
Redes neurais de Maneira Fácil (Parte 6): Experimentos com a taxa de aprendizado da rede neural

Conteúdo
- Introdução
- 1. O problema
- 2. Experimento 1
- 3. Experimento 2
- 4. Experimento 3
- Conclusões
- Referências
- Programas utilizados no artigo
Introdução
Nos artigos anteriores, nós estudamos os princípios da operação e os métodos de implementação das redes perceptron totalmente conectadas, convolucionais e recorrentes. Nós usamos o gradiente descendente para treinar todas as redes. De acordo com esse método, nós determinamos o erro de predição da rede em cada passo e ajustamos os pesos em um esforço para diminuir o erro. No entanto, nós não eliminamos completamente o erro em cada passo, apenas ajustamos os pesos para reduzir o erro. Assim, nós estamos tentando encontrar os pesos que irão repetir de perto o conjunto de treinamento ao longo de todo o seu comprimento. A taxa de aprendizado é responsável pela velocidade de minimização do erro em cada passo.
1. O problema
Qual é o problema com a seleção da taxa de aprendizado? Vamos delinear as questões básicas relacionadas à seleção da taxa de aprendizado.
1. Por que nós não podemos usar a taxa igual a "1" (ou um valor próximo) e compensar imediatamente o erro?
Nesse caso, nós teríamos uma rede neural treinada em excesso para a última situação. Como resultado, outras decisões serão tomadas com base apenas nos dados mais recentes, ignorando o histórico.
2. Qual é o problema de uma taxa reconhecidamente pequena, que permitiria a média dos valores de toda a amostra?
O primeiro problema com essa abordagem é o tempo de treinamento da rede neural. Se a taxa de aprendizado for muito pequena, será necessário um grande número de passos. Isso requer tempo e recursos.
O segundo problema com essa abordagem é que o caminho para a meta nem sempre é fácil. Pode haver vales e colinas. Se nós avançarmos em passos muito pequenos, nós podemos ficar presos em um desses valores, determinando-o erroneamente como um mínimo global. Nesse caso, nós nunca alcançaremos a meta. Isso pode ser parcialmente resolvido usando um impulso na fórmula de atualização do peso, mas o problema ainda existe.

3. Qual é o problema de uma taxa sabidamente grande, que permitiria calcular a média dos valores em uma certa distância e evitar os mínimos locais?
Uma tentativa de resolver o problema do mínimo local aumentando a taxa de aprendizado leva a outro problema: o uso de uma grande taxa de aprendizado muitas vezes não permite minimizar o erro, pois com a próxima atualização dos pesos sua mudança será maior que a necessária e, como resultado, saltaremos em torno do mínimo global. Se nós voltarmos a isso mais uma vez, a situação será semelhante. Como resultado, nós vamos oscilar em torno do mínimo global.

Esses são problemas bem conhecidos e frequentemente discutidos, mas eu não encontrei nenhuma recomendação clara com relação à seleção da taxa de aprendizado. Todos sugerem a seleção empírica da taxa para cada tarefa específica. Alguns outros autores sugerem a redução gradual da taxa durante o processo de aprendizagem, a fim de minimizar o risco 3 descrito acima.
Neste artigo, eu proponho realizar alguns experimentos treinando uma rede neural com diferentes taxas de aprendizado e ver o efeito desse parâmetro no treinamento da rede neural como um todo.
2. Experimento 1
Por conveniência, vamos tornar em uma variável global a variável eta da classe CNeuronBaseOCL.
double eta=0.01; #include "NeuroNet.mqh"
e
class CNeuronBaseOCL : public CObject { protected: ........ ........ //--- //const double eta;
Agora, criamos três cópias do Expert Advisor com diferentes parâmetros de taxa de aprendizado (0.1; 0.01; 0.001). Além disso, criamos o quarto EA, no qual a taxa de aprendizado inicial é definida como 0.01 e será reduzida em 10 vezes a cada 10 épocas. Para fazer isso, adicionamos o seguinte código ao loop de treinamento na função Train.
if(discount>0) discount--; else { eta*=0.1; discount=10; }
Todos os quatro EAs foram lançados simultaneamente na plataforma. Neste experimento, eu usei os parâmetros de teste dos EA anteriores: símbolo EURUSD, tempo gráfico H1, alimentando a rede com os dados das 20 velas consecutivas e o treinamento é executado usando o histórico dos últimos dois anos. A amostra de treinamento foi de cerca de 12.4 mil barras.
