
Neuronale Netze leicht gemacht (Teil 51): Behavior-Guided Actor-Critic (BAC)

Einführung
Die letzten beiden Artikel waren dem Soft Actor-Critic-Algorithmus gewidmet. Wie Sie sich erinnern, wird der Algorithmus zum Trainieren stochastischer Modelle in einem kontinuierlichen Aktionsraum verwendet. Das Hauptmerkmal dieser Methode ist die Einführung einer Entropiekomponente in die Belohnungsfunktion, die es uns ermöglicht, das Gleichgewicht zwischen Umwelterkundung und Modellbetrieb anzupassen. Gleichzeitig bringt dieser Ansatz einige Einschränkungen für die trainierten Modelle mit sich. Die Verwendung der Entropie erfordert eine gewisse Vorstellung von der Wahrscheinlichkeit von Handlungen, die sich für einen kontinuierlichen Raum von Handlungen nur schwer direkt berechnen lässt.
Wir haben einen Ansatz der Quantilsverteilung verwendet. Hier fügen wir die Anpassung der Hyperparameter der Quantilsverteilung hinzu. Schon der Ansatz, die Quantilsverteilung zu verwenden, entfernt uns ein wenig vom kontinuierlichen Aktionsraum. Schließlich haben wir jedes Mal, wenn wir eine Aktion ausgewählt haben, ein Quantil aus der gelernten Wahrscheinlichkeitsverteilung ausgewählt und dessen Durchschnittswert als Aktion verwendet. Bei einer hinreichend großen Anzahl von Quantilen und einem hinreichend kleinen Bereich möglicher Werte nähern wir uns einem kontinuierlichen Aktionsraum. Dies führt jedoch zu einer zunehmenden Komplexität des Modells und zu einem Anstieg der Kosten für seine Ausbildung und seinen Betrieb. Außerdem werden dadurch Einschränkungen bei der Architektur der trainierten Modelle auferlegt.
In diesem Artikel geht es um einen alternativen Ansatz, die verhaltensgesteuerte Akteurskritik (Behavior-Guided Actor-Critic, BAC), die im April 2021 eingeführt wurde.
1. Merkmale der Algorithmenkonstruktion
Lassen Sie uns zunächst über die Notwendigkeit sprechen, die Umgebung im Allgemeinen zu untersuchen. Ich denke, alle sind sich einig, dass dieser Prozess notwendig ist. Aber wofür genau und in welchem Stadium?
Lassen Sie uns mit einem einfachen Beispiel beginnen. Angenommen, wir befinden uns in einem Raum mit drei identischen Türen und müssen auf die Straße gehen. Was sollen wir tun? Wir öffnen die Türen eine nach der anderen, bis wir die richtige gefunden haben. Wenn wir denselben Raum wieder betreten, öffnen wir nicht mehr alle Türen, um nach draußen zu gelangen, sondern gehen sofort zu dem bereits bekannten Ausgang. Wenn wir eine andere Aufgabe haben, dann sind einige Optionen möglich. Wir können wieder alle Türen öffnen, bis auf den Ausgang, den wir schon kennen, und nach dem richtigen suchen. Oder wir können uns erst einmal daran erinnern, welche Türen wir früher auf der Suche nach einem Ausweg geöffnet haben und ob die, die wir brauchen, darunter war. Wenn wir uns an die richtige Tür erinnern, gehen wir auf sie zu. Ansonsten prüfen wir die Türen, die wir noch nicht ausprobiert haben.
Schlussfolgerung: In einer ungewohnten Situation müssen wir die Umgebung studieren, um das richtige Verhalten zu wählen. Nachdem die gewünschte Route gefunden wurde, kann eine weitere Erkundung der Umgebung nur hinderlich sein.
Wenn sich jedoch die Aufgabe in einem bekannten Zustand ändert, müssen wir möglicherweise zusätzlich die Umgebung untersuchen. Dazu kann auch die Suche nach einer optimaleren Route gehören. Im obigen Beispiel könnte dies der Fall sein, wenn wir durch mehrere Räume gehen müssen oder uns auf der falschen Seite des Gebäudes befinden.
Daher benötigen wir einen Algorithmus, der es uns ermöglicht, die Erkundung der Umgebung in unerforschten Zuständen zu verbessern und in bereits erforschten Zuständen zu minimieren.
Die Entropie-Regularisierung, die in Soft Actor-Critic verwendet wird, kann diese Anforderung erfüllen, allerdings nur unter einer Reihe von Bedingungen. Die Entropie einer Handlung ist hoch, wenn die Handlungswahrscheinlichkeit gering ist. In der Tat ist der Zustand, in den wir nach einer Handlung mit geringer Wahrscheinlichkeit eintreten, wahrscheinlich kaum bekannt. Die Entropie-Regularisierung zwingt uns, den Vorgang zu wiederholen, um nachfolgende Zustände besser untersuchen zu können. Aber was passiert nach der Untersuchung dieses Bewegungsvektors? Wenn wir einen optimaleren Weg gefunden haben, steigt beim Training des Modells die Handlungswahrscheinlichkeit und die Entropie sinkt. Dies entspricht unseren Anforderungen. Die Wahrscheinlichkeit anderer Handlungen sinkt jedoch und ihre Entropie steigt. Dies veranlasst uns zu weiteren Forschungen in andere Richtungen. Nur ein hohes Maß an positiver Belohnung kann uns auf diesem Weg halten.
Entspricht die neue Route hingegen nicht unseren Anforderungen, so verringern wir die Wahrscheinlichkeit einer solchen Aktion beim Training des Modells. Gleichzeitig nimmt die Entropie noch mehr zu, was uns dazu veranlasst, es erneut zu tun. Nur eine erhebliche negative Belohnung (Strafe) kann uns davon abhalten, erneut einen unüberlegten Schritt zu tun.
Deshalb ist die richtige Gewichtung des Temperaturverhältnisses sehr wichtig, um das gewünschte Gleichgewicht zwischen Erkundung und Betrieb des Modells zu gewährleisten.
Dies mag ein wenig seltsam erscheinen. Wir begannen mit der Strategie ε-Greedy, bei der das Gleichgewicht zwischen Erkundung und Nutzung durch eine Wahrscheinlichkeitskonstante geregelt wurde. Jetzt verkomplizieren wir das Modell und sprechen erneut über die Bedeutung der Wahl eines Verhältnisses. Dies ist ein reines Déjà-vu.
Auf der Suche nach einer anderen Lösung wenden wir uns dem Algorithmus Behavior-Guided Actor-Critic (BAC) zu, der in dem Artikel „Behavior-Guided Actor-Critic: Improving Exploration via Learning Policy Behavior Representation for Deep Reinforcement Learning“ vorgestellt wird. Die Autoren der Methode schlagen vor, die Entropiekomponente in der Belohnungsfunktion durch einen bestimmten Wert zu ersetzen, um den Grad des Lernens durch ein Zustands-Aktionspaar-Modell zu bewerten.
Die Wahl des Zustands-Aktions-Paares liegt auf der Hand - dies ist das, was wir zu einem bestimmten Zeitpunkt wissen. Wenn wir uns in einem bestimmten Zustand befinden, entscheiden wir uns für eine Handlung. In gewisser Weise hängen unser Übergang zum nächsten Zustand und die Belohnung für diesen Übergang davon ab. Hinter ein und derselben Handlung kann ein Übergang zum erwarteten neuen Zustand oder ein anderer Zustand (mit einer gewissen Wahrscheinlichkeit) stehen. Um zum Beispiel eine Tür zu öffnen, müssen wir uns ihr nähern. Hier wird erwartet, dass wir nach jedem Schritt näher an die Tür kommen. Dann öffnen wir sie durch Drehen des Türgriffs. Es kann sich jedoch herausstellen, dass sie gesperrt ist (ein Faktor, auf den wir keinen Einfluss haben). Vor der Tür wartet eine Belohnung oder eine Geldstrafe auf uns. Aber das werden wir erst wissen, wenn wir dort sind. Wir können also nur dann von einer vollständigen Untersuchung eines einzelnen Zustands sprechen, wenn wir alle möglichen Handlungen von diesem Zustand aus betrachten.
Die Autoren der Methode schlagen vor, einen Autoencoder als Maß für die Untersuchung des Paares „Zustand-Aktion“ zu verwenden. Wir sind bereits mehrfach auf die Verwendung von Autoencodern in verschiedenen Algorithmen gestoßen. Dies war jedoch immer mit einer Datenkomprimierung oder der Konstruktion bestimmter Abhängigkeitsmodelle verbunden. Die Erfahrung zeigt, dass die Erstellung von Finanzmarktmodellen aufgrund der großen Anzahl von Einflussfaktoren, die nicht immer offensichtlich sind, eine recht schwierige Aufgabe ist. In diesem Fall wird eine andere Eigenschaft des Autoencoders verwendet.
Ein Autoencoder in seiner reinen Form kopiert die Quelldaten recht gut. Aber ein Autoencoder ist ein neuronales Netz. Ganz am Anfang habe ich gesagt, dass neuronale Netze nur bei untersuchten Daten gut funktionieren. Andernfalls können ihre Ergebnisse unvorhersehbar sein. Aus diesem Grund konzentrieren wir uns stets auf die Repräsentativität der Trainingsstichprobe und die Unveränderlichkeit der Modellhyperparameter während des Trainings und des Betriebs.
Die Autoren der Methode haben sich diese Eigenschaft neuronaler Netze zunutze gemacht. Nach dem Training mit einer bestimmten Menge von Zuständen und entsprechenden Aktionen erhalten wir eine gute Kopie davon am Ausgang des Autoencoders. Sobald wir jedoch ein unbekanntes Paar von „Zustands-Aktion“ an die Modelleingabe übermitteln, wird der Fehler beim Kopieren der Daten stark zunehmen. Es ist der Fehler beim Kopieren von Daten, den wir als Maß für die Kenntnis eines separaten Paares „Zustand-Aktion“ verwenden werden.
Dieser Ansatz hat eine Reihe von Vorteilen gegenüber der Entropie-Regularisierung. Erstens ist dieser Ansatz sowohl auf stochastische als auch auf deterministische Modelle anwendbar. Die Verwendung eines Autoencoders hat keinen Einfluss auf die Wahl der Actor-Architektur.
Zweitens nimmt die Anreizbelohnung desPaares „Zustand-Aktion“ mit dem Training ab, unabhängig von der erhaltenen Belohnung und der Wahrscheinlichkeit, die Handlung in der Zukunft auszuführen. Wenn der Autoencoder trainiert wird, tendiert er gegen „0“, was zur vollen Funktionsfähigkeit des Modells führt.
Wenn jedoch ein neuer Zustand eintritt (der angesichts der Generalisierungsfähigkeit neuronaler Netze nicht mit den zuvor untersuchten Zuständen vergleichbar ist), wird der Modus zur Erkundung der Umgebung sofort aktiviert.
Die stimulierende Belohnung eines Paares „Zustand-Aktion“ ist absolut unabhängig vom Grad des Trainings, der Ausführungswahrscheinlichkeit oder anderen Faktoren einer anderen Aktion im selben Zustand.
Natürlich haben wir es mit einem kontinuierlichen Raum von Aktionen zu tun, und das Modell ist in der Lage, die gewonnenen Erfahrungen zu verallgemeinern. Bei der Untersuchung eines Paares „Zustand-Aktion“ kann es zuvor gesammelte Erfahrungen auf ähnliche Zustände und ähnliche Aktionen anwenden. Gleichzeitig ändert sich aber auch der Datenübertragungsfehler ständig und hängt von der Nähe (Ähnlichkeit) der Zustände und Aktionen ab.
Mathematisch lässt sich das Policy-Training wie folgt darstellen:
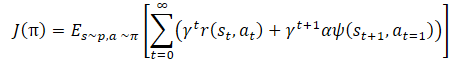
wobei γ ein Diskontierungsfaktor ist,
α — Temperaturverhältnis,
ψ(St+1,At=1) — Funktion des nachfolgenden Zustandsverhaltens (Fehler beim Kopieren durch den Autoencoder).
Auch hier zeigt sich, dass das Temperaturverhältnis das Gleichgewicht zwischen Erkundung und Ausbeutung des Modells regelt. Dies führt wiederum zu den oben beschriebenen Schwierigkeiten bei der Abstimmung der Hyperparameter und der Modelltraining. Die Autoren der Methode schlugen vor, die Trainingsfunktion der Politik leicht zu ändern:
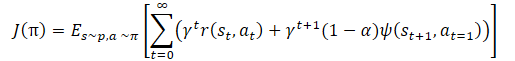
Das α-Temperaturverhältnis selbst sollte anhand der folgenden Gleichung bestimmt werden:
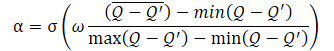
wobei σ die Sigmoidfunktion ist,
ω ist gleich 10,
Q — neuronales Netz zur Bewertung der Handlungsqualität.
Das hier verwendete neuronale Netz Q ist analog zu einem Kritiker und bewertet die Qualität einer Handlung in einem bestimmten Zustand unter Berücksichtigung der aktuellen Politik.
Wie aus der vorgestellten Gleichung hervorgeht, liegt das Temperaturverhältnis (1-α) zwischen 0 und 0,5. Sie nimmt zu, wenn sich die Bewertung der Qualität der Maßnahme verbessert. Offensichtlich tendiert in diesem Moment der Fehler beim Kopieren der Daten durch den Autoencoder gegen „0“. Mit hoher Wahrscheinlichkeit befindet sich das Modell derzeit in einer Art lokalem Minimum, und die Untersuchung der Umwelt kann helfen, aus diesem Zustand herauszukommen.
Wenn die Genauigkeit der Datenübernahme gering ist, sinkt auch die Qualität der Bewertung der Handlung in einem bestimmten Zustand. Dies führt zu einer Vergrößerung des Nenners des Ausdrucks innerhalb der Sigmoidfunktion. Dementsprechend sinkt der Gesamtwert des sigmoiden Arguments, und sein Ergebnis tendiert gegen 0,5.
Denken Sie daran, dass wir hier immer den kleineren Fehler vom größeren subtrahieren. Daher ist das sigmoide Argument immer größer als „0“. Sie ist fast nie gleich „0“, da man nicht durch „0“ teilen kann.
Der vorgestellte Algorithmus gehört zur großen Familie der Algorithmen von Actor-Critic und nutzt die allgemeinen Ansätze dieser Algorithmenfamilie. Wie Soft Actor-Critic wird der Algorithmus verwendet, um Akteurspolitiken in einem kontinuierlichen Aktionsraum zu lernen. Wir werden 2 Modelle von Critics verwenden, um die Qualität der Aktion und die Verteilung des Fehlergradienten von der Belohnung zur Aktion zu bewerten. Wir werden auch das Soft Updating von Zielmodellen, einen Erfahrungspuffer und andere allgemeine Ansätze zum Training von Actor-Critic-Modellen verwenden.
2. Implementierung mit MQL5
Nachdem wir die theoretischen Aspekte des vorgeschlagenen Ansatzes betrachtet haben, wollen wir ihn mit MQL5 umsetzen. Zunächst einmal geht es um die Architektur der Modelle. Um die Methoden vergleichbar zu machen, habe ich die Architektur der Modelle gegenüber dem vorigen Artikel nicht wesentlich verändert. Allerdings habe ich die Actor-Architektur ein wenig vereinfacht und die komplexe letzte neuronale Schicht entfernt, die wir zur Implementierung des stochastischen Actor-Algorithmus aus der Soft Actor-Critic-Methode erstellt haben. Ich habe jedoch die Verwendung der stochastischen Akteurspolitik beibehalten. Diesmal wird dies jedoch durch die Verwendung der latenten Zustandsschicht des Variations-Autoencoders erreicht. Wie Sie sich erinnern, wird die Eingabe dieser neuronalen Schicht mit einem Datentensor versorgt, der genau doppelt so groß ist wie ihr Ergebnispuffer. Der angegebene Quelldatentensor enthält den Mittelwert und die Varianz der Verteilung für jedes Element der Ergebnisse. Auf diese Weise reduzieren wir den Rechenaufwand, belassen aber das stochastische Akteursmodell in einem kontinuierlichen Handlungsraum.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *autoencoder) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!autoencoder) { autoencoder = new CArrayObj(); if(!autoencoder) return false; } //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2*NActions; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Modell von Critic wurde ohne Änderungen übernommen, und wir werden uns nicht weiter damit befassen.
Lassen Sie uns ein wenig über das Autoencoder-Modell sprechen. Wie bereits erwähnt, wird der Autoencoder als Speicherelement für die zuvor diskutierten Paare „Zustand-Action“ verwendet. Wir können es den Zähler der Anzahl der Besuche dieser Paare nennen. Aber vergessen wir nicht, dass unsere Kritiker die Paare „Zustand-Action“ bewerten. Genauer gesagt, bewertet der Kritiker eine einzelne Handlung in einem bestimmten Zustand. Dies mag wie ein Wortspiel erscheinen, aber es gibt einen Satz von Ausgangsdaten.
Um Ressourcen und Zeit für das Training der Modelle zu sparen, haben wir den Block zur Vorverarbeitung der Quelldaten aus der Critics-Architektur ausgeschlossen. Stattdessen verwenden wir bereits verarbeitete Daten aus dem verborgenen Zustand des Actor-Modells. Am Eingang des Critic verknüpfen wir den verborgenen Zustand und den Ergebnispuffer des Actors und kombinieren so den Zustand und die Aktion zu einem Tensor.
Jetzt werden wir noch weiter gehen. Wir werden den versteckten Zustand eines der Kritiker als Eingabe für unseren Autoencoder verwenden. Ähnlich wie beim Critic könnten wir eine Verkettungsschicht aus zwei Tensoren der Originaldaten verwenden. Aber dann müssten wir das Problem des Vergleichs von 1 Puffer mit Autoencoder-Ergebnissen mit 2 Puffern mit Quelldaten lösen. Die Verwendung eines Puffers von Quelldaten aus der latenten Repräsentation des Critic ermöglicht es uns, ein einfacheres Autoencoder-Modell zu verwenden und die Quelldaten mit den Ergebnissen seiner Arbeit "1:1" zu vergleichen. Daher werden wir in der Autoencoder-Architektur nur vollständig verbundene Schichten verwenden.
//--- Autoencoder autoencoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 20; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(2)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(1)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(0)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- return true; }
Bitte beachten Sie, dass wir ab der vierten Schicht des Autoencoders keine vollständige Beschreibung der neuen neuronalen Schichten erstellt haben. Stattdessen haben wir einfach die zuvor erstellten Beschreibungen in umgekehrter Reihenfolge kopiert. Dadurch konnten wir eine Spiegelung des Encoders im Decoder erstellen. Alle Änderungen in der Encoder-Architektur (außer dem Hinzufügen neuer Ebenen) werden sofort in den entsprechenden Decoder-Ebenen berücksichtigt. Die Beschreibung der Architekturen neuronaler Schichten kann in verschiedenen Fällen auf recht bequeme Weise synchronisiert werden.
Nach der Erstellung einer Beschreibung der Modellarchitektur gehen wir dazu über, den Prozess der Sammlung einer Datenbank von Beispielen für das Training des Modells zu organisieren. Wie zuvor ist dieser Prozess in der EA „..\BAC\Research.mq5“ organisiert. Bei der BAC-Methode wird der Algorithmus für die primäre Datenerfassung nicht verändert. Daher waren die Änderungen in diesem EA minimal.
Wir haben die Funktion der Beschreibung der Modellarchitektur geändert, indem wir ihr eine Beschreibung des Autoencoders hinzugefügt haben. Beim Aufruf dieser Funktion in der OnInit-Methode des EA Research.mq5 müssen wir daher drei Zeiger auf dynamische Arrays mit Beschreibungen der Modellarchitektur übergeben. Da wir in diesem EA aber nur den Actor verwenden und keine Beschreibung anderer Modelle benötigen, erstellen wir kein zusätzliches Array von Objekten, sondern verweisen zweimal auf das Array der Beschreibungen der Architektur des Critic. Bei einem solchen Aufruf wird zunächst eine Beschreibung der Architektur des Critic in der Funktion erstellt, dann wird sie gelöscht und die Architektur des Autoencoders in das Array geschrieben. In diesem Fall ist dies für uns unkritisch, da weder das Kritiker- noch das Autoencodermodell verwendet wird.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Darüber hinaus schließen wir die Entropiekomponente aus der Belohnungsfunktion aus. Der Rest des Expert Advisor-Codes blieb unverändert. Den vollständigen Code des EA und alle seine Funktionen finden Sie im Anhang.
Der EA-Code für das Modeltraining „..\BAC\Study.mq5“ erforderte mehr Arbeit. Hier verwenden und initialisieren wir alle Modelle. Daher wird vor dem Aufruf der Methode zur Erstellung einer Beschreibung der Modellarchitektur ein zusätzliches dynamisches Array für den Autoencoder erstellt.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Autoencoder.Load(FileName + "AEnc.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *autoencoder = new CArrayObj(); if(!CreateDescriptions(actor, critic, autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
Nachdem wir die Modellarchitektur erhalten haben, initialisieren wir alle Modelle und steuern die Operationen.
if(!Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Autoencoder.Create(autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
Vergessen Sie nicht die Zielmodelle der Kritiker.
if(!TargetCritic1.Create(critic) || !TargetCritic2.Create(critic)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; } delete actor; delete critic; delete autoencoder; //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1.0f); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1.0f); }
Stellen wir danach sicher, dass wir alle Modelle in einen OpenCL-Kontext übertragen. Autoencoder ist da keine Ausnahme.
OpenCL = Actor.GetOpenCL(); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Autoencoder.SetOpenCL(OpenCL);
Als Nächstes kommt der Block zur Überprüfung der Modellkorrespondenz.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Hier fügen wir eine Prüfung auf Konsistenz zwischen den Autoencoder- und Critic-Architekturen hinzu:
Critic1.GetLayerOutput(1, Result); latent_state = Result.Total(); Autoencoder.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Autoencoder doesn't match latent state Critic (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Am Ende der Methode initialisieren wir, wie zuvor, den Hilfspuffer und rufen das Modelltrainingsevent auf:
Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Vielleicht fällt Ihnen auf, dass wir für die Funktion der dynamischen Berechnung des Temperaturverhältnisses kein zusätzliches Modell zur Bewertung der Qualität der Maßnahmen erstellt haben. Ich habe betont, dass die Funktionsweise dieses Modells der Arbeit des Kritikers ähnlich ist. Um den gesamten Trainingsprozess zu vereinfachen, werden wir die Modelle unserer Kritiker bei der Implementierung der dynamischen Berechnung des Temperaturverhältnisses verwenden.
Vergessen Sie nach der Erstellung der Modelle nicht, die trainierten Modelle in der OnDeinit-Deinitialisierungsmethode des EA zu speichern. Dabei achten wir auf den Erhalt aller Modelle, sowie auf die Suffixe der Dateinamen und die entsprechenden Modelle, die beim Download angegeben werden:
void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Autoencoder.Save(FileName + "AEnc.nnw", Autoencoder.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
An diesem Punkt ist die Vorarbeit abgeschlossen, und wir können mit der Implementierung des Algorithmus für das direkte Modelltraining in der Train-Methode unseres EA fortfahren.
Der Beginn der Methode ist ziemlich standardisiert. Wie zuvor führen wir einen Trainingszyklus mit der in den externen EA-Parametern angegebenen Anzahl von Iterationen durch:
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Im Hauptteil der Schleife wird eine zufällige Trajektorie aus der Beispieldatenbank und ein bestimmter Trajektorienschritt bestimmt. Dann laden wir Informationen über den nachfolgenden Zustand in die Datenpuffer:
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
Als Nächstes führen wir einen Vorwärtsdurchlauf der Modelle Actor und 2 Target Critics durch, um den Wert des zukünftigen Zustands unter Berücksichtigung der aktualisierten Actor-Strategie zu bestimmen:
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) - Buffer[tr].Revards[i + 1]);
Auf den ersten Blick ist alles gleich wie beim Soft Actor-Critic-Algorithmus. Wir verwenden auch die von zwei Kritikern erhaltene Mindestzustandsbewertung. Beachten Sie jedoch, dass wir die Entropiekomponente ausgeschlossen haben. Dies ist in Anbetracht der Anwendung der BAC-Methode nur logisch. Eine Verhaltenskomponente haben wir jedoch nicht hinzugefügt. Dies ist eine bewusste Abweichung vom ursprünglichen Algorithmus. Wir verwenden nämlich eine Datenbank mit Beispielen, die aus den Durchläufen von Akteuren mit verschiedenen Politiken hervorgegangen sind. Die Einführung einer Verhaltenskomponente verzerrt zwar die Bewertung des Kritikers, stimuliert aber nicht direkt den Akteur. Später werden wir eine indirekte Stimulation des Akteurs erhalten, wenn er auf der Grundlage der Beurteilungen der Kritiker trainiert wird. Aber es gibt auch eine andere Seite der Medaille. Wie oft wird das Paar „Zustand-Aktion“ beim Training eines Critics verwendet und wie oft das gleiche oder ein ähnliches Paar „Zustand-Aktion“ beim Training eines Actors? Eine Voreingenommenheit zugunsten der einen oder anderen Richtung ist möglich. Deshalb habe ich beschlossen, den Autoencoder zu verwenden, um Zustände und Aktionen beim Training des Actors zu schätzen. Ich bin davon überzeugt, dass dies eine genauere Bewertung der Häufigkeit der Besuche der Zuständen und der vom Akteur angewandten Maßnahmen ermöglichen wird, wobei die Aktualisierung seiner Verhaltenspolitik berücksichtigt wird.
Die nächste Stufe ist das Training der Kritiker. Wir laden die Daten des ausgewählten Zustands aus der Beispieldatenbank in die Datenpuffer:
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Update(0, (Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Update(1, Buffer[tr].States[i].account[1] / PrevBalance); Account.Update(2, (Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Update(3, Buffer[tr].States[i].account[2]); Account.Update(4, Buffer[tr].States[i].account[3]); Account.Update(5, Buffer[tr].States[i].account[4] / PrevBalance); Account.Update(6, Buffer[tr].States[i].account[5] / PrevBalance); Account.Update(7, Buffer[tr].States[i].account[6] / PrevBalance); x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); Account.BufferWrite();
Nun ist es an der Zeit, den direkten Durchgang des Akteurs zu vollziehen. Ich möchte Sie daran erinnern, dass wir sie in diesem Fall für die vorläufige Verarbeitung von Ausgangsdaten über den Zustand der Umgebung verwenden:
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Dann müssen wir einen Vorwärts- und Rückwärtsdurchlauf der Critics durchführen, um ihre Parameter anzupassen. Beim Training der Modelle mit der Soft-Actor-Critic-Methode haben wir die Modelle gewechselt. In diesem Fall trainieren wir beide Critics gleichzeitig mit denselben Beispielen. Wir rufen die Direktübergabemethoden von Critics für Aktionen aus der Beispieldatenbank auf:
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Doch bevor wir den umgekehrten Durchlauf machen, bereiten wir die Daten vor, um das Temperaturverhältnis der Verhaltenskomponente unserer Belohnungsfunktion zu berechnen. Zunächst vergleichen wir die Ergebnisse der ersten kritischen Schätzung mit der oben berechneten Schätzung des zukünftigen Zustands und aktualisieren die minimalen, maximalen und durchschnittlichen Fehlerwerte.
Beachten Sie, dass wir bei der ersten Iteration einfach den aktuellen Fehler auf alle drei Variablen übertragen. Dann aktualisieren wir das Maximum und Minimum auf der Grundlage der Vergleichsergebnisse. Dann berechnen wir den exponentiellen Durchschnitt:
Critic1.getResults(Result); float error = reward - Result[0]; if(iter == 0) { MaxCriticError = error; MinCriticError = error; AvgCriticError = error; } else { MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error; }
Für den zweiten Critic haben wir bereits die Anfangswerte der Variablen. Wir aktualisieren ihre Werte unabhängig von der Trainingsiteration des Modells:
Critic2.getResults(Result); error = reward - Result[0]; MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error;
Am Ende der Aktualisierung der Parameter der kritischen Modelle müssen wir nur noch einen Rückwärtsdurchlauf beider Modelle durchführen, wobei wir die minimale Schätzung des zukünftigen Zustands aus den Zielmodellen als Referenzwert angeben:
Result.Update(0, reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Damit ist die Aktualisierung der Parameter der Kritiker abgeschlossen, und wir fahren mit dem Training des Actors fort. Die Autoren der BAC-Methode für das Training des Actors empfehlen, den Critic mit einer minimalen Bewertung der ausgewählten Aktion einzusetzen. Um einen direkten Durchlauf durch zwei Kritiker und den Vergleich ihrer Ergebnisse zu vermeiden, werden wir die Dinge etwas anders angehen. Wir wählen den Kritiker mit dem geringsten durchschnittlichen Fehler bei der Vorhersage der Zustands- und Handlungsbewertung. Dieser Wert wird bei jedem Rückwärtsdurchlauf des Kritik-Modells neu geschätzt. Seine Gewinnung ist mit minimalen Kosten verbunden, die im Vergleich zu einem direkten Durchgang durch das Modell vernachlässigbar sind.
Um zu vermeiden, dass komplexe verzweigte Strukturen mit der Wiederholung von Aktionen für ein und das zweite Critic-Modell entstehen, speichern wir einfach den Zeiger auf das gewünschte Modell in einer lokalen Variablen. Dann werden wir mit dieser lokalen Variable arbeiten:
//--- Policy study CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
Im Gegensatz zu TD3 aktualisieren die Actor-Critic-Methoden die Actor-Politik bei jeder Iteration. Wir verwenden die gleichen Ausgangsdaten, die wir für das Training der Kritiker ausgewählt haben. Ich möchte Sie daran erinnern, dass wir beim Training von Critics bereits einen direkten Durchlauf des Actors mit dem aktuellen Satz von Ausgangsdaten durchgeführt haben. Daher reicht es aus, einen direkten Durchlauf des ausgewählten Kritikers durchzuführen, um die Aktionen des Akteurs im aktuellen Zustand zu bewerten, wobei die Aktualisierung seiner Politik berücksichtigt wird:
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Autoencoder.feedForward(critic, 1, NULL, -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Nach dem Vorwärtsdurchlauf des Critic, führen wir einen Vorwärtsdurchlauf des Autoencoders durch. Hier ist eine Nuance. Bei der Verknüpfung der beiden Modelle zu einem Ganzen haben wir nämlich zuvor die Quelldatenschicht des nachfolgenden Modells durch den Zeiger auf die latente Schicht des Modells ersetzt, das diese Quelldaten liefert. Dies funktioniert hervorragend, wenn wir einen Akteur als Spender für zwei Kritiker verwenden. Während der ersten Iteration entfernt Critics die unnötige Quelldatenschicht und speichert einen Zeiger auf die latente Zustandsschicht des Actors. Im Fall von Autoencoder ist die Situation umgekehrt. Wir verwenden 2 Critic-Modelle als Spender für einen Autoencoder. Bei der ersten Iteration entfernt der Autoencoder die unnötige Schicht der Originaldaten und speichert einen Zeiger auf die latente Schicht des verwendeten Critic. Wenn Sie jedoch den Kritiker wechseln, wird die Ebene des einen Kritikers gelöscht und der Zeiger auf die Ebene des anderen Kritikers gespeichert. Dieser Prozess ist für uns äußerst unerwünscht. Außerdem schadet es unserer gesamten Ausbildung. Daher müssen wir nach dem ersten Löschen der Quelldatenschicht das Objektlöschkennzeichen bei der Aktualisierung des Arrays der neuronalen Schicht deaktivieren:
bool CNet::feedForward(CNet *inputNet, int inputLayer = -1, CNet *secondNet = NULL, int secondLayer = -1) { ........ ........ //--- if(layer.At(0) != neuron) if(!layer.Update(0, neuron)) { if(del_second) delete second; return false; } else layer.FreeMode(false); //--- ........ ........ //--- return true; }
Dies ist eine kleine Abweichung vom Trainingsprozess und dem BAC-Algorithmus, aber es ist entscheidend für unsere Implementierung des Prozessdesigns.
Kehren wir nun zum Algorithmus unserer Trainingsmethode des Modells Train zurück. Nach einem direkten Durchlauf des Autoencoders müssen wir den Fehler beim Kopieren der Daten bewerten. Dazu laden wir das Ergebnis des Autoencoders und die Ausgangsdaten aus dem latenten Zustand des Critic. Um die Effizienz unseres Codes zu erhöhen, werden wir Vektorvariablen verwenden, in die beide Datenpuffer geladen werden:
Autoencoder.getResults(AutoencoderResult);
critic.GetLayerOutput(1, Result);
Result.GetData(CriticResult);
Hier werden wir sofort die Ergebnisse der kritischen Bewertung der Aktionen hochladen:
critic.getResults(Result);
Wir benötigen beide Informationsströme, um den Zielwert für das Training der Actor-Politik zu bestimmen. Daher werden wir die gesamte Berechnung in einem Block zusammenfassen.
Zuvor haben wir Daten für die Berechnung des Temperaturverhältnisses vorbereitet. Nun berechnen wir zunächst das sigmoide Argument. Dann bestimmen wir den Wert der Funktion und ziehen ihn von „1“ ab:
float alpha = (MaxCriticError == MinCriticError ? 0 : 10.0f * (AvgCriticError - MinCriticError) / (MaxCriticError - MinCriticError)); alpha = 1.0f / (1.0f + MathExp(-alpha)); alpha = 1 - alpha; reward = Result[0]; reward = (reward > 0 ? reward + PoliticAdjust : PoliticAdjust); reward += AutoencoderResult.Loss(CriticResult, LOSS_MSE) * alpha;
Als Nächstes verschieben wir, ähnlich wie in TD3, die Parameter des Akteurs in Richtung Steigerung der Rentabilität der Operationen. Daher fügen wir der aktuellen Bewertung der Maßnahme eine kleine Konstante hinzu, die eine Verschiebung der Gradienten in Richtung einer steigenden Rentabilität bewirkt.
Um die Bildung des Zielwertes zu vervollständigen, fügen wir die Verhaltenskomponente unter Berücksichtigung der Verlustfunktion des Autoencoders hinzu. Dank der Vektoroperationen wird die Größe der Verlustfunktion buchstäblich in einem einzigen String definiert, unabhängig von der Größe der Datenpuffer.
Nach der Erzeugung des Zielwerts können wir nun einen umgekehrten Durchlauf des Critic und des Actor durchführen, um den Fehlergradienten vor der Aktion und der anschließenden Anpassung der Parameter des Actor zu verteilen.
Um eine gegenseitige Anpassung der Parameter von Critic und Actor zu verhindern, schalten wir den Trainingsmodus des Critic vor dem Rückwärtsdurchgang aus und nach der Durchführung der Operationen wieder ein:
Result.Update(0, reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
Beachten Sie, dass wir zwei Arten des Rückwärtsdurchgangs für den Akteur durchführen. Zunächst verteilen wir den Fehlergradienten auf die Datenvorverarbeitungseinheit, was uns eine Feinabstimmung der Filter der Faltungsschichten auf der Grundlage der Anforderungen der Kritiker ermöglicht. Dann führen wir einen Rückwärtsdurchlauf durch, um den Entscheidungsblock bei der Wahl einer bestimmten Aktion anzupassen. Es ist sehr wichtig, dass die Vorgänge in dieser Reihenfolge durchgeführt werden. Nach einem vollständigen Vorwärtsdurchlauf mit Anpassung der Parameter des Entscheidungsblocks werden auch die Fehlergradienten für den Datenvorverarbeitungsblock neu geschrieben. In diesem Fall hat der Aufruf eines zusätzlichen Rücklaufs keine positiven Auswirkungen. Außerdem kann sie auch negative Auswirkungen haben.
In diesem Stadium haben wir die Parameter von Critics und Actor aktualisiert. Wir müssen nur noch die Autoencoder-Parameter aktualisieren. Hier ist alles ganz einfach. Wir übergeben die latenten Zustandsdaten des Critic als Referenzwerte und führen einen Rückwärtsdurchlauf durch das Modell durch:
//--- Autoencoder study Result.AssignArray(CriticResult); if(!Autoencoder.backProp(Result, critic, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Am Ende der Iterationen des Trainingszyklus aktualisieren wir die Zielmodelle der beiden Kritiker und informieren den Nutzer über den Fortschritt des Trainings:
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Das Ende der Ausbildungsmethode ist ziemlich konventionell:
- Löschen des Kommentarfelds,
- Anzeigen der Trainingsergebnisse,
- Einleiten des Endes der Arbeit des EA einleiten.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Der vollständige Code der EA-Training und alle verwendeten Programme sind im Anhang zu finden. Dort finden Sie auch den Code für den Test-EA, der fast unverändert aus dem vorherigen Artikel übernommen wurde. Lediglich die Entropiekomponente wurde im EA-Code entfernt, wobei die durchlaufene Flugbahn beibehalten wurde.
Damit ist die Arbeit an der Erstellung von EAs abgeschlossen, und wir können mit dem Testen der geleisteten Arbeit und dem Training von Modellen fortfahren.
Meiner Meinung nach führte die Arbeit zu einer ziemlich großen Anzahl von Iterationen des Datenaustauschs zwischen dem Hauptspeicher und dem OpenCL-Kontext. Dies macht sich in dem Block zur Bestimmung der Verhaltenskomponente der Belohnungsfunktion bemerkbar. Hier gibt es einiges zu bedenken. Schauen wir uns an, wie sich dies auf die Gesamtleistung der Modelltraining auswirkt.
3. Test
Wir haben bei der Implementierung des Algorithmus Behavior-Guided Actor-Critic eine beeindruckende Arbeit geleistet, und nun ist es an der Zeit, die Ergebnisse zu betrachten. Wie zuvor wurden die Modelle auf EURUSD H1 für die ersten 5 Monate des Jahres 2023 trainiert. Alle Indikatorparameter werden standardmäßig verwendet. Das Anfangsguthaben beträgt 10.000 USD.
In der ersten Phase wurde eine Trainingsmenge von 300 Zufallsdurchläufen erstellt, die mehr als 750 Tausend separate Datensätze „Zustand → Aktion → Neuer Zustand → Belohnung“ ergab. Beachten Sie, dass ich hier die „Zufallsdurchgänge“ erwähnt habe. Zu diesem Zeitpunkt haben wir noch kein trainiertes Modell. Bei jedem Durchlauf im Strategietester generiert der EA „..\BAC\Research.mq5“ ein neues Modell und füllt es mit Zufallsparametern. Die Funktionsweise solcher Modelle ist daher so zufällig wie ihre Parameter. In diesem Stadium habe ich die Mindestrentabilität eines Durchgangs nicht eingeschränkt, um Beispiele in der Datenbank zu speichern.
Nachdem wir Beispiele gesammelt haben, führen wir ein erstes Training unseres Modells durch. Dazu führen wir den EA „..\BAC\Study.mq5“ für 500.000 Iterationen des Modelltrainings aus.
Ich muss sagen, dass nach dem anfänglichen Training des Modells die Stochastizität der Politik des Akteurs ziemlich stark zu spüren ist. Dies spiegelt sich in der großen Streuung der Ergebnisse der einzelnen Durchgänge wider.
In der zweiten Phase wird die Trainingsdatenerfassung EA im Optimierungsmodus des Strategietesters für 300 Iterationen mit einer vollständigen Parametersuche neu gestartet. Diesmal begrenzen wir die Mindesterträge auf die Höhe der positiven Renditen (0 oder etwas höher). Infolgedessen wurde eine relativ kleine Anzahl von Ergebnissen hinzugefügt (15-20 Durchgänge).
Bitte beachten Sie, dass bei der Ausführung von Data Collection EA nach dem anfänglichen Training alle Durchläufe das gleiche vortrainierte Modell verwenden. Die gesamte Streuung der Ergebnisse ist auf die Stochastizität der Politik des Akteurs zurückzuführen.
Als Nächstes führen wir das Modelltraining mit denselben 500.000 Iterationen erneut durch.
Das Sammeln von Beispielen und das Trainieren des Modells werden mehrmals wiederholt, bis das gewünschte Ergebnis erreicht ist oder ein lokales Minimum erreicht ist, wenn die nächste Iteration des Sammelns von Beispielen und des Trainierens des Modells keinen Fortschritt bringt.
Beachten Sie, dass die zuvor gesammelten Übergänge beim nächsten Lauf der Beispiel-Datenbanksammlung EA nicht gelöscht werden. Die neuen Einträge werden am Ende der Datei hinzugefügt. Die Konstante MaxReplayBuffer wurde der Datei „..\BAC\Trajectory.mqh“ hinzugefügt, um die Ansammlung einer zu großen Datenbank von Beispielen zu verhindern. Diese Konstante gibt die maximale Anzahl der Durchläufe an (nicht die Dateigröße). Wenn sich der Puffer füllt, werden ältere Durchgänge gelöscht. Ich empfehle Ihnen, diese Konstante zu verwenden, um die Größe der Beispieldatenbank an die technischen Möglichkeiten Ihrer Geräte anzupassen.
#define MaxReplayBuffer 500
Nach etwa 7 Iterationen der Aktualisierung der Beispieldatenbank und des Trainings des Modells war ich in der Lage, ein Modell zu erhalten, das in der Lage war, in dem Trainingszeitintervall Gewinne zu erzielen. