006346274096 Iteration: 2 R^2: 0.9532278725035132 Iteration: 3 R^2: 0.900845571741786 Iteration: 4 R^2: 0.9651728908727953 Iteration: 5 R^2: 0.966531822300101 Iteration: 6 R^2: 0.9688263099200539 Iteration: 7 R^2: 0.8789927823514787 Iteration: 8 R^2: 0.6084261786804662 Iteration: 9 R^2: 0.884741078512629
Большинство моделей имеет высокую оценку R^2 на новых данных, что говорит о высокой стабильности модели. В итоге график баланса на обучающих данных и данных вне обучения получился такой.
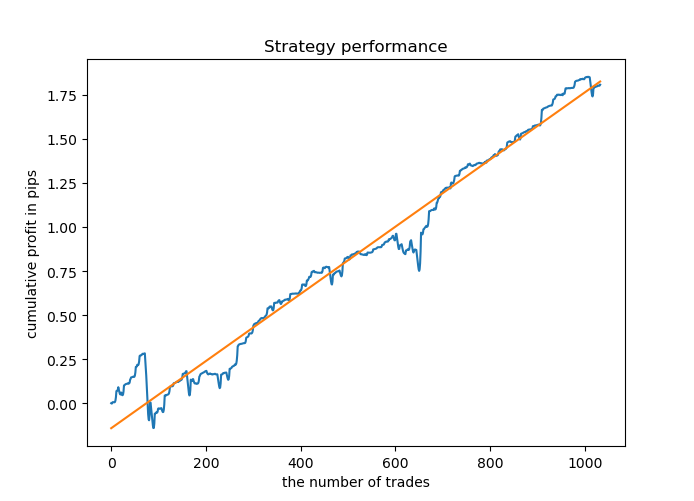
Выглядит неплохо. Теперь мы можем экспортировать обученную модель в MetaTrader 5 и проверить её результативность в тестере терминала. Для этого нужно подготовить торгового эксперта и подключаемый include-файл. Для каждой обученной модели будет свой файл, поэтому их легко хранить и менять между собой.
Экспортируем CatBoost модель в MQL5
Для экспорта модели следует вызвать функцию.
export_model_to_MQL_code(res[-1][1])
Функция претерпела некоторые изменения, которые следует пояснить.
def export_model_to_MQL_code(model):
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
# add variables
code = '#include <Math\Stat\Math.mqh>'
code += '\n'
code += 'int MAs[' + str(len(MA_PERIODS)) + \
'] = {' + ','.join(map(str, MA_PERIODS)) + '};'
code += '\n'
code += 'int grid_size = ' + str(GRID_SIZE) + ';'
code += '\n'
code += 'double grid_distances[' + str(len(GRID_DISTANCES)) + \
'] = {' + ','.join(map(str, GRID_DISTANCES)) + '};'
code += '\n'
code += 'double grid_coefficients[' + str(len(GRID_COEFFICIENTS)) + \
'] = {' + ','.join(map(str, GRID_COEFFICIENTS)) + '};'
code += '\n'
# get features
code += 'void fill_arays( double &features[]) {\n'
code += ' double pr[], ret[];\n'
code += ' ArrayResize(ret, 1);\n'
code += ' for(int i=ArraySize(MAs)-1; i>=0; i--) {\n'
code += ' CopyClose(NULL,PERIOD_CURRENT,1,MAs[i],pr);\n'
code += ' double mean = MathMean(pr);\n'
code += ' ret[0] = pr[MAs[i]-1] - mean;\n'
code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n'
code += ' ArraySetAsSeries(features, true);\n'
code += '}\n\n'
# add CatBosst
code += 'double catboost_model' + '(const double &features[]) { \n'
code += ' '
with open('catmodel.h', 'r') as file:
data = file.read()
code += data[data.find("unsigned int TreeDepth")
:data.find("double Scale = 1;")]
code += '\n\n'
code += 'return ' + \
'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
code += 'double ApplyCatboostModel(const double &features[],uint &TreeDepth_[],uint &TreeSplits_[],uint &BorderCounts_[],float &Borders_[],double &LeafValues_[]) {\n\
uint FloatFeatureCount=ArrayRange(BorderCounts_,0);\n\
uint BinaryFeatureCount=ArrayRange(Borders_,0);\n\
uint TreeCount=ArrayRange(TreeDepth_,0);\n\
bool binaryFeatures[];\n\
ArrayResize(binaryFeatures,BinaryFeatureCount);\n\
uint binFeatureIndex=0;\n\
for(uint i=0; i<FloatFeatureCount; i++) {\n\
for(uint j=0; j<BorderCounts_[i]; j++) {\n\
binaryFeatures[binFeatureIndex]=features[i]>Borders_[binFeatureIndex];\n\
binFeatureIndex++;\n\
}\n\
}\n\
double result=0.0;\n\
uint treeSplitsPtr=0;\n\
uint leafValuesForCurrentTreePtr=0;\n\
for(uint treeId=0; treeId<TreeCount; treeId++) {\n\
uint currentTreeDepth=TreeDepth_[treeId];\n\
uint index=0;\n\
for(uint depth=0; depth<currentTreeDepth; depth++) {\n\
index|=(binaryFeatures[TreeSplits_[treeSplitsPtr+depth]]<<depth);\n\
}\n\
result+=LeafValues_[leafValuesForCurrentTreePtr+index];\n\
treeSplitsPtr+=currentTreeDepth;\n\
leafValuesForCurrentTreePtr+=(1<<currentTreeDepth);\n\
}\n\
return 1.0/(1.0+MathPow(M_E,-result));\n\
}'
file = open('C:/Users/dmitrievsky/AppData/Roaming/MetaQuotes/Terminal/D0E8209F77C8CF37AD8BF550E51FF075/MQL5/Include/' +
str(SYMBOL) + '_cat_model_martin' + '.mqh', "w")
file.write(code)
file.close()
print('The file ' + 'cat_model' + '.mqh ' + 'has been written to disc') Теперь сохраняются настройки сетки, которые использовались при обучении. Они же будут использоваться в торговле.
Скользящее среднее из стандартной поставки терминала и индикаторные буферы теперь не используются. Вместо этого расчет всех признаков происходит в теле функции. При добавлении своих оригинальных признаков их также необходимо добавить в функцию экспорта.
Зеленым помечен путь до папки Include вашего терминала, для сохранения .mqh файла и подключения его к советнику.
Посмотрим как выглядит теперь сам .mqh файл (модель CatBoost здесь опущена)
#include <Math\Stat\Math.mqh> int MAs[14] = {5,25,55,75,100,125,150,200,250,300,350,400,450,500}; int grid_size = 10; double grid_distances[10] = {0.003,0.0035555555555555557,0.004111111111111111,0.004666666666666666,0.005222222222222222, 0.0057777777777777775,0.006333333333333333,0.006888888888888889,0.0074444444444444445,0.008}; double grid_coefficients[10] = {1.0,1.4444444444444444,1.8888888888888888,2.333333333333333, 2.7777777777777777,3.2222222222222223,3.6666666666666665,4.111111111111111,4.555555555555555,5.0}; void fill_arays( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(MAs)-1; i>=0; i--) { CopyClose(NULL,PERIOD_CURRENT,1,MAs[i],pr); double mean = MathMean(pr); ret[0] = pr[MAs[i]-1] - mean; ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Как видно, все настройки сетки сохранены и модель готова к работе, достаточно подключить её к советнику.
#include <EURUSD_cat_model_martin.mqh> Теперь следует пояснить логику обработки сигналов советником на примере всего того, что работает в OnTick() функции. В боте используется библиотека MT4Orders, которую необходимо скачать.
void OnTick() { //--- if(!isNewBar()) return; TimeToStruct(TimeCurrent(), hours); double features[]; fill_arays(features); if(ArraySize(features) !=ArraySize(MAs)) { Print("No history availible, will try again on next signal!"); return; } double sig = catboost_model(features); // закрываем позиции по противоположному сигналу if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } // удаляем все отложки, если нет маркет ордеров if(!count_market_orders(0) && !count_market_orders(1)) { for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 2 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic ) if(OrderDelete(OrderTicket())) { } if(OrderType() == 3 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic ) if(OrderDelete(OrderTicket())) { } } } // открываем позиции и отложки по сигналам if(countOrders() == 0 && CheckMoneyForTrade(_Symbol,LotsOptimized(),ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig < 0.5) { OrderSend(Symbol(),OP_BUY,l, Ask, 0, Bid-stoploss*_Point, Ask+takeprofit*_Point, NULL, OrderMagic); double p = Ask; for(int i=0; i<grid_size; i++) { p = NormalizeDouble(p - grid_distances[i], _Digits); double gl = NormalizeDouble(l * grid_coefficients[i], 2); OrderSend(Symbol(),OP_BUYLIMIT,gl, p, 0, p-stoploss*_Point, p+takeprofit*_Point, NULL, OrderMagic); } } else { OrderSend(Symbol(),OP_SELL,l, Bid, 0, Ask+stoploss*_Point, Bid-takeprofit*_Point, NULL, OrderMagic); double p = Ask; for(int i=0; i<grid_size; i++) { p = NormalizeDouble(p + grid_distances[i], _Digits); double gl = NormalizeDouble(l * grid_coefficients[i], 2); OrderSend(Symbol(),OP_SELLLIMIT,gl, p, 0, p+stoploss*_Point, p-takeprofit*_Point, NULL, OrderMagic); } } } }
Функция fill_arrays подготавливает признаки для модели CatBoost, заполняя ими массив features. Дальше этот массив передается в функцию catboost_model(), которая возвращает сигнал в диапазоне 0;1.
На примере ордеров на покупку видно, что используется переменная grid_size (количество отложенных ордеров), которые располагаются на расстоянии grid_distances друг от друга. Стандартный лот домножается на коэффициент из массива grid_coefficients, который соответствует порядковому номеру ордера.
После того, как бот скомпилирован, можно перейти к тестированию.
Проверка бота в MetaTrader 5 тестере
Тестировать необходимо на том таймфрейме, для которого бот обучался. В данном случае это H1. Можно тестировать по ценам открытия, поскольку бот с явным контролем открытия баров. Но т. к. используется сетка, для точности, можно выбрать M1 OHLC.
Данный конкретный бот обучался на периоде:
START_DATE = datetime(2020, 5, 1) TSTART_DATE = datetime(2019, 1, 1) FULL_DATE = datetime(2018, 1, 1) END_DATE = datetime(2022, 1, 1)
- С пятого месяца 20 года и по сей день — это период обучения, который разделен 50\50 на тренировочную и валидационную подвыборки.
- С 1 месяца 2019 года модель оценивалась по R^2 и выбиралась лучшая.
- С 1 месяца 2018 года модель была протестирована в кастомном тестере.
- Данные для обучения брались синтетические (сгенерированный моделью гауссовских смесей)
- Модель CatBoost имеет сильную регуляризацию, благодаря которой не подгоняется под обучающую выборку.
Все эти факторы говорят о том (и кастомный тестер это подтвердил), что найдена определенная закономерность на интервале с 2018 года по сей день.
Давайте посмотрим как это выглядит в тестере MT5.
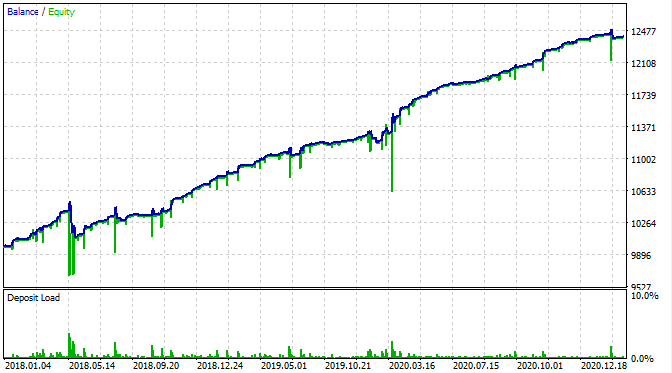
За исключением того, что теперь видны просадки по эквити, график баланса выглядит аналогичным образом, как это было в моем кастомном тестере. Это хорошая новость. Проверим, что бот торгует именно сетку, а не что-либо еще.
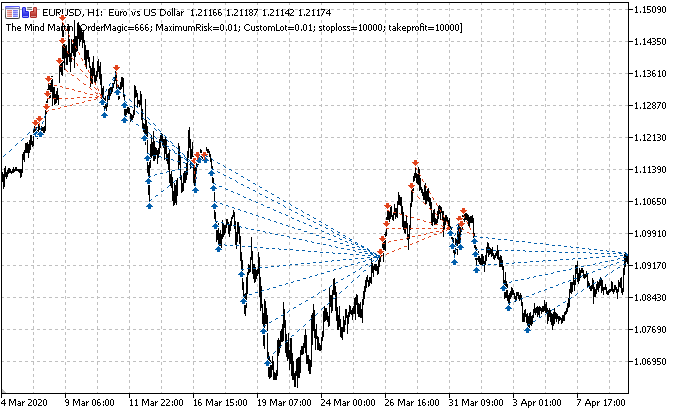
Я протестировал бота с начала 2015 года, и он показал следующий результат.
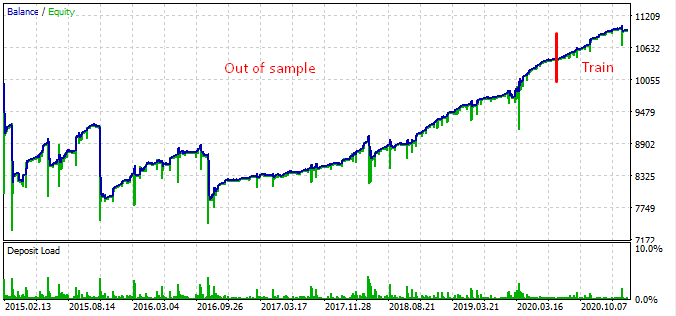
Из графика следует, что найденная закономерность работает с конца 2016 года по сей день, а затем ломается. Первоначальный лот в данном случае минимальный, поэтому бот не слился. Хорошо, мы знаем, что бот работает с начала 2017 года и можем поднять риск, чтобы повысить прибыльность. В данном случае он показывает внушительные 1600% за 3 года при просадке 40% и гипотетическом риске полного слива.
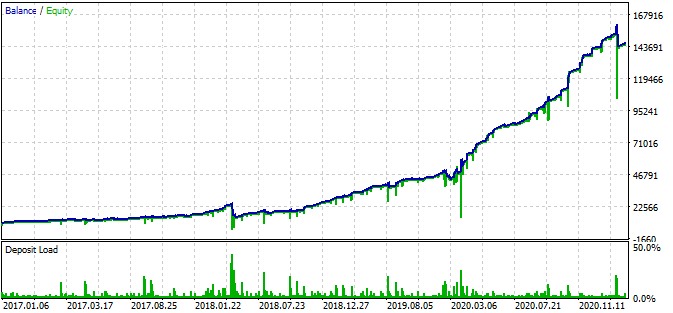
Робот также имеет стоплосс и тейкпрофит для каждой позиции. Их можно использовать, жертвуя производительность, но ограничивая риски.
Следует заметить, что я использовал достаточно агрессивную сетку.
GRID_COEFFICIENTS = np.linspace(1, 5, num= GRID_SIZE)
array([1. , 1.44444444, 1.88888889, 2.33333333, 2.77777778, 3.22222222, 3.66666667, 4.11111111, 4.55555556, 5. ])
Последний множитель равен пяти. Это означает, что лот последнего ордера в серии в пять раз выше чем первоначальный, что ведет к дополнительным рискам. Вы можете выбрать более щадящие режимы.
Почему бот перестал работать в 2016 году и ранее? У меня нет осмысленного ответа на данный вопрос. Похоже, что существуют длительные семилетние циклы на FOREX или более короткие, закономерности которых никак не связаны между собой. Это отдельная тема, требующая пристального рассмотрения.
Заключение
В данной статье я постарался описать технику, через которую можно обучать бустинг либо нейронную сеть торговать мартингейл. Предложено готовое решение, позволяющее создавать собственных ботов, готовых к торговле.
 Полезные и экзотические приемы для автоматической торговли
Полезные и экзотические приемы для автоматической торговли
 Нейросети — это просто (Часть 12): Dropout
Нейросети — это просто (Часть 12): Dropout
 Самоадаптирующийся алгоритм (Часть IV): Дополнительный функционал и тесты
Самоадаптирующийся алгоритм (Часть IV): Дополнительный функционал и тесты
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Придется ведь учитывать те данные, которые никак не размечены вручную
Это необязательно, надо чтобы учитывались только те, что с моей разметкой
Вы наверно рыбак, раз такое название пишите. Я вот давно не ловлю рыбу. Кушать жалко. Вполне можно что-то другое скушать. Дичь какая-то, поймать рыбку. Потом её и съесть. Кстати Китайцы давно придумали соевую рыбу. Там даже кости есть, но более богатые кальцием. Правда если ещё приправить немного, то вполне сносная еда. Моя жена(кстати у неё подруга была шеф поваром одного крупного ресторана), когда первый раз мне приготовила, я вообще не мог поверить что это можно приготовить. Представляете, вполне простые продукты, да я и сам не плохо готовлю. Но когда я попробовал у неё, я сначала вытаращил глаза, потом долго расспрашивал у неё рецепт. Я так и не поверил что так можно готовить. Но я ел это несколько лет. Кстати и не привык. Всегда вспоминаю и мне кажется что это какое-то было наваждение. Магия. Мне кажется она что-то делала совсем не так, или не что что мне рассказывала.
Самое интересное, что она рассказывала про кулинарию, она говорила что можно приготовить любой кусок мяса разными вкусами. Всегда по разному. И его не отличишь. Более того главное не в основных продуктах, а специях. Конечно, можно покупать супер дорогие и изысканные продукты, тратя куча времени и средств на это занятие. Но можно самое просто. Просто добавить специй. Может странно звучит. Но я так и сейчас не верю что это работает.
Удивительно могут ли дорогие продукты быть заменены дешёвыми продуктами и простыми приправами. Как не странно, не смотря на то что многие скажут более нет чем да. Это работает. Более того работает даже лучше. Зачем нужно тратить кучу сил и времени, бегая за синей птицей по магазинам, когда всегда всё и так есть под ругой.
Что же касается техники, оно вроде и хорошо с одной стороны, но уж как-то выглядит угловато. Естественно можно демонстрировать брутал, вкачивая в алгоритмы и в производительность. И может здесь я ошибаюсь, но всё хорошо в меру. Всегда нужно смотреть чтобы картина была комплексной. Мне кажется всего должно быть в меру.
Конечно, хорошо выцеживать показатели мощностями, а почему бы и нет, конечно будут результата, но если использовать более гибкие подходы, то здесь может быть и сети лишние, да и рыбу мучать не зачем. Палка всегда об двух концах. Если с одной стороны на кучку свечей терафлопсы, то может с другой стороны нужно хотя бы машку.
Иначе картина будет очень однобокая, если мы будем что-то не замечать. Это моё мнение. Можете его игнорировать. Но я думаю Вы согласны с тем что ударяясь во что-то одно, другое мы просто можем упускать из вида.
Статья хорошая, правда немного заумно написана. Но и ладно. В целом норм.
Вы наверно рыбак, раз такое название пишите. Я вот давно не ловлю рыбу. Кушать жалко. Вполне можно что-то другое скушать. Дичь какая-то, поймать рыбку. Потом её и съесть. Кстати Китайцы давно придумали соевую рыбу. Там даже кости есть, но более богатые кальцием. Правда если ещё приправить немного, то вполне сносная еда. Моя жена(кстати у неё подруга была шеф поваром одного крупного ресторана), когда первый раз мне приготовила, я вообще не мог поверить что это можно приготовить. Представляете, вполне простые продукты, да я и сам не плохо готовлю. Но когда я попробовал у неё, я сначала вытаращил глаза, потом долго расспрашивал у неё рецепт. Я так и не поверил что так можно готовить. Но я ел это несколько лет. Кстати и не привык. Всегда вспоминаю и мне кажется что это какое-то было наваждение. Магия. Мне кажется она что-то делала совсем не так, или не что что мне рассказывала.
Самое интересное, что она рассказывала про кулинарию, она говорила что можно приготовить любой кусок мяса разными вкусами. Всегда по разному. И его не отличишь. Более того главное не в основных продуктах, а специях. Конечно, можно покупать супер дорогие и изысканные продукты, тратя куча времени и средств на это занятие. Но можно самое просто. Просто добавить специй. Может странно звучит. Но я так и сейчас не верю что это работает.
Удивительно могут ли дорогие продукты быть заменены дешёвыми продуктами и простыми приправами. Как не странно, не смотря на то что многие скажут более нет чем да. Это работает. Более того работает даже лучше. Зачем нужно тратить кучу сил и времени, бегая за синей птицей по магазинам, когда всегда всё и так есть под ругой.
Что же касается техники, оно вроде и хорошо с одной стороны, но уж как-то выглядит угловато. Естественно можно демонстрировать брутал, вкачивая в алгоритмы и в производительность. И может здесь я ошибаюсь, но всё хорошо в меру. Всегда нужно смотреть чтобы картина была комплексной. Мне кажется всего должно быть в меру.
Конечно, хорошо выцеживать показатели мощностями, а почему бы и нет, конечно будут результата, но если использовать более гибкие подходы, то здесь может быть и сети лишние, да и рыбу мучать не зачем. Палка всегда об двух концах. Если с одной стороны на кучку свечей терафлопсы, то может с другой стороны нужно хотя бы машку.
Иначе картина будет очень однобокая, если мы будем что-то не замечать. Это моё мнение. Можете его игнорировать. Но я думаю Вы согласны с тем что ударяясь во что-то одно, другое мы просто можем упускать из вида.
Статья хорошая, правда немного заумно написана. Но и ладно. В целом норм.
Многим известно, что сетями можно поймать больше рыбы, но они запрещены. Если перегородить сетью реку, то она перекроет ход косяка рыбы, и многие рыбаки останутся без еды в этот вечер. Конечно, сейчас мало кто добывает себе еду таким образом, в основном это любители, которые не прочь выловить пару-тройку лещей и пожарить их на сковороде. Бывает, сидишь в лодке час или больше, а клева все нет. К тому же постоянно зацепляешь блесны об коряги. В такие моменты жалеешь что не поставил сеть и не занялся более насущными проблемами. Конечно, рыбалка сетью это совсем не то, что ловля на блесну. Упускаются многие, в том числе эстетические, моменты. Настоящий рыбак, видимо, никогда не пойдет на это. Он хочет чувствовать каждое свое движение, ощущать ветер в лицо и слушать жужжание комаров в прибрежных зонах, перемежающееся кваканьем лягушек в запрудах. Такая рыбалка постепенно уходит в глубокий вечер, когда солнце в закате освещает бездвижную как зеркало водную гладь, натянутую струну которой то там то здесь потревожат редкие всплески кормящейся щуки и судака. Определенно это особая философия, недоступная для урбанизированного потребителя, привыкшего брать готовое из печи.
Многим известно, что сетями можно поймать больше рыбы, но они запрещены. Если перегородить сетью реку, то она перекроет ход косяка рыбы, и многие рыбаки останутся без еды в этот вечер. Конечно, сейчас мало кто добывает себе еду таким образом, в основном это любители, которые не прочь выловить пару-тройку лещей и пожарить их на сковороде. Бывает, сидишь в лодке час или больше, а клева все нет. К тому же постоянно зацепляешь блесны об коряги. В такие моменты жалеешь что не поставил сеть и не занялся более насущными проблемами. Конечно, рыбалка сетью это совсем не то, что ловля на блесну. Упускаются многие, в том числе эстетические, моменты. Настоящий рыбак, видимо, никогда не пойдет на это. Он хочет чувствовать каждое свое движение, ощущать ветер в лицо и слушать жужжание комаров в прибрежных зонах, перемежающееся кваканьем лягушек в запрудах. Такая рыбалка постепенно уходит в глубокий вечер, когда солнце в закате освещает бездвижную как зеркало водную гладь, натянутую струну которой то там то здесь потревожат редкие всплески кормящейся щуки и судака. Определенно это особая философия, недоступная для урбанизированного потребителя, привыкшего брать готовое из печи.
Так то да. Если у тебя есть стадо лучше доить пару десятков коров, чтобы потом собирать сливки, а лишнее сбывать и покупать новое сено. Многие хотят всё и сразу. Ваша статья гарантия для большинства. Если есть стадо нужно его двигать, иначе оно разбредётся. Вливание новой порции каких-то гарантий это всегда похвально. Здесь даже возражать трудно. Самое прибыльное всегда есть, будет, да и останется хорошее шоу. А лучше хорошего шоу, может быть только более лучшее шоу на запросы большинства. Это верно. Толпа рулит. Значит надо кидать всё больше и больше корма на потеху зрителей. Главное что все готовы платить за то что они получают. Готовы иметь стабильный доход? Получите распишитесь. Дальше в соответствие с купленными местами на корабле. Публика получает своё место в зале.
Зачёт, здесь даже разумная логика не нужна. Подходим берём. Чем больше покупаем тем больше берём. Статья как раз в кассу. Хотите сеткой работать, значит работаем сеткой. Кстати, у меня сейчас пару заказов на сетки. Ладно толпа рулит. :)
Так то да. Если у тебя есть стадо лучше доить пару десятков коров, чтобы потом собирать сливки, а лишнее сбывать и покупать новое сено. Многие хотят всё и сразу. Ваша статья гарантия для большинства. Если есть стадо нужно его двигать, иначе оно разбредётся. Вливание новой порции каких-то гарантий это всегда похвально. Здесь даже возражать трудно. Самое прибыльное всегда есть, будет, да и останется хорошее шоу. А лучше хорошего шоу, может быть только более лучшее шоу на запросы большинства. Это верно. Толпа рулит. Значит надо кидать всё больше и больше корма на потеху зрителей. Главное что все готовы платить за то что они получают. Готовы иметь стабильный доход? Получите распишитесь. Дальше в соответствие с купленными местами на корабле. Публика получает своё место в зале.
Зачёт, здесь даже разумная логика не нужна. Подходим берём. Чем больше покупаем тем больше берём. Статья как раз в кассу. Хотите сеткой работать, значит работаем сеткой. Кстати, у меня сейчас пару заказов на сетки. Ладно толпа рулит. :)
Совершенно верно. Есть некоторые "традиционные" вещи, которые некогда пользовались\пользуются популярностью\спросом. Почему бы не взять новые фантики в виде технологий машинного обучения и завернуть в них старые конфетки.
Есть спрос также на применение ИИ в парной торговле и торговле корзинами. Отчасти, спрос подогревается статьями. Но и новые продукты в Маркете от других авторов появляются на основе этих статей. Поскольку тут не вода, а готовые решения.