
Redes neurais de maneira fácil (Parte 66): Problemáticas da pesquisa em treinamento off-line

Introdução
Desde os primeiros artigos sobre aprendizado por reforço, foi levantada a questão do equilíbrio entre a exploração do ambiente e o aproveitamento da política aprendida. E diferentes métodos para estimular a exploração pelo Agente já foram considerados anteriormente. No entanto, frequentemente os algoritmos que mostram excelentes resultados no treinamento on-line provam ser menos eficazes no modo off-line. O problema é que, no modo off-line, as informações sobre o ambiente estão limitadas ao volume da amostra de treinamento. E mais frequentemente, os dados selecionados para treinar modelos são específicos, pois são coletados em um subespaço pequeno da tarefa definida. Isso dá uma representação ainda mais limitada do ambiente. No entanto, para encontrar a solução ideal, o Agente precisa de uma representação o mais completa possível sobre o ambiente e suas regularidades. Já notamos que os resultados do treinamento muitas vezes dependem da amostra de treinamento.
Além disso, muitas vezes durante o treinamento, o Agente toma decisões que vão além do subespaço da amostra de treinamento. E nessas situações, é difícil prever os resultados subsequentes. É por isso que, após o treinamento preliminar do modelo, realizamos uma coleta adicional de trajetórias para a amostra de treinamento, que pode ajustar o processo de treinamento.
O treinamento on-line do modelo do ambiente às vezes pode mitigar os problemas mencionados. Mas, infelizmente, por várias razões, nem sempre é possível treinar o modelo do ambiente. Muitas vezes, treinar o modelo pode ser ainda mais caro do que treinar a política do Agente. E às vezes é simplesmente impossível.
A segunda direção óbvia é expandir a amostra de treinamento. Mas aqui, principalmente, nos deparamos com o tamanho físico dos recursos disponíveis e o limite dos custos para estudar o ambiente.
Neste artigo, convido você a se familiarizar com o framework Exploratory Data for off-line RL (ExORL), que foi apresentado no artigo "Don't Change the Algorithm, Change the Data: Exploratory Data for offline Reinforcement Learning". Os resultados apresentados no artigo demonstram que uma abordagem correta para a coleta de dados tem um impacto significativo nos resultados finais do treinamento. Assim como a escolha do algoritmo de treinamento e da arquitetura do modelo.
1. Método Exploratory Data for offline RL (ExORL)
Deve-se dizer imediatamente que os autores do método Exploratory Data for offline RL (ExORL) não oferecem novos algoritmos de treinamento ou soluções arquitetônicas para modelos. Pelo contrário, todo o foco está no processo de coleta de dados para treinar modelos. E então são realizados experimentos com cinco diferentes métodos de treinamento para avaliar o impacto do conteúdo da amostra de treinamento nos resultados do treinamento.
O método ExORL pode ser dividido em três etapas principais. A primeira etapa é a coleta de dados exploratórios não rotulados. Para isso, é possível usar diferentes algoritmos de aprendizado não supervisionado. Os autores do método não limitam o conjunto de algoritmos utilizados. Durante a interação com o ambiente, em cada episódio é utilizada uma política π, que depende do histórico de interações anteriores. Cada episódio é salvo no conjunto de dados como uma sequência de estado St, ação At e o estado subsequente St+1. A coleta de dados de treinamento continua até que a amostra de treinamento esteja completamente preenchida, limitada pelo escopo técnico ou recursos disponíveis.
Na prática, os autores do artigo avaliam nove diferentes algoritmos de coleta de dados não supervisionados:
- Uma simples linha de base, que sempre emprega uma política de seleção aleatória uniforme;
- Métodos baseados na maximização do erro do modelo preditivo: ICM, Disagreement, RND;
- Algoritmos que maximizam alguma estimativa de cobertura do espaço de estados: APT e Proto-RL;
- Algoritmos baseados em competências, que treinam uma variedade de habilidades: DIAYN, SMM, e APS.
Após a coleta do conjunto de dados sobre estados e ações, é realizada uma reavaliação usando uma função de recompensa definida. Nesta etapa, é essencial avaliar a recompensa para cada tupla no conjunto de dados.
Nos seus experimentos, os autores do método usam funções de recompensa padrão ou manuais. Além disso, é observado que o framework proposto também permite treinar a função de recompensa. Ou seja, realizar RL inverso.
A última etapa do ExORL é o treinamento do modelo. O treinamento da política é realizado usando algoritmos de aprendizado por reforço off-line no conjunto de dados rotulado. O treinamento off-line é realizado inteiramente com dados off-line da amostra de treinamento, através da seleção aleatória de tuplas. Após isso, a política final é avaliada no ambiente real.
Abaixo está a visualização do método pelos autores.
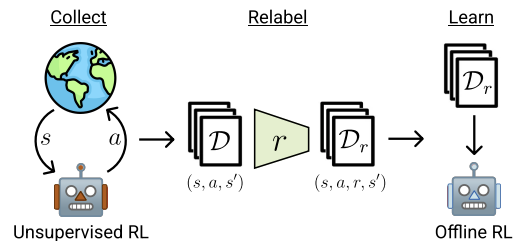
No artigo, os autores demonstram os resultados de cinco diferentes algoritmos de aprendizado por reforço off-line. Como uma linha de base, é usado o simples clonamento de comportamento. Também são apresentados resultados de três algoritmos modernos de aprendizado por reforço off-line, cada um utilizando diferentes mecanismos para prevenir a extrapolação além das ações presentes nos dados. E o clássico TD3 é apresentado como um teste básico para avaliar o impacto do modo off-line em métodos originalmente projetados para treinamento on-line e que não possuem um mecanismo explicitamente destinado a prevenir a extrapolação além da amostra de treinamento.
De acordo com os resultados dos experimentos realizados, os autores do método concluem que o uso de dados diversificados pode simplificar significativamente os algoritmos de aprendizado por reforço off-line, eliminando a necessidade de lidar com o problema de extrapolação. Os resultados demonstram que os dados exploratórios aumentam a eficácia do aprendizado por reforço off-line na resolução de uma variedade de tarefas. Além disso, os algoritmos de aprendizado por reforço off-line previamente desenvolvidos lidam bem com dados orientados para tarefas, mas são inferiores ao TD3 em dados não rotulados do ExORL. Idealmente, os algoritmos de aprendizado por reforço off-line deveriam se adaptar automaticamente ao conjunto de dados utilizado, para aproveitar o melhor de ambos os métodos.
2. Implementação com MQL5
Como você pode notar a partir da descrição acima, os autores do método Exploratory Data for off-line RL (ExORL) fornecem uma direção geral para a construção do framework. Ao mesmo tempo, eles experimentam com diferentes métodos de treinamento de modelos. E na parte prática do artigo, decidi construir uma implementação do ExORL o mais próxima possível do modelo do artigo anterior. Mas aqui vale a pena regatar algo muito construtivo. O algoritmo DWSL prevê a ponderação das ações do estado S por seu Benefício. Lembro que em nossa implementação, encontrávamos os estados mais próximos de todas as trajetórias por sua incorporação. E ponderávamos as ações nos estados selecionados de acordo com sua influência no resultado.
No entanto, o método ExORL pressupõe a máxima diversidade no comportamento do Agente. E nesse contexto, precisamos definir a distância entre as ações em estados individuais. Usar a distância para o par "Estado-Ação" mais próximo como recompensa incentivará o Agente a explorar o ambiente. Portanto, definiremos a incorporação do estado levando em conta a ação.
Como alternativa, existe a prática de definir a distância entre os estados subsequentes. E trabalhar com um ambiente estocástico adiciona uma pitada de racionalidade nisso. Quando a realização de uma ação com certa probabilidade pode levar a diferentes estados subsequentes. Mas o uso de tais algoritmos nos distancia ainda mais do método DWSL, que usamos como base para nossa implementação. E ajustes mínimos no algoritmo base nos permitirão avaliar melhor o impacto do framework ExORL nos resultados do treinamento do modelo.
Por isso, optei pela primeira opção e aumentei o tamanho da camada de dados de entrada do modelo do Codificador pelo vetor de ações do Ator. De resto, a arquitetura dos modelos permaneceu inalterada. E você pode se familiarizar com ela por conta própria no anexo. Arquivo "...\ExORL\Trajectory.mqh", método CreateDescriptions.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor ........ ........ //--- Critic ........ ........ //--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr + NActions; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 ........ ........ //--- return true; }
A coleta de dados de treinamento é realizada no EA "...\ExORL\ResearchExORL.mq5".
Observe a indicação do framework no nome do arquivo. Isso porque no anexo você também encontrará o arquivo "...\ExORL\Research.mq5", que foi transferido sem alterações do artigo anterior. E nós não vamos parar para analisar seu algoritmo.
Ambos os EAs mencionados são destinados para preencher a amostra de treinamento. E por mais estranho que possa parecer, durante o treinamento, usaremos ambos os EAs. Mas falaremos sobre isso mais tarde. Agora, vamos voltar à análise do algoritmo do EA "\...\ExORL\ResearchExORL.mq5".
Os parâmetros externos do EA foram transferidos sem alterações do EA básico de interação com o ambiente.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = 10; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price input int Agent = 1;
Apenas que, durante o processo de interação, vamos treinar a política de exploração do ambiente para o Ator. E, durante o treinamento, precisaremos dos modelos do Crítico e do Codificador. Para reduzir os custos de treinamento da política de exploração e, consequentemente, aumentar a velocidade de coleta de dados de treinamento, foi decidido usar apenas 1 Crítico.
CNet Actor; CNet Critic; CNet Convolution;
Além disso, adicionaremos à lista de variáveis globais a flag de carregamento de trajetórias previamente percorridas e a matriz de suas incorporações.
bool BaseLoaded; matrix<float> state_embeddings;
No método de inicialização do EA OnInit, primeiro inicializamos os indicadores analisados.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Indicaremos o tipo de operação de negociação.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
E carregaremos os modelos previamente treinados. Na ausência de tais modelos, criamos novos modelos, inicializados com pesos aleatórios. Neste EA, decidi dividir o carregamento dos modelos em diferentes blocos, o que me permite usar um Crítico previamente treinado na ausência de um Ator ou Codificador treinado.
Note que sempre falamos sobre a necessidade de ter um conjunto completo de modelos sincronizados. E, neste caso, deliberadamente usamos um Crítico treinado separadamente do Ator. E há uma razão para isso. Pensei muito sobre a construção do algoritmo de sincronização de coeficientes de peso entre os modelos em diferentes agentes de teste do MetaTrader 5. Mas desisti dessa ideia e decidi criar vários modelos do Ator de exploração treinados paralelamente. Uma vez inicializados com parâmetros aleatórios, esses modelos serão treinados paralelamente em dados históricos. E apesar de um único segmento histórico, cada modelo do Ator de exploração seguirá seu próprio caminho de treinamento. Assim, expandindo o subespaço explorado do ambiente. E o uso de um buffer de trajetórias previamente percorridas minimizará a repetição das trajetórias.
Para identificar os modelos dos Atores de exploração, adicionamos o sufixo "Ex" e o número do agente nos parâmetros externos ao nome do arquivo do modelo. E a otimização deste parâmetro nos permite executar vários Atores de exploração paralelamente no testador de estratégias do MetaTrader 5.
//--- load models float temp; if(!Actor.Load(StringFormat("%sAct%d.nnw", FileName, Agent), temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- }
Ao mesmo tempo, para criar condições idênticas de treinamento para todos os Atores de exploração, usamos um único modelo de Crítico. É por isso que é importante carregar o modelo de Crítico previamente treinado mesmo na ausência de modelos de Atores de exploração.
if(!Critic.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Critic.Create(critic)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
O uso de um único modelo de Codificador para todos os agentes também permite efetuar a comparação de estados e ações em um único subespaço. Mas não é crítico para o processo de treinamento. Pois cada Agente codifica independentemente as trajetórias previamente percorridas. Isso permite que ele avalie corretamente as distâncias e diversifique o comportamento do Ator.
if(!Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Convolution.Create(convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
Concordo que o código apresentado parece complicado. E, provavelmente, seria lógico dividir a descrição da arquitetura dos modelos em diferentes métodos. Mas isso simplificaria o código apenas para este EA. E, por outro lado, complicaria o código de outros programas usados no artigo. É precisamente por essa razão que optei por não fragmentar o método de descrição da arquitetura dos modelos.
Todos os modelos nós transferimos para um único contexto OpenCL, o que nos permitirá sincronizar seu funcionamento e reduzir o volume de cópias de dados entre a memória principal e a memória do contexto OpenCL.
Critic.SetOpenCL(Actor.GetOpenCL());
Convolution.SetOpenCL(Actor.GetOpenCL());
Critic.TrainMode(false);
Observe que desativamos o modo de treinamento do Crítico. Acima discutimos a importância de criar condições idênticas para o treinamento de todos os Agentes de exploração do ambiente. E manter o Crítico em um estado fixo desempenha um papel importante nesse processo.
Então, realizamos o controle mínimo padrão da arquitetura dos modelos.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
E inicializamos as variáveis globais.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); BaseLoaded = false; bGradient.BufferInit(MathMax(AccountDescr, NActions), 0); //--- return(INIT_SUCCEEDED); }
Após a conclusão bem-sucedida de todas as operações mencionadas acima, encerramos o método de inicialização do EA.
No método de inicialização do programa, não carregamos as trajetórias previamente percorridas. E não criamos suas incorporações. Isso se deve ao fato de que o processo de criação de incorporações dos estados previamente percorridos pode ser bastante custoso e demorado. Sua duração depende do número de estados visitados.
Como já mencionado anteriormente, ao contrário dos EAs de interação com o ambiente previamente considerados, neste caso estamos realizando o treinamento do Ator de exploração. E, após cada passagem, salvamos o modelo treinado.
void OnDeinit(const int reason) { //--- ResetLastError(); if(!Actor.Save(StringFormat("%sActEx%d.nnw", FileName, Agent), 0, 0, 0, TimeCurrent(), true)) PrintFormat("Error of saving Agent %d: %d", Agent, GetLastError()); delete Result; }
A seguir, vale a pena mencionar algumas palavras sobre os métodos auxiliares criados. Primeiramente, o processo de codificação dos estados e ações foi deslocado para o método CreateEmbeddings. Este método não possui parâmetros e retorna a matriz de incorporações dos estados.
No corpo do método, primeiro criamos variáveis locais.
matrix<float> CreateEmbeddings(void) { vector<float> temp; CBufferFloat State; Convolution.getResults(temp); matrix<float> result = matrix<float>::Zeros(0, temp.Size());
Depois tentamos carregar o banco de trajetórias coletado anteriormente. E em caso de erro de carregamento dos dados, retornamos uma matriz vazia para o programa chamador.
BaseLoaded = LoadTotalBase(); if(!BaseLoaded) { PrintFormat("%s - %d => Error of load base", __FUNCTION__, __LINE__); return result; }
Com o carregamento bem-sucedido do banco de trajetórias, calculamos o número total de estados em todas as trajetórias e ajustamos o tamanho da matriz a ser preenchida.
int total_tr = ArraySize(Buffer); //--- int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; result.Resize(total_states, temp.Size());
Segue-se um sistema de laços aninhados para codificar os estados e ações. No laço externo, percorremos as trajetórias carregadas. E no laço aninhado — os estados.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
No corpo deste sistema de laços, primeiro criamos um buffer com dados descritivos do estado do ambiente. Neste buffer, transferimos dados históricos de movimento de preço e indicadores analisados.
Em seguida, adicionamos a descrição do estado da conta e das posições abertas.
float prevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float prevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - prevBalance) / prevBalance); State.Add(Buffer[tr].States[st].account[1] / prevBalance); State.Add((Buffer[tr].States[st].account[1] - prevEquity) / prevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / prevBalance); State.Add(Buffer[tr].States[st].account[5] / prevBalance); State.Add(Buffer[tr].States[st].account[6] / prevBalance);
Adicionamos uma marca temporal na forma de um vetor de harmônicos.
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
E adicionamos o vetor de ações do Ator.
State.AddArray(Buffer[tr].States[st].action);
O tensor coletado é então passado ao Codificador para codificação e chamamos o método de propagação. A incorporação obtida é adicionada à matriz de resultados.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp); if(!result.Row(temp, state)) continue; state++; } } }
Depois disso, passamos para o próximo estado do buffer de trajetórias.
Após a conclusão de todas as iterações do sistema de laços de codificação dos estados, reduzimos o tamanho da matriz de resultados para o número real de incorporações salvas e limpamos o buffer das trajetórias carregadas anteriormente. Daqui para frente, trabalharemos apenas com as incorporações.
if(state != total_states) result.Reshape(state, result.Cols()); ArrayFree(Buffer);
O resultado obtido é retornado ao programa chamador e finalizamos o trabalho do método.
//--- return result; }
Em seguida, construímos o método de geração de recompensa interna, ResearchReward. É importante destacar que para criar um sistema eficaz de exploração do ambiente durante o treinamento dos Atores de exploração, usaremos apenas a recompensa interna, destinada a estimular o Agente a realizar ações diversificadas e não repetitivas. Portanto, nesta fase, não precisamos de dados rotulados ou recompensa externa, que poderiam limitar o espaço explorado do ambiente. Neste contexto, deve-se prestar especial atenção à formulação da recompensa interna.
Nos parâmetros do método ResearchReward, passamos:
- o quantil dos estados e ações mais próximos, usados para formar a recompensa interna;
- a incorporação do estado analisado;
- a matriz de incorporações de estados, que foi formada pelo método apresentado anteriormente.
No corpo do método, preparamos um vetor de resultados nulo e verificamos a correspondência dos tamanhos da incorporação do estado analisado com as incorporações na matriz previamente criada.
vector<float> ResearchReward(double quant, vector<float> &embedding, matrix<float> &state_embedding) { vector<float> result = vector<float>::Zeros(NRewards); if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
Após passar com sucesso pelo bloco de controle, inicializamos as variáveis locais.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * quant); matrix<float> temp = matrix<float>::Zeros(states, size); vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S;
A próxima etapa é calcular a distância entre o par analisado "Estado-Ação" e os anteriormente salvos no buffer de reprodução de experiência. Para obter uma avaliação suave das distâncias, usamos a função LogSumExp, conforme proposto pelos autores do método DWSL.
for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha = temp.Max(); if(alpha == 0) alpha = 1; vector<float> dist = MathLog(MathExp(temp / (-alpha)).Sum(1)) * (-alpha);
Em seguida, selecionamos o número necessário de incorporações dos pares "Estado-Ação" mais próximos.
float max = dist.Quantile(quant); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
E, usando o algoritmo de normas de kernel, geramos a recompensa interna para a ação selecionada do Ator e o estado latente.
k_embedding.SVD(U, V, S); result[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result[NRewards - 1] = EntropyLatentState(Actor); //--- return result; }
O resultado obtido é retornado ao programa chamador.
Note que, no vetor de resultados, os elementos da recompensa externa permanecem com valores zero. Isso é totalmente consistente com o framework ExORL. O EA em discussão é destinado à organização de uma exploração não supervisionada do ambiente. E como já foi mencionado anteriormente, o uso de recompensa externa nesta fase apenas restringiria o subespaço explorado.
O processo direto de interação com o ambiente e o treinamento da política do Ator de exploração é organizado no método de processamento de ticks, OnTick. Deve-se dizer imediatamente que, nesta fase, o processo de treinamento foi simplificado ao máximo. Como já mencionado anteriormente, durante o treinamento, usamos apenas 1 Crítico. Além disso, não desistimos do uso do buffer de reprodução de experiência durante o treinamento do modelo do Ator de exploração. Potencialmente, a ausência dele é compensada por passagens adicionais no testador de estratégias.
Realizaremos uma retropropagação em cada vela. Ao mesmo tempo, a correção dos parâmetros é feita com base na última ação do Ator.
Esse método pode não ser o mais eficiente, mas é o mais simples de implementar. E é perfeitamente aplicável para avaliar a eficácia do método.
No corpo do método, como sempre, primeiro verificamos a ocorrência de uma nova barra aberta.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Depois carregamos os dados históricos.
//--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
A seguir, formamos os buffers de dados de entrada do nosso Ator-pesquisador. Aqui primeiro preenchemos o buffer com a descrição do estado do ambiente usando os dados históricos obtidos.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Então verificamos o estado atual da conta e as posições abertas.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Com os dados obtidos, criamos um buffer descrevendo o estado da conta.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
Ao qual, em seguida, adicionamos o vetor de harmônicas da marca temporal.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Os dados formados são suficientes para realizar a propagação do Ator.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
Como resultado de uma propagação bem-sucedida do Ator, obtemos um vetor de ações previstas, que decodificamos e transmitimos ao ambiente.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Primeiramente, realizamos a interação com o ambiente no contexto de uma posição longa.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
E repetimos as operações para uma curta.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Os resultados da interação com o ambiente são coletados em uma estrutura descrevendo o estado e as ações. Complementamos com uma recompensa externa. E adicionamos à trajetória, que será incluída no buffer de reprodução de experiência após a passagem.
//--- sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove();
É importante notar o vetor de recompensas. Anteriormente falamos de uma pesquisa não controlada, e preenchemos o vetor com recompensas externas. Enquanto isso, os elementos da recompensa interna, ao contrário, são deixados com valores zero. Aqui é importante entender que as trajetórias salvas serão usadas para treinar a política principal do Ator na fase 3 do framework ExORL. E o preenchimento do buffer de recompensa é uma implementação da segunda fase do método considerado — Reavaliação de estados e ações. Portanto, todas as nossas ações estão dentro dos limites do algoritmo ExORL.
Como você pode observar, o algoritmo apresentado acima praticamente repete os métodos de interação com o ambiente que examinamos anteriormente. Mas não concluímos o trabalho do método como antes. E passamos para a implementação do processo de treinamento da política do Ator-pesquisador.
Primeiramente, precisamos da incorporação do estado atual e da ação realizada. Para isso, complementamos o buffer do estado atual do ambiente com informações sobre o estado da conta e a ação realizada pelo Ator. O buffer obtido é então fornecido à entrada do Codificador e chamamos o método de propagação.
bState.AddArray(GetPointer(bAccount)); bState.AddArray(temp); bActions.AssignArray(temp); if(!Convolution.feedForward(GetPointer(bState), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Convolution.getResults(temp);
Como resultado das operações bem-sucedidas, obtemos a incorporação do estado atual.
Em seguida, verificamos a presença de dados carregados sobre as trajetórias previamente percorridas e, se necessário, realizamos sua codificação, chamando o método apresentado CreateEmbeddings.
if(!BaseLoaded) { state_embeddings = CreateEmbeddings(); BaseLoaded = true; }
Note que, independentemente do resultado das operações, mudamos para o estado true a flag de carregamento de dados. Isso nos permitirá no futuro evitar tentativas repetidas de carregar a base de estados percorridos.
Em seguida, verificamos o tamanho da matriz de incorporação de estados. Um tamanho zero dessa matriz pode indicar a ausência de trajetórias previamente percorridas. Nesse caso, não temos dados para atualizar os parâmetros do modelo nesta etapa. E simplesmente adicionamos à matriz a incorporação do estado atual. Após o qual passamos a aguardar a abertura da próxima vela.
ulong total_states = state_embeddings.Rows(); if(total_states <= 0) { ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError()); return; }
Se houver dados na matriz de incorporação de estados percorridos, geramos uma recompensa interna e complementamos a matriz com a incorporação do estado atual.
vector<float> rewards = ResearchReward(Quant, temp, state_embeddings); ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError());
É muito importante adicionar a incorporação do estado atual à matriz de incorporações de estados passados apenas após a geração da recompensa interna. Caso contrário, a incorporação atual será contabilizada duas vezes no cálculo da recompensa interna, o que pode distorcer os dados.
A eliminação completa do processo de adição de incorporações na matriz impedirá a consideração dos estados do percurso atual ao gerar a recompensa interna.
A recompensa interna gerada é transferida para o buffer de dados. E então realizamos a propagação e a retropropagação do Crítico. Seguida pela retropropagação do Ator-pesquisador.
Result.AssignArray(rewards); if(!Critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(bActions)) || !Critic.backProp(Result, GetPointer(bActions), GetPointer(bGradient)) || !Actor.backPropGradient(GetPointer(bAccount), GetPointer(bGradient), LatentLayer)) PrintFormat("%s -> %d: Error of backpropagation %", __FUNCTION__, __LINE__, GetLastError()); }
Note que, neste caso, dentro de uma única operação, realizamos uma chamada sequencial dos métodos de propagação e retropropagação do Crítico. A questão é que não estamos realizando o treinamento do Crítico nem avaliando os resultados de sua propagação. Ele é necessário apenas para transmitir o gradiente de erro ao Ator. Por isso, ambos os métodos são chamados no contexto da realização do procedimento de retropropagação do Ator. Isso levou a tal composição incomum de chamada de métodos, que, no entanto, não influencia o resultado final.
Com isso, concluímos a descrição do método de interação com o ambiente e do treinamento on-line da política do Ator-pesquisador. Outros métodos do EA foram transferidos sem alterações. E você pode se familiarizar com eles no anexo.
Agora passamos para a correção do EA de treinamento do modelo. Apesar de os autores do método terem usado métodos básicos de treinamento de modelos em seus experimentos, a implementação de nossa abordagem exigiu algumas alterações do EA de treinamento do artigo anterior. As mudanças são principalmente devido à alteração da arquitetura do Codificador, o que levou à correção dos pontos de interação com o modelo. Mas vamos por partes.
As mudanças introduzidas não são globais. Portanto, nos concentraremos apenas na revisão do método de treinamento direto do modelo, Train. No corpo do método, verificamos o número de trajetórias carregadas.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Depois, calculamos o número total de estados nessas trajetórias.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total;
A seguir, preparamos variáveis locais.
vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
E estabelecemos um sistema de laços para codificar os estados anteriormente percorridos, formando uma matriz de incorporações. Este processo é semelhante ao descrito acima, mas há uma nuance.
Como antes, no corpo do sistema de laços, preenchemos o buffer do estado atual do ambiente.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
Complementamos com o estado da conta e posições abertas.
float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance);
Preenchemos as harmônicas da marca temporal.
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Mas, em vez do vetor de ações, passamos um vetor zero de comprimento correspondente.
State.AddArray(vector<float>::Zeros(NActions));
Essa decisão nos permite excluir a influência das ações realizadas sobre a incorporação dos estados. E assim, retornamos à implementação do método DWSL do artigo anterior, neutralizando as mudanças na arquitetura do Codificador. Assim, de acordo com as recomendações dos autores do método ExORL, usamos métodos de treinamento de modelos não modificados. Durante o processo de treinamento de todos os modelos, é utilizado um único Codificador de "Estados-Ações". Isso nos permite treinar corretamente tanto as políticas dos Ator-pesquisadores quanto a política principal do Ator.
Em seguida, realizamos a propagação do Codificador. E adicionamos o resultado em forma de incorporação do estado à matriz.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); if(!state_embedding.Row(temp, state)) continue;
Ao mesmo tempo, sincronizamos o preenchimento das matrizes de ações e recompensas, que serão usadas no processo de treinamento conforme o algoritmo DWSL. Como antes, a matriz de recompensas é preenchida com os valores dos benefícios das ações realizadas.
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue; state++;
Informamos o usuário sobre o progresso da codificação dos estados e passamos para a próxima iteração do sistema de laços.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão bem-sucedida de todas as iterações de codificação dos estados, reduzimos o tamanho das matrizes para o volume de dados realmente salvos. No entanto, ao contrário do método de codificação CreateEmbeddings considerado anteriormente, não limpamos o array de trajetórias, pois ele ainda será necessário no treinamento dos modelos.
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
} Segue-se a realização do processo de treinamento imediato. Primeiramente, criamos variáveis locais e formamos um vetor de probabilidades de seleção de trajetórias.
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr;
Em seguida, executamos um ciclo de treinamento. No corpo do ciclo, amostramos uma trajetória e um estado nela.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Depois, verificamos a necessidade de formar uma recompensa até o final do episódio. E, se necessário, preenchemos o buffer do próximo estado do ambiente.
target_reward = vector<float>::Zeros(NRewards); //--- Target if(iter >= StartTargetIter) { State.AssignArray(Buffer[tr].States[i + 1].state);
Imediatamente preenchemos o buffer descrevendo o próximo estado da conta e posições abertas.
float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
E o complementamos com as harmônicas da marca temporal.
double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Os dados formados são suficientes para realizar a propagação do Ator, que gerará uma ação de acordo com a política atualizada.
//--- if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A ação obtida é avaliada por 2 Críticos-alvo.
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2);
Usamos a menor das avaliações como a recompensa esperada. E a complementamos com a entropia do estado latente.
target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
A próxima etapa é o treinamento dos modelos dos Críticos. Para isso, formamos um vetor descrevendo o estado atual do ambiente.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
Formamos um vetor que descreve o estado da conta e posições abertas, complementado com as harmônicas da marca temporal.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Depois, realizamos a propagação do Ator.
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Como você lembra, para o treinamento dos Críticos, usamos as ações reais realizadas durante a interação com o ambiente. No entanto, a propagação do Ator é necessária para a formação do estado latente.
Em seguida, copiamos as ações reais da amostra de treinamento para o buffer de dados e realizamos a propagação dos Críticos.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Depois, adicionamos ao buffer descrevendo o estado atual do ambiente os dados sobre o estado da conta e um vetor zero, para substituir as ações do Ator. E geramos a incorporação do estado analisado do ambiente.
if(!State.AddArray(GetPointer(Account)) || !State.AddArray(vector<float>::Zeros(NActions)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
Com base na incorporação obtida, geramos uma estrutura de metas para o treinamento dos modelos. O algoritmo do método de formação de valores-alvo é descrito no artigo anterior.
target = GetTargets(Quant, temp, state_embedding, rewards, actions);
Neste estágio, temos todos os dados necessários para a retropropagação dos Críticos. Mas, como ajustaremos o vetor de gradiente de erro usando o método CAGrad, realizaremos o treinamento dos modelos sequencialmente.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
O próximo passo é o treinamento da política principal do Ator. Como antes, para o treinamento da política, usaremos combinações de abordagens. Inicialmente, usamos o algoritmo DWSL e treinamos o Ator para repetir ações ponderadas pelo seu impacto no resultado final.
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
E então ajustaremos as ações do Ator para aumentar a rentabilidade. Somente a segunda etapa do treinamento é usada quando há confiança suficiente na precisão da avaliação pelo Crítico.
//--- CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
Ao concluir as iterações do processo de treinamento, ajustaremos os parâmetros dos modelos alvo.
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
Informaremos o usuário sobre o andamento do treinamento e passaremos para a próxima iteração do ciclo de treinamento.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após concluir o ciclo completo de treinamento dos modelos, limparemos o campo de comentários no gráfico. Exibiremos os resultados do treinamento no log e iniciaremos o processo de encerramento do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, concluímos a descrição dos algoritmos utilizados nos programas. O código completo de todos os programas usados neste artigo pode ser encontrado no anexo. Agora passamos para a etapa de testar o trabalho realizado.
3. Testando
Nas seções anteriores deste artigo, aprendemos sobre o método Exploratory data for offline RL e implementamos nossa visão do método usando MQL5. Agora é hora de avaliar os resultados do trabalho realizado. Como sempre, o treinamento e os testes do modelo são realizados em dados históricos do instrumento EURUSD, timeframe H1. Os parâmetros de todos os indicadores são usados por padrão. O treinamento dos modelos é realizado com dados históricos dos primeiros 7 meses de 2023. Os testes dos modelos treinados são realizados com dados de agosto de 2023.
O algoritmo apresentado no artigo permite treinar modelos completamente novos. Por assim dizer, "do zero". No entanto, o método também permite o ajuste fino de modelos previamente treinados. Foi essa segunda opção de uso do método que decidi testar. Como mencionado no início de nosso trabalho, os EAs da artigo anterior foram usados como base para nosso trabalho. A otimização deste modelo que realizaremos. Primeiramente, é necessário renomear os arquivos dos modelos.
| DWSL.bd. | ==> | ExORL.bd. |
| DWSLAct.nnw | ==> | ExORLAct.nnw |
| DWSLCrt1.nnw | ==> | ExORLCrt1.nnw |
| DWSLCrt2.nnw | ==> | ExORLCrt2.nnw |
Não transferimos o modelo do Codificador, pois alteramos sua arquitetura.
Após renomear os arquivos, executamos o EA "ResearchExORL.mq5" para uma investigação adicional do ambiente nos dados de treinamento. Em meu trabalho, realizei 100 passagens adicionais com 5 agentes de teste.
A experiência prática mostra a possibilidade de uso paralelo em um único buffer de reprodução coletado por diferentes métodos. Usei tanto as trajetórias coletadas anteriormente pelo EA "Research.mq5" quanto pelo "ResearchExORL.mq5". O primeiro destaca as vantagens e desvantagens da política aprendida pelo Ator. O segundo permite explorar ao máximo o ambiente e avaliar as oportunidades não contabilizadas.
Durante o processo iterativo de treinamento do modelo, consegui aumentar sua eficácia.


Com uma redução geral no número de negociações durante o período de teste em 3 vezes (56 contra 176), o lucro aumentou quase 3 vezes. O valor da negociação mais lucrativa aumentou mais de duas vezes. E a média de lucro por negociação aumentou cinco vezes. Durante todo o período de teste, observamos um aumento no saldo. Como resultado, o fator de lucro do modelo aumentou de 1.3 para 2.96.
Considerações finais
Neste artigo, exploramos um novo método, Exploratory data for off-line RL, que enfatiza principalmente a abordagem de coleta de dados para a amostra de treinamento durante o treinamento off-line de modelos. Os experimentos realizados pelos autores do método colocam a escolha dos dados iniciais como uma das questões chave, que tem um impacto no resultado ao nível da escolha da arquitetura do modelo e do método de treinamento.
Na parte prática de nosso artigo, implementamos nossa visão do método proposto e realizamos seus testes em dados históricos do testador de estratégias MetaTrader 5. Os testes realizados confirmam as conclusões dos autores do método sobre o impacto do algoritmo de coleta de amostra de treinamento no resultado do treinamento do modelo. Foi praticamente apenas graças à mudança na abordagem de coleta de trajetórias de treinamento que conseguimos otimizar o funcionamento do modelo do artigo anterior.
No entanto, gostaria de chamar a atenção novamente para o fato de que todos os programas apresentados no artigo são destinados apenas para demonstração do método e não são otimizados para negociação real.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA para coleta de exemplos |
| 2 | ResearchExORL.mq5 | EA | EA para coleta de exemplos pelo método ExORL |
| 3 | Study.mq5 | EA | EA para treinamento do agente |
| 4 | Test.mq5 | EA | EA para testar o modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura que descreve o estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criar redes neurais |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13819
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso