
Neuronale Netze leicht gemacht (Teil 52): Forschung mit Optimismus und Verteilungskorrektur

Einführung
Eines der grundlegenden Elemente zur Erhöhung der Stabilität des Q-Funktionslernens ist die Verwendung eines Erfahrungswiederholungspuffers. Eine Vergrößerung des Puffers ermöglicht es, vielfältigere Beispiele für die Interaktion mit der Umwelt zu sammeln. Dies ermöglicht es unserem Modell, die Q-Funktion der Umwelt besser zu untersuchen und zu reproduzieren. Diese Technik ist in verschiedenen Algorithmen des Reinforcement Learning weit verbreitet, darunter auch in Algorithmen der Familien von Akteur und Kritiker.
Aber es gibt auch eine andere Seite der Medaille. Während des Lernprozesses unterscheiden sich die Handlungen des Akteurs zunehmend von den Beispielen, die im Erfahrungswiedergabepuffer gespeichert sind. Je mehr Iterationen zur Aktualisierung der Modellparameter durchgeführt werden, desto größer ist dieser Unterschied. Dies führt zu einer Verringerung der Effizienz der Ausbildung der Akteurspolitik. Eine mögliche Lösung wurde in dem Artikel „Off-policy Reinforcement Learning with Optimistic Exploration and Distribution Correction“ (Oktober 2021) vorgestellt. Die Autoren der Methode haben vorgeschlagen, die Methode der Verteilungskorrekturschätzung (DICE) an den Soft Actor-Critic-Algorithmus anzupassen.
Gleichzeitig haben die Autoren der Methode auf eine weitere Nuance geachtet. Während des Trainings der Richtlinien verwendet die Methode Soft Actor-Critic eine minimale Handlungsbewertung. Die praktische Anwendung dieses Ansatzes zeigt eine Tendenz zur pessimistischen, unzureichenden Erkundung der Umwelt und zur gezielten Homogenität der Maßnahmen. Um diesen Effekt zu minimieren, schlugen die Autoren des Artikels vor, zusätzlich ein optimistisches Forschungsakteursmodell zu trainieren. Dies wiederum vergrößert die Diskrepanz zwischen dem Beispiel der Interaktion zwischen dem optimistischen Akteursmodell und der Umwelt und der Verteilung der Aktionen des trainierten Zielmodells weiter.
Die kombinierte Anwendung der Korrektur von Verteilungsschätzungen und die Untersuchung eines optimistischen Akteursmodells kann jedoch das Trainingsergebnis des Zielmodells verbessern.

1. Forschung mit Optimismus
Die ersten Ideen zur Umgebungserkundung mit Optimismus wurden in dem Artikel „Off-policy Reinforcement Learning with Optimistic Exploration and Distribution Correction“ (Oktober 2019) dargelegt. Die Autoren stellten fest, dass die Kombination aus der gierigen Aktualisierung des Akteurs und der pessimistischen Einschätzung des Kritikers dazu führt, dass der Akteur Handlungen vermeidet, von denen er nichts weiß. Dieses Phänomen wurde als „pessimistische Unterexploration“ bezeichnet. Darüber hinaus sind die meisten Algorithmen nicht über die Forschungsrichtung informiert. Bei zufällig ausgewählten Aktionen ist die Wahrscheinlichkeit gleich groß, dass sie sich auf den entgegengesetzten Seiten des aktuellen Durchschnitts befinden, während wir in der Regel in bestimmten Bereichen viel mehr Aktionen brauchen als in anderen. Um diese Phänomene zu korrigieren, wurde der Algorithmus Optimistic Actor Critic (OAC) vorgeschlagen, der die unteren und oberen Vertrauensgrenzen der State-Action-Wertfunktion approximiert. Dies ermöglichte die Anwendung des Optimismusprinzips bei der Ungewissheit, eine gezielte Forschung mit einer Obergrenze durchzuführen. Gleichzeitig trägt die Untergrenze dazu bei, dass die Maßnahmen nicht überbewertet werden.
Die Autoren der Methode haben die Ideen vom Optimistischen Akteur-Kritiker aufgegriffen und weiterentwickelt. Wie bei Soft Actor-Critic werden wir 2 Kritiker-Modelle trainieren. Gleichzeitig werden wir aber auch 2 Akteursmodelle trainieren: πе und das Ziel πт-Forschung.
Die Strategie πе wird so trainiert, dass sie eine Annäherung an die obere Schranke der Werte der Q-Funktion QUB maximiert. Gleichzeitig wird πт trainiert, um eine Annäherung an die untere Schranke der Q-Funktion QLB zu maximieren. OAC zeigt, dass die Forschung mit πе im Vergleich zu Soft Actor-Critic eine effizientere Nutzung von Stichproben ermöglicht.
Um eine ungefähre obere Schranke der Q-Funktion QUB zu erhalten, werden zunächst der Mittelwert und die Varianz der Bewertungen der beiden Kritiker berechnet:
![]()
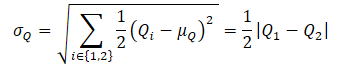
Als Nächstes definieren wir QUB anhand der Gleichung:
![]()
wobei βUB ∈ R ist und das Optimismusniveau steuert.
Man beachte, dass die vorherige ungefähre untere Schranke der Q-Funktion QLB ausgedrückt werden kann als
![]()
Bei einem Pessimismusgrad von βLB = 1 entspricht QLB dem Minimum der Bewertungen der Kritiker.
Optimistic Actor-Critic wendet eine maximale KL-Divergenz-Beschränkung zwischen πе und πт an, die es uns ermöglicht, eine geschlossene Lösung für πе zu erhalten und das Training zu stabilisieren. Gleichzeitig schränkt dies das Potenzial von πе ein, informativere Maßnahmen zu ergreifen, die möglicherweise die falschen Einschätzungen der Kritiker korrigieren könnten. Diese Einschränkung verhindert, dass πе Handlungen erzeugt, die sich stark von denen der Strategie πт unterscheiden, die konservativ auf der Grundlage der Mindestbewertung der Kritiker trainiert wurde.
Beim Algorithmus SAC+DICE entfällt durch den Zusatz der Verteilungskorrektur die Verwendung der KL-Beschränkung, um alle Explorationsmöglichkeiten mit einer optimistischen Politik zu erschließen. In diesem Fall wird die Stabilität des Trainings aufrechterhalten, indem die verzerrte Gradientenschätzung beim Training der Strategie explizit korrigiert wird.
Während des Trainings der Verhaltenspolitik des Akteurs πт, um eine Überschätzung der Q-Funktion zu verhindern, wird eine ungefähre untere Schranke der QLB als Kritiker verwendet, wie bei der Soft Actor-Critic-Methode. Es wird jedoch eine Anpassung der Stichprobenverteilung durch das Verhältnis dπт(s,a)/dD(s,a) vorgenommen. Wir erhalten das folgende Trainingsziel:
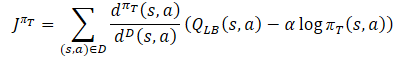
wobei dπт(s,a) die Zustands-Aktions-Verteilung der aktuellen Politik darstellt, während dD(s,a) die Zustands-Aktions-Verteilung aus dem Erfahrungswiedergabepuffer definiert. Der Gradient eines solchen Trainingsziels liefert eine unvoreingenommene Schätzung des Policy-Gradienten, im Gegensatz zu früheren Actor-Critic-Lernalgorithmen, die eine voreingenommene Schätzung beim Training der Ziel-Policy verwenden.
Die Forschungsstrategie πе sollte die optimistische Verzerrung im Verhältnis zu den geschätzten Q-Funktionswerten untersuchen, um Erfahrungen mit der wirksamen Korrektur falscher Schätzungen zu sammeln. Daher schlugen die Autoren der Methode vor, eine ungefähre obere Schranke ähnlich der optimistischen akteurskritischen QUB als Kritiker in der Zielfunktion zu verwenden. Das letztendliche Ziel der Strategie πе und einer besseren Schätzung der Q-Funktion besteht darin, eine genauere Schätzung des Gradienten für die Zielstrategie πт zu ermöglichen. Daher sollte die Stichprobenverteilung für die Verlustfunktion πе mit der Verhaltenspolitik πт konsistent sein. Folglich schlagen die Autoren der Methode vor, denselben Korrekturkoeffizienten zu verwenden wie für die Verlustfunktion der Zielpolitik des Akteurs.
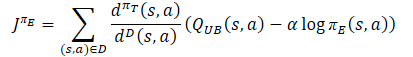
Was die Kritiker betrifft, so wird der zuvor diskutierte Ansatz vom Soft Actor-Critic beibehalten. Die untere Grenze der Q-Funktion der Zielmodelle wird verwendet, um sie zu trainieren. Es gibt jedoch eine Reihe von Studien, die die Effizienz der Verwendung derselben Proben für die Ausbildung von Akteuren und Kritikern belegen. Daher wurde auch ein Verteilungskorrekturfaktor zur Verlustfunktion Critics hinzugefügt.
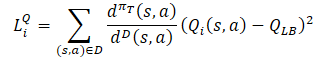
Wie Sie sehen, wirft der Verteilungskorrekturkoeffizient die meisten Fragen zu den oben beschriebenen Punkten auf. Betrachten wir sie im Detail.
2. Korrektur der Verteilung
Die Algorithmusfamilie Distribution Correction Estimation (DICE) wurde entwickelt, um das Problem der OPE-Korrektur (Off-Policy Evaluation) zu lösen. Mit diesen Methoden können wir einen Schätzer für den Strategiewert trainieren, d. h. die normalisierte erwartete Belohnung für einen Schritt auf der Grundlage des statischen Wiederholungspuffers D. DICE erhält einen unverzerrten Schätzer, der den Verteilungskorrekturkoeffizienten schätzt.
![]()
Um den Verteilungskorrekturkoeffizienten zu schätzen, haben die Autoren der Methode die DICE-Optimierungsstruktur angepasst, die als lineares Minimax-Verteilungsprogramm mit verschiedenen Regularisierungen formuliert werden kann. Die direkte Anwendung von DICE-Algorithmen auf Off-Policy-Reinforcement-Learning-Settings stellt eine große Herausforderung für die Optimierung dar. Das bewertungsfreie Training setzt eine feste Zielpolitik und einen statischen Wiedergabepuffer mit ausreichender Zustands-Aktionsraum-Abdeckung voraus, während sich bei RL die Zielpolitik und der Erfahrungswiedergabepuffer während des Trainings ändern. Daher haben die Autoren der SAC+DICE-Methode mehrere Änderungen vorgenommen, um diese Schwierigkeiten zu überwinden. Wir werden jetzt nicht in die Mathematik eintauchen und uns mit diesen Änderungen befassen. Sie finden sie im Originalartikel. Ich werde nur die Verlustfunktionen vorstellen, die sich aus den vorgeschlagenen Änderungen ergeben.
![]()
![]()
![]()
Hier sind ζ(s,a) und v(s,a) Modelle neuronaler Netze, während λ ein einstellbarer Lagrange-Koeffizient ist. ζ(s,a) approximiert den Verteilungskorrekturfaktor. v(s,a) ist eine Art Kritiker. Um das Training zu stabilisieren, werden wir die v Zielmodell mit einer weichen Aktualisierung seiner Parameter, ähnlich wie beim Kritiker.
Zur Optimierung aller Parameter schlagen die Autoren vor, die Adam-Methode anzuwenden.
Alle oben genannten Verfahren werden zu einem einzigen SAC+DICE-Algorithmus verallgemeinert. Wie bei konventionellen Algorithmen zum Verstärkungslernen ohne Strategie führen wir nacheinander Interaktionen mit der Umwelt durch, wobei wir der optimistischen Explorationsstrategie πе folgen, und speichern die Daten im Erfahrungswiedergabepuffer. Bei jedem Trainingsschritt aktualisiert der betrachtete Algorithmus zunächst die Modelle und DICE-Parameter (v, ζ, λ) unter Verwendung von SGD in Bezug auf die oben genannten Verlustfunktionen.
Dann berechnen wir das Korrekturverhältnis der ζ-Verteilung anhand des aktualisierten Modells.
Dann trainieren wir RL mit ζ, um πт, πе, Q1 und Q2 zu aktualisieren.
Am Ende eines jeden Trainingsschritts werden die Zielmodelle Q1, Q2 und v sanft aktualisiert.
3. Implementierung mittels MQL5
Beim Lesen des theoretischen Teils ist Ihnen vielleicht aufgefallen, dass die Anzahl der trainierten Modelle und Parameter stark ansteigt. Die Anzahl der trainierten Modelle hat sich von 3 auf 6 erhöht. Ihre Interaktion wird immer komplizierter. Gleichzeitig erwarten wir, ein Modell der Verhaltenspolitik des Akteurs zu erhalten. Um die ganze Routinearbeit vor den Nutzern zu verbergen, werden wir unseren Ansatz leicht ändern und das gesamte Training in eine separate Klasse CNet_SAC_DICE verpacken. Unsere neue Klasse wird ein Nachfolger der Basisklasse der neuronalen Netzmodelle von CNet sein. Im Klassenkörper werden wir 5 trainierbare Modelle und 3 Zielmodelle deklarieren. Hier werden wir auch eine Reihe von internen Variablen deklarieren. Wir werden uns ihre Funktionalität während der Implementierung ansehen.
class CNet_SAC_DICE : protected CNet { protected: CNet cActorExploer; CNet cCritic1; CNet cCritic2; CNet cTargetCritic1; CNet cTargetCritic2; CNet cZeta; CNet cNu; CNet cTargetNu; float fLambda; float fLambda_m; float fLambda_v; int iLatentLayer; //--- float fLoss1; float fLoss2; float fZeta; //--- vector<float> GetLogProbability(CBufferFloat *Actions); public: //--- CNet_SAC_DICE(void); ~CNet_SAC_DICE(void) {} //--- bool Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer = -1); //--- virtual bool Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &ActionsLogProbab, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float reward, float discount, float tau); virtual void GetLoss(float &loss1, float &loss2) { loss1 = fLoss1; loss2 = fLoss2; } //--- virtual bool Save(string file_name, bool common = true); bool Load(string file_name, bool common = true); };
Bitte beachten Sie, dass wir ursprünglich von 6 trainierbaren Modellen sprachen, aber nur 5 angaben. Unter den angekündigten Modellen gibt es keine Zielpolitik des Akteurs. Das Ziel der gesamten Ausbildung ist es jedoch, genau dies zu erreichen. Wie bereits erwähnt, ist unsere neue Klasse ein Nachfolger der Basisklasse neuronales Netz. Das bedeutet, dass es selbst ein Lernmodell ist. Daher wird die Schulung der grundlegenden Akteurspolitik mit Hilfe der übergeordneten Klasse durchgeführt.
Außerdem wird die neue Klasse CNet_SAC_DICE, die gerade erstellt wird, nur für das Modelltraining verwendet. Im laufenden Betrieb ist die Erstellung von Objekten zusätzlicher Modelle nicht sinnvoll und verbraucht unnötig Ressourcen. Daher planen wir, während des Betriebs grundlegende Modellobjekte zu verwenden. Aus diesem Grund verfügt die neue Klasse nicht über Vorwärts- oder Rückwärtspassmethoden. Die gesamte Funktionsweise in der Methode Study implementiert.
Natürlich gibt es auch Methoden für die Arbeit mit den Dateien Save und Load. Aber das Wichtigste zuerst.
Im Klassenkonstruktor initialisieren wir interne Variablen mit Anfangswerten. Alle internen Objekte werden statisch deklariert und unterliegen nicht der Initialisierung. Dementsprechend brauchen wir den Speicher im Destruktor nicht zu löschen, was uns erlaubt, den Destruktor leer zu lassen.
CNet_SAC_DICE::CNet_SAC_DICE(void) : fLambda(1.0e-5f), fLambda_m(0), fLambda_v(0), fLoss1(0), fLoss2(0), fZeta(0) { }
Die vollständige Initialisierung der Modelle wird in der Methode Create durchgeführt. In den Parametern der Methode werden die dynamischen Arrays der Beschreibungen der Architektur aller verwendeten Modelle und die ID der latenten Schicht des Akteurs mit einer komprimierten Darstellung des analysierten Zustands der Umgebung übergeben.
Im Hauptteil der Methode erstellen wir zunächst die Actor-Modelle. Das optimistische Modell wird im Objekt cActorExploer erstellt. Das Zielmodell wird im Hauptteil unserer Klasse mit Hilfe der geerbten Werkzeuge erstellt.
bool CNet_SAC_DICE::Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer) { ResetLastError(); //--- if(!cActorExploer.Create(actor) || !CNet::Create(actor)) { PrintFormat("Error of create Actor: %d", GetLastError()); return false; } //--- if(!opencl) { Print("Don't opened OpenCL context"); return false; }
Wir überprüfen sofort den erstellten OpenCL-Kontextzeiger.
Als Nächstes erstellen wir trainierbare Modelle der beiden Kritiker.
if(!cCritic1.Create(critic) || !cCritic2.Create(critic)) { PrintFormat("Error of create Critic: %d", GetLastError()); return false; }
Es folgen die Block-DICE-Objekte und Zielmodelle.
if(!cZeta.Create(zeta) || !cNu.Create(nu)) { PrintFormat("Error of create function nets: %d", GetLastError()); return false; } //--- if(!cTargetCritic1.Create(critic) || !cTargetCritic2.Create(critic) || !cTargetNu.Create(nu)) { PrintFormat("Error of create target models: %d", GetLastError()); return false; }
Nachdem wir alle Modelle erfolgreich erstellt haben, übergeben wir sie an einen einzigen OpenCL-Kontext.
cActorExploer.SetOpenCL(opencl); cCritic1.SetOpenCL(opencl); cCritic2.SetOpenCL(opencl); cZeta.SetOpenCL(opencl); cNu.SetOpenCL(opencl); cTargetCritic1.SetOpenCL(opencl); cTargetCritic2.SetOpenCL(opencl); cTargetNu.SetOpenCL(opencl);
Und kopieren Sie die Modellparameter in ihre Zielkopien. Außerdem sollten wir nicht vergessen, die Ausführung der Vorgänge bei jedem Schritt zu kontrollieren.
if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), 1.0) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), 1.0) || !cTargetNu.WeightsUpdate(GetPointer(cNu), 1.0)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; }
Nachdem alle erforderlichen Objekte erfolgreich erstellt wurden, werden die Daten in interne Variablen übertragen und die Methode beendet.
fLambda = 1.0e-5f; fLambda_m = 0; fLambda_v = 0; fZeta = 0; iLatentLayer = latent_layer; //--- return true; }
Nach der Initialisierung der internen Objekte der Klasse fahren wir mit dem Training des Modells CNet_SAC_DICE::Study fort. In den Parametern dieser Klasse erhalten wir alle Informationen, die für einen Schritt des Trainings des Modells notwendig sind. Hier sind die aktuellen und zukünftigen Zustände der Umwelt. In diesem Fall wird jeder Zustand in zwei Datenpuffern beschrieben: historische Daten und Gleichgewichtszustand. Hier sehen Sie auch den Aktionspuffer und die Belohnungsvariable. Es gibt auch Variablen für Abzinsungssätze und die sanfte Aktualisierung von Zielmodellen. Zum ersten Mal fügen wir einen Vektor der Logarithmen der Wahrscheinlichkeit der ursprünglichen Politik hinzu (die beim Sammeln von Beispielen verwendet wird).
bool CNet_SAC_DICE::Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &ActionsLogProbab, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float reward, float discount, float tau) { //--- if(!Actions || Actions.Total()!=ActionsLogProbab.Size()) return false;
Im Hauptteil der Methode führen wir zunächst einen kleinen Kontrollblock durch, in dem wir die Relevanz des Zeigers auf den Aktionspuffer und die Übereinstimmung seiner Größe mit der Größe des Wahrscheinlichkeitslogarithmusvektors überprüfen. Zeiger auf andere Puffer werden nicht überprüft, da ihre Kontrolle in den aufgerufenen Methoden implementiert ist.
Nach erfolgreichem Durchlaufen des Kontrollblocks führen wir weitere Zustandsbewertungen durch die Zielmodelle unter Berücksichtigung der aktuellen Politik durch. Zu diesem Zweck führen wir zunächst einen direkten Durchlauf unserer konservativen Akteurspolitik durch. Wir verwenden es zur Vorverarbeitung von Rohdaten, die den aktuellen Zustand beschreiben, und zur Vorhersage des Aktionsvektors aus diesem Zustand. Wir übergeben die gewonnenen Daten an zwei Zielmodelle von Critics und das Modell v aus dem DICE-Block.
if(!CNet::feedForward(NextState, 1, false, NextSecondInput)) return false; if(!cTargetCritic1.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1) || !cTargetCritic2.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false; //--- if(!cTargetNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false;
Der nächste Schritt ist die Aufbereitung der aktuellen Zustandsdaten. Wie beim nachfolgenden Zustand verwenden wir das aktuelle konservative Akteursmodell, um die Beschreibung des aktuellen Zustands vorzuverarbeiten.
if(!CNet::feedForward(State, 1, false, SecondInput)) return false; CBufferFloat *output = ((CNeuronBaseOCL*)((CLayer*)layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite();
Hier führen wir einen kleinen Trick aus, um die Ergebnisse eines Vorwärtsdurchgangs zu ersetzen. Anstelle der erhaltenen Aktionen der aktuellen Akteurspolitik speichern wir den Aktionstensor aus dem Erfahrungswiedergabepuffer in den Ergebnispuffer der letzten neuronalen Schicht. Der Zweck dieser Operation ist es, die Übereinstimmung zwischen der Handlung und der Belohnung durch die Umwelt aufrechtzuerhalten. Wir sind uns bewusst, dass während des Vorwärtsdurchgangs höchstwahrscheinlich andere Aktionen durchgeführt wurden. Aber unsere neuronale Schicht CNeuronSoftActorCritic untersucht die Verteilung von Aktionen und deren Wahrscheinlichkeiten in den Tiefen ihrer internen Objekte. Während des Rückwärtsdurchlaufs werden Quantile und Wahrscheinlichkeiten ermittelt, die den Aktionen aus dem Erfahrungswiedergabepuffer entsprechen. In diesem Fall verläuft der unverzerrte Gradient genau an diesen Quantilen, wodurch das Actor-Modell genauer und ohne Verzerrungen trainiert werden kann.
Nach der Aufbereitung der aktuellen Umgebungsdaten können wir einen Vorwärtsdurchlauf durch die DICE-Blockmodelle durchführen. Vergessen wir nicht, die Ausführung von Vorgängen zu kontrollieren.
if(!cNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false; if(!cZeta.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false;
In Übereinstimmung mit dem SAC+DICE-Algorithmus aktualisieren wir zunächst die Modelle und Parameter des Blocks DICE. Bevor wir jedoch die Parameter aktualisieren, müssen wir die Werte der Verlustfunktionen für v, ζ, λ berechnen.
Um den Wert der Verlustfunktionen zu erhalten, benötigen wir einen Zielwert für das Verhältnis von Zustands- und Aktionswahrscheinlichkeit bei der aktuellen konservativen Politik und bei der Interaktion mit der Umwelt während der Sammlung der Beispielbasis. An dieser Stelle sei gesagt, dass die historischen Daten, die den Zustand der Umwelt beschreiben, nicht von der Politik des Akteurs abhängen. Darüber hinaus betrachten wir den aktuellen Zustand als Ausgangspunkt für eine Entscheidung und die anschließende Entwicklung eines Handlungsplans. Folglich wird die Wahrscheinlichkeit des Ausgangszustands als gleich 1 wahrgenommen, weil wir uns in diesem Zustand befinden.
Während des Trainings der Strategie ändert sich nur die Wahrscheinlichkeitsverteilung der Aktionen in Übereinstimmung mit der gelernten Strategie. Unser Zielwert ist daher das Verhältnis der Handlungswahrscheinlichkeiten der beiden Strategien. Bei den Operationen wird die Differenz der Wahrscheinlichkeitslogarithmen anstelle des Wahrscheinlichkeitsverhältnisses verwendet. In diesem Fall werden die Wahrscheinlichkeiten aller Aktionen nicht multipliziert, sondern die Summe ihrer Logarithmen verwendet und der Wert durch einen Exponenten wiederhergestellt.
vector<float> nu, next_nu, zeta, ones; cNu.getResults(nu); cTargetNu.getResults(next_nu); cZeta.getResults(zeta); ones = vector<float>::Ones(zeta.Size()); vector<float> log_prob = GetLogProbability(output); float policy_ratio = MathExp((log_prob - ActionsLogProbab).Sum()); vector<float> bellman_residuals = next_nu * discount * policy_ratio - nu + policy_ratio * reward; vector<float> zeta_loss = zeta * (MathAbs(bellman_residuals) - fLambda) * (-1) + MathPow(zeta, 2.0f) / 2; vector<float> nu_loss = zeta * MathAbs(bellman_residuals) + MathPow(nu, 2.0f) / 2.0f; float lambda_los = fLambda * (ones - zeta).Sum();
Nach der Bestimmung der Verlustfunktionswerte werden wir die Fehlergradienten definieren und die Parameter aktualisieren. Zunächst aktualisieren wir die Werte der Lagrange-Koeffizienten. Bei der Anpassung der Parameter verwenden wir den Algorithmus der Adam-Methode.
//--- update lambda float grad_lambda = (ones - zeta).Sum() * (-lambda_los); fLambda_m = b1 * fLambda_m + (1 - b1) * grad_lambda; fLambda_v = b2 * fLambda_v + (1 - b2) * MathPow(grad_lambda, 2); fLambda += lr * fLambda_m / (fLambda_v != 0.0f ? MathSqrt(fLambda_v) : 1.0f);
Als Nächstes müssen wir die Parameter der Modelle v, ζ aktualisieren. Denken Sie daran, dass wir die Werte der Verlustfunktionen definiert haben, nicht die Zielwerte. Außerdem ist die Verlustfunktion für jedes Modell individuell und unterscheidet sich stark von den bisher von uns verwendeten Modellen. Derzeit werden wir die Operationen nicht an die grundlegende Verlustfunktion unseres Modells anpassen. Stattdessen berechnen wir sofort den Fehlergradienten. Übertragen wir den resultierenden Wert in den entsprechenden Modellpuffer und propagieren wir den Fehlergradienten über die Modellparameter.
Wir aktualisieren zunächst die Parameter des Modells v.
//--- CBufferFloat temp; temp.BufferInit(MathMax(Actions.Total(), SecondInput.Total()), 0); temp.BufferCreate(opencl); //--- update nu int last_layer = cNu.layers.Total() - 1; CLayer *layer = cNu.layers.At(last_layer); if(!layer) return false; CNeuronBaseOCL *neuron = layer.At(0); if(!neuron) return false; CBufferFloat *buffer = neuron.getGradient(); if(!buffer) return false; vector<float> nu_grad = nu_loss * (zeta * bellman_residuals / MathAbs(bellman_residuals) + nu); if(!buffer.AssignArray(nu_grad) || !buffer.BufferWrite()) return false; if(!cNu.backPropGradient(output, GetPointer(temp))) return false;
Dann führen wir ähnliche Operationen für das Modell ζ durch.
//--- update zeta last_layer = cZeta.layers.Total() - 1; layer = cZeta.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; vector<float> zeta_grad = zeta_loss * (zeta - MathAbs(bellman_residuals) + fLambda) * (-1); if(!buffer.AssignArray(zeta_grad) || !buffer.BufferWrite()) return false; if(!cZeta.backPropGradient(output, GetPointer(temp))) return false;
An diesem Punkt haben wir die Parameter des DICE-Blocks aktualisiert und gehen direkt zum Verfahren des Reinforcement Learning (Verstärkungslernen) über. Wir führen zunächst einen direkten Durchgang bei beiden Kritiker durch. In diesem Fall führen wir keinen direkten Durchgang des Akteurs durch, da wir diesen Vorgang bereits bei der Aktualisierung der Parameter der DICE-Objekte des Blocks durchgeführt haben.
//--- feed forward critics if(!cCritic1.feedForward(GetPointer(this), iLatentLayer, output) || !cCritic2.feedForward(GetPointer(this), iLatentLayer, output)) return false;
Als Nächstes werden wir, wie bei der Aktualisierung der DICE-Parameter, die Werte der Verlustfunktionen bestimmen. Doch zunächst müssen wir ein wenig Vorarbeit leisten. Um die Stabilität des Modelltrainings zu erhöhen, normalisieren wir den Verteilungskorrekturkoeffizienten und berechnen den Referenzwert, der von den kritischen Zielmodellen unter Berücksichtigung der aktuellen Politik des Akteurs vorhergesagt wird.
vector<float> result; if(fZeta == 0) fZeta = MathAbs(zeta[0]); else fZeta = 0.9f * fZeta + 0.1f * MathAbs(zeta[0]); zeta[0] = MathPow(MathAbs(zeta[0]), 1.0f / 3.0f) / (10.0f * MathPow(fZeta, 1.0f / 3.0f)); cTargetCritic1.getResults(result); float target = result[0]; cTargetCritic2.getResults(result); target = reward + discount * (MathMin(result[0], target) - LogProbMultiplier * log_prob.Sum());
Trotz des Vorhandenseins eines Zielwerts können wir die grundlegende Methode des Rückgriffs auf die Modelle der Kritiker nicht anwenden, da die Verwendung eines Verteilungskorrekturkoeffizienten nicht in diese Methode passt. Daher verwenden wir die oben entwickelte Technik mit der Berechnung des Fehlergradienten und seiner direkten Übertragung in den Puffer der neuronalen Schicht der Ergebnisse, gefolgt von der Verteilung der Gradienten über das Modell.
//--- update critic1 cCritic1.getResults(result); float loss = zeta[0] * MathPow(result[0] - target, 2.0f); if(fLoss1 == 0) fLoss1 = MathSqrt(loss); else fLoss1 = MathSqrt(0.999f * MathPow(fLoss1, 2.0f) + 0.001f * loss); float grad = loss * 2 * zeta[0] * (target - result[0]); last_layer = cCritic1.layers.Total() - 1; layer = cCritic1.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.Update(0, grad) || !buffer.BufferWrite()) return false; if(!cCritic1.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
Gleichzeitig berechnen wir den durchschnittlichen Fehler des Modells, den wir dem Nutzer zur visuellen Kontrolle des Modelltrainings anzeigen werden.
Wiederholen wir die Vorgänge für den zweiten Kritiker.
//--- update critic2 cCritic2.getResults(result); loss = zeta[0] * MathPow(result[0] - target, 2.0f); if(fLoss2 == 0) fLoss2 = MathSqrt(loss); else fLoss2 = MathSqrt(0.999f * MathPow(fLoss1, 2.0f) + 0.001f * loss); grad = loss * 2 * zeta[0] * (target - result[0]); last_layer = cCritic2.layers.Total() - 1; layer = cCritic2.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.Update(0, grad) || !buffer.BufferWrite()) return false; if(!cCritic2.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
Nach der Aktualisierung der Parameter für die Kritiker gehen wir zur Aktualisierung der Politik für die Akteure über. Wir werden zuerst die Politik des konservativen Akteurs aktualisieren. Hier berechnen wir den Zielwert unter Berücksichtigung der unteren Schranke der Q-Funktionswerte und der aktuellen Wahrscheinlichkeitsverteilung der Aktionen. Wir korrigieren den resultierenden Wert um den Verteilungskorrekturkoeffizienten und zeichnen den Fehlergradienten durch das Modell des Kritikers. Als Erstes werden wir den Trainingsmodus des Kritikers deaktivieren.
//--- update policy cCritic1.getResults(result); float mean = result[0]; float var = result[0]; cCritic2.getResults(result); mean += result[0]; var -= result[0]; mean /= 2.0f; var = MathAbs(var) / 2.0f; target = zeta[0] * (mean - 2.5f * var + discount * log_prob.Sum() * LogProbMultiplier) + result[0]; CBufferFloat bTarget; bTarget.Add(target); cCritic2.TrainMode(false); if(!cCritic2.backProp(GetPointer(bTarget), GetPointer(this)) || !backPropGradient(SecondInput, GetPointer(temp))) { cCritic2.TrainMode(true); return false; }
Bevor wir die Parameter der optimistischen Forschungspolitik des Akteurs aktualisieren, führen wir einen Vorwärtsdurchlauf durch das angegebene Modell durch und ersetzen die Werte des Ergebnispuffers (wie wir es zuvor für das pessimistische Modell getan haben).
Dann berechnen wir den Zielwert unter Berücksichtigung des Optimismuskoeffizienten neu und verteilen den Fehlergradienten durch das kritische Modell.
//--- update exploration policy if(!cActorExploer.feedForward(State, 1, false, SecondInput)) { cCritic2.TrainMode(true); return false; } output = ((CNeuronBaseOCL*)((CLayer*)cActorExploer.layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite(); cActorExploer.GetLogProbs(log_prob); target = zeta[0] * (mean + 2.0f * var + discount * log_prob.Sum() * LogProbMultiplier) + result[0]; bTarget.Update(0, target); if(!cCritic2.backProp(GetPointer(bTarget), GetPointer(cActorExploer)) || !cActorExploer.backPropGradient(SecondInput, GetPointer(temp))) { cCritic2.TrainMode(true); return false; } cCritic2.TrainMode(true);
Nach Abschluss der Operationen schalten wir den Trainingsmodus des Kritikers ein und aktualisieren die Parameter der Zielmodelle.
if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), tau) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), tau) || !cTargetNu.WeightsUpdate(GetPointer(cNu), tau)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; } //--- return true; }
Wir haben die Arbeit an der Modellbildungsmethode abgeschlossen. Nun ist es an der Zeit, die Methoden für die Arbeit mit Dateien zu entwickeln. Zunächst erstellen wir eine Methode zum Speichern der Modelle. Im Gegensatz zu den zuvor besprochenen ähnlichen Methoden werden wir nicht alle Daten in einer Datei speichern. Im Gegensatz dazu erhält jedes trainierte Modell eine eigene Datei. So können wir jedes einzelne Modell unabhängig von den anderen verwenden.
In den Parametern erhält die Datensicherungsmethode CNet_SAC_DICE::Save den gemeinsamen Dateinamen (ohne Erweiterung) und das Speicherflag im gemeinsamen Terminalordner. Im Hauptteil der Methode wird sofort geprüft, ob der Dateiname in der resultierenden Textvariable vorhanden ist.
bool CNet_SAC_DICE::Save(string file_name, bool common = true) { if(file_name == NULL) return false;
Anschließend wird eine Datei mit dem angegebenen Namen und der Erweiterung ".set" erstellt. Darin werden die Werte der internen Variablen gespeichert.
int handle = FileOpen(file_name + ".set", (common ? FILE_COMMON : 0) | FILE_BIN | FILE_WRITE); if(handle == INVALID_HANDLE) return false; if(FileWriteFloat(handle, fLambda) < sizeof(fLambda) || FileWriteFloat(handle, fLambda_m) < sizeof(fLambda_m) || FileWriteFloat(handle, fLambda_v) < sizeof(fLambda_v) || FileWriteInteger(handle, iLatentLayer) < sizeof(iLatentLayer)) return false; FileFlush(handle); FileClose(handle);
Danach rufen wir die Methoden zum Speichern von Modellen nacheinander auf und steuern den Prozess der Durchführung von Operationen. Hier lohnt es sich, auf die angegebenen Dateinamen zu achten. Ein Akteur mit einer konservativen Richtlinie erhält das Dateinamenssuffix „Act.nnw“ (wie wir es zuvor für Akteure festgelegt haben). Das optimistische Akteursmodell erhält eine Datei mit der Endung ActExp.nnw. Darüber hinaus speichern wir nur die Zielmodelle von Critics und v-Modellen. Die entsprechenden trainierten Modelle werden nicht gespeichert.
if(!CNet::Save(file_name + "Act.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- if(!cActorExploer.Save(file_name + "ActExp.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- if(!cTargetCritic1.Save(file_name + "Crt1.nnw", fLoss1, 0, 0, TimeCurrent(), common)) return false; //--- if(!cTargetCritic2.Save(file_name + "Crt2.nnw", fLoss2, 0, 0, TimeCurrent(), common)) return false; //--- if(!cZeta.Save(file_name + "Zeta.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- if(!cTargetNu.Save(file_name + "Nu.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- return true; }
Bei der Methode des Datenladens wiederholen wir die Vorgänge streng in der Reihenfolge, in der die Daten eingestellt wurden. In diesem Fall werden das trainierte Modell und das Zielmodell aus denselben entsprechenden Dateien geladen.
bool CNet_SAC_DICE::Load(string file_name, bool common = true) { if(file_name == NULL) return false; //--- int handle = FileOpen(file_name + ".set", (common ? FILE_COMMON : 0) | FILE_BIN | FILE_READ); if(handle == INVALID_HANDLE) return false; if(FileIsEnding(handle)) return false; fLambda = FileReadFloat(handle); if(FileIsEnding(handle)) return false; fLambda_m = FileReadFloat(handle); if(FileIsEnding(handle)) return false; fLambda_v = FileReadFloat(handle); if(FileIsEnding(handle)) return false; iLatentLayer = FileReadInteger(handle);; FileClose(handle); //--- float temp; datetime dt; if(!CNet::Load(file_name + "Act.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cActorExploer.Load(file_name + "ActExp.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cCritic1.Load(file_name + "Crt1.nnw", fLoss1, temp, temp, dt, common) || !cTargetCritic1.Load(file_name + "Crt1.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cCritic2.Load(file_name + "Crt2.nnw", fLoss2, temp, temp, dt, common) || !cTargetCritic2.Load(file_name + "Crt2.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cZeta.Load(file_name + "Zeta.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cNu.Load(file_name + "Nu.nnw", temp, temp, temp, dt, common) || !cTargetNu.Load(file_name + "Nu.nnw", temp, temp, temp, dt, common)) return false;
Nach dem Laden dieser Modelle übertragen wir sie in einen einzigen OpenCL-Kontext.
cActorExploer.SetOpenCL(opencl); cCritic1.SetOpenCL(opencl); cCritic2.SetOpenCL(opencl); cZeta.SetOpenCL(opencl); cNu.SetOpenCL(opencl); cTargetCritic1.SetOpenCL(opencl); cTargetCritic2.SetOpenCL(opencl); cTargetNu.SetOpenCL(opencl); //--- return true; }
Damit ist unsere Arbeit an der Klasse CNet_SAC_DICE abgeschlossen. Einen vollständigen Code aller Methoden finden Sie im Anhang. Wie Sie sich vielleicht erinnern, geben die Parameter der oben beschriebenen Trainingsmethode einen Vektor von Logarithmen der Handlungswahrscheinlichkeiten an. Aber wir haben solche Daten bisher noch nicht im Wiedergabepuffer für Erfahrungen gespeichert. Daher müssen wir nun das entsprechende Array zur Zustands-Aktions-Beschreibungsstruktur SState in der Datei „..\SAC&DICE\Trajectory.mqh“ hinzufügen. Die Größe des Arrays ist gleich der Anzahl der Aktionen.
struct SState { float state[HistoryBars * BarDescr]; float account[AccountDescr - 4]; float action[NActions]; float log_prob[NActions]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(log_prob, obj.log_prob); } };
Vergessen wir nicht, das Array in den Algorithmus der Methoden zum Kopieren von Strukturen und Arbeiten mit Dateien aufzunehmen. Der vollständige Strukturcode ist in der Anlage zu finden.
Kommen wir nun zum Erstellen und Trainieren von Modellen. Die Modellarchitektur wurde unverändert aus dem Artikel übernommen, der die Methode Soft Actor-Critic beschreibt. Gleichzeitig haben wir keine getrennten Architekturen für die Modelle v und ζ erstellt. Wir haben die Architektur des Kritikers für sie verwendet.
Beim Training des Modells verwenden wir wie zuvor drei EAs:
- Research — Sammeln von Beispielen Datenbank
- Study — Modelltraining
- Test — Überprüfung der erzielten Ergebnisse.
Beim Sammeln von Daten für die Beispieldatenbank in der Research EA verwenden wir die optimistische Actor-Policy (die Datei mit dem Suffix „ActExp.nnw“). Um das trainierte Modell zu testen, verwenden wir jedoch ein konservatives Modell (die Datei mit dem Suffix „Act.nnw“). Dies sollte beim Laden von Modellen in die entsprechenden Dateien beachtet werden. Vergessen wir außerdem nicht, beim Sammeln von Daten im Erfahrungswiedergabepuffer den Logarithmus der Verteilungswahrscheinlichkeiten der Aktionen zu addieren. Der vollständige Code der EAs ist im Anhang zu finden.
Der Trainings-EA Study hat maximale Änderungen erfahren. Dies ist nicht überraschend. Wir haben einen großen Teil seiner Funktionsweisen in die Trainingsmethode Study der Klasse CNet_SAC_DICE übertragen.
Wir beginnen mit der Änderung der Bibliothek, die unser Modell enthält.
#include "Net_SAC_DICE.mqh"
Im Block der globalen Variablen deklarieren wir nur ein Modell der neu erstellten Klasse CNet_SAC_DICE. Gleichzeitig erhöhen wir die Anzahl der Datenpuffer. Dies ist darauf zurückzuführen, dass wir bisher einen Puffer für zwei Zustände in verschiedenen Phasen der Ausbildung verwenden konnten. Nun müssen wir dem Modell gleichzeitig Informationen über zwei nachfolgende Zustände übermitteln.
STrajectory Buffer[]; CNet_SAC_DICE Net; //--- float dError; datetime dtStudied; //--- CBufferFloat bState; CBufferFloat bAccount; CBufferFloat bActions; CBufferFloat bNextState; CBufferFloat bNextAccount;
Wie zuvor laden wir bei der EA-Initialisierungsmethode zunächst den Erfahrungswiedergabepuffer für die Trainingsmodelle.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Danach laden wir ein einzelnes Modell. Wenn das Modell noch nicht erstellt wurde, bilden wir Arrays von Beschreibungen der Modellarchitektur und erstellen nur ein Modell, indem wir alle Architekturbeschreibungen an dieses übergeben. Wir prüfen das Ergebnis der Operation nur einmal.
Wie oben erwähnt, beschreiben wir die Architektur des Kritikers für DICE-Blockmodelle. Es sind aber auch andere Optionen möglich. Achten Sie bei der Erstellung Ihrer eigenen Modelle für diesen Block auf die Verwendung des Actor-Modells als Block für die primäre Verarbeitung von Quelldaten. Genau auf diese Weise haben wir den gesamten Algorithmus für die Modellschulung aufgebaut. Wir müssen sie entweder bei der Erstellung von Modellarchitekturen beachten oder den Methodenalgorithmus entsprechend ändern.
//--- load models if(!Net.Load(FileName, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Net.Create(actor, critic, critic, critic, LatentLayer)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Wenn ich sage „nur ein einziges Modell“, ist das vielleicht nicht ganz richtig. Während des Trainingsprozesses erstellen wir 6 aktualisierte Modelle und 3 Zielmodelle. Alle Modelle werden innerhalb unserer neuen Klasse erstellt und sind für den Nutzer unsichtbar. Auf der obersten Ebene arbeiten wir nur mit einer Klasse.
Am Ende der EA-Initialisierungsmethode erzeugen wir ein Modelltrainingsereignis.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Nach erfolgreichem Abschluss aller Operationen schließen wir das EA-Initialisierungsverfahren ab.
Der nächste Schritt ist die Ausarbeitung eines Verfahrens für das direkte Training der Modelle Train.
Wie zuvor ordnen wir im Körper dieser Funktion einen Trainingszyklus entsprechend der in den externen Parametern von EA angegebenen Anzahl von Iterationen an.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i<0) { iter--; continue; }
Innerhalb der Schleife werden die Trajektorie und der individuelle Schritt für die aktuelle Iteration des Modelltrainings abgetastet.
Als Nächstes werden wir die vorbereitenden Arbeiten durchführen und die erforderlichen Daten in den zuvor angegebenen Datenpuffern sammeln. Zunächst werden die historischen Daten, die den späteren Zustand der Umwelt beschreiben, zwischengespeichert.
//--- Target bNextState.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; if(PrevBalance==0) { iter--; continue; } bNextAccount.Clear(); bNextAccount.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); bNextAccount.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); bNextAccount.Add(Buffer[tr].States[i + 1].account[2]); bNextAccount.Add(Buffer[tr].States[i + 1].account[3]); bNextAccount.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); bNextAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
In einem weiteren Puffer werden wir eine Beschreibung des Kontostatus erstellen und Zeitstempel hinzufügen.
In ähnlicher Weise werden wir Puffer vorbereiten, die den analysierten Zustand der Umgebung beschreiben.
bState.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Dann werden wir die abgeschlossenen Aktionen in den Puffer verschieben. Der Wahrscheinlichkeitslogarithmus wird in den Vektor geladen.
bActions.AssignArray(Buffer[tr].States[i].action); vector<float> log_prob; log_prob.Assign(Buffer[tr].States[i].log_prob);
In dieser Phase schließen wir die vorbereitenden Arbeiten ab. Alle Daten, die für eine Trainingsiteration erforderlich sind, wurden bereits in den Datenpuffern gesammelt. Wir rufen die CNet_SAC_DICE::Study Trainingsmethode unseres Modells auf und übergeben die notwendigen Daten in den Parametern.
if(!Net.Study(GetPointer(bState), GetPointer(bAccount), GetPointer(bActions), log_prob, GetPointer(bNextState), GetPointer(bNextAccount), Buffer[tr].Revards[i] - DiscFactor * Buffer[tr].Revards[i + 1], DiscFactor, Tau)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Bitte beachten Sie, dass wir die Belohnungen im Erfahrungswiederholungspuffer als kumulierte Summe gespeichert haben. Nun übertragen wir die Nettobelohnung für einen einzelnen Schritt auf die Modellbildungsmethode. Fehlende Daten werden durch Zielmodelle vorhergesagt.
Wir haben alle Modelltrainingsoperationen in die Trainingsmethode unserer Klasse implementiert. Jetzt müssen wir nur noch das Ergebnis der Methodenoperationen überprüfen. Dann informieren wir den Nutzer über den Prozess der Modellbildung.
if(GetTickCount() - ticks > 500) { float loss1, loss2; Net.GetLoss(loss1, loss2); string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), loss1); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), loss2); Comment(str); ticks = GetTickCount(); } }
Nach Abschluss der Schleifeniterationen löschen wir das Kommentarfeld und leiten den EA-Abschaltprozess ein.
Comment(""); //--- float loss1, loss2; Net.GetLoss(loss1, loss2); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", loss1); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", loss2); ExpertRemove(); //--- }
Wie wir sehen, können wir durch die Unterbringung der Modelltrainingsoperationen in einer separaten Klassenmethode die Code- und Arbeitskosten auf der Seite des Hauptprogramms erheblich reduzieren. Gleichzeitig verringert dieser Ansatz die Flexibilität des Modelltrainings und die Möglichkeiten des Nutzers, es anzupassen. Beide Ansätze haben ihre positiven und negativen Seiten. Die Wahl eines bestimmten Ansatzes hängt von der jeweiligen Aufgabe und den persönlichen Vorlieben ab.
Der vollständige Code des EA und aller im Artikel verwendeten Programme ist im Anhang verfügbar.
4. Test
Das Modell wurde mit historischen Daten von EURUSD H1 im Zeitraum Januar - Mai 2023 trainiert. Die Indikatorparameter und alle Hyperparameter wurden auf ihre Standardwerte gesetzt. Während des Trainingsprozesses wurde ein Modell erstellt, das in der Lage war, auf der Trainingsmenge Gewinne zu erzielen.


Während des 5-monatigen Trainingszeitraums konnte das Modell 15 % des Gewinns erwirtschaften. Es wurden 314 Positionen eröffnet, von denen 45,8 % mit Gewinn geschlossen wurden. Der maximale Gewinn des Handels übersteigen den maximalen Verlust fast um das Doppelte. Außerdem ist der durchschnittliche Gewinn um 1/3 höher als der durchschnittliche Verlust. Dieses Verhältnis von Gewinnen und Verlusten ermöglichte es uns, einen Gewinnfaktor von 1,13 zu erhalten.
Wie üblich sind wir viel mehr an der Effizienz des Modells bei neuen Daten interessiert. Die Verallgemeinerungsfähigkeit und Leistung des Modells bei unbekannten Daten wurde im Strategietester an historischen Daten für Juni 2023 getestet. Wie man sieht, schließt sich die Testphase unmittelbar an die Trainingsgruppe an. Dies gewährleistet eine maximale Homogenität der Trainings- und Testproben. Die Testergebnisse werden im Folgenden vorgestellt.

Das dargestellte Saldenkurve zeigt einen Drawdown in den ersten zehn Tagen des Monats. Doch dann folgt eine Phase mit Gewinnen, die bis zum Ende des Monats anhält. Infolgedessen erzielte der EA im Laufe des Monats einen Gewinn von 7,7 % bei einem maximalen Drawdown des Kapitals von 5,46 %. Beim Saldo war der Drawdown sogar noch geringer und lag nicht über 4,87 %.

Die Tabelle der Testergebnisse zeigt, dass der EA während des Tests in beide Richtungen gehandelt hat. Es wurden insgesamt 48 Positionen gehandelt. 54,17 % davon wurden mit einem Gewinn beendet Der größte Gewinn aller Handelsgeschäfte ist mehr als dreimal so hoch wie der größte Verlust. Und das durchschnittliche Gewinn der gehandelten Positionen übersteigt den durchschnittlichen Verlust um die Hälfte. Quantitativ gesehen kommen im Durchschnitt auf 3 gewinnbringende Handelsgeschäfte 2 mit Verlust. Daraus ergibt sich ein Gewinnfaktor von 1,74 und ein Erholungsfaktor von 1,41.
Schlussfolgerung
Der Artikel bespricht einen weiteren Algorithmus aus der Familie von Actor-Critic, den SAC+DICE-Algorithmus, der auf zwei Hauptrichtungen der Modifikation des Soft-Actor-Critic-Algorithmus beruht. Die Anwendung eines optimistischen Modells der Umweltforschung ermöglicht es uns, den Bereich der Umweltforschung zu erweitern. Die Forschung wird mit dem Ziel durchgeführt, die Rentabilität der allgemeinen Politik zu erhöhen. Dies führt natürlich zu einem Bruch in der Verteilung der Politik der Umgebungserforschung und der konservativen Lernpolitik. Um eine unverzerrte Schätzung der Gradienten zu erhalten, haben wir einen modifizierten DICE-Ansatz verwendet und einen trainierbaren Verteilungskorrekturkoeffizienten eingeführt. All dies ermöglicht es, die Effizienz des Modelltrainings zu erhöhen, was im praktischen Teil unseres Artikels bestätigt wurde.
Wir haben den vorgeschlagenen Algorithmus mit MQL5 implementiert. Während dieser Implementierung wurde ein Ansatz demonstriert, der den Modellbildungsprozess in eine separate Klassenmethode verlagert. Dies ermöglicht es uns, die Arbeit auf der Seite des Hauptprogramms erheblich zu reduzieren und die Nutzung zu vereinfachen.
Wir trainierten und testeten das trainierte Modell mit neuen Daten. Die Testergebnisse belegen die Effizienz unserer Implementierung. Das trainierte Modell war in der Lage, die gewonnenen Erfahrungen auf neue Daten zu übertragen. Während des Tests erzielte der EA einen Gewinn.
Alle vorgestellten Programme zeigen jedoch nur die Möglichkeit der Nutzung dieser Technologie. Sie sind nicht für den Einsatz auf realen Finanzmärkten geeignet. Die EAs müssen verfeinert und zusätzlich getestet werden, bevor sie auf einem realen Markt eingeführt werden.
Links
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Trainings-EA des Agenten |
| 3 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | Netz_SAC_DICE.mqh | Klassenbibliothek | Modellklasse |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13055
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.