
Redes neurais de maneira fácil (Parte 65): aprendizado supervisionado ponderado por distância (DWSL)

Introdução
Os métodos de clonagem de comportamento, em grande parte baseados nos princípios do aprendizado supervisionado, demonstram resultados bastante bons. No entanto, seu principal problema permanece na busca de exemplos ideais para imitação, que muitas vezes são muito difíceis de coletar. Por sua vez, os métodos de aprendizado por reforço podem trabalhar com dados de entrada subótimos. Eles também encontram políticas subótimas para alcançar os objetivos estabelecidos. Entretanto, ao buscar a política ótima, frequentemente enfrentamos o problema de otimização, que é mais grave em ambientes de alta dimensionalidade e estocásticos.
Para superar a lacuna entre essas duas abordagens, foi proposto o método Distance Weighted Supervised Learning (DWSL), apresentado no artigo "Distance Weighted Supervised Learning for Offline Interaction Data". Este é um algoritmo de aprendizado off-line supervisionado para políticas direcionadas. Teoricamente, converge para a política ótima com uma margem de retorno mínima no nível das trajetórias da amostra de treinamento. Exemplos práticos dos autores demonstram a superioridade do método proposto sobre os algoritmos de aprendizado por imitação e por reforço. Convido você a dar uma olhada mais de perto no DWSL. E a avaliar de forma prática seus pontos fortes e fracos na solução de nossas tarefas.
1. Algoritmo DWSL
Os autores do distance weighted supervised learning tinham como objetivo obter um algoritmo capaz de usar o conjunto de dados mais amplo possível para o treinamento. E, nesse paradigma, supõe-se que o Agente opera em um processo determinístico de tomada de decisão de Markov com:
- um espaço de estados S;
- um espaço de ações A;
- uma dinâmica determinística de transições St+1 = F(St,At), onde St+1 é o novo estado do ambiente após a ação At ser tomada no estado St;
- um espaço de metas G;
- uma função de recompensa esparsa, condicionada ao alcance de uma meta R(S,A,G);
- um fator de desconto γ.
O espaço de metas G é um subconjunto do espaço de estados S com uma função de dependência de metas G = φ(St), que é frequentemente idêntica φ(St+6}) = St+n. O objetivo do algoritmo é treinar uma política condicionada ao alcance de uma meta π(A|S,G). Que tem domínio no ambiente estudado e é capaz de alcançar a meta estabelecida e permanecer nela. Para obter o resultado desejado, maximizamos a renda descontada da função de recompensa R(S,A,G) condicionada ao alcance da meta G a partir da distribuição de metas p(G).
Embora essa configuração de tarefa seja diferente das consideradas anteriormente, ela tem fortes conexões com duas configurações comuns de problemas: o problema do caminho mais curto estocástico e o GCRL.
Os autores do método destacam que os trabalhos em GCRL pressupõem a existência de trajetórias com submetas rotuladas. Essas submetas são definidas pela intenção da política, o que fornece ao modelo informações sobre a distribuição de metas p(G) durante os testes. Isso limita os dados para extração de conhecimento durante o aprendizado off-line em GCRL. A razão é que muitas fontes de dados off-line não contêm rótulos de metas (submetas) junto com cada trajetória. Além disso, as metas podem ser difíceis de obter.
Para explorar um conjunto mais amplo de dados off-line, os autores do método consideram uma situação mais geral. Que não presume acesso à dinâmica verdadeira do ambiente, rótulos de recompensas ou distribuição de metas nas fases de teste e operação. Na fase de treinamento, é usado apenas um conjunto de trajetórias de estados e ações de variados níveis de otimalidade. A distribuição p(G) é adotada como a distribuição de metas, induzida pela aplicação da função de dependência φ(St) a todos os estados no conjunto de dados. Supõe-se que para a maioria dos conjuntos de dados práticos, as metas em torno da distribuição de dados provavelmente estão próximas das metas para as tarefas de interesse. O método DWSL pode utilizar qualquer função de recompensa esparsa que possa ser calculada apenas a partir das sequências existentes de estados e ações, mas as investigações práticas dos autores do método demonstram bons resultados ao simplesmente contar o número de iterações para alcançar a meta estabelecida.
Intuitivamente, ao usar essa função de recompensa, a melhor estratégia para alcançar a meta G do estado atual S é usar o caminho com o menor número de passos temporais (o caminho mais curto). No entanto, as trajetórias no conjunto de dados de treinamento não necessariamente seguem os caminhos mais curtos. Como resultado, os métodos de clonagem de comportamento podem exibir comportamento subótimo.