Todos os EAs foram inicializados com os pesos aleatórios variando de -1 a 1, excluindo os valores iguais a zero.
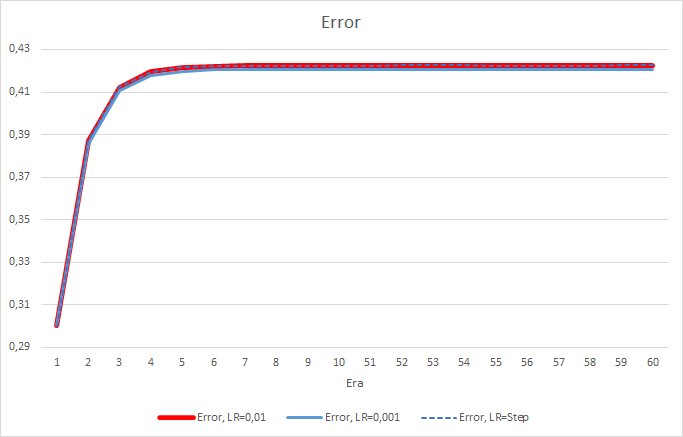
Infelizmente, o EA com a taxa de aprendizado igual a 0.1 apresentou um erro próximo de 1 e, portanto, ele não é exibido nos gráficos. A dinâmica de aprendizagem dos outros EAs é exibida nos gráficos abaixo.
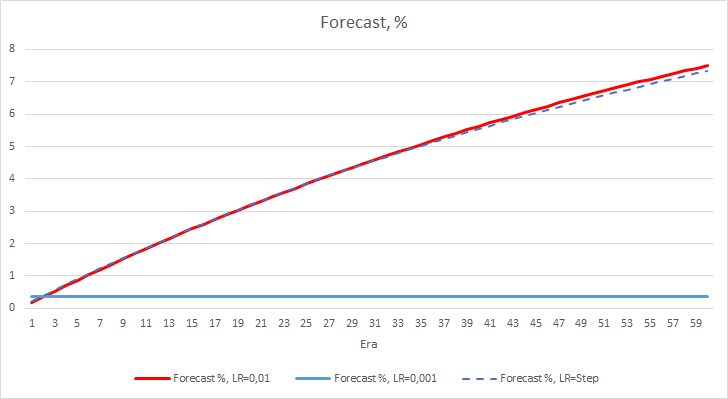
Após 5 épocas, o erro de todos os EAs atingiu o nível de 0.42, onde ele continuou a flutuar em torno disso pelo resto do tempo. O erro do EA com a taxa de aprendizado igual a 0.001 foi um pouco menor. As diferenças apareceram na terceira casa decimal (0.420 contra 0.422 dos outros dois EAs).
A trajetória de erro do EA com uma taxa de aprendizado variável segue a linha de erro do EA com um fator de aprendizagem de 0.01. Isso é bastante esperado nas primeiras dez épocas, mas não há desvio quando a taxa diminui.
