
Neural networks made easy (Part 68): Offline Preference-guided Policy Optimization

Einführung
Das Verstärkungslernen ist eine universelle Plattform für das Erlernen optimaler Verhaltensweisen in einer zu erforschenden Umgebung. Optimale Politik wird durch die Maximierung der Belohnungen erreicht, die von der Umwelt während der Interaktion mit ihr erhalten werden. Hier liegt jedoch eines der Hauptprobleme dieses Ansatzes. Die Schaffung einer angemessenen Belohnungsfunktion erfordert oft erheblichen menschlichen Einsatz. Außerdem können die Belohnungen spärlich und/oder unzureichend sein, um das eigentliche Lernziel auszudrücken. Als eine der Möglichkeiten zur Lösung dieses Problems schlugen die Autoren des Artikels „Beyond Reward: Offline Preference-guided Policy Optimization“ die OPPO-Methode vor (OPPO steht für die Offline Preference-guided Policy Optimization). Die Autoren der Methode empfehlen, die von der Umgebung gegebene Belohnung durch die Präferenzen des verantwortlichen Menschen zwischen zwei in der zu erforschenden Umgebung absolvierten Trajektorien zu ersetzen. Schauen wir uns den vorgeschlagenen Algorithmus genauer an.
1. Der OPPO-Algorithmus
Im Kontext des offline-präferenzgeleiteten Lernens besteht der allgemeine Ansatz aus zwei Schritten und beinhaltet typischerweise die Optimierung des Belohnungsfunktionsmodells mit Hilfe von überwachtem Lernen und das anschließende Training der Politik mit einem beliebigen offline-RL-Algorithmus auf Transitionen, die mit Hilfe der gelernten Belohnungsfunktion neu definiert wurden. Allerdings kann die Praxis des separaten Trainings der Belohnungsfunktion die Politik nicht direkt anweisen, wie sie sich optimal verhalten soll. Die Präferenzmarkierungen definieren die Lernaufgabe, und daher ist das Ziel, die bevorzugte Trajektorie zu lernen und nicht die Belohnung zu maximieren. Bei komplexen Problemen können skalare Belohnungen zu einem Informationsengpass bei der Optimierung von Strategien führen, was wiederum ein suboptimales Verhalten des Agenten zur Folge hat. Außerdem können bei der Offline-Richtlinienoptimierung Schwachstellen in falschen Belohnungsfunktionen ausgenutzt werden. Dies wiederum führt zu unerwünschtem Verhalten.
Als Alternative zu diesem zweistufigen Ansatz zielen die Autoren der Methode Offline Preference-guided Policy Optimization (OPPO) darauf ab, die Politik direkt aus einem Offline-Präferenz-geleiteten Datensatz zu lernen. Sie schlagen einen einstufigen Algorithmus vor, der gleichzeitig Offline-Präferenzen modelliert und die optimale Entscheidungspolitik erlernt, ohne dass die Belohnungsfunktion separat trainiert werden muss. Dies wird durch den Einsatz von zwei Zielen erreicht:
- Sammeln von Informationen „in Abwesenheit“ von offline;
- Präferenzmodellierung.
Durch die iterative Optimierung dieser Ziele kommen wir zur Konstruktion einer kontextuellen Politik π(A|S,Z), um Offline-Daten und den optimalen Kontext der Präferenzen Z' zu modellieren. OPPO konzentriert sich auf die Erforschung des hochdimensionalen Raums Z und die Bewertung der Politik in einem solchen Raum. Dieser hochdimensionale Z-Raum erfasst im Vergleich zu einem skalaren Payoff mehr Informationen über die jeweilige Aufgabe und eignet sich daher ideal für die Optimierung von Strategien. Darüber hinaus wird die optimale Strategie durch eine bedingte Modellierung der kontextbezogenen Strategie π(A|S,Z) auf dem erlernten optimalen Kontext Z' ermittelt.
Die Autoren des Algorithmus stellen die Annahme auf, dass es möglich ist, die Präferenzfunktion durch das Modell Iθ zu approximieren, was uns erlaubt, das folgende Ziel zu formulieren:
![]()
wobei Z=Iθ(τ) der Kontext der Präferenzen ist. Diese Encoder-Decoder-Struktur wird dem Offline-Simulationslernen ähneln. Da es im Rahmen des präferenzbasierten Lernens jedoch keine Expertendemonstrationen gibt, verwenden die Autoren des Algorithmus Präferenzkennzeichnungen, um retrospektive Informationen zu gewinnen.
Um Konsistenz mit den historischen Informationen Iθ(τ) und den Präferenzen in einem gelabelten Datensatz zu erreichen, formulieren die Autoren der Methode das folgende Ziel der Präferenzmodellierung:
![]()
wobei z+ und z- den Kontext der bevorzugten (positiven) Trajektorie Iθ(yτj + (1-y)τi) bzw. der weniger bevorzugten (negativen) Trajektorie Iθ(yτi + (1-y)τj) darstellen. Diesem Ziel liegt die Annahme zugrunde, dass Menschen typischerweise zweistufige Vergleiche anstellen, bevor sie ihre Präferenzen zwischen zwei Trajektorien (τi, τj):
- Getrennter Vergleich der Ähnlichkeit zwischen der Trajektorie τi und einer hypothetischen optimalen Trajektorie τ*, d.h. l(z*,z+) und der Ähnlichkeit zwischen der Trajektorie τj und einer hypothetischen optimalen Trajektorie τ* d. h. l(z*,z-),
- Schätzung der Differenzen zwischen diesen beiden Ähnlichkeiten l(z*,z+) und l (z*,z-), wobei die Trajektorie als diejenige festgelegt wird, die der bevorzugten näher kommt.
Die Zieloptimierung sorgt also dafür, dass ein optimaler Kontext gefunden wird, der z+ mehr und z- weniger ähnlich ist.
Es sollte klargestellt werden, dass z* der relevante Kontext für die Trajektorie τ* ist, während die Trajektorie τ* immer gegenüber allen Offline-Trajektorien im Datensatz bevorzugt wird.
Man beachte, dass die Posteriorwahrscheinlichkeit des optimalen Kontexts z* und die Extraktion der retrospektiven Präferenzinformation Iθ(•) nacheinander aktualisiert werden, um die Stabilität des Trainings zu gewährleisten. Eine bessere Schätzung der optimalen Einbettung hilft dem Kodierer, Merkmale zu extrahieren, denen eine Person bei der Bestimmung ihrer Präferenzen mehr Aufmerksamkeit schenkt. Ein besserer, retrospektiver Informationskodierer wiederum beschleunigt den Prozess der Suche nach der optimalen Trajektorie im übergeordneten Einbettungsraum. Die Verlustfunktion für den Encoder besteht also aus zwei Teilen:
- Fehler beim Vergleich von Informationen aus Retrospektiven im überwachten Trainingsstil.
- Fehler, um die binäre Beobachtung, die der markierte Präferenzdatensatz liefert, besser zu berücksichtigen.
Im Folgenden wird die Visualisierung des OPPO-Algorithmus durch die Autoren vorgestellt.
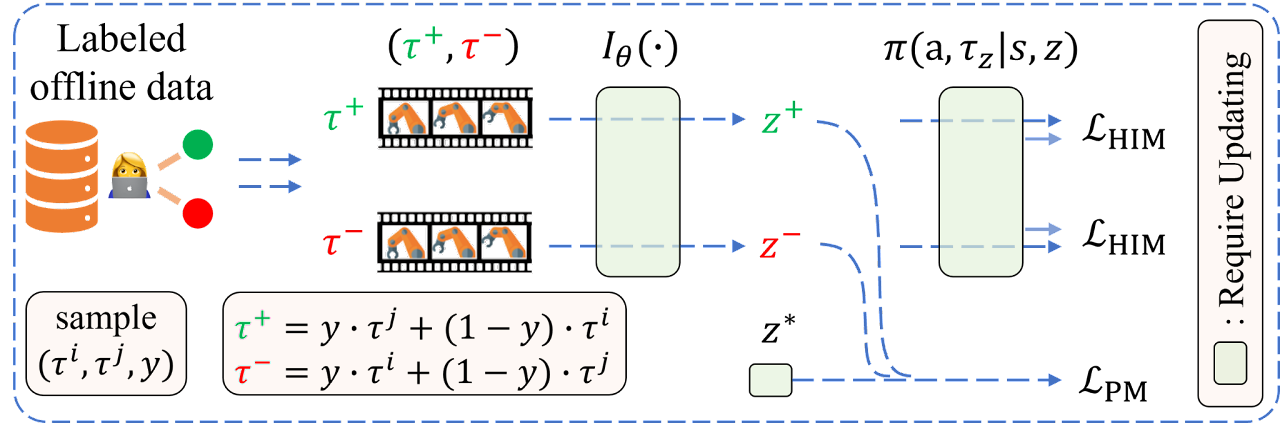
2. Implementierung mit MQL5
Wir haben uns mit den theoretischen Aspekten der Algorithmen befasst und kommen nun zum praktischen Teil, in dem wir uns mit der Umsetzung des vorgeschlagenen Algorithmus befassen werden. Wir beginnen mit der Datenspeicherstruktur SState. Wie bereits erwähnt, ersetzen die Autoren der Methode die traditionell verwendete Belohnung durch ein Präferenzlabel für die Trajektorie. Daher brauchen wir die Belohnungen nicht bei jedem Übergang zu einem neuen Zustand der Umgebung zu speichern. Gleichzeitig führen wir das Konzept des bevorzugten Trajektorie-Kontextes ein. Gemäß der vorgeschlagenen Logik in der Struktur der Umgebungszustandsbeschreibung ersetzen wir das Belohnungsfeld mit zerlegten Belohnungen durch das Kontextfeld des Scheduler.
struct SState { float state[BarDescr * NBarInPattern]; float account[AccountDescr]; float action[NActions]; float scheduler[EmbeddingSize]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- void Clear(void) { ArrayInitialize(state, 0); ArrayInitialize(account, 0); ArrayInitialize(action, 0); ArrayInitialize(scheduler, 0); } //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(scheduler, obj.scheduler); } };
Bitte beachten Sie, dass wir nicht nur den Namen, sondern auch die Größe des Arrays geändert haben.
Zusätzlich zum verborgenen Kontext führt der Algorithmus auch das Konzept der Trajektorie-Präferenz ein. Hier gibt es mehrere Aspekte zu beachten:
- Die Prioritäten werden für den gesamten Verlauf und nicht für einzelne Maßnahmen und Übergänge gesetzt (die Politik wird bewertet).
- Die Prioritäten werden paarweise zwischen allen Trajektorien im Offline-Datensatz im Bereich [0: 1].
- Die Prioritäten werden von einem Experten festgelegt.
Bitte beachten Sie, dass wir nicht allen Trajektorien aus dem Erfahrungswiedergabepuffer manuell Prioritäten zuweisen werden. Wir werden auch keine Schachtabelle mit Prioritäten erstellen.
Es gibt eine ganze Reihe von Prioritätskriterien, die ausgewählt werden können. Aber im Rahmen dieses Artikels habe ich nur eine verwendet, nämlich den Gewinn aus dem Passieren der Trajektorie. Ich stimme zu, dass wir die maximale Inanspruchnahme sowohl in Bezug auf den Saldo als auch auf das Eigenkapital zu den Kriterien hinzufügen könnten. Wir könnten auch den Gewinnfaktor und andere Kriterien hinzufügen. Ich schlage jedoch vor, dass Sie selbständig die für Sie optimalen Kriterien und deren Wertkoeffizienten auswählen. Die von Ihnen gewählten Kriterien wirken sich zwar auf das Endergebnis der Richtlinienschulung aus, nicht aber auf den Algorithmus der vorgeschlagenen Implementierung.
Und da die Priorität für die gesamte Trajektorie festgelegt wird, brauchen wir nur den Betrag des Gewinns zu speichern, den wir am Ende der Trajektorie erhalten. Wir speichern sie in der Trajektorie-Beschreibungsstruktur STrajectory.
struct STrajectory { SState States[Buffer_Size]; int Total; double Profit; //--- STrajectory(void); //--- bool Add(SState &state); void ClearFirstN(const int n); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const STrajectory &obj) { Total = obj.Total; Profit = obj.Profit; for(int i = 0; i < Buffer_Size; i++) States[i] = obj.States[i]; } };
Wenn wir die Felder von Strukturen ändern, müssen wir natürlich auch die Methoden zum Kopieren und Arbeiten mit Dateien der angegebenen Strukturen ändern. Aber diese Anpassungen sind so spezifisch, dass ich Ihnen empfehle, sich mit ihnen in den beigefügten Dateien vertraut zu machen.
2.1 Modellarchitektur
Wir werden 2 Modelle verwenden, um die Politik zu trainieren. Der Scheduler lernt Präferenzen, und der Agent lernt Verhaltensregeln. Beide Modelle beruhen auf dem Prinzip des Decision Transformer (DT) und nutzen Aufmerksamkeitsmechanismen. Im Gegensatz zur Lösung der Autoren, die Modelle einzeln zu aktualisieren, werden wir jedoch 2 Expert Advisors für das Training der Modelle erstellen. Jeder von ihnen wird nur an der Ausbildung eines Modells teilnehmen. In der Phase der Erprobung und des Betriebs des Modells werden wir sie zu einem einzigen Mechanismus zusammenfassen. Um die Architektur der Modelle zu beschreiben, werden wir daher auch 2 Methoden erstellen:
- CreateSchedulerDescriptions - zur Beschreibung der Scheduler-Architektur
- CreateAgentDescriptions - zur Beschreibung der Agentenarchitektur
Wir geben in den Scheduler folgendes ein:
- die historischen Kursbewegungen und Indikatordaten
- die Beschreibungen des Kontostands und der offenen Positionen
- einen Zeitstempel
- die letzte Aktion des Agenten
bool CreateSchedulerDescriptions(CArrayObj *scheduler) { //--- CLayerDescription *descr; //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Wie wir in früheren Artikeln gesehen haben, macht sich der Decision Transformer die GPT-Architektur zunutze und speichert Einbettungen von zuvor empfangenen Daten in seinem verborgenen Zustand, was es Ihnen ermöglicht, während der gesamten Episode Entscheidungen in einem einzigen Kontext zu treffen. Daher geben wir dem Modell nur eine kurze Beschreibung des aktuellen Stands, wobei wir uns auf die jüngsten Änderungen konzentrieren. Mit anderen Worten, wir geben nur Daten über die letzte geschlossene Kerze in das Modell ein.
Die empfangenen Daten werden in der Normalisierungsschicht vorverarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Danach wird es in der Einbettungsebene in eine vergleichbare Form umgewandelt.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!scheduler.Add(descr)) { delete descr; return false; }
Anschließend normalisieren wir die resultierenden Einbettungen mit der Funktion SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 4; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Die auf diese Weise vorverarbeiteten Daten durchlaufen den Aufmerksamkeitsblock.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 4; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Wir normalisieren die empfangenen Daten erneut mit SoftMax und leiten sie durch einen Block von voll verknüpften Entscheidungsschichten.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
Am Ausgang des Modells erhalten wir einen Vektor der latenten Darstellung des Kontexts, dessen Größe durch die Konstante EmbeddingSize bestimmt wird.
Wir entwerfen eine ähnliche Architektur für unseren Agenten. Der generierte Kontext wird den Quelldaten hinzugefügt.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateAgentDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + EmbeddingSize); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Die Daten werden auch durch Stapelnormalisierung und Einbettungsschichten vorverarbeitet und durch die SoftMax-Funktion normalisiert.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, EmbeddingSize}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 5; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Wir wiederholen den Aufmerksamkeitsblock vollständig, gefolgt von einer Normalisierung mit SoftMax. Hier sollten Sie nur darauf achten, die Größe des verarbeiteten Tensors zu ändern.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Als Nächstes reduzieren wir die Dimensionalität der Daten mithilfe von Faltungsschichten und versuchen gleichzeitig, stabile Muster darin zu erkennen.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Danach durchlaufen die Daten einen Entscheidungsblock aus 4 vollständig verbundenen Schichten. Die Größe der letzten Schicht entspricht dem Aktionsraum des Agenten.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
2.2 Sammeln von Trajektorien für das Training
Nachdem wir die Architektur der Modelle beschrieben haben, gehen wir dazu über, Expert Advisors für ihr Training zu konstruieren. Wir beginnen mit dem Aufbau des EA für die Interaktion mit der Umgebung, um Trajektorien zu sammeln und den Erfahrungswiedergabepuffer zu füllen, den wir später im Offline-Lernprozess „...\OPPO\Research.mq5“ ausnutzen werden.
Um die Umgebung zu erkunden, verwenden wir die ɛ-greedy-Strategie und fügen dem EA den entsprechenden externen Parameter hinzu.
input double Epsilon = 0.5;
Wie bereits erwähnt, verwenden wir im Prozess der Interaktion mit der Umwelt beide Modelle. Daher müssen wir für sie globale Variablen deklarieren.
CNet Agent; CNet Scheduler;
Die Methode zur Initialisierung des EA unterscheidet sich nicht wesentlich von der ähnlichen Methode der EAs, die wir zuvor besprochen haben. Daher denke ich, dass es nicht notwendig ist, den Algorithmus erneut zu prüfen. Sie können ihn im Anhang studieren. Betrachten wir nun die Methode OnTick, in deren Körper der Hauptprozess der Interaktion mit der Umgebung und der Datenerfassung aufgebaut ist.
Im Hauptteil der Methode wird geprüft, ob das Ereignis des Öffnens eines neuen Balkens eingetreten ist.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Falls erforderlich, laden wir Daten über historische Kursbewegungen herunter.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return;
Dann aktualisieren wir die Messwerte der analysierten Indikatoren.
RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Wir formatieren die empfangenen Daten in die Struktur des aktuellen Zustands und übertragen sie in den Datenpuffer, um sie anschließend als Eingangsdaten für unsere Modelle zu verwenden.
//--- History data float atr = 0; //--- for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
In der nächsten Phase ergänzen wir die Struktur der Beschreibung des aktuellen Zustands der Umwelt durch Informationen über den Kontostand und die offenen Positionen.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Die gesammelten Informationen werden auch dem Quelldatenpuffer hinzugefügt.
bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Als Nächstes fügen wir dem Quelldatenpuffer einen Zeitstempel und die letzte Aktion des Agenten hinzu.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
In diesem Stadium haben wir genügend Informationen für einen Vorwärtsdurchlauf des Schedulers gesammelt. So können wir den für unseren Agenten erforderlichen Kontextvektor bilden. Daher führen wir den Feed-Forward-Durchlauf des Schedulers durch.
if(!Scheduler.feedForward(GetPointer(bState), 1, false)) return; Scheduler.getResults(sState.scheduler); bState.AddArray(sState.scheduler);
Wir entladen das erhaltene Ergebnis und ergänzen den Quelldatenpuffer. Anschließend rufen wir die Feed-Forward-Pass-Methode des Agenten auf.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat *)NULL)) return;
An dieser Stelle möchte ich Sie daran erinnern, dass die korrekte Ausführung der Vorgänge in jeder Phase kontrolliert werden muss.
In diesem Stadium schließen wir die Arbeit mit den Modellen ab, speichern die Daten für spätere Operationen und gehen zur direkten Interaktion mit der Umwelt über.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Nachdem wir die Daten von unserem Agenten erhalten haben, fügen wir ihnen, falls erforderlich, ein Rauschen hinzu.
Agent.getResults(AgentResult); if(Epsilon > (double(MathRand()) / 32767.0)) for(ulong i = 0; i < AgentResult.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.03f; float t = AgentResult[i] + rnd; if(t > 1 || t < 0) t = AgentResult[i] - rnd; AgentResult[i] = t; } AgentResult.Clip(0.0f, 1.0f);
Wir entfernen doppelte Volumina aus den Positionsgrößen.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(AgentResult[0] >= AgentResult[3]) { AgentResult[0] -= AgentResult[3]; AgentResult[3] = 0; } else { AgentResult[3] -= AgentResult[0]; AgentResult[0] = 0; }
Danach passen wir zunächst die Kaufposition an.
//--- buy control if(AgentResult[0] < 0.9 * min_lot || (AgentResult[1] * MaxTP * Symb.Point()) <= stops || (AgentResult[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double(AgentResult[0] + FLT_EPSILON) - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + AgentResult[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - AgentResult[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Und dann führen wir ähnliche Operationen für eine Verkaufsposition durch.
//--- sell control if(AgentResult[3] < 0.9 * min_lot || (AgentResult[4] * MaxTP * Symb.Point()) <= stops || (AgentResult[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double(AgentResult[3] + FLT_EPSILON) - min_lot) / step_lot) * step_lot; double sell_tp = Symb.NormalizePrice(Symb.Bid() - AgentResult[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + AgentResult[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
In diesem Stadium bilden wir normalerweise einen Belohnungsvektor. Belohnungen werden im Rahmen des derzeitigen Algorithmus jedoch nicht verwendet. Daher übertragen wir einfach Daten über die abgeschlossenen Aktionen des Agenten und übermitteln Daten, um die Trajektorie zu speichern.
for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Dann warten wir weiter auf das Öffnen des nächsten Balkens.
An dieser Stelle stellt sich die folgende Frage: Wie werden wir die Präferenzen bewerten?
Die Antwort ist einfach: Wir werden Informationen über die Wirksamkeit des Durchlaufs in der OnTester-Methode hinzufügen, nachdem der Durchlauf im Strategietester abgeschlossen ist.
//+------------------------------------------------------------------+ //| Tester function | //+------------------------------------------------------------------+ double OnTester() { //--- double ret = 0.0; //--- Base.Profit = TesterStatistics(STAT_PROFIT); Frame[0] = Base; if(Base.Profit >= MinProfit) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), 1, Base.Profit, Frame); //--- return(ret); }
Die übrigen Methoden des EA zur Interaktion mit der Umwelt bleiben unverändert. Sie finden sie in der Anlage. Kommen wir nun zu den Algorithmen für die Modellschulung.
2.3 Training des Präferenzmodells
Schauen wir uns zunächst das Präferenzmodell-Training EA „...\OPPO\StudyScheduler.mq5“ an. Die EA-Architektur ist unverändert geblieben, sodass wir nur die Methoden für das Training des Modells im Detail betrachten werden.
Ich muss zugeben, dass der Prozess der Modellbildung auf Entwicklungen aus früheren Artikeln zurückgreift. Die Symbiose mit ihnen dürfte meiner Meinung nach die Effizienz des Lernprozesses erhöhen.
Bevor wir mit dem Lernprozess beginnen, erstellen wir eine Wahrscheinlichkeitsverteilung für die Auswahl der Trajektorien auf der Grundlage ihrer Rentabilität, wie es in der Methode CWBC vorgeschlagen wurde. Die zuvor beschriebene Methode GetProbTrajectories erfordert jedoch einige Änderungen, da kein Reward-Vektor vorhanden ist. Wir ändern zunächst die Informationsquelle für das Gesamtergebnis der Trajektorie. In diesem Fall wird der zerlegte Belohnungsvektor durch den skalaren Wert des Endgewinns ersetzt. Daher ersetzen wir die Matrix durch einen Vektor.
vector<double> GetProbTrajectories(STrajectory &buffer[], float lanbda) { ulong total = buffer.Size(); vector<double> rewards = vector<double>::Zeros(total); for(ulong i = 0; i < total; i++) rewards[i]=Buffer[i].Profit;
Dann bestimmen wir das maximale Rentabilitätsniveau und die Standardabweichung.
double std = rewards.Std(); double max_profit = rewards.Max();
Im nächsten Schritt sortieren wir die Ergebnisse der Trajektorie, um das Perzentil korrekt zu bestimmen.
vector<double> sorted = rewards; bool sort = true; while(sort) { sort = false; for(ulong i = 0; i < sorted.Size() - 1; i++) if(sorted[i] > sorted[i + 1]) { double temp = sorted[i]; sorted[i] = sorted[i + 1]; sorted[i + 1] = temp; sort = true; } }
Das weitere Vorgehen zur Konstruktion der Wahrscheinlichkeitsverteilung hat sich nicht geändert und wird in der zuvor beschriebenen Form verwendet.
double min = rewards.Min() - 0.1 * std; if(max_profit > min) { double k = sorted.Percentile(90) - max_profit; vector<double> multipl = MathAbs(rewards - max_profit) / (k == 0 ? -std : k); multipl = exp(multipl); rewards = (rewards - min) / (max_profit - min); rewards = rewards / (rewards + lanbda) * multipl; rewards.ReplaceNan(0); } else rewards.Fill(1); rewards = rewards / rewards.Sum(); rewards = rewards.CumSum(); //--- return rewards; }
An diesem Punkt kann die Vorbereitungsphase als abgeschlossen betrachtet werden, und wir gehen zur Betrachtung des Trainingsalgorithmus für das Präferenzmodell über - Train.
Im Hauptteil der Methode bilden wir zunächst einen Vektor der Wahrscheinlichkeitsverteilung für die Auswahl von Trajektorien aus dem Erfahrungswiedergabepuffer mit Hilfe der oben beschriebenen Methode GetProbTrajectories.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { vector<double> probability = GetProbTrajectories(Buffer, 0.1f); uint ticks = GetTickCount();
Als Nächstes organisieren wir ein System von Schleifen für das Modelltraining. Die Anzahl der Iterationen der äußeren Schleife wird durch den externen Parameter des Expert Advisors bestimmt.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr_p = SampleTrajectory(probability); int tr_m = SampleTrajectory(probability); while(tr_p == tr_m) tr_m = SampleTrajectory(probability);
Im Schleifenkörper nehmen wir zwei Trajektorien als Positiv- und Negativbeispiele. Um den Prinzipien der maximalen Objektivität gerecht zu werden, kontrollieren wir die Auswahl von 2 verschiedenen Trajektorien aus dem Erfahrungswiedergabepuffer.
Es liegt auf der Hand, dass eine einfache Stichprobe keine Garantie dafür ist, dass die positive Trajektorie zuerst gewählt wird und umgekehrt. Daher überprüfen wir die Rentabilität der ausgewählten Bahnen und ordnen gegebenenfalls die Zeiger auf die Trajektorien in den Variablen neu an.
if(Buffer[tr_p].Profit < Buffer[tr_m].Profit) { int t = tr_p; tr_p = tr_m; tr_m = t; }
Außerdem erfordert der Algorithmus OPPO das Training eines Präferenzmodells in der Richtung von einer negativen Trajektorie zu einer bevorzugten Trajektorie. Auf den ersten Blick mag es einfach und offensichtlich erscheinen. In der Praxis gibt es jedoch einige Fallstricke.
Für die Erstellung aller Trajektorien haben wir ein Segment der historischen Daten verwendet. Daher werden die Informationen über die Preisbewegung und die Werte der analysierten Indikatoren für alle Trajektorien identisch sein. Bei anderen analysierten Parametern ist die Situation jedoch anders. Ich spreche vom Kontostatus, von offenen Positionen und natürlich von den Aktionen des Agenten. Um die korrekte Übertragung des Fehlergradienten zu gewährleisten, müssen wir daher den Feedforward-Durchlauf für die Zustände beider Trajektorien nacheinander durchführen.
Dies führt jedoch zu der nächsten Frage. In unserem Modell verwenden wir die GPT-Architektur, die auf die Reihenfolge der Eingabedaten reagiert. Wie können wir also die Abläufe zweier verschiedener Trajektorien in einem Modell speichern? Die offensichtliche Antwort ist die parallele Verwendung von 2 Modellen mit periodischer Zusammenführung der Gewichtskoeffizienten, ähnlich der weichen Aktualisierung der Zielmodelle in den MN Methoden von TD3 und SAC. Aber auch hier gibt es Schwierigkeiten. Bei den genannten Methoden wurden die Zielmodelle nicht trainiert. Wir haben ihre Momentpuffer als Teil des sanften Lernprozesses genutzt. In diesem Fall werden die Modelle jedoch trainiert. Die Momentpuffer werden also für den vorgesehenen Zweck verwendet. Die Ergänzung mit Informationen über die sanfte Aktualisierung der Gewichtskoeffizienten kann den Lernprozess verzerren. Wir verzichten nicht auf eine detaillierte Analyse und suchen nach konstruktiven Lösungen.
Meiner Meinung nach ist die akzeptabelste Option, ein Modell sequentiell zu trainieren, zuerst auf den Daten einer Trajektorie und dann auf den Daten der zweiten Trajektorie unter Verwendung inverser Werte der Fehlergradienten. Denn bei der bevorzugten Trajektorie minimieren wir den Abstand, und bei der negativen maximieren wir ihn.
Nach dieser Logik nehmen wir den Ausgangszustand auf der bevorzugten Trajektorie.
//--- Positive int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr_p].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr_p].Total, 20))); if(i < 0) { iter--; continue; }
Wir leeren die Modellstapel und organisieren den Lernprozess im Rahmen der bevorzugten Trajektorie.
Scheduler.Clear(); for(int state = i; state < MathMin(Buffer[tr_p].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr_p].States[state].state);
Im Schleifenkörper füllen wir den anfänglichen Datenpuffer mit historischen Preisbewegungswerten und Indikatorwerten aus der Trainingsstichprobe von Trajektorien.
Wir fügen Informationen über den Kontostatus und die offenen Positionen hinzu.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr_p].States[state].account[0] : Buffer[tr_p].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr_p].States[state].account[1] : Buffer[tr_p].States[state - 1].account[1]); State.Add((Buffer[tr_p].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr_p].States[state].account[1] / PrevBalance); State.Add((Buffer[tr_p].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr_p].States[state].account[2]); State.Add(Buffer[tr_p].States[state].account[3]); State.Add(Buffer[tr_p].States[state].account[4] / PrevBalance); State.Add(Buffer[tr_p].States[state].account[5] / PrevBalance); State.Add(Buffer[tr_p].States[state].account[6] / PrevBalance);
Fügen wir die Oberschwingungen des Zeitstempels und den Vektor der letzten Aktionen des Agenten hinzu.
//--- Time label double x = (double)Buffer[tr_p].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr_p].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
Nach erfolgreicher Sammlung aller erforderlichen Daten führen wir einen Feed-Forward-Durchlauf mit dem trainierten Modell durch.
//--- Feed Forward if(!Scheduler.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Das Modell wird ähnlich wie überwachte Lernmethoden trainiert und zielt darauf ab, die Abweichungen der vorhergesagten Kontextwerte von den entsprechenden bevorzugten Trajektoriendaten im Erfahrungswiedergabepuffer zu minimieren.
//--- Study Result.AssignArray(Buffer[tr_p].States[state].scheduler); if(!Scheduler.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Anschließend informieren wir den Nutzer über den Fortschritt des Trainingsprozesses und fahren mit der nächsten Iteration des Trainings des Modells mit der bevorzugten Trajektorie fort.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheeduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nach erfolgreichem Abschluss der Schleifeniterationen innerhalb der bevorzugten Trajektorie gehen wir zur Arbeit mit der zweiten Trajektorie über.
Theoretisch können wir mit einer ähnlichen Zeitspanne arbeiten und den für die positive Trajektorie abgetasteten Anfangszustand verwenden. In einem historischen Zeitraum haben wir in allen Trajektorien die gleiche Anzahl von Schritten. Dies ist jedoch ein Sonderfall. Betrachtet man jedoch einen allgemeineren Fall, so kann es verschiedene Varianten mit einer unterschiedlichen Anzahl von Schritten in den Trajektorien geben. Wenn wir zum Beispiel über einen langen Zeitraum oder mit einer eher kleinen Einlage arbeiten, können wir diese Einlage verlieren und einen Stop-Out haben. Daher beschloss ich, die Ausgangszustände innerhalb der Arbeitstrajektorien zu erfassen.
//--- Negotive i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr_m].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr_m].Total, 20))); if(i < 0) { iter--; continue; }
Als Nächstes leeren wir den Modellstapel und organisieren eine Trainingsschleife, ähnlich der oben im Rahmen der bevorzugten Trajektorie durchgeführten Arbeit.
Scheduler.Clear(); for(int state = i; state < MathMin(Buffer[tr_m].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr_m].States[state].state); //--- Account description float PrevBalance = (state == 0 ? Buffer[tr_m].States[state].account[0] : Buffer[tr_m].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr_m].States[state].account[1] : Buffer[tr_m].States[state - 1].account[1]); State.Add((Buffer[tr_m].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr_m].States[state].account[1] / PrevBalance); State.Add((Buffer[tr_m].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr_m].States[state].account[2]); State.Add(Buffer[tr_m].States[state].account[3]); State.Add(Buffer[tr_m].States[state].account[4] / PrevBalance); State.Add(Buffer[tr_m].States[state].account[5] / PrevBalance); State.Add(Buffer[tr_m].States[state].account[6] / PrevBalance); //--- Time label double x = (double)Buffer[tr_m].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr_m].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions)); //--- Feed Forward if(!Scheduler.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Aber es gibt ein Detail bei der Festlegung der Ziele. Wir ziehen 2 Optionen in Betracht. Erstens, als Sonderfall: Wenn die Gewinne der bevorzugten Trajektorie und der zweiten Trajektorie gleich sind (im Grunde sind beide Trajektorien vorzuziehen), verwenden wir einen ähnlichen Ansatz wie bei der bevorzugten Trajektorie.
//--- Study if(Buffer[tr_p].Profit == Buffer[tr_m].Profit) Result.AssignArray(Buffer[tr_m].States[state].scheduler);
Der zweite Fall ist allgemeiner: Wenn der Gewinn der zweiten Trajektorie geringer ist, müssen wir von ihr in die entgegengesetzte Richtung abspringen. Dazu entladen wir den vorhergesagten Wert und ermitteln seine Abweichung vom Kontext der negativen Trajektorie aus dem Erfahrungswiedergabepuffer. Aber hier müssen wir in die entgegengesetzte Richtung gehen. Deshalb addieren wir nicht, sondern subtrahieren die resultierende Abweichung von den Prognosewerten. Um die Priorität der Bewegung in Richtung der bevorzugten Trajektorie zu erhöhen, reduziere ich bei der Berechnung des Zielwerts die resultierende Abweichung um das Zweifache.
else { vector<float> target, forecast; target.Assign(Buffer[tr_m].States[state].scheduler); Scheduler.getResults(forecast); target = forecast - (target - forecast) / 2; Result.AssignArray(target); }
Jetzt können wir den Backpropagation-Durchgang des Modells mit den verfügbaren Methoden durchführen, um die Abweichung vom eingestellten Ziel zu minimieren.
if(!Scheduler.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Wir informieren den Nutzer über den Fortschritt des Lernprozesses und fahren mit der nächsten Iteration unseres Schleifensystems fort.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheeduler", (iter + 0.5) * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nachdem alle Iterationen des Lernschleifensystems abgeschlossen sind, löschen wir das Kommentarfeld im Chart. Wir protokollieren die Ergebnisse des Lernprozesses und leiten den Prozess der erzwungenen Beendigung des Expert Advisors ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); ExpertRemove(); //--- }
Wir haben die Betrachtung der Expert Advisor Methoden für das Training des Präferenzmodells „...\OPPO\StudyScheduler.mq5“ abgeschlossen. Den vollständigen Code aller Methoden und Funktionen finden Sie im Anhang.
2.4 Schulung der Agentenpolitik
Der nächste Schritt ist die Erstellung des EA „...\OPPO\StudyAgent.mq5“ für die Agentenschulung. Die Architektur des EA ist fast identisch mit dem oben beschriebenen EA. Es gibt nur einige Unterschiede in der Methode des Trainings des Train-Modells. Betrachten wir sie genauer.
Wie zuvor ermitteln wir im Hauptteil der Methode zunächst die Wahrscheinlichkeiten für die Wahl der Trajektorien, indem wir die Methode GetProbTrajectories aufrufen.
vector<double> probability = GetProbTrajectories(Buffer, 0.1f); uint ticks = GetTickCount();
Als Nächstes organisieren wir ein System von verschachtelten Modelltrainingsschleifen.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
Diesmal nehmen wir nur eine Trajektorie im Hauptteil der äußeren Schleife. In diesem Stadium müssen wir die Strategie des Agenten erlernen, die in der Lage ist, den latenten Kontext mit spezifischen Aktionen zu verbinden. Dadurch werden die Aktionen des Agenten berechenbarer und kontrollierbarer. Daher unterteilen wir die Trajektorien nicht in bevorzugte und nicht bevorzugte Trajektorien.
Als Nächstes leeren wir den Modellstapel und organisieren eine verschachtelte Modelltrainingsschleife innerhalb der aufeinanderfolgenden Zustände der abgetasteten Teiltrajektorie.
Agent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Im Hauptteil der Schleife wird der anfängliche Datenpuffer mit den historischen Daten der Preisbewegung und den Indikatoren der analysierten Indikatoren aus dem Trainingssatz gefüllt. Wir ergänzen diese mit Daten über den Kontostand und offene Positionen.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Die Oberschwingungen des Zeitstempels und der Vektor der letzten Aktionen des Agenten werden ergänzt.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
Anders als das Präferenzmodell benötigt der Agent einen Kontext. Wir nehmen es aus dem Erfahrungswiedergabepuffer.
//--- Scheduler
State.AddArray(Buffer[tr].States[state].scheduler);
Die gesammelten Daten reichen für den Feedforward-Durchgang des Agentenmodells aus. Wir rufen also die entsprechende Methode auf.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Wie bereits erwähnt, trainieren wir die Actor-Policy, um Abhängigkeiten zwischen dem latenten Kontext und der ausgeführten Aktion herzustellen. Dies steht in vollem Einklang mit den Zielen von DT. In DT haben wir Abhängigkeiten zwischen Zielen und Aktionen hergestellt. Der latente Kontext kann als eine Art Einbettung des Ziels betrachtet werden. Die Form ändert sich zwar, aber der Kern bleibt derselbe. Folglich wird der Lernprozess ähnlich verlaufen. Wir minimieren den Fehler zwischen Prognose und tatsächlichem Handeln.
//--- Policy study Result.AssignArray(Buffer[tr].States[state].action); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Als Nächstes müssen wir den Nutzer nur noch über den Fortschritt des Lernprozesses informieren und zur nächsten Iteration übergehen.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nachdem der Schulungsprozess abgeschlossen ist, wird das Kommentarfeld auf dem Chart gelöscht. Wir geben das Ergebnis des Modelltrainings in das Protokoll ein und leiten den Abschluss des EA ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
Hier schließen wir mit dem Algorithmus der in diesem Artikel verwendeten Programme ab. Den vollständigen Code finden Sie im Anhang. Der Anhang enthält auch den Code des Expert Advisors zum Testen des trainierten Modells „...\OPPO\Test.mq5“, der den Algorithmus des Expert Advisors für die Interaktion mit der Umgebung fast vollständig wiederholt. Ich habe nur ausgeschlossen, dass die Aktionen des Agenten durch Rauschen verstärkt werden. Auf diese Weise können wir den Zufallsfaktor eliminieren und die erlernte Strategie vollständig bewerten.
3. Tests
Wir haben viel Arbeit in die Implementierung des Algorithmus OPPO (Offline Preference-guided Policy Optimization) gesteckt. Ich weise noch einmal darauf hin, dass die Arbeit eine persönliche Vision der Implementierung darstellt, bei der einige Operationen hinzugefügt wurden, die in dem von den Autoren der Methode beschriebenen ursprünglichen Algorithmus fehlen. Ich möchte in keiner Weise die Verdienste und die Arbeit der Autoren der Methode OPPO anrechnen. Andererseits möchte ich ihnen keine Fehler oder Missverständnisse der ursprünglichen Ideen zuschreiben.
Wie immer wird das Modell auf historischen Daten des EURUSD-Instruments, Zeitrahmen H1 für die ersten 7 Monate des Jahres 2023, trainiert. Das trainierte Modell wurde mit historischen Daten vom August 2023 getestet.
Aufgrund von Änderungen in der Struktur der Trajektorenspeicherung in dieser Arbeit können wir keine Beispieltrajektoren verwenden, die für frühere Arbeiten gesammelt wurden. Daher wurden völlig neue Trajektorien in den Trainingsdatensatz aufgenommen.
Hier muss ich zugeben, dass das Sammeln von 500 Trajektorien von neuen Modellen, die mit Zufallsgewichten initialisiert wurden, 3 Tage ununterbrochene Arbeit an meinem Laptop erforderte. Das kam völlig unerwartet.
Nach dem Sammeln des Trainingsdatensatzes begann ich mit dem parallelen Training der Modelle, was durch die Aufteilung des Trainingsprozesses in 2 unabhängige Expert Advisors ermöglicht wurde.
Wie immer war der Lernprozess ohne iterative Auswahl des Trainingsdatensatzes und unter Berücksichtigung von Modellaktualisierungen nicht vollständig. Wie Sie sehen werden, ist der Lernprozess ziemlich gleichmäßig und zielgerichtet. Selbst wenn der Trainingsdatensatz Verluste aufweist, ist es mit der Methode möglich, die Strategie zu verbessern.
Nach meiner persönlichen Beobachtung muss der Trainingsdatensatz positive Durchgänge haben, um eine profitable Strategie für das Verhalten des Agenten zu entwickeln. Das Vorhandensein solcher Durchgänge wird nur durch die Erkundung der Umgebung und das Sammeln zusätzlicher Trajektorien erreicht. Wie wir im vorigen Artikel gesehen haben, ist es auch möglich, Experten-Trajektorien zu verwenden oder Signaltransaktionen zu kopieren. Und durch die Hinzufügung profitabler Durchgänge wird der Modellbildungsprozess erheblich beschleunigt.
Während des Trainingsprozesses haben wir ein Modell erhalten, das in der Lage ist, sowohl bei den Trainings- als auch bei den Testproben Gewinne zu erzielen. Die Ergebnisse des Modells für das Testzeitintervall sind nachstehend aufgeführt.


Wie Sie auf den Screenshots sehen können, weist die Gleichgewichtslinie sowohl starke Anstiege als auch Rückgänge auf. Die Saldenkurve kann kaum als stabil bezeichnet werden, aber der allgemeine Aufwärtstrend bleibt erhalten. Ausgehend von den Ergebnissen des Testmonats haben wir einen Gewinn erzielt.
Während des Testzeitraums führte der EA insgesamt 180 Handelsgeschäfte aus. Fast 49 % davon wurden mit Gewinn abgeschlossen. Wir können es als Parität von gewinnbringenden und verlustbringenden Geschäften bezeichnen. Da jedoch der durchschnittliche Gewinn um 30 % höher ist als der durchschnittliche Verlust, erhöht sich der Saldo insgesamt. Der Gewinnfaktor in diesem historischen Testzeitraum betrug 1,25.
Schlussfolgerung
In diesem Artikel haben wir eine weitere interessante Methode zur Modellbildung vorgestellt: Offline-Präferenz-geführte Optimierung (OPPO). Das Hauptmerkmal dieser Methode ist die Eliminierung der Belohnungsfunktion aus dem Modellbildungsprozess. Dadurch wird der Anwendungsbereich erheblich erweitert. Denn manchmal kann es recht schwierig sein, ein bestimmtes Lernziel zu formulieren und zu präzisieren. Noch schwieriger wird es, die Auswirkungen jeder einzelnen Maßnahme auf das Endergebnis zu beurteilen, insbesondere wenn die Umwelt nur spärlich reagiert. Oder wenn eine solche Antwort mit einiger Verzögerung eintrifft. Stattdessen bewertet die vorgestellte OPPO-Methode die gesamte Trajektorie als ein einziges Ganzes, das aus einer einzigen Politik resultiert. Wir bewerten also nicht die Handlungen des Agenten, sondern seine Politik in einem bestimmten Umfeld. Und wir treffen die Entscheidung, diese Politik zu übernehmen oder, im Gegenteil, in die entgegengesetzte Richtung zu gehen, um eine optimalere Lösung zu finden.
Im praktischen Teil dieses Artikels haben wir die OPPO-Methode mit MQL5 umgesetzt, allerdings mit einigen Abweichungen von der ursprünglichen Methode. Dennoch ist es uns gelungen, eine Strategie zu trainieren, die in der Lage ist, sowohl in der historischen Trainingsperiode als auch in der Testperiode außerhalb des Trainingsdatensatzes Gewinne zu erzielen.
Die Ergebnisse des Modelltrainings und -tests zeigen die Möglichkeit, die vorgeschlagenen Ansätze für die Entwicklung echter Handelsstrategien zu nutzen.
Ich möchte Sie jedoch noch einmal daran erinnern, dass alle in diesem Artikel vorgestellten Programme nur zur Demonstration der Technologie dienen und nicht für den realen Finanzhandel geeignet sind.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | Beispielsammlung EA |
| 2 | StudyAgent.mq5 | EA | Trainings-EA des Agenten |
| 3 | StudyScheduler.mq5 | EA | Trainings-Expert Advisor des Präferenzmodells |
| 4 | Test.mq5 | EA | Testmodel des EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13912
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.