
Метамодели в машинном обучении и трейдинге: Оригинальный тайминг торговых приказов

Введение
Отличительной особенностью некоторых торговых систем является избирательная торговля, то есть они не постоянно находятся в рынке. По большей части, это обусловлено наличием закономерностей в те или иные моменты времени, тогда как в остальные моменты они отсутствуют или не определены.
В предыдущих статьях мы подробно рассмотрели различные способы применения моделей машинного обучения в задачах классификации временных рядов. Все эти модели обучались "как есть" на тренировочной выборке и компилировались в ботов после обучения. Процесс разметки обучающего датасета и выбора лучшей модели был максимально автоматизирован, что практически исключило человеческий фактор. При всем изяществе предложенных подходов эти модели имеют два недостатка, которые сложно было бы исправить без внесения дополнительного функционала.
Я задался целью расширить подход на случаи, когда модель может:
- подстраиваться под обучающий датасет, выбирая оптимальные примеры для обучения
- фильтровать те участки временного ряда, которые плохо поддаются классификации и пропускать их в процессе обучения и торговли
Такое обобщение заставило меня частично пересмотреть подход к обучению. Оказалось, что использование только одного классификатора не отвечает новым требованиям: он не может корректировать сам себя в процессе обучения. Поэтому представляю новую работу, с измененным для вышеприведённых случаев функционалом.
Теоретические аспекты нового подхода
В начале данного раздела хотелось бы сделать небольшую ремарку. Поскольку в процессе разработки торговых систем (в том числе с применением машинного обучения) исследователь имеет дело с неопределенностью, то невозможно строго формализовать то, что ищется в конечном итоге. Это какие-то более-менее устойчивые зависимости в многомерном пространстве, тяжело поддающиеся интерпретации на человеческом и даже математическом языках. Сложно провести детальный разбор того, что мы получаем на выходе высоко параметризованных самообучающихся систем. Такие алгоритмы требуют к себе некоторую степень доверия от человека, основанного на результатах бэктестов, но не проясняют саму суть и даже характер найденной закономерности.
Мы хотим написать алгоритм, который будет иметь возможность анализировать и корректировать собственные ошибки, итеративно улучшая свои результаты. Для этого предлагается взять связку из двух классификаторов и обучать их последовательно, как предложено ниже на схеме. Далее будет подробное описание идеи и объяснение схемы.
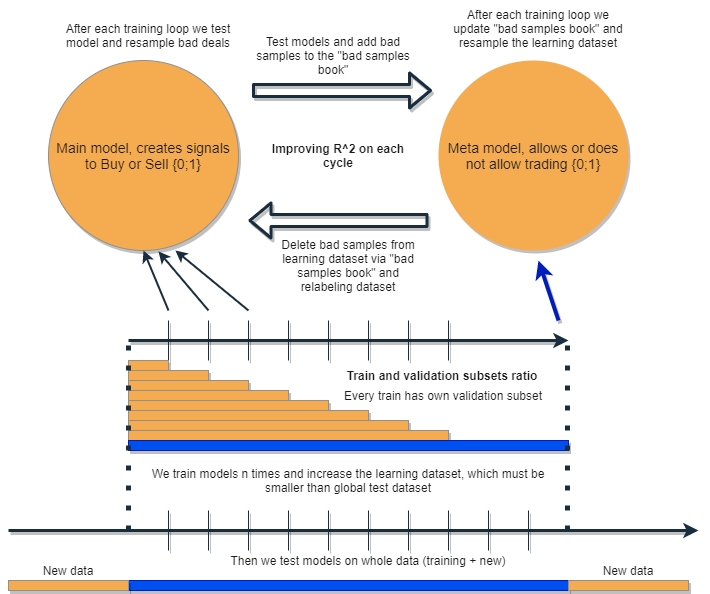
Каждый из классификаторов обучается на своем собственном датасете, которые имеют разные размеры. Синяя горизонтальная линия представляет условную глубину истории для метамодели, а оранжевые для базовой модели. Другими словами, глубина истории для метамодели всегда больше, чем для базовой и равняется оценочному (тестовому) временному интервалу, на котором будет тестироваться связка этих моделей.
Связка моделей переобучается несколько раз, при этом обучающий датасет для базовой модели может постепенно увеличиваться (увеличение длины оранжевых столбцов на каждой новой итерации), но его длина не должна превышать длину синего. После каждой итерации из обучающей выборки базовой модели удаляются все примеры, которые были классифицированы метамоделью как ложные (или ноли). Метамодель, в свою очередь, продолжает обучаться на всех примерах.
Интуиция такого подхода состоит в том, что убыточные сделки являются ошибками классификации первого рода для базовой модели, по терминологии матрицы несоответствия (confusion matrix). То есть это те случаи, которые она классифицирует как false positives. Метамодель фильтрует такие случаи и дает оценку 1 для true positives и 0 для всего остального. Фильтруя через метамодель датасет для обучения базовой модели, мы повышаем ее Precision (точность), то есть количество правильных срабатываний на покупку и продажу. В это же время метамодель повышает свой Recall (полноту), классифицируя как можно больше различных исходов.
Чем выше точность и полнота, тем точнее модель. Но в реальных ситуациях улучшение одного показателя приводит к ухудшению другого в рамках одного классификатора, поэтому использование связки двух классификаторов выглядит любопытной идеей, приводящей к улучшению обоих показателей.
По задумке, две модели обучаются на одних и тех же признаках, в связи с чем имеют дополнительное взаимодействие. Благодаря увеличенной выборке для метамодели (синий горизонтальный столбец, по сравнению с оранжевыми), она оставляет хорошие торговые ситуации, как бы фильтруя ошибки базовой модели на новых для нее данных. Взаимодействуя между собой, модели итеративно улучшаются благодаря переразметке, и оценка R^2 на валидационной выборке постоянно растет. Но метамодель может обучаться на своих собственных признаках как фильтр для базовой модели, такая связка не совсем укладывается в рамки предложенного подхода, поэтому не рассматривается в данной работе.
Базовая модель должна работать хорошо благодаря постоянной "поддержке" метамодели, но сама метамодель тоже может ошибаться. Например, на первой итерации были классифицированы случаи, при которых торговать не стоит. На второй итерации, после переобучения базовой модели и корректировке примеров для метамодели, плохие примеры могут отличаться от тех, которые были на предыдущей итерации. Из-за этого метамодель может иметь тенденцию постоянно переразмечать примеры, которые будут отличаться от итерации к итерации. Такое поведение может никогда не прийти к оптимуму. Чтобы исправить этот недостаток, создается таблица "bad samples book", которая будет пополняться примерами со всех предыдущих итераций. Если конкретнее, в нее будут записаны значения признаков в моменты времени, размеченные как плохие для торговли на всех предыдущих итерациях обучения. Это позволит обновлять датасет метамодели перед каждым её переобучением таким образом, что все неудачные моменты из предыдущих итераций будут тоже отмечены как плохие (ноли).
"bad samples book" тоже имеет свой недостаток, поскольку слишком большое количество итераций добавит слишком много нолей (плохих сделок), количество примеров значительно уменьшится для каждой новой итерации обучения. Поэтому необходимо найти баланс между количеством итераций и количеством примеров, добавляемых в книгу плохих примеров. Частично ситуацию можно решить, если усреднить количество плохих примеров в зависимости от времени их появления и фильтровать только наиболее часто встречающиеся. Благодаря этому датасет для метамодели не будет вырождаться (останется баланс между нулями и единицами). Неплохим подспорьем было бы использовать оверсемплинг, если классы оказываются сильно несбалансированными.
После нескольких итераций данная связка моделей будет показывать превосходный результат на обучающих и валидационных данных. Причем результат будет улучшаться от итерации к итерации. После обучения, связку моделей следует протестировать на совершенно новых данных, которые могут располагаться как раньше по времени, так и позже обучающей подвыборки. Нет никакой теории, позволяющей однозначно утверждать какой именно участок истории необходимо выбрать для тестов на нестационарных финансовых временных рядах. Тем не менее, предполагается улучшение производительности предложенного подхода на новых данных, а остальное покажет практика.
Хорошо, мы обучаем одну модель, корректируем ее ошибки на новых данных другой моделью и повторяем этот процесс несколько раз. Почему это должно повысить устойчивость классификаторов на новых данных? Однозначного ответа на этот вопрос нет. Есть предположение, что существует какая-то закономерность и если она существует, то будет найдена, а ситуации без закономерности будут отфильтрованы. Если эта закономерность устойчивая, то модель будет работать и на новых данных.
Данный подход, в теории, должен убивать двух зайцев одновременно:
- иметь высокое матожидание прибыльных сделок
- делать автоматический "тайминг" торговой системы, торгуя только в определенные высокоэффективные моменты времени
Поскольку речь зашла о тайминге торговой системы, то следовало бы затронуть еще один интересный момент. Теперь снижается зависимость от выбора признаков (фичей) для модели.
Базовый подход и разметка с учителем предполагают щепетильное отношение к выбору предикторов и целевых, по сути это является основной проблемой такого подхода. Подготовка и анализ данных всегда стоят на первом месте, а качество моделей напрямую зависит от профессионализма аналитика в той или иной сфере, в частности FOREX.
Предложенный же подход должен автоматически находить взаимосвязанные события тайминга, предикторов и меток и эксплуатировать автоматически найденные закономерности. Выбор предикторов и разметка сделок происходит автоматически. Все еще необходимо соблюдать ряд условий: например, признаки должны быть стационарными и иметь хотя бы опосредованное отношение к финансовому инструменту. Но в ситуации, когда истинные закономерности нам неизвестны и неоткуда почерпнуть информацию, такой подход выглядит оправданным.
Конечно, при откровенно "мусорных" признаках, которые не имеют никакой причинно-следственной связи со сделками, данный алгоритм будет работать случайным образом. Но это уже вопрос наличия/отсутствия причинно-следственных связей как таковых. В данной статье намеренно не рассматривается конструирование иных признаков, кроме как приращений (разницы между скользящим средним и ценой), поскольку это отдельная объемная тема, которая может быть рассмотрена в других статьях. Предполагается, что аналитический подход к подбору информативных признаков должен значительно повышать устойчивость данного алгоритма на новых данных.
Практическая реализация предложенного подхода
В теории все выглядит чудесно (как всегда), теперь давайте проверим, какой на самом деле эффект можно получить от связки двух классификаторов. Для этого нужно снова переписать код.
Функция автоматической разметки сделок
Были внесены изменения: теперь имеется возможность переразмечать лейблы для базовой модели на основе лейблов метамодели:
def labelling_relabeling(dataset, min=15, max=15, relabeling=False) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if relabeling: m_labels = dataset['meta_labels'][i:rand+1].values if relabeling and 0.0 in m_labels: labels.append(2.0) else: if future_pr + MARKUP < curr_pr: labels.append(1.0) elif future_pr - MARKUP > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index) return dataset
Выделенный код проверяет наличие флага переразметки, если он True и текущие метаметки с горизонтом сделки содержат нули, значит метамодель отвергает торговлю на этом участке. Соответственно, такие сделки размечаются как 2.0 и удаляются из датасета. Таким образом можно проводить итеративное удаление ненужных семплов из обучающей выборки для базовой модели, уменьшая ошибку её обучения.
Функция кастомного тестера
Теперь имеется расширенный функционал, позволяющий тестировать сразу две модели (базовую и мета). Кроме того, кастомный тестер теперь умеет переразмечать лейблы для метамодели, для её улучшения на следующей итерации.
def tester(dataset: pd.DataFrame, markup=0.0, use_meta=False, plot=False): last_deal = int(2) last_price = 0.0 report = [0.0] meta_labels = dataset['labels'].copy() for i in range(dataset.shape[0]): pred = dataset['labels'][i] meta_labels[i] = np.nan if use_meta: pred_meta = dataset['meta_labels'][i] # 1 = allow trades if last_deal == 2 and ((use_meta and pred_meta==1) or not use_meta): last_price = dataset['close'][i] last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 continue if last_deal == 1 and pred < 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (last_price - dataset['close'][i])) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.plot(report) plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l,".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l, meta_labels.fillna(method='backfill')
Тестер работает следующим образом.
Если установлен флаг учета метамодели в процессе тестирования, то проверяется условие наличия её сигнала (единица). Если сигнал существует, то базовой модели разрешается открывать и закрывать сделки, иначе она не торгует. Салатовым маркером помечены моменты добавления новых меток для метамодели в зависимости от результата закрытой сделки. Если результат положительный, то добавляется единица, в противном случае сделка размечается как 0 (неудачная).
Функция brute force
Самые объемные изменения были произведены здесь. Я помечу их в листинге разными цветами и опишу для понимания происходящего.
def brute_force(dataset, bad_samples_fraction=0.5): # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels']==1] X = dataset[dataset.columns[:-2]] X = X[X.index >= START_DATE] X = X[X.index <= STOP_DATE] X_meta = dataset[dataset.columns[:-2]] X_meta = X_meta[X_meta.index >= TSTART_DATE] X_meta = X_meta[X_meta.index <= STOP_DATE] # labels for model\meta models y = dataset[dataset['meta_labels']==1] y = dataset[dataset.columns[-2]] y = y[y.index >= START_DATE] y = y[y.index <= STOP_DATE] y_meta = dataset[dataset.columns[-1]] y_meta = y_meta[y_meta.index >= TSTART_DATE] y_meta = y_meta[y_meta.index <= STOP_DATE] # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.5, test_size=0.5, shuffle=True,) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # train\test split train_X, test_X, train_y, test_y = train_test_split( X_meta, y_meta, train_size=0.5, test_size=0.5, shuffle=True) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) meta_model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # predict on new data (validation plus learning) pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] X.columns = [''] * len(X.columns) X_meta = X.copy() # predict the learned models (base and meta) p = model.predict_proba(X) p_meta = meta_model.predict_proba(X_meta) p2 = [x[0] < 0.5 for x in p] p2_meta = [x[0] < 0.5 for x in p_meta] pr2 = pr_tst.iloc[:len(p2)].copy() pr2['labels'] = p2 pr2['meta_labels'] = p2_meta pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) full_pr = pr2.copy() pr2 = pr2[pr2.index >= TSTART_DATE] pr2 = pr2[pr2.index <= STOP_DATE] # add bad samples of this iteratin (bad meta labels) global BAD_SAMPLES_BOOK BAD_SAMPLES_BOOK = BAD_SAMPLES_BOOK.append(pr2[pr2['meta_labels']==0.0].index) # test mdels and resample meta labels R2, meta_labels = tester(pr2, MARKUP, use_meta=True, plot=False) pr2['meta_labels'] = meta_labels # resample labels based on meta labels pr2 = labelling_relabeling(pr2, relabeling=True) pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) # mark bad labels from bad_samples_book if BAD_SAMPLES_BOOK.value_counts().max() > 1: to_mark = BAD_SAMPLES_BOOK.value_counts() mean = to_mark.mean() marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index pr2.loc[pr2.index.isin(marked_idx), 'meta_labels'] = 0.0 else: pr2.loc[pr2.index.isin(BAD_SAMPLES_BOOK), 'meta_labels'] = 0.0 R2, _ = tester(full_pr, MARKUP, use_meta=True, plot=False) return [R2, model, meta_model, pr2]
BAD_SAMPLES_BOOK и остальная часть кода, помеченная соответствующим маркером, отвечает за реализацию книги плохих примеров. На каждой новой итерации переобучения двух моделей она пополняется новыми примерами неудачных сделок, которые открывались предыдущими моделями после их обучения. Проверка происходит через тестер.
Последний выделенный блок может быть гибко настроен в зависимости от того, какую часть неудачных примеров следует размечать как 0 при следующем переобучении. По умолчанию рассчитывается среднее значение всех дубликатов по каждой дате, которые содержатся в книге.
marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index Это сделано для того, чтобы можно было удалять не все неудачные даты, а только те, в моменты которых модель ошибалась больше всего раз на протяжении всех итераций обучения. Чем больше значение параметра bad_samples_fraction, тем меньше неудачных дат будет удалено, и наоборот.
Голубым цветом отмечено, что для базовой модели используется укороченная часть датасета, которая начинается со времени START_DATE. Более ранние данные не учувствуют в её обучении, но участвуют в обучении метамодели. Также этим цветом выделено, что обучаются именно две разных модели. Базовая и Мета.
Розовым цветом отмечена часть, где извлекаются предсказания обеих моделей. С помощью этих предсказаний формируется новый датасет, который проталкивается дальше по коду. Из него же добавляются плохие метки метамодели в книгу плохих примеров.
После этого обе модели тестируются в кастомном тестере, который дополнительно переразмечает (корректирует) метки для метамодели для последующей итерации обучения. На скорректированном датасете дальше проводится переразметка для базовой модели.
На завершающем этапе датасет дополнительно корректируется с помощью книги плохих меток и возвращается функцией для следующей итерации обучения.
Несмотря на обилие питоновского кода, он работает быстро за счет избавления от вложенных циклов и оптимизации. Основное время занимает обучение классификаторов CatBoost. Время обучения растет при увеличении количества признаков и длины датасета.
Процесс итеративного переобучения моделей
Я закончил с описанием основных деталей нового подхода, теперь можно перейти непосредственно к циклу обучения моделей. Предлагаю рассмотреть всё, что происходит на каждом этапе.
# make dataset
pr = get_prices()
pr = labelling_relabeling(pr, relabeling=False)
a, b = tester(pr, MARKUP, use_meta=False, plot=False)
pr['meta_labels'] = b
pr = pr.dropna()
pr = labelling_relabeling(pr, relabeling=True)
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3] Первые две строки просто создают обучающий датасет, как это происходило в примерах из предыдущих статей.
>>> pr = get_prices(START_DATE, STOP_DATE) >>> pr = labelling_relabeling(pr, relabeling=False) >>> pr close 0 1 2 3 4 5 6 labels time 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 -0.002396 -0.004554 -0.007759 -0.009549 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 -0.002664 -0.004900 -0.008039 -0.009938 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 -0.003494 -0.005663 -0.008761 -0.010778 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 -0.003380 -0.005485 -0.008559 -0.010684 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 -0.002873 -0.004894 -0.007929 -0.010144 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 23:00:00 1.19474 0.000154 0.002590 0.003375 0.003498 0.004095 0.004273 0.004888 0.0 2021-04-14 00:00:00 1.19492 0.000108 0.002337 0.003398 0.003565 0.004183 0.004410 0.005001 0.0 2021-04-14 01:00:00 1.19491 -0.000038 0.002023 0.003238 0.003433 0.004076 0.004353 0.004908 0.0 2021-04-14 02:00:00 1.19537 0.000278 0.002129 0.003534 0.003780 0.004422 0.004758 0.005286 0.0 2021-04-14 03:00:00 1.19543 0.000356 0.001783 0.003423 0.003700 0.004370 0.004765 0.005259 0.0 [5670 rows x 9 columns]
Теперь необходимо добавить лейблы для метамодели. Вспомним, что функция tester() возвращает оценку R^2 и фрейм с размеченными сделками. Поэтому мы запускаем тестер и добавляем полученный фрейм к исходным данным.
>>> a, b = tester(pr, MARKUP, use_meta=False, plot=False) >>> pr['meta_labels'] = b >>> pr = pr.dropna() >>> pr close 0 1 2 ... 5 6 labels meta_labels time ... 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 ... -0.007759 -0.009549 1.0 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 ... -0.008039 -0.009938 1.0 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 ... -0.008761 -0.010778 1.0 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 ... -0.008559 -0.010684 1.0 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 ... -0.007929 -0.010144 1.0 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 18:00:00 1.19385 0.001442 0.003437 0.003198 ... 0.003637 0.004279 0.0 1.0 2021-04-13 19:00:00 1.19379 0.000546 0.003121 0.003015 ... 0.003522 0.004166 0.0 1.0 2021-04-13 20:00:00 1.19423 0.000622 0.003269 0.003349 ... 0.003904 0.004555 0.0 1.0 2021-04-13 21:00:00 1.19465 0.000820 0.003315 0.003640 ... 0.004267 0.004929 0.0 1.0 2021-04-13 22:00:00 1.19552 0.001112 0.003733 0.004311 ... 0.005092 0.005733 1.0 1.0 [5665 rows x 10 columns]
Теперь данные подготовлены для обучения. Можно сделать дополнительную переразметку основных меток ('labels') согласно вторым меткам ('meta_labels'), то есть удалить из датасета все сделки, которые оказались убыточными.
pr = labelling_relabeling(pr, relabeling=True) Данные полностью готовы, теперь посмотрим на работу цикла обучения обеих моделей.
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3] Сначала необходимо обнулить книгу плохих сделок, если в ней что-то осталось после предыдущего обучения. Затем в цикле задается необходимое количество итераций. На каждой итерации в список res[] пишутся вложенные списки с сохраненными моделями и всем остальным что возвращает функция brute_force(). Например, можно дополнительно распечатывать основные метрики моделей на каждой итерации.
В переменную pr записывается преобразованный и возвращенный датасет, который будет использован для обучения на следующей итерации.
Можно увеличивать период обучения базовой модели, как это было предложено в теоретической части. Для этого изменяется начальная дата обучения на заданное количество дней. Но при этом его размер не должен превышать размер валидационного интервала TSTART_DATE, на котором обучается метамодель.
После запуска обучения можно видеть примерно следующую картину:
Iteration: 0, R^2: 0.30121038659012245 Iteration: 1, R^2: 0.7400055934041012 Iteration: 2, R^2: 0.6221261327516192 Iteration: 3, R^2: 0.8892813889403367 Iteration: 4, R^2: 0.787251984980149 Iteration: 5, R^2: 0.794241109825588 Iteration: 6, R^2: 0.9167876214355855 Iteration: 7, R^2: 0.903399695678254 Iteration: 8, R^2: 0.8273236332747745 Iteration: 9, R^2: 0.8646088124681762 Iteration: 10, R^2: 0.8614746864767437 Iteration: 11, R^2: 0.7900599001415054 Iteration: 12, R^2: 0.8837049280116869 Iteration: 13, R^2: 0.784793801426211 Iteration: 14, R^2: 0.941340102099874 Iteration: 15, R^2: 0.8715065229034792 Iteration: 16, R^2: 0.8104990158946458 Iteration: 17, R^2: 0.8542444489379808 Iteration: 18, R^2: 0.8307365677342298 Iteration: 19, R^2: 0.9092509787525882
Первый запуск, как правило, не очень хорош, а затем модель старается улучшать сама себя при каждом новом проходе. После этого модели сортируются по возрастанию R^2 и их можно проверить на новых данных. Можно не использовать сортировку, а посмотреть сначала на эволюцию моделей. Характерным признаком эволюции является уменьшение количества сделок при тестировании моделей.
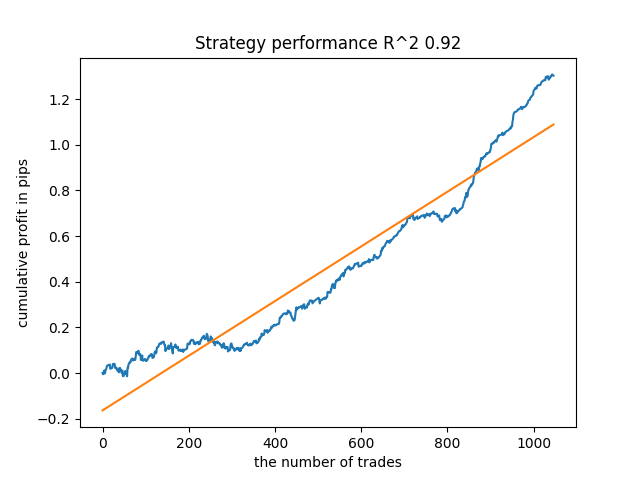
Например, я протестировал последнюю обученную модель и получил такой результат (все результаты приведены с учетом новых данных):
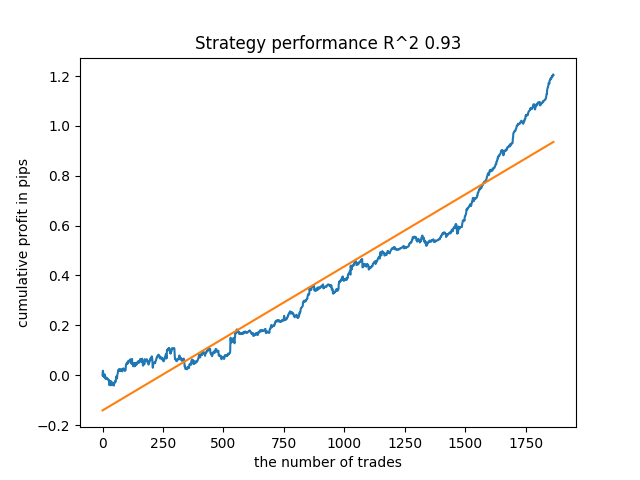
Пятая с конца модель будет иметь больше сделок, и так далее:
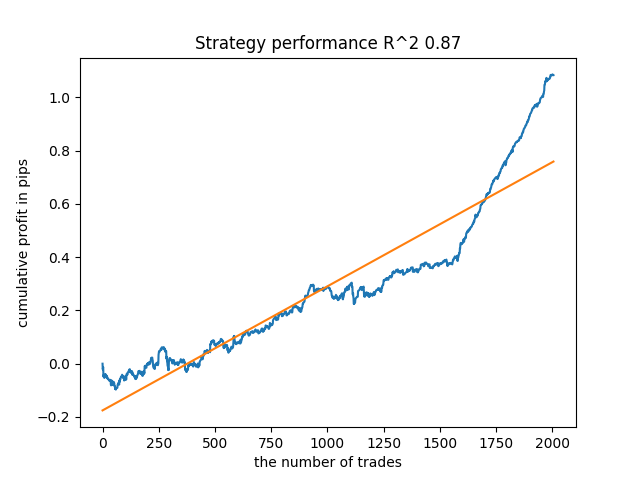
В зависимости от количества итераций и параметра bad_samples_fraction, а также от размеров обучающей и тестовой выборки можно получать модели, устойчивые на новых данных. В целом идея оказалась рабочей, хоть и достаточно сложной в понимании и реализации. Примерно такая же ситуация получилась с включенным параметром use_GMM_resampling. Количество сделок напрямую зависит от количества итераций, но бывают исключения. Я убрал ресемплинг из библиотеки, поскольку он занимал слишком много времени обучения и не слишком улучшал результаты при данном подходе.
Например, мне понравился пятый с конца результат:
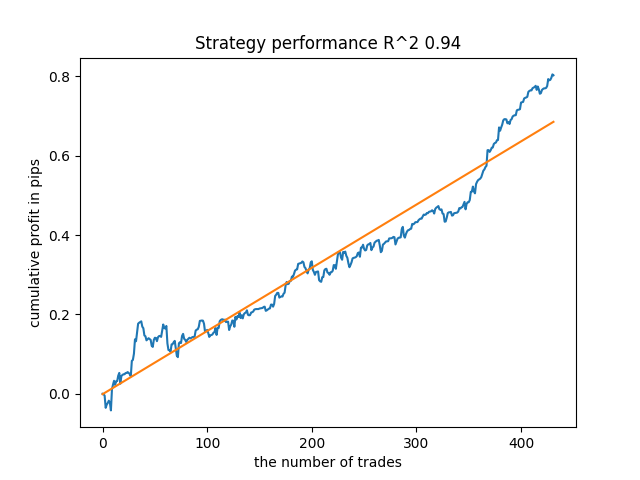
Но седьмой результат оказался предпочтительней с точки зрения количества сделок, которых оказалось в два раза больше. Суммарная прибыль в пунктах также выросла:
Экспорт моделей в MQL5 формат и компиляция торгового эксперта
Теперь сохраняться будут две модели: базовая и метамодель. Базовая, как и прежде, контролирует сигналы на покупку и продажу, тогда как метамодель запрещает или разрешает торговать в определенные моменты времени.
# add CatBosst base model code += 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n' # add CatBosst meta model code += 'double catboost_meta_model' + '(const double &features[]) { \n' code += ' ' with open('meta_catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
Код торгового эксперта изменен незначительно. Вызывается функция catboost_meta_model(), которая генерирует сигнал. Если он больше 0.5, то торговля разрешена.
void OnTick() { //--- if(!isNewBar()) return; TimeToStruct(TimeCurrent(), hours); double features[]; fill_arays(features); if(ArraySize(features) !=ArraySize(MAs)) { Print("No history availible, will try again on next signal!"); return; } double sig = catboost_model(features); double meta_sig = catboost_meta_model(features); // закрываем позиции по противоположному сигналу if(meta_sig > 0.5) if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } // открываем позиции и отложки по сигналам if(meta_sig > 0.5) if(countOrders() == 0 && CheckMoneyForTrade(_Symbol,LotsOptimized(),ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig < 0.5) { OrderSend(Symbol(),OP_BUY,l, Ask, 0, Bid-stoploss*_Point, Ask+takeprofit*_Point, NULL, OrderMagic); } else { OrderSend(Symbol(),OP_SELL,l, Bid, 0, Ask+stoploss*_Point, Bid-takeprofit*_Point, NULL, OrderMagic); } } }
Дополнения
Для пользователей MAC и Linux недоступно терминальное api для подгрузки котировок. Предлагаю воспользоваться другой функцией, которая принимает выгруженные из MetaTrader 5 терминала котировки в файл. Файл нужно сохранить в рабочую директорию.
def get_prices() -> pd.DataFrame:
p = pd.read_csv('EURUSDMT5.csv', delim_whitespace=True)
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], infer_datetime_format=True)
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
pFixed = pFixed.dropna()
pFixedC = pFixed.copy()
count = 0
for i in MA_PERIODS:
pFixed[str(count)] = pFixedC - pFixedC.rolling(i).mean()
count += 1
return pFixed.dropna() Теперь используются три даты. Благодаря этому можно сортировать модели как по бэк тесту так и по форвард тесту. Начало форварда задается глобальной переменной STOP_DATE, данные после этой даты не будут использованы в процессе обучения, но будут использованы в процессе тестирования. По аналогии, все что раньше TSTART_DATE - бэк тест.
START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2017, 1, 1) STOP_DATE = datetime(2022, 1, 1)
Не нужно забывать, что базовая модель обучается на данных за период START_DATE - STOP_DATE, а метамодель - на данных TSTART_DATE - STOP_DATE. Все остальные данные, оставшиеся в файле, участвуют только в бэк и форвард тестах.
Еще немного тестов
Я решил протестировать предложенный метод обучения на каком-нибудь кросс-курсе, например GBPJPY H1. Из терминала былы выгружены котировки с 2010 года. Количество признаков и периоды для обучения былы выбраны следующие:
MA_PERIODS = [i for i in range(15, 500, 15)] MARKUP = 0.00002 START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2018, 1, 1) STOP_DATE = datetime(2022, 1, 1)
Базовая модель обучается с 2021 по начало 2022 года, тогда как метамодель с 2018 по 2022. Все остальные данные используются для тестирования на новых данных, то есть с 2010 по 2022.06.15.
Семплинг сделок со случайной продолжительностью выбран в интервале 15-35.
def labelling_relabeling(dataset, min=15, max=35, relabeling=False):
И выбрано 25 итераций обучения и множитель для плохих примеров для книги примеров равный 0.5:
# iterative learning res = [] BAD_SAMPLES_BOOK = pd.DatetimeIndex([]) for i in range(25): res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.5)) print('Iteration: {}, R^2: {}'.format(i, res[-1][0])) pr = res[-1][3] # test best model res.sort() p = test_model(res[-1])
В процессе обучения получены такие значения оценок R^2 на всем датасете с 2010 года:
Iteration: 0, R^2: 0.8364212812476872 Iteration: 1, R^2: 0.8265960950867208 Iteration: 2, R^2: 0.8710535097094494 Iteration: 3, R^2: 0.820894300254345 Iteration: 4, R^2: 0.7271704621597865 Iteration: 5, R^2: 0.8746302835797399 Iteration: 6, R^2: 0.7746283871087961 Iteration: 7, R^2: 0.870806543378866 Iteration: 8, R^2: 0.8651222653557956 Iteration: 9, R^2: 0.9452164577256995 Iteration: 10, R^2: 0.867541289963404 Iteration: 11, R^2: 0.9759544230548619 Iteration: 12, R^2: 0.9063804006221455 Iteration: 13, R^2: 0.9609701853129079 Iteration: 14, R^2: 0.9666262255426672 Iteration: 15, R^2: 0.7046628448822643 Iteration: 16, R^2: 0.7750941894554821 Iteration: 17, R^2: 0.9436968900331276 Iteration: 18, R^2: 0.8961403809578388 Iteration: 19, R^2: 0.9627553719743711 Iteration: 20, R^2: 0.9559809326980575 Iteration: 21, R^2: 0.9578579606050637 Iteration: 22, R^2: 0.8095556721129047 Iteration: 23, R^2: 0.654147043077418 Iteration: 24, R^2: 0.7538928969905255
Далее модели были отсортированы по максимальному R^2, вот лучшие из них, в порядке убывания оценки.
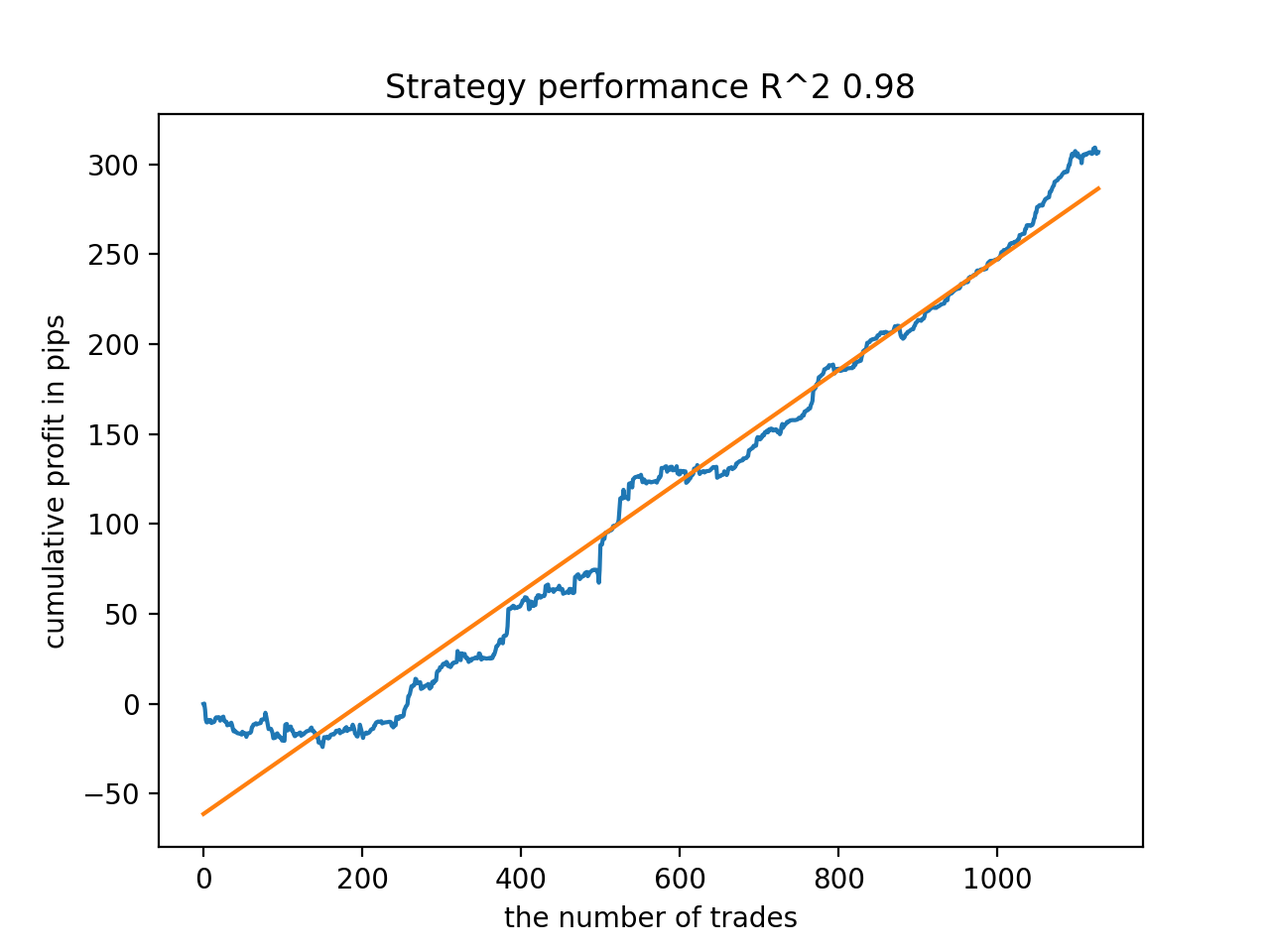
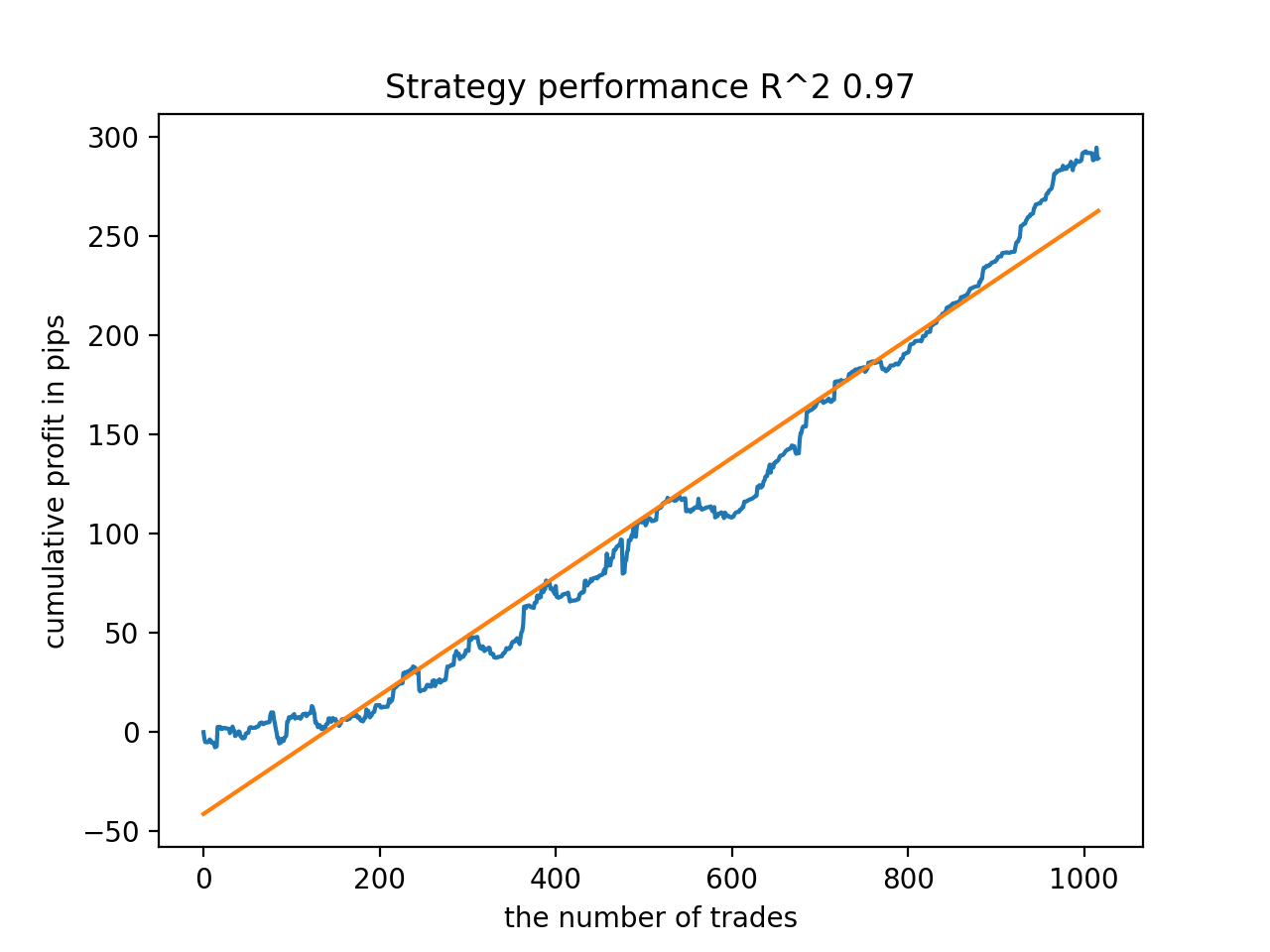
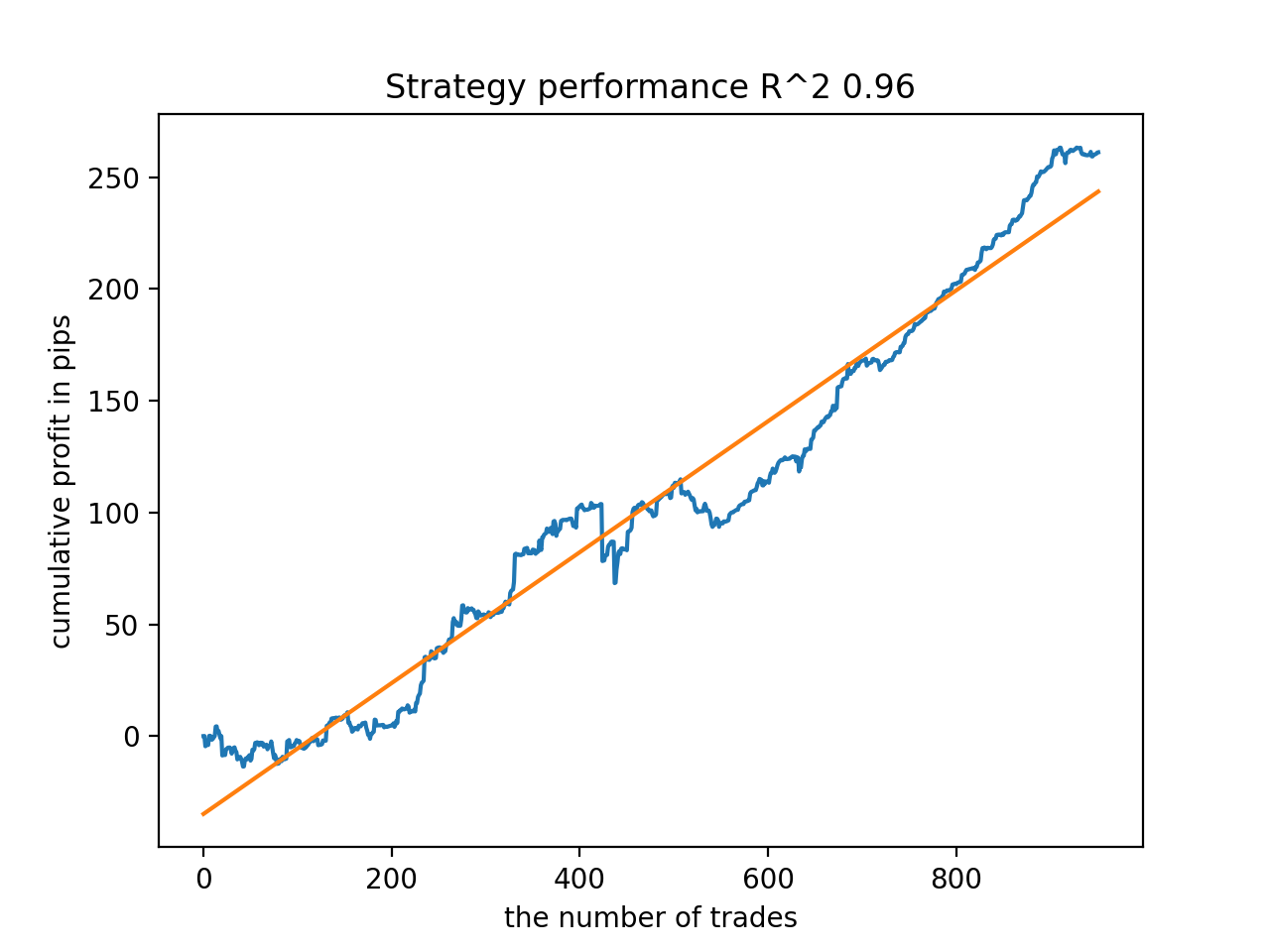
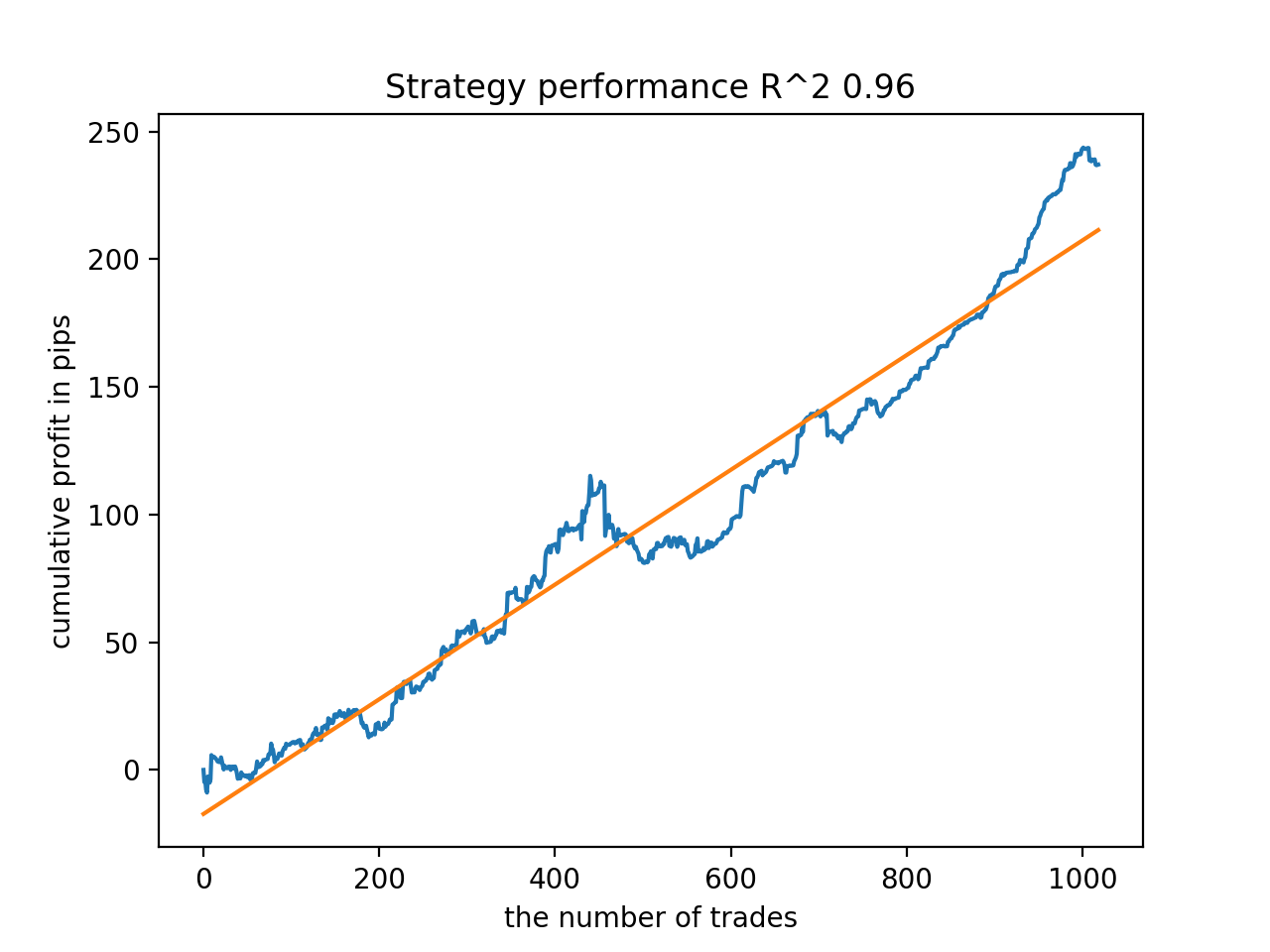
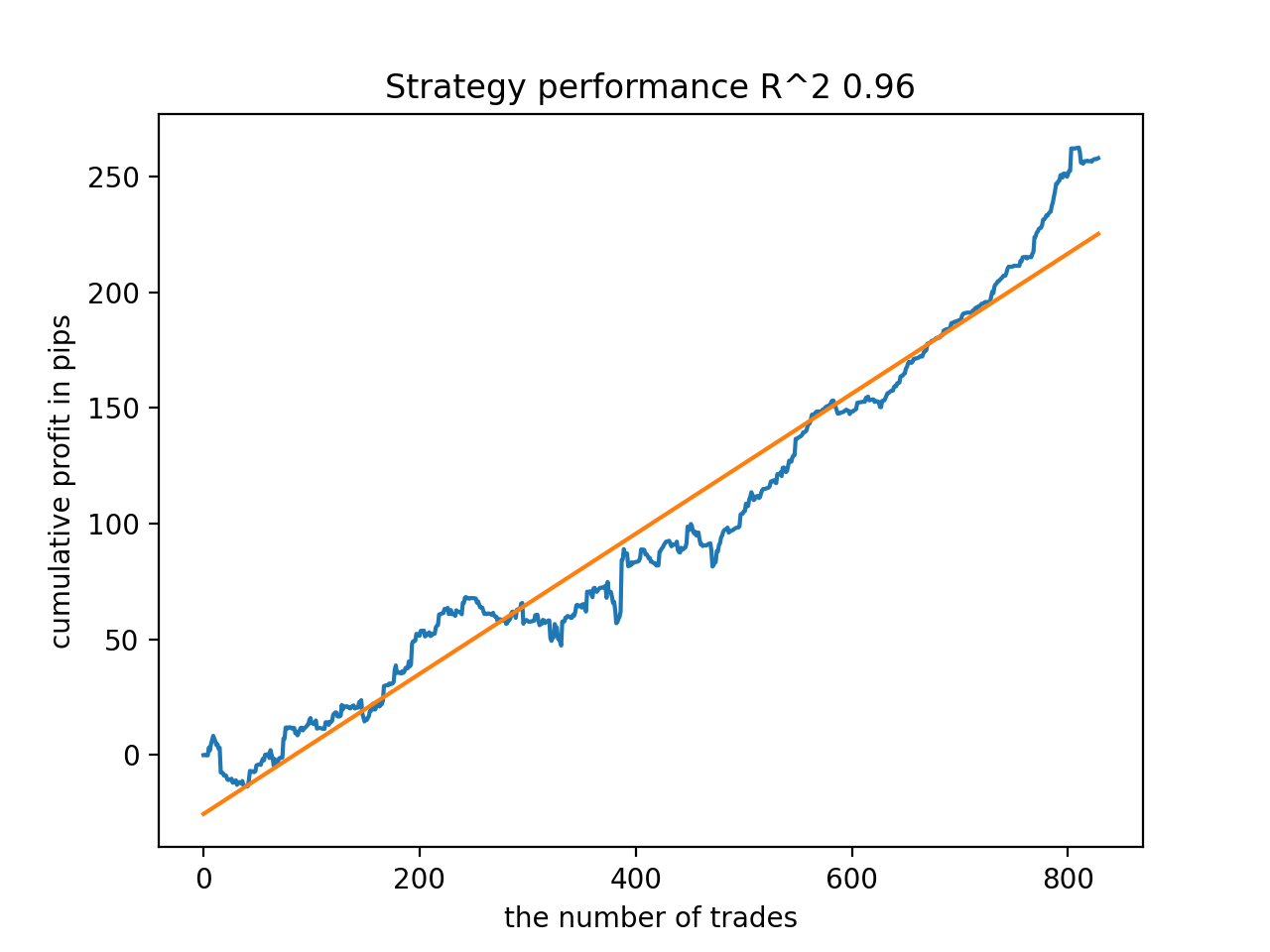
Все модели, в целом, достаточно устойчивы на периоде с 2010 года, хотя графики не представляют идеальные кривые.
На финальном этапе экспортируем заинтересовавшие модели в MetaTrader 5 для дополнительного тестирования или использования в торговле. Функция экспорта принимает на вход модель (в данном случае это лучшая с конца) и номер модели для изменения имени файла, чтобы можно было вести запись нескольких моделей одновременно.
export_model_to_MQL_code(res[-1], str(1))
Компилируем бота и проверяем в тестере стратегий MetaTrader 5.
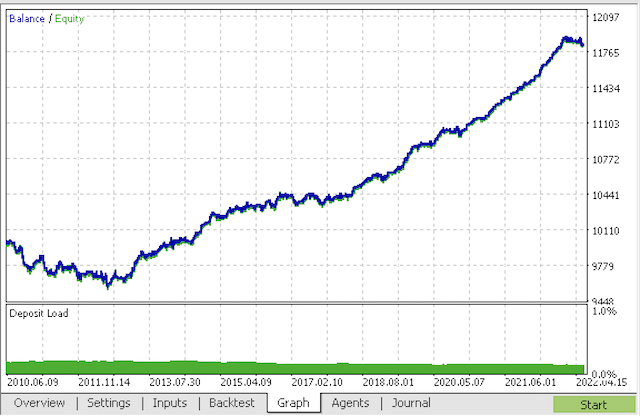
На финальном этапе вы можете работать с моделями уже в привычном терминале MetaTrader 5.
Заключение
Наверное, в этой статье создана и продемонстрирована самая сложная и изощренная модель классификации временных рядов, которую мне когда-либо приходилось реализовывать. Интересным моментом является способность автоматического выбрасывания сложно классифицируемых кусков истории посредством метамодели. Такие модели иногда даже превосходят сезонные, которые обучались торговать в специально отведенное время суток или день недели, где имеются выраженные сезонные циклы. Здесь же фильтрация по времени происходит на автомате, без участия человека.
 Разработка торговой системы на основе индикатора CCI
Разработка торговой системы на основе индикатора CCI
 Биржевая сеточная торговля лимитными ордерами на полном автомате на Московской бирже MOEX
Биржевая сеточная торговля лимитными ордерами на полном автомате на Московской бирже MOEX
 Нейросети — это просто (Часть 17): Понижение размерности
Нейросети — это просто (Часть 17): Понижение размерности
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Мой код работает чуть быстрей изначального :) Поэтому обучения проходит даже быстрей. Но я использую GPU.
Прошу пояснить, не ошибка ли это в коде
Правильным кажется такое выражение
Иначе первая строка просто не имеет смысла, так как во второй строке выполняется повторно условие копирование данных, что приводит к копированию без фильтрации по целевой "1" мета модели.
Я только учусь и могу быть не прав с этим питоном, поэтому и спрашиваю...
Да, вы правильно заметили, ваш код правильный
тоже есть более быстрая и вообще несколько другая версия, хотел залить, в виде статьи мбДа, вы правильно заметили, ваш код правильный
тоже есть более быстрая и вообще несколько другая версия, хотел залить, в виде статьи мбПишите, будет интересно.
Лучшее на обучении, что смог получить
А это на отдельной выборке
Добавил процесс инициализации через обучение.
Пишите, будет интересно.
Лучшее на обучении, что смог получить
А это на отдельной выборке
Добавил процесс инициализации через обучение.
Ну вот, уже в питоне разбираетесь
Я бы не утверждал, что разбираюсь - все со "словарём".
Мне интересно было найти какой то эффект от данного подхода. Пока я так и не понял, есть ли он. Так то на выборке обучается CatBoost, в целом, без всякой "магии" - баланс ниже на картинке. Поэтому ожидал результата более выразительного.
Я бы не утверждал, что разбираюсь - все со "словарём".
Мне интересно было найти какой то эффект от данного подхода. Пока я так и не понял, есть ли он. Так то на выборке обучается CatBoost, в целом, без всякой "магии" - баланс ниже на картинке. Поэтому ожидал результата более выразительного.