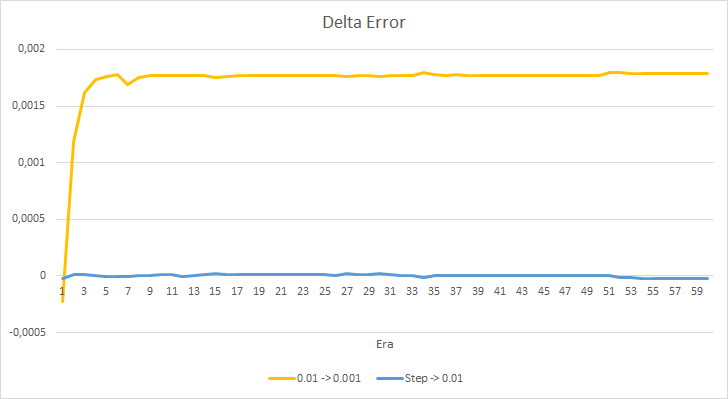
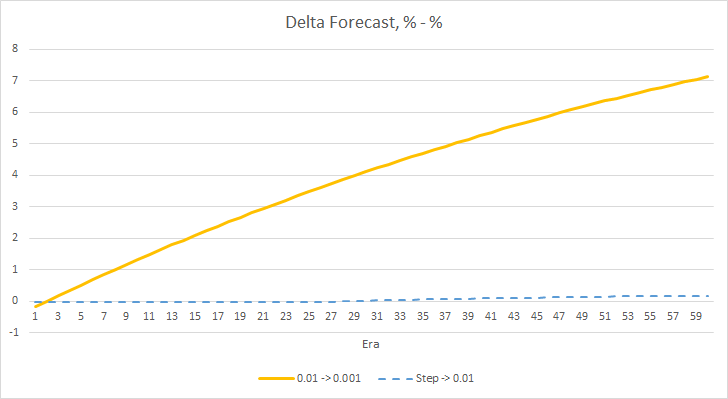
Vamos observar em mais detalhes a diferença entre os erros dos EAs acima. Quase ao longo de todo o experimento, a diferença entre os erros dos EAs com as taxas de aprendizado constantes de 0.01 e 0.001 oscilou em torno de 0.0018. Além disso, a diminuição na taxa de aprendizado do EA a cada 10 épocas quase não tem efeito e o desvio do EA com uma taxa de 0.01 (igual à taxa de aprendizado inicial) flutua em torno de 0.
Os valores de erro obtidos mostram que a taxa de aprendizado de 0.1 não é aplicável em nosso caso. O uso de uma taxa de aprendizado de 0.01 e inferior produz resultados semelhantes com um erro de cerca de 42%.
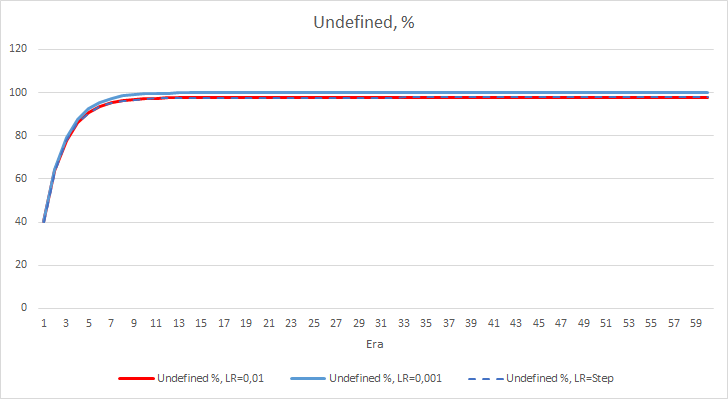
O erro estatístico da rede neural é bem claro. Como isso afetará o desempenho do EA? Vamos verificar o número de fractais perdidos. Infelizmente, todos os EAs mostraram resultados ruins durante o experimento: todos eles perderam quase 100% dos fractais. Além disso, um EA com a taxa de aprendizado de 0.01 determina cerca de 2.5% de fractais, enquanto com a taxa de 0.001 o EA pulou 100% os fractais. Após a 52ª época, o EA com taxa de aprendizado de 0.01 apresentou tendência em diminuir o número de fractais perdidos. Tal tendência não foi evidenciada pelo EA com a taxa variável.
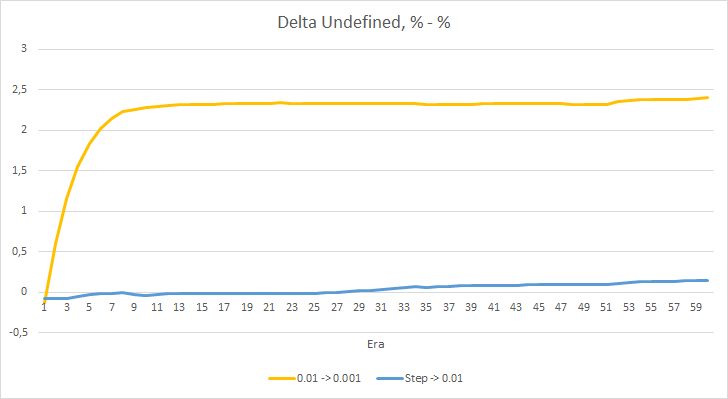
O gráfico de deltas de porcentagem de fractal ausente também mostra um aumento gradual na diferença a favor do EA com uma taxa de aprendizado de 0.01.
Nós consideramos duas métricas de desempenho da rede neural e, até agora, o EA com uma taxa de aprendizado mais baixa tem um erro menor, mas perde fractais. Agora, vamos verificar o terceiro valor: "acerto" dos fractais previstos.
Os gráficos abaixo mostram um crescimento da porcentagem de "acertos" no treinamento dos EAs com uma taxa de aprendizado de 0.01 e com uma taxa decrescente dinamicamente. A taxa de crescimento variável diminui com uma diminuição na taxa de aprendizado. O EA com a taxa de aprendizado de 0.001 teve a porcentagem de "acerto" presa em torno de 0, o que é bastante natural porque falha 100% dos fractais.
O experimento acima mostra que a taxa ideal de aprendizado ou treinamento de uma rede neural em nosso problema está perto de 0.01. Uma diminuição gradual na taxa de aprendizado não deu um resultado positivo. Talvez o efeito da redução da taxa seja diferente se nós diminuirmos com menos frequência do que em 10 épocas. Talvez os resultados sejam melhores com 100 ou 1000 épocas. No entanto, isso precisa ser verificado experimentalmente.
3. Experimento 2
No primeiro experimento, as matrizes de peso da rede neural foram inicializadas aleatoriamente. E, portanto, todos os EAs tinham estados iniciais diferentes. Para eliminar a influência da aleatoriedade nos resultados do experimento, carregamos a matriz de peso obtida no experimento anterior com o EA tendo uma taxa de aprendizado igual a 0.01 em todos os três EAs e continuamos o treinamento por mais 30 épocas.
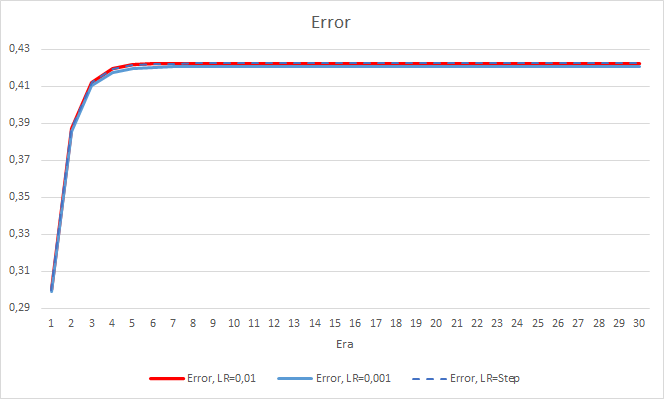
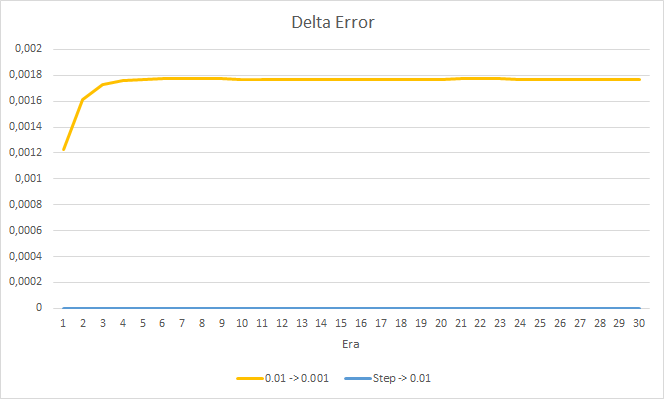
O novo treinamento confirma os resultados obtidos anteriormente. Vemos um erro médio em torno de 0.42 nos três EAs. O EA com a menor taxa de aprendizado (0.001) novamente teve um erro um pouco menor (com a mesma diferença de 0.0018). O efeito de uma diminuição gradual na taxa de aprendizado é praticamente igual a 0.
