Brute-Force-Ansatz zur Mustersuche (Teil VI): Zyklische Optimierung

Inhalt
- Einführung
- Routinevorgänge
- Neuer Optimierungsalgorithmus
- Wichtigstes Optimierungskriterium
- Automatische Suche nach Handelskonfigurationen
- Schlussfolgerung
- Links
Einführung
In Anbetracht des Materials aus meinem vorherigen Artikel kann ich sagen, dass dies nur eine oberflächliche Beschreibung aller Funktionen ist, die ich in meinen Algorithmus eingeführt habe. Sie betreffen nicht nur die vollständige Automatisierung der EA-Erstellung, sondern auch so wichtige Funktionen wie die vollständige Automatisierung der Optimierung und Auswahl der Ergebnisse mit anschließender Verwendung für den automatischen Handel oder die Erstellung fortschrittlicherer EAs, die ich etwas später vorstellen werde.
Dank der Symbiose von Trading-Terminals, universellen EAs und dem Algorithmus selbst können Sie sich von der manuellen Entwicklung vollständig befreien oder im schlimmsten Fall die Arbeitsintensität möglicher Verbesserungen um eine Größenordnung reduzieren, vorausgesetzt, Sie verfügen über die notwendigen Rechenkapazitäten. In diesem Artikel werde ich zunächst die wichtigsten Aspekte dieser Innovationen beschreiben.
Routinevorgänge
Der wichtigste Faktor bei der Entwicklung und späteren Änderung solcher Lösungen war für mich die Möglichkeit, Routinevorgänge maximal zu automatisieren. Zu den Routinemaßnahmen gehören in diesem Fall alle nicht wesentlichen menschlichen Tätigkeiten:
- Generierung von Ideen.
- Erstellen einer Theorie.
- Schreiben eines Codes gemäß der Theorie.
- Code-Korrektur.
- Ständige EA-Neuroptimierung.
- Konstante EA-Auswahl.
- EA-Wartung.
- Arbeiten mit den Terminals.
- Experimente und Praxis.
- Sonstiges.
Wie Sie sehen können, ist die Bandbreite dieser Routinevorgänge recht groß. Ich betrachte dies als Routinevorgänge, denn ich konnte beweisen, dass all diese Dinge automatisiert werden können. Ich habe eine allgemeine Liste erstellt. Es spielt keine Rolle, wer Sie sind – ein algorithmischer Händler, ein Programmierer oder beides. Es spielt keine Rolle, ob Sie programmieren können oder nicht. Selbst wenn Sie das nicht tun, werden Sie auf jeden Fall auf mindestens die Hälfte dieser Liste stoßen. Ich spreche nicht von Fällen, in denen Sie einen EA auf dem Markt gekauft haben, ihn auf dem Chart gestartet haben und sich mit einem Knopfdruck beruhigt haben. Das kommt natürlich vor, wenn auch äußerst selten.
Um all dies zu verstehen, musste ich zunächst die offensichtlichsten Dinge automatisieren. Ich habe all diese Optimierungen in einem früheren Artikel konzeptionell beschrieben. Aber wenn man so etwas macht, beginnt man zu verstehen, wie man das Ganze auf der Grundlage der bereits implementierten Funktionen verbessern kann. Die wichtigsten Ideen in diesem Zusammenhang waren für mich die folgenden:
- Verbesserung des Optimierungsmechanismus.
- Schaffung eines Mechanismus zur Zusammenlegung von EAs (Bots verbinden).
- Korrekte Architektur der Interaktionspfade aller Komponenten.
Dies ist natürlich eine recht kurze Aufzählung. Ich werde alles ausführlicher beschreiben. Mit der Verbesserung der Optimierung meine ich eine Reihe von Faktoren auf einmal. All dies wird im Rahmen des gewählten Paradigmas für den Aufbau des gesamten Systems durchdacht:
- Beschleunigung der Optimierung durch Vermeiden der Ticks.
- Beschleunigung der Optimierung durch Eliminierung der Gewinnkurvenkontrolle zwischen Handelsentscheidungspunkten.
- Verbesserung der Qualität der Optimierung durch Einführung benutzerdefinierter Optimierungskriterien.
- Maximierung der Effizienz der Vorlaufzeit.
Im Forum dieser Website wird immer noch darüber diskutiert, ob eine Optimierung überhaupt notwendig ist und welchen Nutzen sie hat. Früher hatte ich eine ziemlich klare Haltung zu dieser Aktion, was vor allem auf den Einfluss einzelner Nutzer des Forums und der Website zurückzuführen ist. Nun stört mich diese Meinung überhaupt nicht. Was die Optimierung betrifft, so hängt alles davon ab, ob Sie wissen, wie man sie richtig einsetzt und welche Ziele Sie verfolgen. Bei richtiger Anwendung führt diese Aktion zum gewünschten Ergebnis. Im Allgemeinen erweist sich diese Maßnahme als äußerst nützlich.
Viele Menschen mögen die Optimierung nicht. Hierfür gibt es zwei objektive Gründe:
- Mangelndes Verständnis der Grundlagen (warum, was und wie zu tun ist, wie man Ergebnisse auswählt und alles, was damit zusammenhängt, einschließlich mangelnder Erfahrung).
- Unvollkommenheit von Optimierungsalgorithmen.
In der Tat verstärken sich beide Faktoren gegenseitig. Fairerweise muss man sagen, dass der MetaTrader 5 Optimizer strukturell tadellos ausgeführt ist, aber in Bezug auf die Optimierungskriterien und möglichen Filter noch viele Verbesserungen benötigt. Bislang sind all diese Funktionen wie ein Sandkasten für Kinder. Nur wenige Menschen denken darüber nach, wie sie positive Vorwärtsphasen erreichen und vor allem, wie sie diesen Prozess kontrollieren können. Ich habe lange über diese Frage nachgedacht. Diesem Thema soll ein großer Teil des vorliegenden Artikels gewidmet werden.
Neuer Optimierungsalgorithmus
Zusätzlich zu den bekannten grundlegenden Bewertungskriterien eines Backtests können wir einige kombinierte Merkmale finden, die den Wert eines jeden Algorithmus für eine effizientere Auswahl der Ergebnisse und die anschließende Anwendung der Einstellungen vervielfachen können. Der Vorteil dieser Merkmale ist, dass sie den Prozess der Suche nach Arbeitseinstellungen beschleunigen können. Zu diesem Zweck habe ich eine Art Strategie-Tester-Bericht erstellt, ähnlich dem in MetaTrader:
Abbildung 1

Mit diesem Tool kann ich die gewünschte Option mit einem einfachen Klick auswählen. Durch Anklicken wird eine Einstellung generiert, die ich sofort übernehmen und in den entsprechenden Ordner im Terminal verschieben kann, sodass universelle EAs sie lesen und mit dem Handel beginnen können. Wenn ich will, kann ich auch auf die Schaltfläche klicken, um einen EA zu generieren, und er wird erstellt, falls ich einen separaten EA mit den darin fest verdrahteten Einstellungen benötige. Es gibt auch eine Gewinnkurve, die neu gezeichnet wird, wenn Sie die nächste Option in der Tabelle auswählen.
Lassen Sie uns herausfinden, was in der Tabelle gezählt wird. Die wichtigsten Elemente zur Berechnung dieser Merkmale sind die folgenden Daten:
- Points: Gewinn des gesamten Backtests in „_Point“ des entsprechenden Instruments.
- Orders: die Anzahl der vollständig offenen und geschlossenen Aufträge (sie folgen in strenger Reihenfolge aufeinander, gemäß der Regel „es kann nur einen offenen Auftrag geben“).
- Drawdown: Drawdown des Saldos.
Auf der Grundlage dieser Werte werden die folgenden Handelsmerkmale berechnet:
- Math Waiting: mathematische Erwartung in Punkten.
- P-Faktor: Analogon des Gewinnfaktors, normiert auf den Bereich [-1 ... 0 ... 1] (mein Kriterium).
- Martingale: Anwendbarkeit des Martingals (mein Kriterium).
- MPM Complex: ein zusammengesetzter Indikator der drei vorhergehenden (mein Kriterium).
Schauen wir uns nun an, wie diese Kriterien berechnet werden:
Gleichungen 1

Wie Sie sehen, sind alle Kriterien, die ich erstellt habe, sehr einfach und vor allem leicht zu verstehen. Da die Erhöhung jedes einzelnen Kriteriums anzeigt, dass das Backtest-Ergebnis im Sinne der Wahrscheinlichkeitstheorie besser ist, können diese Kriterien multipliziert werden, wie ich es beim MPM Complex-Kriterium getan habe. Mit einer gemeinsamen Metrik lassen sich die Ergebnisse besser nach ihrer Bedeutung sortieren. Bei massiven Optimierungen können Sie so mehr hochwertige Optionen beibehalten bzw. mehr minderwertige entfernen.
Beachten Sie auch, dass bei diesen Berechnungen alles in Punkten erfolgt. Dies wirkt sich positiv auf den Optimierungsprozess aus. Für Berechnungen werden streng positive Primärgrößen verwendet, die immer zu Beginn berechnet werden. Alles andere wird auf der Grundlage dieser Daten berechnet. Ich denke, es lohnt sich, diese Primärmengen aufzulisten, die nicht in der Tabelle enthalten sind:
- Points Plus: Summe der Gewinne jedes profitablen oder Null-Auftrags in Punkten
- Points Minus: Summe der Verlustmodule jedes unrentablen Auftrags in Punkten
- Drawdown: Drawdown des Saldos (ich berechne ihn auf meine Weise)
Interessant ist hier vor allem, wie der Drawdown berechnet wird. In unserem Fall ist dies der maximale relative Salden-Drawdown. In Anbetracht der Tatsache, dass mein Testalgorithmus sich weigert, die Saldenkurve zu überwachen, können andere Arten von Drawdowns nicht berechnet werden. Ich denke jedoch, dass es sinnvoll wäre, zu zeigen, wie ich diesen Drawdown berechne:
Abbildung 2

Sie ist sehr einfach definiert:
- Wir berechnen den Startpunkt des Backtests (den Beginn des ersten Drawdown-Countdowns).
- Wenn der Handel mit einem Gewinn beginnt, verschieben wir diesen Punkt entsprechend dem Wachstum des Saldos nach oben, bis der erste negative Wert erscheint (er markiert den Beginn der Drawdown-Berechnung).
- Wir warten, bis der Saldo die Höhe des Referenzpunktes erreicht hat. Danach setzen wir ihn als neuen Bezugspunkt.
- Wir kehren zum letzten Abschnitt der Suche nach den Drawdowns zurück und suchen den niedrigsten Punkt (die Höhe des Drawdowns in diesem Abschnitt wird von diesem Punkt aus berechnet).
- Wir wiederholen den gesamten Vorgang für die gesamte Backtest- oder Handelskurve.
Der letzte Zyklus wird immer unvollendet bleiben. Allerdings wird auch sein Drawdown berücksichtigt, obwohl die Möglichkeit besteht, dass er sich erhöht, wenn der Test fortgesetzt wird. Aber das ist hier nicht besonders wichtig.
Wichtigstes Optimierungskriterium
Lassen Sie uns nun über den wichtigsten Filter sprechen. Dieses Kriterium ist in der Tat das wichtigste bei der Auswahl von Optimierungsergebnissen. Dieses Kriterium ist in der Funktionalität des MetaTrader 5-Optimierers nicht enthalten, was sehr schade ist. Ich möchte daher theoretisches Material zur Verfügung stellen, damit jeder diesen Algorithmus in seinem eigenen Code reproduzieren kann. In der Tat ist dieses Kriterium multifunktional für jede Art von Handel und funktioniert für absolut jede Gewinnkurve, einschließlich Sportwetten, Kryptowährungen und alles andere, was Sie sich vorstellen können. Das Kriterium lautet wie folgt:
Gleichungen 2

Schauen wir uns an, was in dieser Gleichung steht:
- N — Anzahl der vollständig offenen und geschlossenen Handelspositionen während des gesamten Backtests oder Handelsabschnitts.
- B(i) — Wert der Saldenlinie nach der entsprechenden geschlossenen Position „i“.
- L(i) — gerade Linie von Null bis zum letzten Punkt des Saldos (Endsaldo).
Um diesen Parameter zu berechnen, müssen wir zwei Backtests durchführen. Der erste Backtest wird den Endsaldo berechnen. Danach wird es möglich sein, den entsprechenden Indikator zu berechnen, indem der Wert jedes Bilanzpunktes gespeichert wird, sodass keine unnötigen Berechnungen vorgenommen werden müssen. Dennoch kann diese Berechnung als wiederholter Backtest bezeichnet werden. Diese Gleichung kann in nutzerdefinierten Testern verwendet werden, die in Ihre EAs eingebaut werden können.
Es ist wichtig zu beachten, dass dieser Indikator als Ganzes für ein besseres Verständnis verändert werden kann. Zum Beispiel so:
Gleichungen 3

Diese Gleichung ist in Bezug auf Wahrnehmung und Verständnis schwieriger. Aus praktischer Sicht ist ein solches Kriterium jedoch praktisch, denn je höher es ist, desto mehr ähnelt unsere Saldenkurve einer Geraden. In früheren Artikeln habe ich ähnliche Themen angesprochen, ohne jedoch die Bedeutung dahinter zu erklären. Schauen wir uns zunächst die folgende Abbildung an:
Abbildung 3

Diese Abbildung zeigt eine Gleichgewichtslinie und zwei Kurven: eine davon bezieht sich auf unsere Gleichung (rot), die zweite auf das folgende modifizierte Kriterium (Gleichungen 11). Ich werde das noch weiter ausführen, aber jetzt wollen wir uns auf die Gleichung konzentrieren.
Wenn wir uns unseren Backtest als eine einfache Reihe von Punkten mit Salden vorstellen, können wir ihn als statistische Stichprobe darstellen und Gleichungen der Wahrscheinlichkeitstheorie auf ihn anwenden. Wir betrachten die gerade Linie als das angestrebte Modell und die Gewinnkurve selbst als den tatsächlichen Datenfluss, der unser Modell anstrebt.
Es ist wichtig zu verstehen, dass der Linearitätsfaktor die Zuverlässigkeit des gesamten verfügbaren Satzes von Handelskriterien angibt. Eine höhere Verlässlichkeit der Daten kann wiederum auf eine mögliche längere und bessere Vorlaufzeit hinweisen (profitables Handeln in der Zukunft). Streng genommen hätte ich diese Überlegungen ursprünglich mit einer Betrachtung von Zufallsvariablen beginnen sollen, aber ich hatte den Eindruck, dass eine solche Darstellung das Verständnis erleichtern würde.
Lassen Sie uns ein alternatives Analogon zu unserem Linearitätsfaktor erstellen, das mögliche zufällige Ausschläge berücksichtigt. Dazu müssen wir eine für uns geeignete Zufallsvariable und ihren Durchschnitt für die anschließende Streuungsberechnung einführen:
Gleichungen 4

Zum besseren Verständnis sollte klargestellt werden, dass wir „N“ vollständig offene und geschlossene Positionen haben, die streng aufeinander folgen. Das bedeutet, dass wir „N+1“ Punkte haben, die diese Segmente der Gleichgewichtslinie verbinden. Der Nullpunkt aller Linien ist gemeinsam, sodass seine Daten die Ergebnisse in Richtung Verbesserung verzerren, genau wie der letzte Punkt. Deshalb werden sie aus den Berechnungen herausgenommen, und es bleiben „N-1“ Punkte übrig, mit denen wir Berechnungen durchführen werden.
Die Auswahl des Ausdrucks für die Umwandlung der Wertefelder zweier Zeilen in ein einziges erwies sich als sehr interessant. Bitte beachten Sie die folgende Fraktion:
Gleichungen 5

Wichtig ist dabei, dass wir in allen Fällen alles durch den Endsaldo teilen. Wir reduzieren also alles auf einen relativen Wert, der die Gleichwertigkeit der berechneten Merkmale für ausnahmslos alle getesteten Strategien gewährleistet. Es ist kein Zufall, dass derselbe Bruchteil im allerersten und einfachen Kriterium des Linearitätsfaktors enthalten ist, da es auf derselben Überlegung beruht. Aber lassen Sie uns die Konstruktion unseres alternativen Kriteriums vervollständigen. Dazu können wir ein so bekanntes Konzept wie die Streuung verwenden:
Gleichungen 6

Die Streuung ist nichts anderes als das arithmetische Mittel der quadrierten Abweichung vom Mittelwert der gesamten Stichprobe. Ich habe dort sofort unsere Zufallsvariablen eingesetzt, deren Ausdrücke oben definiert wurden. Eine ideale Kurve hat eine mittlere Abweichung von Null und folglich ist auch die Streuung einer gegebenen Stichprobe gleich Null. Anhand dieser Daten lässt sich leicht erraten, dass diese Streuung aufgrund ihrer Struktur – der verwendeten Zufallsvariablen oder der Stichprobe (je nach Wunsch – als alternativer Linearitätsfaktor verwendet werden kann. Darüber hinaus können beide Kriterien zusammen verwendet werden, um die Stichprobenparameter besser einzuschränken, obwohl ich ehrlich gesagt nur das erste Kriterium verwende.
Betrachten wir ein ähnliches, einfacheres Kriterium, das ebenfalls auf einem neuen, von uns definierten Linearitätsfaktor beruht:
Gleichungen 7
![]()
Wie wir sehen können, ist es identisch mit einem ähnlichen Kriterium, das auf der Grundlage des ersten Kriteriums (Gleichungen 2) aufgebaut ist. Diese beiden Kriterien sind jedoch bei weitem nicht alles, was man sich vorstellen kann. Eine offensichtliche Tatsache, die für diese Überlegung spricht, ist, dass dieses Kriterium zu idealisiert ist und sich eher für ideale Modelle eignet, und es wird äußerst schwierig sein, einen EA anzupassen, um eine mehr oder weniger bedeutende Übereinstimmung zu erreichen. Ich denke, es lohnt sich, die negativen Faktoren aufzulisten, die einige Zeit nach Anwendung der Gleichungen offensichtlich werden:
- Kritische Verringerung der Anzahl der Abschlüsse (verringert die Zuverlässigkeit der Ergebnisse)
- Ablehnung der maximalen Anzahl effizienter Szenarien (je nach Strategie tendiert die Kurve nicht immer zu einer Geraden)
Diese Unzulänglichkeiten sind sehr kritisch, da das Ziel nicht darin besteht, gute Strategien zu verwerfen, sondern im Gegenteil neue und verbesserte Kriterien zu finden, die frei von diesen Unzulänglichkeiten sind. Diese Nachteile können durch die gleichzeitige Einführung mehrerer bevorzugter Linien, von denen jede als akzeptables oder bevorzugtes Modell angesehen werden kann, ganz oder teilweise neutralisiert werden. Um das neue, verbesserte Kriterium zu verstehen, das diese Mängel nicht mehr aufweist, müssen Sie nur die entsprechende Ersetzung verstehen:
Gleichungen 8

Dann können wir den Anpassungsfaktor für jede Kurve aus der Liste berechnen:
Gleichungen 9

In ähnlicher Weise können wir auch ein alternatives Kriterium berechnen, das zufällige Ausschläge für jede der Kurven berücksichtigt:
Gleichungen 10

Dann müssen wir das Folgende berechnen:
Gleichungen 11

Hier führe ich ein Kriterium ein, das ich den Kurvenfamilienfaktor nenne. Mit dieser Aktion finden wir gleichzeitig die Kurve, die unserer Handelskurve am ähnlichsten ist, und finden sofort den Faktor, der ihr entspricht. Die Kurve mit dem geringsten Anpassungsfaktor kommt der realen Situation am nächsten. Wir nehmen seinen Wert als den Wert des modifizierten Kriteriums, und natürlich kann die Berechnung auf zwei Arten erfolgen, je nachdem, welche der beiden Varianten uns besser gefällt.
Das ist alles sehr cool, aber hier gibt es, wie viele bemerkt haben, Nuancen im Zusammenhang mit der Auswahl einer solchen Familie von Kurven. Um eine solche Familie richtig zu beschreiben, kann man verschiedene Überlegungen anstellen, aber hier sind meine Gedanken:
- Alle Kurven sollten keine Wendepunkte haben (jeder nachfolgende Zwischenpunkt sollte unbedingt höher sein als der vorherige).
- Die Kurve sollte konkav sein (die Steigung der Kurve kann entweder konstant sein oder sie kann nur zunehmen).
- Die Konkavität der Kurve sollte einstellbar sein (z. B. sollte der Betrag der Durchbiegung anhand eines relativen Wertes oder Prozentsatzes eingestellt werden).
- Einfachheit des Kurvenmodells (es ist besser, das Modell auf zunächst einfache und verständliche grafische Modelle zu stützen).
Dies ist nur die erste Variante dieser Kurvenfamilie. Es ist möglich, umfangreichere Variationen unter Berücksichtigung aller gewünschten Konfigurationen vorzunehmen, was uns den Verlust von Qualitätseinstellungen vollständig ersparen kann. Ich werde mich dieser Aufgabe später widmen, aber jetzt werde ich nur auf die ursprüngliche Strategie der Familie der konkaven Kurven eingehen. Mit meinen mathematischen Kenntnissen konnte ich eine solche Familie ganz einfach erstellen. Lassen Sie mich Ihnen gleich zeigen, wie diese Kurvenfamilie letztendlich aussieht:
Abbildung 4

Bei der Konstruktion einer solchen Familie habe ich die Abstraktion eines elastischen Stabes verwendet, der auf vertikalen Stützen liegt. Der Grad der Durchbiegung einer solchen Messlatte hängt vom Angriffspunkt der Kraft und ihrer Größe ab. Es ist klar, dass dies nur ein wenig dem ähnelt, womit wir es hier zu tun haben, aber es reicht völlig aus, um eine Art visuelles Modell zu entwickeln. In dieser Situation sollten wir natürlich zunächst die Koordinate des Extremums bestimmen, die mit einem der Punkte auf dem Backtest-Chart übereinstimmen sollte, und dort wird die X-Achse durch die Handelsindizes dargestellt, die bei Null beginnen. Ich rechne das folgendermaßen:
Gleichungen 12

Hier gibt es zwei Fälle: für gerade und ungerade „N“. Wenn „N“ gerade ist, kann es nicht einfach durch zwei geteilt werden, da der Index eine ganze Zahl sein muss. Übrigens habe ich genau diesen Fall auf dem letzten Bild dargestellt. Dort liegt der Punkt der Kraftanwendung etwas näher am Anfang. Sie können natürlich auch das Gegenteil tun, etwas näher am Ende, aber das wird nur bei einer kleinen Anzahl von Geschäften von Bedeutung sein, wie ich in der Abbildung dargestellt habe. Mit zunehmender Anzahl der Positionen spielt all dies für die Optimierungsalgorithmen keine Rolle mehr.
Nachdem der prozentuale Wert der Auslenkung „P“ und der Endsaldo „B“ des Backtests festgelegt wurden und die Koordinate des Extremwerts bestimmt wurde, kann man damit beginnen, nacheinander weitere Komponenten zu berechnen, um Ausdrücke für jede der akzeptierten Kurvenfamilien zu konstruieren. Als Nächstes benötigen wir die Steigung der geraden Linie, die den Anfang und das Ende des Backtests verbindet:
Gleichungen 13

Ein weiteres Merkmal dieser Kurven ist die Tatsache, dass der Tangentenwinkel zu jeder der Kurven an den Punkten mit der Abszisse „N0“ identisch mit „K“ ist. Bei der Konstruktion der Gleichungen habe ich diese Bedingung aus der Aufgabe übernommen. Dies ist in der letzten Abbildung (Abbildung 4) auch grafisch zu sehen, und es gibt dort auch einige Gleichungen und Identitäten. Weiter geht's. Nun müssen wir den folgenden Wert berechnen:
Gleichungen 14

Beachten Sie, dass „P“ für jede Kurve der Familie anders eingestellt ist. Streng genommen handelt es sich dabei um Gleichungen für die Konstruktion einer Kurve aus einer Familie. Diese Berechnungen sollten für jede Kurve der Familie wiederholt werden. Dann müssen wir eine weitere wichtige Kennzahl berechnen:
Gleichungen 15
![]()
Es ist nicht notwendig, die Bedeutung dieser Strukturen zu ergründen. Sie wurden nur geschaffen, um die Konstruktion von Kurven zu vereinfachen. Bleibt noch die Berechnung der letzten Hilfsquote:
Gleichungen 16

Auf der Grundlage der gewonnenen Daten können wir nun einen mathematischen Ausdruck für die Berechnung der Punkte der konstruierten Kurve erhalten. Zunächst muss jedoch klargestellt werden, dass die Kurve nicht durch eine einzige Gleichung beschrieben wird. Links vom Punkt „N0“ befindet sich eine Gleichung, während rechts davon eine andere gilt. Um das Verständnis zu erleichtern, können wir wie folgt vorgehen:
Gleichungen 17
![]()
Jetzt können wir die endgültigen Gleichungen sehen:
Gleichungen 18

Wir können dies auch wie folgt zeigen:
Gleichungen 19

Streng genommen sollte diese Funktion als diskrete Hilfsfunktion verwendet werden. Dennoch ermöglicht es uns, Werte in Bruchteilen von „i“ zu berechnen. Dies ist natürlich für unser Problem nicht von Nutzen.
Da ich solche Mathematik gebe, bin ich verpflichtet, Beispiele für die Umsetzung des Algorithmus zu geben. Ich denke, jeder wird daran interessiert sein, fertigen Code zu erhalten, der sich leichter an seine Systeme anpassen lässt. Beginnen wir mit der Definition der wichtigsten Variablen und Methoden, die die Berechnung der erforderlichen Größen vereinfachen werden:
//+------------------------------------------------------------------+ //| Number of lines in the balance model | //+------------------------------------------------------------------+ #define Lines 11 //+------------------------------------------------------------------+ //| Initializing variables | //+------------------------------------------------------------------+ double MaxPercent = 10.0; double BalanceMidK[,Lines]; double Deviations[Lines]; int Segments; double K; //+------------------------------------------------------------------+ //| Method for initializing required variables and arrays | //| Parameters: number of segments and initial balance | //+------------------------------------------------------------------+ void InitLines(int SegmentsInput, double BalanceInput) { Segments = SegmentsInput; K = BalanceInput / Segments; ArrayResize(BalanceMidK,Segments+1); ZeroStartBalances(); ZeroDeviations(); BuildBalances(); } //+------------------------------------------------------------------+ //| Resetting variables for incrementing balances | //+------------------------------------------------------------------+ void ZeroStartBalances() { for (int i = 0; i < Lines; i++ ) { for (int j = 0; j <= Segments; j++) { BalanceMidK[j,i] = 0.0; } } } //+------------------------------------------------------------------+ //| Reset deviations | //+------------------------------------------------------------------+ void ZeroDeviations() { for (int i = 0; i < Lines; i++) { Deviations[i] = -1.0; } }
Der Code ist so konzipiert, dass er wiederverwendet werden kann. Nach der nächsten Berechnung können Sie den Indikator für eine andere Saldenkurve berechnen, indem Sie zunächst die Methode InitLines aufrufen. Sie müssen der Endsaldo des Backtests und die Anzahl der Trades angeben. Danach können Sie beginnen, unsere Kurven auf der Grundlage dieser Daten zu erstellen:
//+------------------------------------------------------------------+ //| Constructing all balances | //+------------------------------------------------------------------+ void BuildBalances() { int N0 = MathFloor(Segments / 2.0) - Segments / 2.0 == 0 ? Segments / 2 : (int)MathFloor(Segments / 2.0);//calculate first required N0 for (int i = 0; i < Lines; i++) { if (i==0)//very first and straight line { for (int j = 0; j <= Segments; j++) { BalanceMidK[j,i] = K*j; } } else//build curved lines { double ThisP = i * (MaxPercent / 10.0);//calculate current line curvature percentage double KDelta = ( (ThisP /100.0) * K * Segments) / (MathPow(N0,2)/2.0 );//calculation first auxiliary ratio double Psi0 = -KDelta * N0;//calculation second auxiliary ratio double KDelta1 = ((ThisP / 100.0) * K * Segments) / (MathPow(Segments-N0, 2) / 2.0);//calculate last auxiliary ratio //this completes the calculation of auxiliary ratios for a specific line, it is time to construct it for (int j = 0; j <= N0; j++)//construct the first half of the curve { BalanceMidK[j,i] = (K + Psi0 + (KDelta * j) / 2.0) * j; } for (int j = N0; j <= Segments; j++)//construct the second half of the curve { BalanceMidK[j,i] = BalanceMidK[i, N0] + (K + (KDelta1 * (j-N0)) / 2.0) * (j-N0); } } } }
Bitte beachten Sie, dass die „Linien“ bestimmt, wie viele Kurven es in unserer Familie geben wird. Die Konkavität nimmt allmählich von Null (gerade) bis zu MaxPercent zu, genau wie in der entsprechenden Abbildung gezeigt. Dann können Sie die Abweichung für jede der Kurven berechnen und die kleinste Kurve auswählen:
//+------------------------------------------------------------------+ //| Calculation of the minimum deviation from all lines | //| Parameters: initial balance passed via link | //| Return: minimum deviation | //+------------------------------------------------------------------+ double CalculateMinDeviation(double &OriginalBalance[]) { //define maximum relative deviation for each curve for (int i = 0; i < Lines; i++) { for (int j = 0; j <= Segments; j++) { double CurrentDeviation = OriginalBalance[Segments] ? MathAbs(OriginalBalance[j] - BalanceMidK[j, i]) / OriginalBalance[Segments] : -1.0; if (CurrentDeviation > Deviations[i]) { Deviations[i] = CurrentDeviation; } } } //determine curve with minimum deviation and deviation itself double MinDeviation=0.0; for (int i = 0; i < Lines; i++) { if ( Deviations[i] != -1.0 && MinDeviation == 0.0) { MinDeviation = Deviations[i]; } else if (Deviations[i] != -1.0 && Deviations[i] < MinDeviation) { MinDeviation = Deviations[i]; } } return MinDeviation; }
So sollten wir es verwenden:
- Definition des OriginalBalance-Arrays für den ursprünglichen Saldo.
- Wir bestimmen die Länge SegmentsInput und den Endsaldo BalanceInput, und rufen die Methode InitLines auf.
- Anschließend werden die Kurven durch Aufruf der Methode BuildBalances erstellt.
- Da die Kurven gezeichnet sind, können wir unser verbessertes CalculateMinDeviation-Kriterium für die Kurvenfamilie berücksichtigen.
Damit ist die Berechnung des Kriteriums abgeschlossen. Ich denke, die Berechnung des Kurvenfamilienfaktors wird keine Schwierigkeiten bereiten. Es ist nicht notwendig, sie hier zu präsentieren.
Automatische Suche nach Handelskonfigurationen
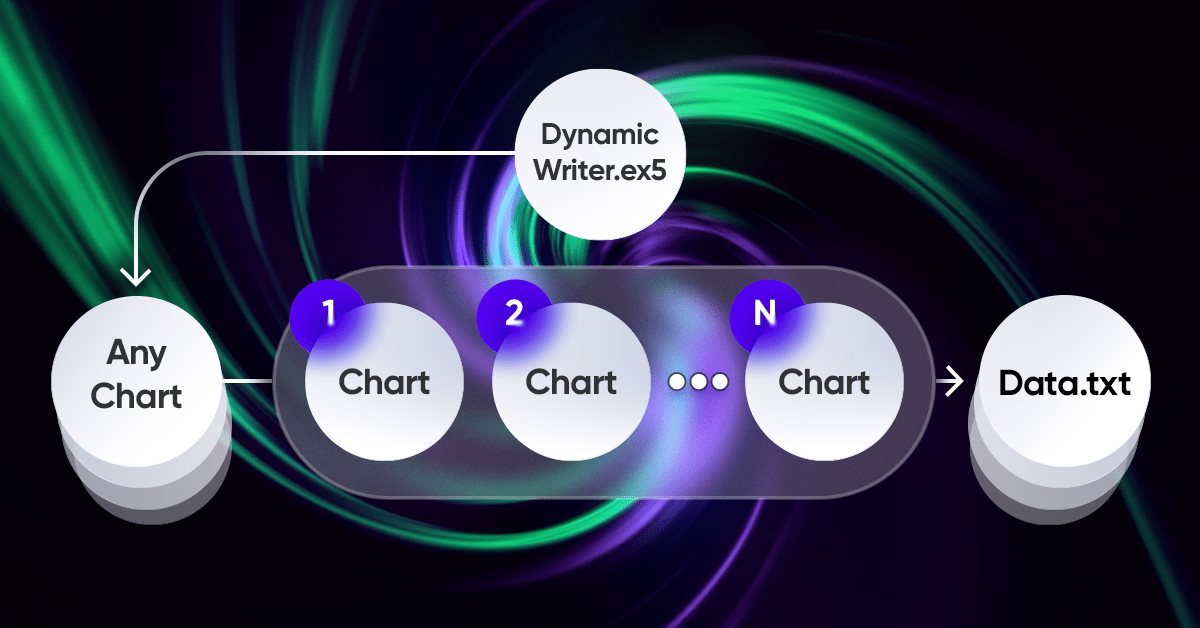
Das wichtigste Element der ganzen Idee ist das Interaktionssystem zwischen dem Terminal und meinem Programm. Es handelt sich um einen zyklischen Optimierer mit erweiterten Optimierungskriterien. Die wichtigsten wurden bereits im vorherigen Abschnitt behandelt. Damit das gesamte System funktioniert, benötigen wir zunächst eine Quelle für Kurse, nämlich eines der MetaTrader 5-Terminals. Wie ich bereits im vorigen Artikel gezeigt habe, werden Kurse in eine Datei in einem für mich bequemen Format geschrieben. Dies geschieht mit Hilfe eines EA, der auf den ersten Blick recht seltsam funktioniert:
. 
Ich fand es eine interessante und nützliche Erfahrung, mein eigenes Schema für das Funktionieren des EA zu verwenden. Dies ist nur eine Demonstration der Probleme, die ich zu lösen hatte, aber all dies kann auch für Handels-EAs verwendet werden:

Die Besonderheit dieses Schemas besteht darin, dass wir einen beliebigen Graphen auswählen können. Es wird nicht als Handelsinstrument verwendet, um eine Duplizierung von Daten zu vermeiden, sondern dient lediglich als Tick-Handler oder Timer. Die übrigen Charts stellen die Instrumente und Zeiträume dar, für die wir Kurse erstellen müssen.
Das Schreiben von Kursen erfolgt in Form einer zufälligen Auswahl von Zitaten mit Hilfe eines Zufallszahlengenerators. Bei Bedarf können wir diesen Prozess optimieren. Bei dieser Grundfunktion erfolgt das Schreiben nach einer bestimmten Zeitspanne:
//+------------------------------------------------------------------+ //| Function to write data if present | //| Write quotes to file | //+------------------------------------------------------------------+ void WriteDataIfPresent() { // Declare array to store quotes MqlRates rates[]; ArraySetAsSeries(rates, false); // Select a random chart from those we added to the workspace ChartData Chart = SelectAnyChart(); // If the file name string is not empty if (Chart.FileNameString != "") { // Copy quotes and calculate the real number of bars int copied = CopyRates(Chart.SymbolX, Chart.PeriodX, 1, int((YearsE*(365.0*(5.0/7.0)*24*60*60)) / double(PeriodSeconds(Chart.PeriodX))), rates); // Calculate ideal number of bars int ideal = int((YearsE*(365.0*(5.0/7.0)*24*60*60)) / double(PeriodSeconds(Chart.PeriodX))); // Calculate percentage of received data double Percent = 100.0 * copied / ideal; // If the received data is not very different from the desired data, // then we accept them and write them to a file if (Percent >= 95.0) { // Open file (create it if it does not exist, // otherwise, erase all the data it contained) OpenAndWriteStart(rates, Chart, CommonE); WriteAllBars(rates); // Write all data to file WriteEnd(rates); // Add to end CloseFile(); // Close and save data file } else { // If there are much fewer quotes than required for calculation Print("Not enough data"); } } }
Die Funktion WriteDataIfPresent schreibt Informationen über Kurse aus dem ausgewählten Chart in eine Datei, wenn die kopierten Daten mindestens 95 % der idealen Anzahl von Balken betragen, die anhand der angegebenen Parameter berechnet wurde. Wenn die kopierten Daten weniger als 95% betragen, zeigt die Funktion die Meldung „Not enough data“ (Nicht genug Daten) an. Wenn eine Datei mit dem angegebenen Namen nicht existiert, erstellt die Funktion sie.
Damit dieser Code funktioniert, sollte Folgendes zusätzlich beschrieben werden:
//+------------------------------------------------------------------+ //| ChartData structure | //| Objective: Storing the necessary chart data | //+------------------------------------------------------------------+ struct ChartData { string FileNameString; string SymbolX; ENUM_TIMEFRAMES PeriodX; }; //+------------------------------------------------------------------+ //| Randomindex function | //| Objective: Get a random number with uniform distribution | //+------------------------------------------------------------------+ int Randomindex(int start, int end) { return start + int((double(MathRand())/32767.0)*double(end-start+1)); } //+------------------------------------------------------------------+ //| SelectAnyChart function | //| Objective: View all charts except current one and select one of | //| them to write quotes | //+------------------------------------------------------------------+ ChartData SelectAnyChart() { ChartData chosenChart; chosenChart.FileNameString = ""; int chartCount = 0; long currentChartId, previousChartId = ChartFirst(); // Calculate number of charts while (currentChartId = ChartNext(previousChartId)) { if(currentChartId < 0) { break; } previousChartId = currentChartId; if (currentChartId != ChartID()) { chartCount++; } } int randomChartIndex = Randomindex(0, chartCount - 1); chartCount = 0; currentChartId = ChartFirst(); previousChartId = currentChartId; // Select random chart while (currentChartId = ChartNext(previousChartId)) { if(currentChartId < 0) { break; } previousChartId = currentChartId; // Fill in selected chart data if (chartCount == randomChartIndex) { chosenChart.SymbolX = ChartSymbol(currentChartId); chosenChart.PeriodX = ChartPeriod(currentChartId); chosenChart.FileNameString = "DataHistory" + " " + chosenChart.SymbolX + " " + IntegerToString(CorrectPeriod(chosenChart.PeriodX)); } if (chartCount > randomChartIndex) { break; } if (currentChartId != ChartID()) { chartCount++; } } return chosenChart; }
Dieser Code wird verwendet, um historische Finanzmarktdaten (Kurse) für verschiedene Währungen aus verschiedenen Charts, die im Terminal geöffnet werden können, aufzuzeichnen und zu analysieren.
- Die Struktur ChartData wird verwendet, um Daten über jedes Chart zu speichern, einschließlich Dateiname, Symbol (Währungspaar) und Zeitrahmen.
- Die Funktion „Randomindex(start, end)“ erzeugt eine Zufallszahl zwischen "start" und "end". Mit dieser Funktion wird eine der verfügbaren Charts zufällig ausgewählt.
- SelectAnyChart() durchläuft alle geöffneten und verfügbaren Charts, mit Ausnahme des aktuellen, und wählt dann zufällig einen davon zur Verarbeitung aus.
Die generierten Kurse werden automatisch vom Programm übernommen, woraufhin automatisch nach profitablen Konfigurationen gesucht wird. Die Automatisierung des gesamten Prozesses ist ziemlich komplex, aber ich habe versucht, sie in einem Bild zusammenzufassen:
Abbildung 5

Bei diesem Algorithmus gibt es drei Stufen:
- Deaktiviert.
- Wartend auf Kurse.
- Aktiv.
Wenn der EA für die Aufzeichnung von Kursen noch keine einzige Datei erzeugt hat oder wir alle Kurse aus dem angegebenen Ordner gelöscht haben, dann wartet der Algorithmus einfach darauf, dass sie erscheinen, und hält eine Weile inne. Was unser verbessertes Kriterium betrifft, das ich für Sie im MQL5-Stil implementiert habe, so ist es ebenfalls sowohl für Brute-Force als auch für Optimierung implementiert:
Abbildung 6

Im erweiterten Modus wird der Kurvenfamilienfaktor verwendet, während der Standardalgorithmus nur den Linearitätsfaktor verwendet. Die übrigen Verbesserungen sind zu umfangreich, um sie in diesen Artikel aufzunehmen. Im nächsten Artikel werde ich meinen neuen Algorithmus zum Verbinden von EAs auf der Grundlage der universellen Mehrwährungsvorlage vorstellen. Die Vorlage wird auf einem Chart gestartet, verarbeitet aber alle zusammengeführten Handelssysteme, ohne dass jeder EA auf seinem eigenen Chart gestartet werden muss. Einige seiner Funktionen wurden in diesem Artikel verwendet.
Schlussfolgerung
In diesem Artikel haben wir neue Möglichkeiten und Ideen im Bereich der Automatisierung des Prozesses der Entwicklung und Optimierung von Handelssystemen näher untersucht. Die wichtigsten Errungenschaften sind die Entwicklung eines neuen Optimierungsalgorithmus, die Schaffung eines Mechanismus zur Synchronisierung der Terminals und eines automatischen Optimierers sowie ein wichtiges Optimierungskriterium – der Kurvenfaktor und die Kurvenfamilie. Dadurch können wir die Entwicklungszeit verkürzen und die Qualität der erzielten Ergebnisse verbessern.
Eine wichtige Ergänzung ist auch die Familie der konkaven Kurven, die ein realistischeres Gleichgewichtsmodell im Zusammenhang mit umgekehrten Vorwärtsperioden darstellen. Durch die Berechnung des Anpassungsfaktors für jede Kurve können wir die optimalen Einstellungen für den automatisierten Handel genauer auswählen.
Links
- Brute-Force-Ansatz zur Mustersuche (Teil V): Neuer Blickwinkel
- Brute-Force-Ansatz zur Mustersuche (Teil IV): Minimale Funktionalität
- Brute-Force-Ansatz zur Mustersuche (Teil III): Neue Horizonte
- Brute-Force-Ansatz zur Mustersuche (Teil II): Immersion
- Brute-Force-Ansatz für die Mustersuche
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/9305
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.