Para resolver esse problema, o DWSL avalia as distâncias usando aprendizado supervisionado, avalia os modelos treinados dentro da distribuição de dados da amostra de treinamento. O modelo aprende toda a distribuição de distâncias par-a-par entre os estados no conjunto de treinamento. E utiliza essa distribuição para estimar a distância mínima até a meta contida no conjunto de dados de cada estado. E então ensina a política a seguir esses caminhos. Abaixo está apresentada uma representação do método DWSL.

Entre quaisquer dois estados Si e Sj em uma única trajetória onde i < j, existe pelo menos um caminho de "j - i" passos temporais. Usando essa propriedade, geramos um conjunto de dados rotulado que contém todas as distâncias par-a-par entre estados e metas no conjunto de dados de treinamento. Para cada par "Estado–Meta", selecionado da nova distribuição, modelamos a distribuição discreta sobre o número de passos temporais k do estado atual até a meta, conforme ilustrado na figura 1 à esquerda. Isso nos permite obter uma estimativa parametrizada da distribuição pelo método de máxima verossimilhança no conjunto de dados rotulado:
![]()
Na prática, a distribuição é modelada como um classificador discreto sobre as possíveis distâncias. O caminho mais curto entre os estados inicial e alvo, contido no conjunto de dados rotulado, é determinado pelo menor número de passos temporais k. No entanto, como a distribuição é estudada usando aproximações de funções, a estimativa da distância mínima provavelmente incluirá erros de modelagem. Para minimizar esse erro, os autores do método propõem calcular o LogSumExp sobre a distribuição de distâncias para obter uma estimativa suavizada da distância mínima:
![]()
Observe que, na fórmula apresentada, a distância é multiplicada por "-1" para obter uma estimativa do mínimo, em vez do máximo. Aqui, α é um hiperparâmetro de temperatura. Quando α tende a "0", o valor da função d(s, g) aproxima-se da distância mínima k.
Após estudar as estimativas de distância mínima, queremos usar os caminhos conhecidos que partem de cada estado. Suponha que o Agente esteja no estado S e precise alcançar o objetivo G. No estado inicial, o Agente pode executar uma das duas ações (A1 ou A2), que levam aos estados S1 e S2, respectivamente. Preferiremos realizar a primeira ação se ela iniciar o caminho até o objetivo com o menor número de passos (distância estimada menor até o objetivo). Portanto, queremos ponderar a probabilidade de diferentes ações com base nas suas estimativas de distância em relação ao objetivo (à direita na figura acima). No entanto, uma ponderação ingênua das ações dessa forma resultaria em um peso maior para todos os pontos de dados próximos ao objetivo, já que qualquer estado distante do objetivo naturalmente teria uma distância maior. Em vez disso, ponderamos a probabilidade das ações de acordo com a redução estimada na distância até o objetivo, que os autores do método chamaram de Vantagem. Isso permite formar um novo objetivo de treinamento para o modelo:
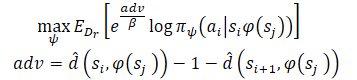
Os autores do método usam a exponenciação da Vantagem para garantir um valor positivo para todos os pesos.
2. Implementação com MQL5
Após nos familiarizarmos com os aspectos teóricos do método distance weighted supervised learning, passamos para a parte prática do nosso artigo, onde criaremos nossa própria versão de sua implementação usando MQL5. Como sempre, tentaremos combinar o algoritmo proposto com os conhecimentos que acumulamos anteriormente. E reproduzir nossa interpretação dos métodos sugeridos. Concordo que essa abordagem, até certo ponto, nos afasta do algoritmo original dos autores e não é uma reprodução exata dele. Consequentemente, quaisquer pontos fracos que possam ser identificados no processo de teste se aplicam somente a esta implementação.
Desde já, quero dizer que no artigo original, os experimentos foram realizados com manipuladores robóticos. Nessas condições, a definição de objetivo desempenha um papel predominante na obtenção de resultados positivos. Além disso, ela é clara em cada caso individual. Na minha implementação, no entanto, enfoco a maximização da rentabilidade do robô durante o período de treinamento. E para simplificar o modelo, foi decidida a dispensa da definição de submetas em cada etapa. Isso, por sua vez, nos permite não treinar o modelo de definição de metas.
Além disso, neste trabalho, treinaremos o modelo usando as abordagens Ator-Crítico. E como doador, utilizaremos o modelo de Ator-Crítico Marginal Estocástico (SMAC). No entanto, nós o complementaremos com outros desenvolvimentos. Em particular, adicionaremos o mecanismo de ponderação de trajetórias de CWBC. Mas vamos por partes. Começamos descrevendo a arquitetura dos modelos.