Quanto à porcentagem de fractais perdidos, os resultados obtidos anteriormente são confirmados novamente. O EA com um fator de aprendizado menor se aproximou de 100% dos fractais perdidos em 10 épocas, ou seja, o EA é incapaz de indicar fractais. Os outros dois EAs apresentam um valor de 97.6%. O efeito de uma diminuição gradual na taxa de aprendizado é praticamente igual a 0.
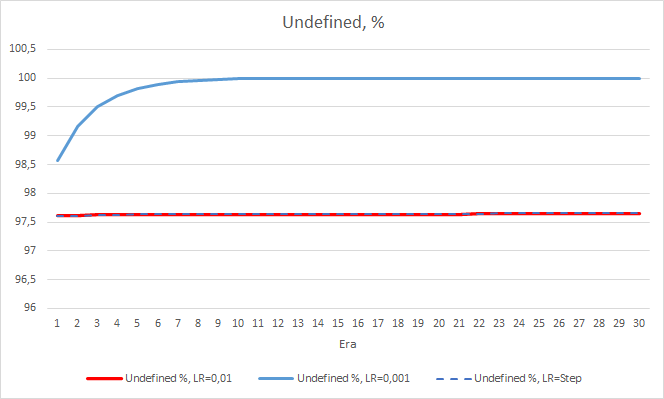
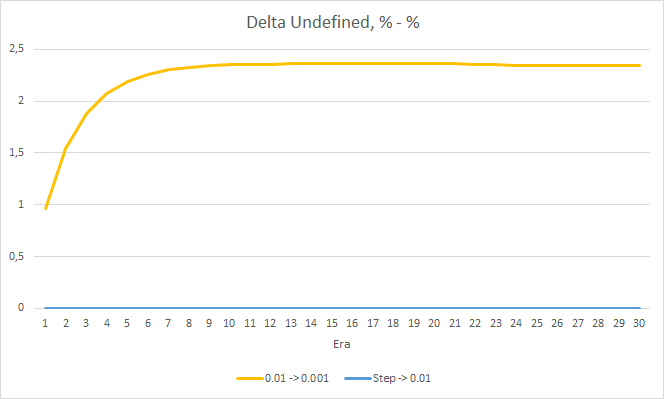
A porcentagem de "acerto" do EA com a taxa de aprendizado de 0.001 continua a crescer gradualmente. Uma diminuição gradual na taxa de aprendizado não afeta esse valor.
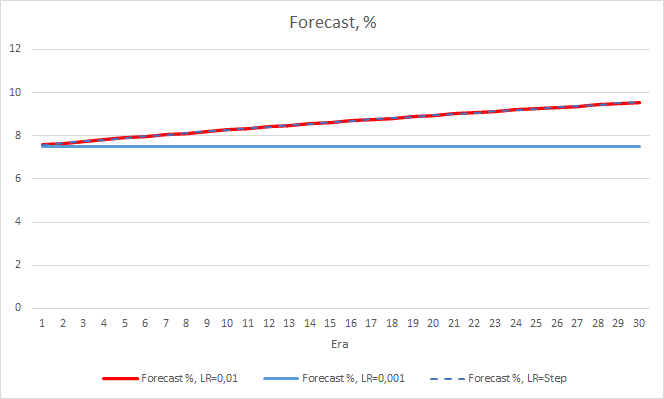
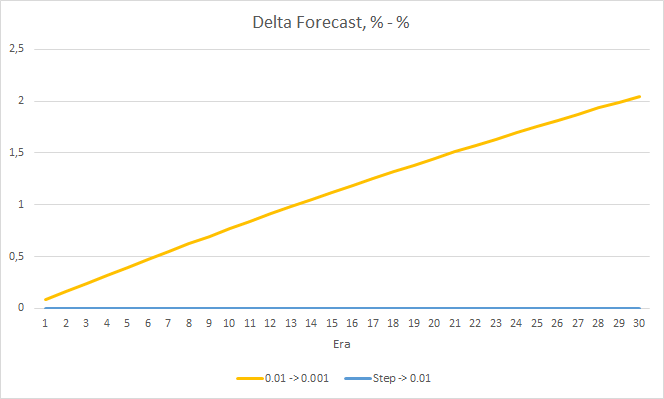
4. Experimento 3
O terceiro experimento é um ligeiro desvio do tópico principal do artigo. Sua ideia surgiu durante os dois primeiros experimentos. Então, eu decidi compartilhar com você. Ao observar o treinamento da rede neural, eu percebi que a probabilidade da ausência de um fractal oscila em torno de 60-70% e raramente cai abaixo de 50%. A probabilidade de surgimento de um fractal, seja para comprar ou vender, é em torno de 20-30%. Isso é bastante natural, pois há bem menos fractais no gráfico do que velas dentro das tendências. Portanto, nossa rede neural está sobrecarregada e nós obtemos os resultados acima. Quase 100% dos fractais são perdidos e apenas em casos raros que eles podem ser detectados.

Para resolver esse problema, eu decidi compensar um pouco a irregularidade da amostra: para a ausência de um fractal no valor de referência, eu especifiquei 0.5 em vez de 1 ao treinar a rede.
TempData.Add((double)buy); TempData.Add((double)sell); TempData.Add((double)((!buy && !sell) ? 0.5 : 0));
Este passo produziu um bom efeito. O Expert Advisor rodando com uma taxa de aprendizado de 0.01 e uma matriz de peso obtida dos experimentos anteriores mostra a estabilização do erro de cerca de 0.34 após 5 épocas de treinamento. A percentagem de fractais perdidos diminuiu para 51% e a percentagem de acertos aumentou para 9.88%. Você pode ver no gráfico que o EA gera sinais em grupo e, portanto, ele mostra algumas zonas corretas. Obviamente, a ideia requer desenvolvimento e testes adicionais. Mas os resultados sugerem que essa abordagem é bastante promissora.

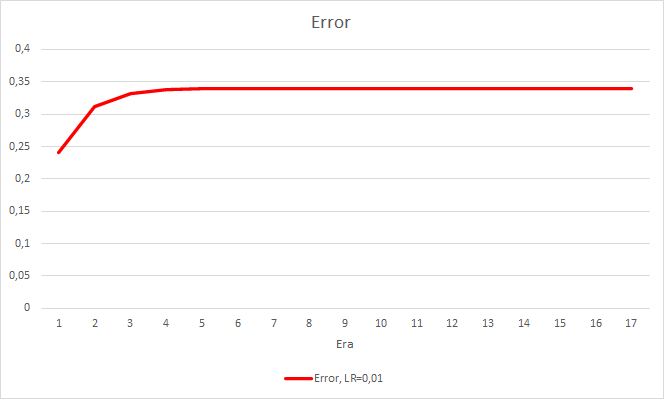
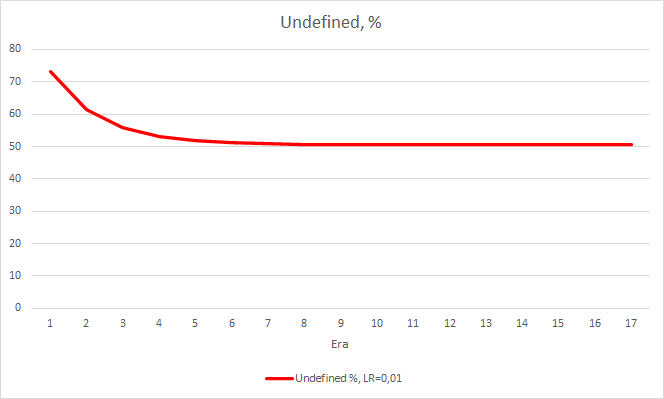
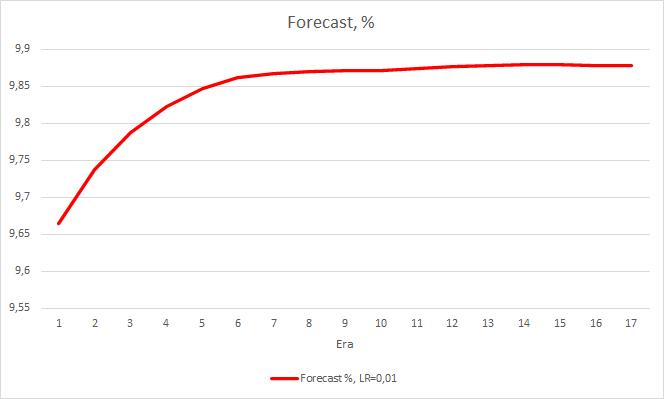
Conclusões
Nós implementamos três experimentos neste artigo. Os dois primeiros experimentos mostraram a importância da seleção correta da taxa de aprendizado da rede neural. A taxa de aprendizado afeta o resultado geral do treinamento da rede neural. No entanto, atualmente não existe uma regra clara para a escolha da taxa de aprendizado. É por isso que você terá que selecioná-la experimentalmente na prática.
O terceiro experimento mostrou que uma abordagem não padronizada para resolver um problema pode melhorar o resultado. Mas a aplicação de cada solução deve ser confirmada experimentalmente.
Referências
- Redes neurais de maneira fácil
- Redes neurais de maneira fácil (Parte 2): Treinamento e teste da rede
- Redes Neurais de Maneira Fácil (Parte 3): Redes Convolucionais
- Redes Neurais de Maneira Fácil(Parte 4): Redes Recorrentes
- Redes Neurais de Maneira Fácil (Parte 5): Cálculos em Paralelo com o OpenCL
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Fractal_OCL1.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando a tecnologia OpenCL e taxa de aprendizado = 0.1 |
| 2 | Fractal_OCL2.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando a tecnologia OpenCL e taxa de aprendizado = 0.01 |
| 3 | Fractal_OCL3.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando a tecnologia OpenCL e taxa de aprendizado = 0.001 |
| 4 | Fractal_OCL_step.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando a tecnologia OpenCL e taxa de aprendizado com uma diminuição de 10x de 0.01 a cada 10 épocas |
| 5 | NeuroNet.mqh | Biblioteca de classe | Uma biblioteca de classes para a criação de uma rede neural |
| 6 | NeuroNet.cl | Código Base | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/8485
 Gradient Boosting (CatBoost) no desenvolvimento de sistemas de negociação. Uma abordagem ingênua
Gradient Boosting (CatBoost) no desenvolvimento de sistemas de negociação. Uma abordagem ingênua
 Conjunto de ferramentas para marcação manual de gráficos e negociação (Parte II). Fazendo a marcação
Conjunto de ferramentas para marcação manual de gráficos e negociação (Parte II). Fazendo a marcação
 Redes Neurais de Maneira Fácil(Parte 7): Métodos de otimização adaptativos
Redes Neurais de Maneira Fácil(Parte 7): Métodos de otimização adaptativos
 Redes Neurais de Maneira Fácil (Parte 5): Cálculos em Paralelo com o OpenCL
Redes Neurais de Maneira Fácil (Parte 5): Cálculos em Paralelo com o OpenCL
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso