
Aprendizaje de máquinas en sistemas comerciales con cuadrícula y martingale. ¿Apostaría por ello?

Introducción
Bien, ya hemos trabajado intensamente e investigado varios enfoques para usar el aprendizaje de máquinas en la búsqueda de patrones en el mercado de divisas. El lector ya tiene una idea general de cómo entrenar e implementar modelos. Pero existe un gran número de enfoques comerciales, y casi todos pueden mejorarse con algoritmos modernos de aprendizaje automático. Uno de los más populares implica la cuadrícula y/o el martingale. Antes de escribir este artículo, hemos realizado un pequeño análisis exploratorio sobre la presencia de información en internet acerca de este tema. Para nuestra sorpresa, este enfoque, por algún motivo, no se ha tratado en absoluto en la red global. Además, a las preguntas realizadas a los miembros de la comunidad sobre las perspectivas de tal solución, la mayoría respondió que ni siquiera sabían cómo abordar este tema, pero que la idea en sí era interesante. Aunque, se diría, no tiene nada de complejo.
Vamos a realizar una serie de experimentos para nuestra propia tranquilidad. En primer lugar, queremos demostrar que esto no resulta tan complicado como podría parecer a primera vista. Y en segundo, averiguar si este enfoque es aplicable y eficaz.
Marcado de transacciones
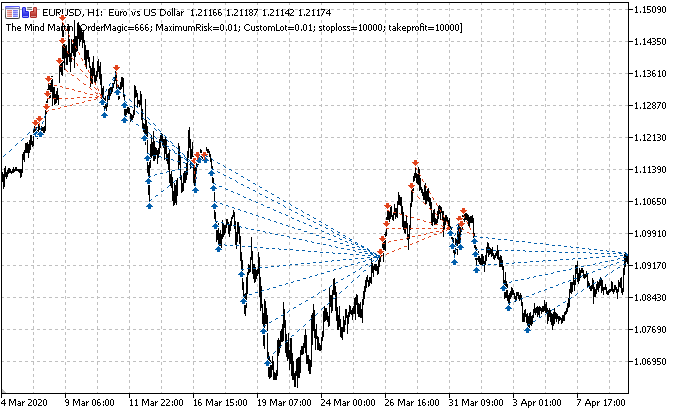
La tarea principal consiste en marcar correctamente las transacciones. Recordemos cómo hicimos esto para posiciones individuales en artículos anteriores. Establecíamos un horizonte de transacciones aleatorio o determinado, por ejemplo, de 15 barras. Si el mercado ascendía hasta estas 15 barras, entonces la transacción estaba marcada como transacción de compra, de lo contrario, como transacción de venta. Con la cuadrícula de órdenes, la lógica será similar, pero deberemos tener en cuenta el beneficio/pérdidas totales para un grupo de posiciones abiertas. Podemos ilustrar lo expuesto con un ejemplo sencillo. Hemos realizado el dibujo lo mejor posible, por favor, no sea demasiado crítico con él.
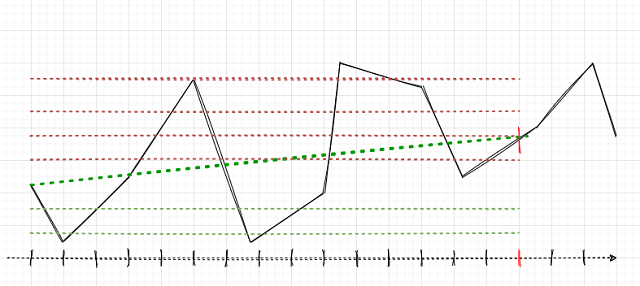
Supongamos que el horizonte de la transacción es de 15 (quince) barras (marcadas con un trazo rojo vertical en la escala de tiempo convencional). Si usamos una sola posición, se marcará para la compra (línea oblicua de puntos verdes), ya que el mercado ha ascendido de un punto a otro. Aquí, el mercado se muestra como una curva discontinua negra.
Con este marcado, no se tendrán en cuenta las oscilaciones intermedias del mercado. Si aplicamos una cuadrícula de órdenes (líneas horizontales rojas y verdes), deberemos calcular el beneficio total para todas las órdenes pendientes activadas más la orden abierta al principio (podemos abrir una posición y colocar la cuadrícula en la misma dirección, o bien no abrir una posición y limitarnos solo a una cuadrícula de órdenes pendientes). Dicho marcado continuará en una ventana deslizante en toda la profundidad de la historia de aprendizaje, mientras que la tarea de AA (aprendizaje automático) consistirá en generalizar la variedad de situaciones completa y predecir los nuevos datos de manera eficiente (si fuera posible).
En este caso, puede haber varias opciones para elegir la dirección del comercio y el marcado de datos: la elección de una de ellas constituye al mismo tiempo una tarea filosófica y experimental.
- Selección según el beneficio máximo total. Si la cuadrícula de venta ofrece más beneficios, marcaremos precisamente esta.
- Selección ponderada entre el número de órdenes abiertas y el beneficio total. Si el beneficio promedio para cada orden de la cuadrícula abierta es superior al del lado opuesto, seleccionaremos este lado.
- Selección según el número máximo de órdenes activadas. Como queremos que el robot comercie exactamente con una cuadrícula, resulta razonable elegir este enfoque. Si el número de órdenes activadas es el máximo y la posición total se encuentra en el beneficio, se seleccionará este lado. Aquí, entendemos por lado la dirección de la cuadrícula (venta o compra).
Para empezar, quizá estos tres criterios resulten suficientes. Por nuestra parte, querríamos centrarnos en el primero, ya que es el más simple y está orientado al beneficio máximo.
Marcando transacciones en el código
Vamos a recordar ahora cómo se realizaba el marcado de transacciones en los artículos anteriores.
def add_labels(dataset, min, max): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if future_pr + MARKUP < curr_pr: labels.append(1.0) elif future_pr - MARKUP > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index).reset_index(drop=True) return dataset
Este código debe generalizarse en el caso de la cuadrícula normal y la cuadrícula con martingale. Una característica destacable es que podemos analizar cuadrículas con diferente número de órdenes, con diferente distancia entre estas, e incluso aplicar un martingale (aumentando el lote).
Para hacer esto, añadiremos variables globales que se puedan iterar y optimizar más adelante.
GRID_SIZE = 10 GRID_DISTANCES = np.full(GRID_SIZE, 0.00200) GRID_COEFFICIENTS = np.linspace(1, 3, num= GRID_SIZE)
La variable GRID_SIZE contiene el número de órdenes en ambas direcciones.
La variable GRID_DISTANCES establece la distancia entre órdenes. Podemos seleccionar la distancia como fija o distinta para todas las órdenes. Esto nos ayudará a aumentar la flexibilidad del sistema comercial.
La variable GRID_COEFFICIENTS contiene los multiplicadores de lote para cada orden. Si los hacemos iguales, se utilizará una cuadrícula normal. Si son diferentes, será un martingale o un anti-martingale, o cualquier otro nombre aplicable a una cuadrícula con diferentes multiplicadores de lote.
Para aquellos que no conocen bien la biblioteca numpy:
- np.full llena una matriz con un número dado de valores idénticos
- np.linspace llena una matriz con un número especificado de valores uniformemente distribuidos entre dos números reales. En el ejemplo anterior, GRID_COEFFICIENTS contendrá lo siguiente.
array([1. , 1.22222222, 1.44444444, 1.66666667, 1.88888889, 2.11111111, 2.33333333, 2.55555556, 2.77777778, 3. ])
Por consiguiente, el multiplicador del primer lote será igual a uno, es decir, el lote básico especificado en la configuración del sistema comercial. Después, el resto de órdenes de la cuadrícula se encontrará en orden ascendente de 1 a 3. Para usar una cuadrícula con multiplicador fijo para todas las órdenes, llamaremos a np.full.
El registro de las órdenes activadas y no activadas puede parecer un poco complicado, por lo que deberemos crear algún tipo de estructura de datos. Hemos decidido crear un diccionario para registrar las órdenes y posiciones para cada caso (muestra) específico. En su lugar, podríamos utilizar un objeto Data Class o pandas Data Frame, o bien una matriz numpy estructurada. Quizá la última solución resultaría la más rápida, pero aquí no supone nada de importancia crítica.
En cada iteración para añadir una muestra al conjunto de entrenamiento, se creará un diccionario que almacenará información sobre la cuadrícula de órdenes. Aquí, quizá sea necesaria una explicación. El diccionario grid_stats contiene toda la información necesaria sobre la cuadrícula de órdenes actual desde el momento en que se abre hasta el momento en que se cierra.
def add_labels(dataset, min, max, distances, coefficients): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) all_pr = dataset['close'][i:i + rand + 1] grid_stats = {'up_range': all_pr[0] - all_pr.min(), 'dwn_range': all_pr.max() - all_pr[0], 'up_state': 0, 'dwn_state': 0, 'up_orders': 0, 'dwn_orders': 0, 'up_profit': all_pr[-1] - all_pr[0] - MARKUP, 'dwn_profit': all_pr[0] - all_pr[-1] - MARKUP } for i in np.nditer(distances): if grid_stats['up_state'] + i <= grid_stats['up_range']: grid_stats['up_state'] += i grid_stats['up_orders'] += 1 grid_stats['up_profit'] += (all_pr[-1] - all_pr[0] + grid_stats['up_state']) \ * coefficients[int(grid_stats['up_orders']-1)] grid_stats['up_profit'] -= MARKUP * coefficients[int(grid_stats['up_orders']-1)] if grid_stats['dwn_state'] + i <= grid_stats['dwn_range']: grid_stats['dwn_state'] += i grid_stats['dwn_orders'] += 1 grid_stats['dwn_profit'] += (all_pr[0] - all_pr[-1] + grid_stats['dwn_state']) \ * coefficients[int(grid_stats['dwn_orders']-1)] grid_stats['dwn_profit'] -= MARKUP * coefficients[int(grid_stats['dwn_orders']-1)] if grid_stats['up_profit'] > grid_stats['dwn_profit'] and grid_stats['up_profit'] > 0: labels.append(0.0) continue elif grid_stats['dwn_profit'] > 0: labels.append(1.0) continue labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index).reset_index(drop=True) return dataset
La variable all_pr contiene los precios desde el actual hasta el futuro; la necesitamos para calcular la propia cuadrícula. Para construir la cuadrícula, queremos conocer los intervalos de precio desde la primera barra hasta la última; estos se encuentran en las entradas del diccionario 'up_range' y 'dwn_range'. Las variables 'up_profit' y 'dwn_profit' contendrán el beneficio final obtenido de aplicar la cuadrícula de compra o venta en el intervalo actual de la historia. Estos valores se inicializan con el beneficio obtenido de la transacción inicialmente abierta según el mercado. Luego, se sumarán con las transacciones que se han abierto en la red, si se han activado órdenes pendientes.
Ahora, deberemos iterar en un ciclo por todas las variables GRID_DISTANCES y comprobar si se han activado las órdenes límite pendientes. Si una orden se encuentra en el intervalo up_range o dwn_range, significará que se ha activado. En este caso, se incrementarán los contadores up_state y dwn_state, respectivamente, encargados de almacenar el nivel de la última orden activada. En la siguiente iteración, se le suma a este nivel la distancia hasta la nueva orden de la cuadrícula, y si esta orden se encuentra en el intervalo de precios, significará que también se ha activado.
En todas las órdenes activadas, se registra la información adicional. Por ejemplo, al beneficio total se suma el beneficio de una orden pendiente. Para las posiciones de compra, este se calcula usando la siguiente fórmula. Aquí, el precio de apertura de la posición se resta del último precio (al que se supone que se cierra la posición) y se añade la distancia hasta la orden pendiente seleccionada en la serie; todo esto se multiplica por el coeficiente de aumento de lote para esta orden en la cuadrícula. Para las órdenes de venta, ocurre lo opuesto. Además, se calcula el etiquetado acumulado.
grid_stats['up_profit'] += (all_pr[-1] - all_pr[0] + grid_stats['up_state']) \ * coefficients[int(grid_stats['up_orders']-1)] grid_stats['up_profit'] -= MARKUP * coefficients[int(grid_stats['up_orders']-1)]
El siguiente bloque de código compara el beneficio de las cuadrículas de compra y venta. Si el beneficio (considerando el etiquetado acumulado) es mayor que cero y resulta máximo, entonces se añadirá la muestra correspondiente al conjunto de entrenamiento. Si no se cumple ninguna de las condiciones, se añadirá la marca 2.0; las muestras marcadas con esta marca se eliminan del conjunto de datos de entrenamiento como no informativas. Podemos cambiar estas condiciones más adelante, dependiendo de las opciones deseadas para la construcción de la cuadrícula que hemos descrito antes.
Actualizando el simulador para trabajar con una cuadrícula de órdenes
Para calcular correctamente el beneficio obtenido al comerciar con una cuadrícula, deberemos modificar el simulador de estrategias. Hemos decidido hacerlo lo más cercano posible al simulador de MetaTrader 5, en el sentido de que el simulador itere secuencialmente la historia de cotizaciones en un ciclo, y abra y cierre transacciones como si se tratara del comercio real. En este caso, se mejorará la comprensión del código y se descartará mirar hacia el futuro. Nos centraremos en los puntos principales del código, para que el lector también pueda entender el proceso. No hemos mostrado la versión anterior del simulador, pero podemos encontrarla en los listados de los artículos anteriores. Es de suponer que para la mayoría de los lectores, el código siguiente supondrá un bosque oscuro, y que les gustaría conseguir el Grial rápidamente, sin entrar en detalles. No obstante, debemos aclarar los puntos clave.
def tester(dataset, markup, distances, coefficients, plot=False): last_deal = int(2) all_pr = np.array([]) report = [0.0] for i in range(dataset.shape[0]): pred = dataset['labels'][i] all_pr = np.append(all_pr, dataset['close'][i]) if last_deal == 2: last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5: last_deal = 1 up_range = all_pr[0] - all_pr.min() up_state = 0 up_orders = 0 up_profit = (all_pr[-1] - all_pr[0]) - markup report.append(report[-1] + up_profit) up_profit = 0 for d in np.nditer(distances): if up_state + d <= up_range: up_state += d up_orders += 1 up_profit += (all_pr[-1] - all_pr[0] + up_state) \ * coefficients[int(up_orders-1)] up_profit -= markup * coefficients[int(up_orders-1)] report.append(report[-1] + up_profit) up_profit = 0 all_pr = np.array([dataset['close'][i]]) continue if last_deal == 1 and pred < 0.5: last_deal = 0 dwn_range = all_pr.max() - all_pr[0] dwn_state = 0 dwn_orders = 0 dwn_profit = (all_pr[0] - all_pr[-1]) - markup report.append(report[-1] + dwn_profit) dwn_profit = 0 for d in np.nditer(distances): if dwn_state + d <= dwn_range: dwn_state += d dwn_orders += 1 dwn_profit += (all_pr[0] + dwn_state - all_pr[-1]) \ * coefficients[int(dwn_orders-1)] dwn_profit -= markup * coefficients[int(dwn_orders-1)] report.append(report[-1] + dwn_profit) dwn_profit = 0 all_pr = np.array([dataset['close'][i]]) continue y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.figure(figsize=(12,7)) plt.plot(report) plt.plot(lr.predict(X)) plt.title("Strategy performance") plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
Históricamente, a los tráders de cuadrículas solo les interesa la curva de balance: la curva de equidad no es algo a lo que presten atención. Vamos a continuar esta tradición y no complicar demasiado un simulador ya de por sí complejo. Mostraremos solo el gráfico de balance, recordando, eso sí, que siempre podremos consultar la curva de equidad en el terminal MetaTrader 5.
En un ciclo, recorremos todos los precios y añadimos estos a la matriz all_pr. Luego, tenemos las tres opciones marcadas abajo. Como ya hemos analizado el simulador en artículos anteriores, solo explicaremos las opciones que permiten cerrar una cuadrícula de órdenes al darse una señal opuesta. Al igual que sucede al marcar transacciones, la variable up_range almacena el intervalo de precios pasados en el momento en que se cierran las posiciones abiertas. A continuación, calcularemos el beneficio de la primera posición abrierta según el mercado. Luego, comprobaremos en un ciclo la presencia de órdenes pendientes activadas y, si se han activado, añadiremos su resultado al gráfico de balance. Lo mismo ocurrirá con las órdenes/posiciones de venta. Por consiguiente, el gráfico de balance reflejará todas las posiciones cerradas, no el beneficio total por grupos.
Probando los nuevos métodos de trabajo con cuadrículas de órdenes
La etapa de preparación de datos para el aprendizaje automático tiene un aspecto bastante familiar. Primero, obtenemos los precios y el conjunto de características, luego marcamos los datos (creamos las etiquetas de compra y venta) y después comprobamos el marcado en el simulador personalizado.
# Get prices and labels and test it pr = get_prices(START_DATE, END_DATE) pr = add_labels(pr, 15, 15, GRID_DISTANCES, GRID_COEFFICIENTS) tester(pr, MARKUP, GRID_DISTANCES, GRID_COEFFICIENTS, plot=True)
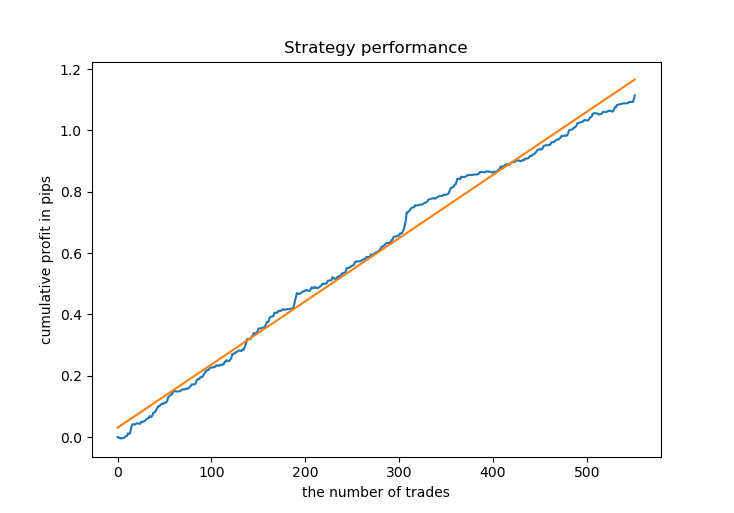
Ahora, necesitamos entrenar el modelo CatBoost y ponerlo a prueba con los nuevos datos. Hemos decidido dejar el entrenamiento con los datos sintéticos generados por el modelo de mezcla gaussiana, ya que funciona bien.
# Learn and test CatBoost model gmm = mixture.GaussianMixture( n_components=N_COMPONENTS, covariance_type='full', n_init=1).fit(pr[pr.columns[1:]]) res = [] for i in range(10): res.append(brute_force(10000)) print('Iteration: ', i, 'R^2: ', res[-1][0]) res.sort() test_model(res[-1])
En este ejemplo, entrenaremos diez modelos con 10,000 muestras generadas y seleccionaremos el mejor a través de una puntuación R^2. El proceso de aprendizaje será el siguiente.
Iteration: 0 R^2: 0.8719436661855786 Iteration: 1 R^2: 0.912006346274096 Iteration: 2 R^2: 0.9532278725035132 Iteration: 3 R^2: 0.900845571741786 Iteration: 4 R^2: 0.9651728908727953 Iteration: 5 R^2: 0.966531822300101 Iteration: 6 R^2: 0.9688263099200539 Iteration: 7 R^2: 0.8789927823514787 Iteration: 8 R^2: 0.6084261786804662 Iteration: 9 R^2: 0.884741078512629
La mayoría de los modelos tienen una puntuación R^2 alta con los datos nuevos, lo cual indica una alta estabilidad del modelo. Como resultado, el gráfico de balance de los datos de entrenamiento y los datos fuera del entrenamiento tiene este aspecto.
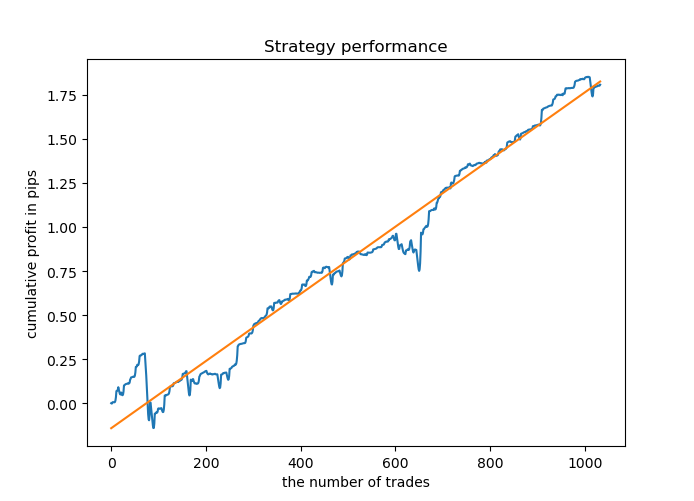
No tiene mala pimta. Ahora, podemos exportar el modelo entrenado a MetaTrader 5 y comprobar su rendimiento usando el simulador de terminal. Para hacerlo, necesitaremos preparar el asesor comercial y el archivo de inclusión. Cada modelo entrenado tendrá su propio archivo, por lo que resultará sencillo almacenarlos y cambiarlos entre sí.
Exportando el modelo CatBoost a MQL5
Para exportar el modelo, llamaremos a la siguiente función:
export_model_to_MQL_code(res[-1][1])
La función ha sufrido algunos cambios que debemos explicar.
def export_model_to_MQL_code(model):
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
# add variables
code = '#include <Math\Stat\Math.mqh>'
code += '\n'
code += 'int MAs[' + str(len(MA_PERIODS)) + \
'] = {' + ','.join(map(str, MA_PERIODS)) + '};'
code += '\n'
code += 'int grid_size = ' + str(GRID_SIZE) + ';'
code += '\n'
code += 'double grid_distances[' + str(len(GRID_DISTANCES)) + \
'] = {' + ','.join(map(str, GRID_DISTANCES)) + '};'
code += '\n'
code += 'double grid_coefficients[' + str(len(GRID_COEFFICIENTS)) + \
'] = {' + ','.join(map(str, GRID_COEFFICIENTS)) + '};'
code += '\n'
# get features
code += 'void fill_arays( double &features[]) {\n'
code += ' double pr[], ret[];\n'
code += ' ArrayResize(ret, 1);\n'
code += ' for(int i=ArraySize(MAs)-1; i>=0; i--) {\n'
code += ' CopyClose(NULL,PERIOD_CURRENT,1,MAs[i],pr);\n'
code += ' double mean = MathMean(pr);\n'
code += ' ret[0] = pr[MAs[i]-1] - mean;\n'
code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n'
code += ' ArraySetAsSeries(features, true);\n'
code += '}\n\n'
# add CatBosst
code += 'double catboost_model' + '(const double &features[]) { \n'
code += ' '
with open('catmodel.h', 'r') as file:
data = file.read()
code += data[data.find("unsigned int TreeDepth")
:data.find("double Scale = 1;")]
code += '\n\n'
code += 'return ' + \
'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
code += 'double ApplyCatboostModel(const double &features[],uint &TreeDepth_[],uint &TreeSplits_[],uint &BorderCounts_[],float &Borders_[],double &LeafValues_[]) {\n\
uint FloatFeatureCount=ArrayRange(BorderCounts_,0);\n\
uint BinaryFeatureCount=ArrayRange(Borders_,0);\n\
uint TreeCount=ArrayRange(TreeDepth_,0);\n\
bool binaryFeatures[];\n\
ArrayResize(binaryFeatures,BinaryFeatureCount);\n\
uint binFeatureIndex=0;\n\
for(uint i=0; i<FloatFeatureCount; i++) {\n\
for(uint j=0; j<BorderCounts_[i]; j++) {\n\
binaryFeatures[binFeatureIndex]=features[i]>Borders_[binFeatureIndex];\n\
binFeatureIndex++;\n\
}\n\
}\n\
double result=0.0;\n\
uint treeSplitsPtr=0;\n\
uint leafValuesForCurrentTreePtr=0;\n\
for(uint treeId=0; treeId<TreeCount; treeId++) {\n\
uint currentTreeDepth=TreeDepth_[treeId];\n\
uint index=0;\n\
for(uint depth=0; depth<currentTreeDepth; depth++) {\n\
index|=(binaryFeatures[TreeSplits_[treeSplitsPtr+depth]]<<depth);\n\
}\n\
result+=LeafValues_[leafValuesForCurrentTreePtr+index];\n\
treeSplitsPtr+=currentTreeDepth;\n\
leafValuesForCurrentTreePtr+=(1<<currentTreeDepth);\n\
}\n\
return 1.0/(1.0+MathPow(M_E,-result));\n\
}'
file = open('C:/Users/dmitrievsky/AppData/Roaming/MetaQuotes/Terminal/D0E8209F77C8CF37AD8BF550E51FF075/MQL5/Include/' +
str(SYMBOL) + '_cat_model_martin' + '.mqh', "w")
file.write(code)
file.close()
print('The file ' + 'cat_model' + '.mqh ' + 'has been written to disc') Ahora, se guardan los ajustes de cuadrícula utilizados al realizar el entrenamiento. Precisamente estos se usarán en el comercio.
La media móvil del paquete estándar del terminal y los búferes de indicador ya no se utilizan. En cambio, calcularemos todas las características en el cuerpo de la función. Al añadir sus características originales, también deberemos agregarlas a la función de exportación.
La ruta hasta la carpeta Include del terminal está marcada en verde, para así poder guardar el archivo .mqh e incluir este en el asesor experto.
Veamos qué aspecto tiene ahora el archivo .mqh (hemos omitido aquí el modelo CatBoost)
#include <Math\Stat\Math.mqh> int MAs[14] = {5,25,55,75,100,125,150,200,250,300,350,400,450,500}; int grid_size = 10; double grid_distances[10] = {0.003,0.0035555555555555557,0.004111111111111111,0.004666666666666666,0.005222222222222222, 0.0057777777777777775,0.006333333333333333,0.006888888888888889,0.0074444444444444445,0.008}; double grid_coefficients[10] = {1.0,1.4444444444444444,1.8888888888888888,2.333333333333333, 2.7777777777777777,3.2222222222222223,3.6666666666666665,4.111111111111111,4.555555555555555,5.0}; void fill_arays( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(MAs)-1; i>=0; i--) { CopyClose(NULL,PERIOD_CURRENT,1,MAs[i],pr); double mean = MathMean(pr); ret[0] = pr[MAs[i]-1] - mean; ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Como podemos ver, todos los ajustes de la cuadrícula han sido guardados y el modelo está listo para funcionar: solo tenemos que conectarlo al asesor experto.
#include <EURUSD_cat_model_martin.mqh> Ahora, tenemos que explicar la lógica de procesamiento de las señales por parte del asesor experto utilizando como ejemplo todo lo que opera en la función OnTick(). El bot utiliza la biblioteca MT4Orders, que deberemos descargar.
void OnTick() { //--- if(!isNewBar()) return; TimeToStruct(TimeCurrent(), hours); double features[]; fill_arays(features); if(ArraySize(features) !=ArraySize(MAs)) { Print("No history availible, will try again on next signal!"); return; } double sig = catboost_model(features); // Close positions by an opposite signal if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } // Delete all pending orders if there are no pending orders if(!count_market_orders(0) && !count_market_orders(1)) { for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 2 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic ) if(OrderDelete(OrderTicket())) { } if(OrderType() == 3 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic ) if(OrderDelete(OrderTicket())) { } } } // Open positions and pending orders by signals if(countOrders() == 0 && CheckMoneyForTrade(_Symbol,LotsOptimized(),ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig < 0.5) { OrderSend(Symbol(),OP_BUY,l, Ask, 0, Bid-stoploss*_Point, Ask+takeprofit*_Point, NULL, OrderMagic); double p = Ask; for(int i=0; i<grid_size; i++) { p = NormalizeDouble(p - grid_distances[i], _Digits); double gl = NormalizeDouble(l * grid_coefficients[i], 2); OrderSend(Symbol(),OP_BUYLIMIT,gl, p, 0, p-stoploss*_Point, p+takeprofit*_Point, NULL, OrderMagic); } } else { OrderSend(Symbol(),OP_SELL,l, Bid, 0, Ask+stoploss*_Point, Bid-takeprofit*_Point, NULL, OrderMagic); double p = Ask; for(int i=0; i<grid_size; i++) { p = NormalizeDouble(p + grid_distances[i], _Digits); double gl = NormalizeDouble(l * grid_coefficients[i], 2); OrderSend(Symbol(),OP_SELLLIMIT,gl, p, 0, p+stoploss*_Point, p-takeprofit*_Point, NULL, OrderMagic); } } } }
La función fill_arrays prepara las características para el modelo CatBoost, rellenando luego la matriz features con ellas. A continuación, esta matriz es transmitida a la función catboost_model(), que retorna una señal en el intervalo 0;1.
Como podemos ver en el ejemplo con órdenes Buy, aquí se usa la variable grid_size. Esta muestra el número de órdenes pendientes que se encuentran entre sí a una distancia grid_distances. El lote estándar se multiplica por el coeficiente de la matriz grid_coefficients, que se corresponde con el número ordinal de la orden.
Una vez compilado el bot, podemos proseguir con la prueba.
Poniendo a prueba el bot en el simulador de MetaTrader 5
Debemos realizar la prueba en el marco temporal con el que se ha entrenado el bot. En este caso, hablamos de H1. Podemos realizar la simulación con los precios de apertura, ya que el bot tiene control explícito sobre la apertura de las barras. Sin embargo, como utilizamos una cuadrícula, podemos seleccionar M1 OHLC para mayor precisión.
Este bot en concreto se ha entrenado con el periodo:
START_DATE = datetime(2020, 5, 1) TSTART_DATE = datetime(2019, 1, 1) FULL_DATE = datetime(2018, 1, 1) END_DATE = datetime(2022, 1, 1)
- El periodo de entrenamiento comienza el quinto mes del año 2020 y termina en la actualidad. Dicho periodo se dividirá en submuestras de entrenamiento y validación en una proporción de 50/50.
- A partir del primer mes de 2019, el modelo ha sido evaluado según R^2, seleccionándose luego el mejor.
- Desde el primer mes de 2018, el modelo ha sido probado en un simulador personalizado.
- Para el entrenamiento, seleccionamos los datos sintéticos (generados por el modelo de mezcla gaussiana)
- El modelo CatBoost tiene una fuerte regularización; gracias a ello, no se ajusta al conjunto de entrenamiento.
Todos estos factores indican (y el simulador personalizado lo ha confirmado) que hemos encontrado un cierto patrón en el intervalo que va desde el año 2018 hasta la actualidad.
Veamos qué aspecto tiene en el simulador MT5.
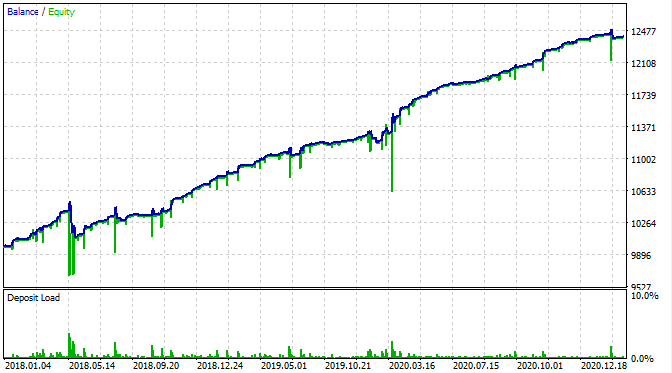
Si obviamos que las reducciones de capital ahora resultan visibles, el gráfico de balance se ve igual que en nuestro simulador personalizado. Y esto es una buena noticia. Vamos a comprobar que el bot esté operando precisamente con la cuadrícula y nada más.
Hemos probado el bot desde principios de 2015 y ha mostrado el siguiente resultado.
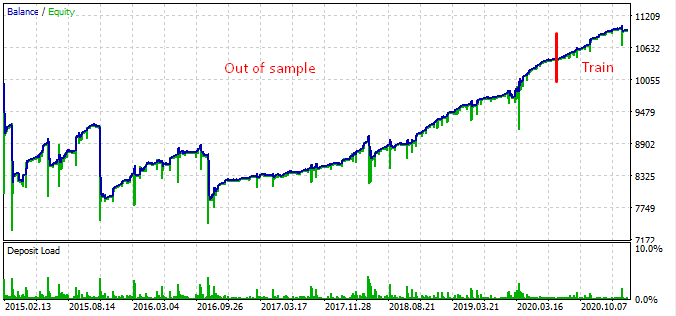
A partir del gráfico, podemos deducir que el patrón detectado funciona desde finales de 2016 hasta el día de hoy, y luego se descompone. En este caso, el lote inicial era el mínimo, por lo que el bot no ha perdido todo. Bien, sabemos que el bot ha funcionado desde principios de 2017 y que puede aumentar el riesgo para incrementar la rentabilidad. En este caso, ha mostrado un impresionante 1600% en 3 años con una reducción del 40% y un riesgo hipotético de pérdida completa del depósito.
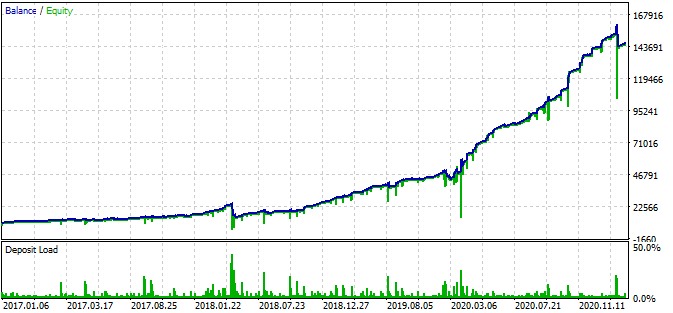
Asimismo, el robot usa stop loss y take profit para cada posición. Podemos usarlos, sacrificando parte del rendimiento y limitando los riesgos.
Hay que señalar que hemos utilizado una cuadrícula bastante agresiva.
GRID_COEFFICIENTS = np.linspace(1, 5, num= GRID_SIZE)
array([1. , 1.44444444, 1.88888889, 2.33333333, 2.77777778, 3.22222222, 3.66666667, 4.11111111, 4.55555556, 5. ])
El último factor es igual a cinco. Esto significa que el lote de la última orden de la serie es cinco veces superior al inicial, lo cual conlleva riesgos adicionales. Podemos elegir modos más moderados.
¿Por qué dejó de funcionar el bot en 2016 y antes? No tenemos una respuesta racional a esta pregunta. Parece ser que en FóREX existen ciclos largos de siete años o menos, cuyos patrones no están conectados entre sí de ninguna forma. Este es un tema aparte que demanda un análisis meticuloso.
Conclusión
En este artículo, hemos intentado describir una técnica que permite entrenar un modelo de boosting o una red neuronal para comerciar con martingale. Asimismo, hemos propuesto una solución lista para usar que nos permite crear nuestros propios robots comerciales.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/8826
 Redes neuronales: así de sencillo (Parte 12): Dropout
Redes neuronales: así de sencillo (Parte 12): Dropout
 Técnicas útiles y exóticas para el comercio automático
Técnicas útiles y exóticas para el comercio automático
 Redes neuronales: así de sencillo (Parte 11): Variaciones de GTP
Redes neuronales: así de sencillo (Parte 11): Variaciones de GTP
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Muchas gracias por tu interesante artículo.
¿Podría concluir que tu sistema adapta automáticamente el "step" y el coeficiente del martingala, de acuerdo a las condiciones del mercado?, o por el contrario, hay que hace el backtest en python y generar el archivo "include" periodicamente.
Gracias de nuevo.