2.1. Arquitetura dos modelos
Como sempre, a arquitetura dos modelos treináveis está presente no método CreateDescriptions. Nos parâmetros do método, passaremos ponteiros para arrays dinâmicos que descrevem a arquitetura de 3 modelos:
- Ator
- Crítico
- Codificador aleatório
Aqui precisamos lembrar que o algoritmo SMAC envolve o treinamento de um codificador estocástico de estado latente, que anteriormente incorporamos na arquitetura do Ator com a possibilidade de uso pelo Crítico. Nesta implementação, mantivemos essa decisão.
No corpo do método, verificamos os ponteiros recebidos e, se necessário, criamos novas instâncias dos objetos.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; }
Alimentamos o ator com dados históricos de movimentação de preços e indicadores, o que se reflete no tamanho de sua camada de dados de entrada.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Alimentamos o modelo com dados brutos sem pré-processamento. Por isso, após a camada de dados de entrada, usamos uma camada de normalização em lote. Ela uniformiza os dados brutos recebidos de várias fontes em um formato comparável.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Depois disso, tentamos identificar padrões estáveis nos dados usando camadas convolucionais. E para obter uma representação probabilística que classifique os dados de entrada em padrões estáveis, usamos a função SoftMax.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
Note que a busca por padrões estáveis é realizada para cada vela de dados históricos individualmente.
Os resultados da busca por padrões são analisados em duas camadas totalmente conectadas.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Aos dados obtidos, adicionamos a descrição do estado da conta.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
E geramos um estado latente estocástico disponibilizado pelo método SMAC.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Segue-se o bloco de tomada de decisões com 2 camadas totalmente conectadas.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
E na saída do Ator, colocamos um bloco de autocodificador variacional para conferir estocasticidade à política. O tamanho da camada de resultados corresponde à dimensionalidade do vetor de ações do Agente.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A arquitetura do Crítico foi transferida sem alterações. Alimentamos o modelo com a representação latente do estado do ambiente da camada oculta do Ator. E os dados recebidos não precisam ser colocados em um formato comparável. Portanto, neste modelo, não usaremos uma camada de normalização em lote.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Adicionamos ao representação latente as ações do Ator.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
Os dados concatenados são analisados por um bloco de tomada de decisões com 3 camadas totalmente conectadas. O tamanho da última camada corresponde ao tamanho do vetor de recompensa decomposta.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Ao concluir o método CreateDescriptions, adicionaremos a descrição da arquitetura do Codificador Aleatório. Adiantando um pouco o que faremos mais para frente, o Codificador será usado dentro do processo de determinação da distância entre os estados do ambiente. Para descrever um estado específico do ambiente, utilizamos dois vetores:
- dados históricos de movimentação de preços e indicadores;
- estado da conta e posições abertas.
Alimentamos o Codificador com o vetor concatenado dessas duas entidades.
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
O modelo do Codificador não é treinado. Portanto, o uso de uma camada de normalização em lote não proporcionará o resultado desejado. Por isso, para uniformizar os dados de alguma forma comparável, usaremos uma camada totalmente conectada. Após isso, normalizamos os dados usando uma camada SoftMax.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = HistoryBars * BarDescr; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = HistoryBars; descr.step = BarDescr; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
Segue-se um bloco de camadas convolucionais, que também é finalizado com uma camada SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count * prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
Na saída do Codificador, usamos uma camada totalmente conectada que retorna a incorporação do estado analisado do ambiente.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- return true; }
2.2 Preparação de métodos auxiliares
Após descrever a arquitetura dos modelos usados, passamos à fase de implementação do algoritmo de treinamento dos modelos. Mas, antes da implementação do próprio processo de treinamento, é necessário mencionar alguns métodos que implementam blocos individuais do algoritmo geral.
Primeiramente, usaremos ponderação e priorização de trajetórias, que foram discutidas dentro do método CWBC. Para isso, transferiremos os métodos GetProbTrajectories e SampleTrajectory. Seu algoritmo foi detalhadamente descrito no artigo anterior e não nos deteremos nele agora.
Para o treinamento do Ator e dos Críticos, usaremos recompensas e ações ponderadas usando as abordagens do método DWSL. Para evitar operações repetitivas, o cálculo dos vetores alvo para ambos os modelos será combinado dentro de um único método, GetTargets. E para poder passar dois vetores em uma única operação, criaremos uma estrutura.
struct STarget { vector<float> rewards; vector<float> actions; };
Assim, o método GetTargets recebe nos parâmetros:
- um percentil para determinar o número de estados mais próximos analisados da amostra de treinamento;
- a incorporação do estado analisado;
- a matriz de incorporações de estados na amostra de treinamento;
- a matriz de recompensas da amostra de treinamento;
- a matriz de ações do Agente da amostra de treinamento.yy
As últimas três matrizes correspondem umas às outras.
O método retorna a estrutura de seus 2 vetores de destino.
STarget GetTargets(int percentile, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards, matrix<float> &actions ) { STarget result;
No corpo do método, declaramos a estrutura de resultados e imediatamente verificamos a correspondência dos tamanhos das incorporações do estado analisado e na matriz de estados da amostra de treinamento.
if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
Em seguida, determinamos a distância entre o estado analisado e os estados da amostra de treinamento. Para determinar a distância suave, usamos LogSumExp, proposto pelos autores do método DWSL.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * percentile / 100); matrix<float> temp = matrix<float>::Zeros(states, size); for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha=temp.Max(); vector<float> dist = MathLog(MathExp(temp/(-alpha)).Sum(1))*(-alpha);
Após isso, criaremos matrizes locais de recompensas, ações e incorporação. Nelas, transferimos dados sobre os estados mais próximos.
vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_rewards = matrix<float>::Zeros(k, NRewards); matrix<float> k_actions = matrix<float>::Zeros(k, NActions); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S; float max = dist.Percentile(percentile); float min = dist.Min(); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_rewards.Row(rewards.Row(i), cur); k_actions.Row(actions.Row(i), cur); k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
Para obter o vetor de recompensa alvo para o treinamento, precisamos ponderar a matriz de recompensas selecionadas com base na distância em relação ao estado analisado. No entanto, devemos observar que a menor distância nos dá o menor peso da recompensa correspondente. Isso contradiz a lógica geral: o valor mais relevante tem o menor impacto no resultado final. Mas isso é fácil de corrigir. Basta multiplicar o vetor de distâncias por "-1". E a função SoftMax converterá os valores resultantes no plano de probabilidades. Agora precisamos multiplicar o vetor de probabilidades resultante pela matriz de recompensas dos estados mais próximos coletados.
vector<float> sf; (min_dist*(-1)).Activation(sf, AF_SOFTMAX); result.rewards = sf.MatMul(k_rewards);
Neste mesmo ponto, adicionaremos normas de kernel para incentivar o Ator a explorar.
k_embedding.SVD(U, V, S); result.rewards[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result.rewards[NRewards - 1] = EntropyLatentState(Actor);
Em seguida, formaremos o vetor de ações alvo. Desta vez, vamos ponderar as ações pelo seu benefício predominante de recompensa. Assim como o vetor de distâncias, calcularemos o vetor de recompensas usando a função LogSumExp.
vector<float> act_sf; alpha=MathAbs(k_rewards).Max(); dist = MathLog(MathExp(k_rewards/(-alpha)).Sum(1))*(-alpha);
Desta vez, a maior recompensa deve ter o máximo de influência e não há necessidade de inverter os valores. Basta simplesmente converter as recompensas para o domínio de valores de probabilidade usando a função SoftMax. Após isso, multiplicamos o vetor resultante pela matriz de ações. O resultado obtido é registrado em uma estrutura. E retornamos ambos os vetores de valores alvo para o programa que chamou.
Com isso, concluímos o trabalho preparatório e passamos à implementação do algoritmo principal.
2.3 EA para coleta de dados para treinamento
Em seguida, abordamos o programa de coleta de dados para o treinamento off-line dos modelos. Como antes, esta tarefa será realizada no EA "...\DWSL\Research.mq5". Não vamos revisar todo o código deste EA. A maioria de seus métodos migrou sem alterações de um artigo para o outro. E já foram revistos em artigos anteriores. Vamos focar apenas nas características chave. E primeiro vamos examinar o método de processamento de ticks OnTick, no qual é implementado o algoritmo principal.
No início do método, verificamos o evento de abertura de uma nova barra e, se necessário, carregamos os dados históricos de movimentação de preços e indicadores analisados.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Com os dados obtidos, formamos o buffer de dados de entrada.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
E o buffer do estado da conta.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance)); double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Passamos os dados coletados para o modelo do Ator e chamamos o método de propagação. Enquanto isso, não esquecemos de monitorar o processo de execução das operações.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
Como resultado da propagação, o modelo do Ator gera um vetor de ações, que deciframos. Aqui, apenas removemos o volume de operações opostas, que não gera lucro. Ao contrário de outros trabalhos já examinados, não adicionamos ruído ao vetor obtido para a exploração do ambiente. A política estocástica do Ator, junto com a estocasticidade do estado latente, já gera uma variação suficiente de ações para explorar o ambiente próximo do espaço de ações.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Em seguida, comparamos a posição existente com a previsão do Ator e, se necessário, realizamos operações de negociação. Primeiro para posições longas.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
E então repetimos as operações para posições curtas.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Ao final das operações do método, só nos resta coletar o feedback do ambiente e passar os dados para o buffer de reprodução de experiência.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove(); }
Com isso, o processo de coleta de dados pode ser considerado implementado. Mas o trabalho sobre este EA não pode ser considerado concluído. No âmbito da implementação do método DWSL, gostaria de destacar um detalhe. Na parte teórica deste artigo, já discutimos que o método DWSL converge para a política ótima com uma margem mínima de rentabilidade ao nível das trajetórias da amostra de treinamento. E, claro, na busca pela trajetória ótima, gostaríamos de elevar o mais alto possível o limite mínimo de rentabilidade. Com esse objetivo, faremos alterações no processo de adição de novas trajetórias ao buffer de reprodução de experiência. Após o preenchimento inicial do buffer, começaremos a substituir gradualmente as trajetórias com menor rentabilidade por outras mais lucrativas. Esse processo é realizado no método OnTesterPass, onde é tratado o evento de conclusão de passagem no testador de estratégias.
No corpo do método, primeiro inicializamos as variáveis locais. E imediatamente criamos um laço para consultar os frames das passagens.
void OnTesterPass() { //--- ulong pass; string name; long id; double value; STrajectory array[]; while(FrameNext(pass, name, id, value, array)) {
No corpo do laço, verificamos a compatibilidade do frame com o programa atual.
int total = ArraySize(Buffer); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue;
Depois, ocorre uma bifurcação do processo, dependendo de quão cheio está o buffer de reprodução de experiência. Se o buffer já estiver cheio até o tamanho máximo definido, então realizamos uma busca no buffer por uma passagem com a menor rentabilidade. Isso pode ser o maior prejuízo ou o menor lucro.
if(total >= MaxReplayBuffer) { for(int a = 0; a < id; a++) { float min = FLT_MAX; int min_tr = 0; for(int i = 0; i < total; i++) { float prof = Buffer[i].States[Buffer[i].Total - 1].account[1]; if(prof < min) { min = MathMin(prof, min); min_tr = i; } }
Em seguida, comparamos o valor obtido com a rentabilidade da última passagem. E se for maior, simplesmente registramos os dados da nova passagem em substituição à encontrada com menor valor. Caso contrário, passamos para a próxima passagem.
float prof = array[a].States[array[a].Total - 1].account[1]; if(min <= prof) { Buffer[min_tr] = array[a]; PrintFormat("Replace %.2f to %.2f -> bars %d", min, prof, array[a].Total); } } }
No caso de o buffer ainda não estar cheio, simplesmente adicionamos a nova passagem sem operações de controle excessivas.
else { if(ArrayResize(Buffer, total + (int)id, 10) < 0) return; ArrayCopy(Buffer, array, total, 0, (int)id); } } }
Exploramos a seguinte prioridade de operações:
- Máximo preenchimento do buffer de reprodução de experiência para fornecer às modelos em treinamento a informação mais completa sobre o ambiente.
- Após o preenchimento do buffer de reprodução de experiência, a seleção das passagens mais lucrativas para construir a estratégia ótima.
O código completo do EA e de todos os seus métodos está disponível no anexo. Lá, você também encontrará o código do EA de teste de modelos "...\DWSL\Test.mq5". Ele tem um algoritmo de método de processamento de ticks semelhante, mas é destinado a uma única execução no testador de estratégias. E vamos omitir sua discussão neste artigo.
2.4 EA de treinamento de modelos
O treinamento de modelos é preparado no EA "...\DWSL\Study.mq5". Também não nos deteremos na análise detalhada de todos os seus métodos. Vamos examinar apenas o método Train, no qual é preparado o algoritmo principal de treinamento de modelos.
No corpo do método, definimos o tamanho do buffer de reprodução de experiência e salvamos em uma variável local o estado do contador de ticks para rastrear o tempo gasto nas operações.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Em seguida, em um laço, passamos por todas as trajetórias para calcular o número total de estados no buffer de reprodução de experiência. Isso nos dará a oportunidade de preparar matrizes de tamanho adequado para registrar as incorporações de estados, bem como as recompensas correspondentes e ações do Agente. A utilização dessas matrizes já foi encontrada no método GetTargets.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
O próximo passo é começar a preencher essas matrizes. Para isso, elaboramos um sistema de laços com uma iteração completa por todos os estados do buffer de reprodução de experiência. No corpo deste sistema de laços, coletamos a descrição de cada estado individual em um único buffer de dados.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
E por meio de uma propagação do codificador, geramos sua incorporação.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp);
O vetor obtido é salvo na matriz da incorporação de estados, state_embedding.
if(!state_embedding.Row(temp, state)) continue;
Nas matrizes de recompensas (rewards) e ações do Agente (actions), salvamos os dados correspondentes do buffer de reprodução de experiência.
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue;
Note que na matriz de recompensas adicionamos apenas as Vantagens por transição para o próximo estado. Além disso, caso ocorra algum erro, não finalizamos completamente o trabalho do programa, mas apenas passamos para o próximo estado. Dessa forma, não finalizamos todo o processo de treinamento, apenas reduzimos um pouco a base de comparação.
Em seguida, aumentamos o contador de incorporações salvas. E antes de passar para a próxima iteração do nosso sistema de laços, informamos o usuário sobre o progresso do processo de codificação de estados.
state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
Após concluir o processo de codificação, reduzimos nossas matrizes ao número real de dados preenchidos.
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
}
O próximo passo é preparar variáveis locais e gerar a priorização das trajetórias. O próprio processo de cálculo das probabilidades de escolha das trajetórias é realizado em um método separado, GetProbTrajectories, cujo algoritmo foi apresentado no artigo anterior artigo.
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Com isso, concluímos a etapa de preparação dos dados e passamos para o algoritmo de treinamento direto dos modelos, que também é gerado em um ciclo. O número de iterações do ciclo de treinamento dos modelos é indicado nos parâmetros externos do EA.
No corpo do ciclo, primeiro amostramos uma trajetória considerando as probabilidades calculadas anteriormente. Este processo é realizado no método SampleTrajectory, cujo algoritmo também foi apresentado no artigo anterior artigo. Então, amostramos um estado na trajetória selecionada.
vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Em seguida, fiz a ramificação de acordo com as iterações de treinamento passadas. Eu excluo a avaliação do estado subsequente com os modelos alvo no estágio inicial, pois a avaliação por modelos não treinados é completamente aleatória e pode direcionar o processo de treinamento na direção errada. Por outro lado, a avaliação do estado subsequente por modelos com um nível suficiente de precisão nos permitirá avaliar a rentabilidade futura esperada da política usada nesta etapa. E, assim, priorizar ações considerando os benefícios subsequentes.
Neste bloco, preenchemos o buffer de dados de entrada com a descrição do estado subsequente do ambiente.
State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
E geramos as ações do Agente considerando a política atualizada.
if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Depois disso, avaliamos a ação obtida com 2 modelos de Críticos alvo.
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Para o cálculo da recompensa esperada, usamos a menor avaliação.
TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward[NRewards - 1] = EntropyLatentState(Actor); target_reward *= DiscFactor; }
Na próxima etapa, passamos para o processo de treinamento dos modelos Críticos. O treinamento desses modelos é realizado com estados e ações do buffer de reprodução de experiência.
Inicialmente, copiamos as descrições do estado atual do ambiente para o buffer de dados de entrada.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
E então formamos o buffer com a descrição do estado da conta.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Os dados coletados nos permitem realizar a propagação do Ator.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Note que antes do treinamento dos Críticos, realizamos a propagação do Ator. Embora no processo de treinamento estaremos usando ações do buffer de reprodução de experiência. Isso está relacionado ao uso do estado latente do Ator como dados de entrada para os Críticos.
Em seguida, preenchemos o buffer de ações da base de dados de treinamento e chamamos os métodos de propagação dos nossos Críticos.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Porém, como valores alvo para o treinamento dos modelos, usaremos recompensas ponderadas. Para obtê-las, primeiro adicionamos ao buffer do estado atual do ambiente a descrição do estado da conta e geramos a incorporação do estado analisado.
if(!State.AddArray(GetPointer(Account)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
Com o conjunto de dados disponível nesta etapa, temos o suficiente para chamar o método GetTargets mencionado anteriormente, que nos retornará vetores de recompensas e ações ponderadas.
target = GetTargets(Percent, temp, state_embedding, rewards, actions);
Na presença de dados alvo, podemos realizar a retropropagação dos modelos Críticos, mas primeiro ajustaremos o gradiente de erro usando o método CAGrad.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A próxima etapa é atualizarmos a política do Ator. A propagação do modelo já foi realizada anteriormente. O vetor de ações alvo ponderadas também já foi obtido. Portanto, temos todos os dados necessários para realizar a retropropagação no modo de treinamento supervisionado.
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Como se pode observar, ao formar o vetor de ações alvo do Ator, utilizamos as Vantagens das ações extraídas diretamente do buffer de reprodução de experiência. Consequentemente, os modelos Críticos treinados não foram utilizados. Nesse caso, é preciso perceber que, independentemente da política utilizada pelo Ator, sua influência no movimento do mercado é mínima. E a reavaliação da Vantagem por meio de um Crítico aproximado pode apenas distorcer os dados interpretando como um erro de modelagem. E, nesse paradigma, treinar modelos Críticos pode parecer uma operação desnecessária. Mas ainda queremos considerar o impacto da política estudada sobre os retornos futuros esperados. Para esse fim, escolhemos um Crítico que, como resultado do treinamento, mostra o mínimo erro e avaliamos com ele as ações do Ator geradas pela nova política. O gradiente da discrepância entre a avaliação obtida e a ponderada é transmitido ao Ator para otimização dos parâmetros.
CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
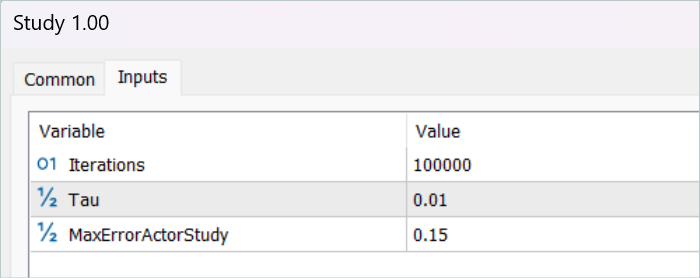
Aqui precisamos destacar que essas operações são realizadas apenas quando o Crítico está confiante o suficiente de que a avaliação das ações é adequada. Para regular esse processo, introduzimos um parâmetro externo adicional, MaxErrorActorStudy, que define o máximo erro de avaliação pelo Crítico para incluir o processo mencionado.
Após o processo de treinamento dos modelos, copiaremos os parâmetros dos modelos Críticos treinados para os modelos alvo. Aqui também vale a pena notar que, na fase inicial antes da inclusão do processo de avaliação de estados subsequentes, transferimos completamente os parâmetros dos modelos treinados para os alvos. E ao usar o mecanismo de avaliação de estados subsequentes, é ativado o processo de cópia suave dos parâmetros.
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
Com isso, concluímos uma iteração do treinamento dos modelos. E resta-nos informar o usuário sobre o progresso do processo de treinamento dos modelos e passar para a próxima iteração.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após a execução de todas as iterações do ciclo de treinamento dos modelos, limpamos o campo de comentários no gráfico do instrumento. Informamos o usuário sobre os resultados do treinamento e iniciamos o processo de finalização do do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, concluímos a parte prática do nosso artigo. E com o código completo de todos os programas utilizados neste trabalho, você pode se familiarizar no anexo. Agora, passamos a testar o trabalho que fizemos.
3. Teste
Fizemos um trabalho extensivo para implementar nossa visão do método DWSL usando MQL5. Devo admitir que acabamos com uma certa conglomeração de vários métodos discutidos anteriormente. O que é um experimento muito grande. E a eficácia da nossa solução pode ser verificada com dados históricos. E é aí que chegamos agora.
Como sempre, para o treinamento dos modelos, foram utilizados dados históricos dos primeiros 7 meses de 2023 do instrumento EURUSD no timeframe H1. A coleta de dados para o treinamento dos modelos foi realizada no testador de estratégias MetaTrader 5 no modo de otimização completa dos parâmetros. Na primeira etapa, coletamos 500 trajetórias aleatórias. Graças à nossa otimização do algoritmo do método OnTesterPass, podemos executar um pouco mais de passagens. E no buffer de reprodução de experiência serão selecionadas as mais lucrativas.
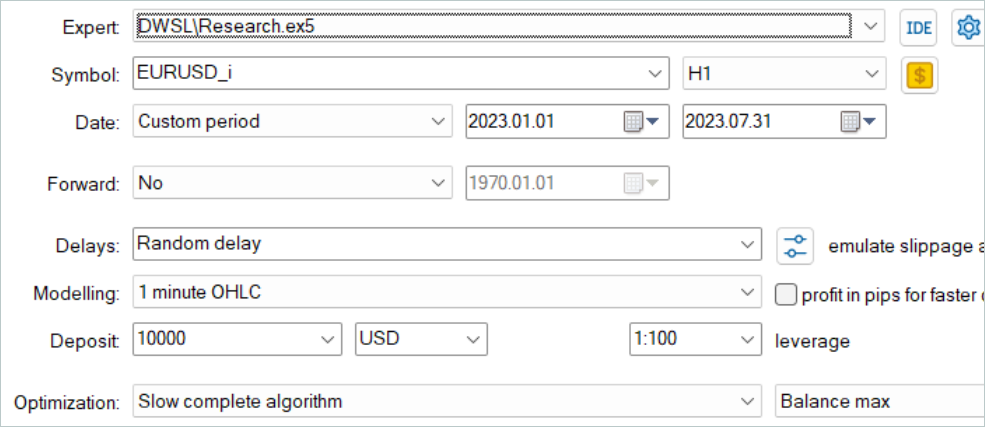
É importante dizer que não se deve esperar obter passagens lucrativas de políticas aleatórias nesta fase. Neste ponto, é um processo bastante aleatório. E como já vimos antes, a probabilidade de obter uma passagem completamente lucrativa de uma política aleatória em todo o intervalo é próxima de "0". Felizmente, o método DWSL pode trabalhar com dados de qualquer qualidade.
Após a coleta da base de dados de treinamento, realizamos a primeira execução do nosso EA de treinamento de modelos.
Confesso que nesta etapa não obtive uma estratégia completamente lucrativa. E isso se deve, em grande parte, à baixa rentabilidade das passagens na amostra de treinamento. Mas aqui precisamos ressaltar que um novo ciclo de interação com o ambiente, já após o primeiro ciclo de treinamento, produziu trajetórias com rentabilidade significativamente maior. Até apareceu uma, possivelmente aleatória, passagem com lucro durante todo o período de treinamento. O que, em geral, demonstra a eficácia do método e a esperança de alcançar melhores resultados.
Após várias iterações de coleta de trajetórias e treinamento, consegui obter um modelo capaz de gerar lucro consistentemente. O modelo obtido foi testado com dados históricos de agosto de 2023, que não faziam parte da amostra de treinamento. Mas como eles se seguiram imediatamente ao período de treinamento, isso nos permite fazer uma suposição sobre a comparabilidade dos dados.


Os resultados do teste mostraram que o modelo conseguiu obter lucro, alcançando um fator de lucro de 1.3. O gráfico de balanço mostra um crescimento bastante rápido na primeira metade do mês. E depois observamos flutuações em uma faixa bastante estreita. Entre os resultados positivos do teste, podemos incluir:
- mais de 50% das posições foram lucrativas;
- a negociação mais lucrativa foi quase quatro vezes maior que a maior perda, e a negociação média lucrativa foi quase um quarto maior que a perda média.
- presença de operações em ambas as direções (60% curtas e 40% longas). Neste contexto, quase 55% das posições curtas e 46% das posições longas foram fechadas com lucro
- a série de lucros máxima supera a série de perdas máxima tanto em número de operações quanto em soma.
Os resultados obtidos criam uma impressão geral positiva.
Considerações finais
Neste artigo, exploramos mais um método interessante de treinamento de modelos: distance weighted supervised learning. Graças ao uso da abordagem de avaliação ponderada dos dados existentes, ele permite otimizar as trajetórias coletadas que não são ótimas e treinar políticas bastante interessantes em modo off-line. O que, posteriormente, mostra resultados não ruins.
A eficácia do método analisado é confirmada pelos nossos resultados práticos. Durante o treinamento, foi obtida uma política capaz de generalizar o material estudado usando novos dados. E, como consequência, um gráfico de saldo lucrativo durante o teste.
No entanto, gostaria de lembrar novamente que todos os programas apresentados no artigo são destinados apenas para demonstração de abordagens e não são otimizados para uso em negociação real.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | Expert Advisor para coleta de exemplos |
| 2 | Study.mq5 | EA | Expert Advisor para treinamento do agente |
| 3 | Test.mq5 | EA | Expert Advisor para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13779
 Criação de um Expert Advisor simples em várias moedas usando MQL5 (Parte 4): Média móvel triangular — Sinais do indicador
Criação de um Expert Advisor simples em várias moedas usando MQL5 (Parte 4): Média móvel triangular — Sinais do indicador
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso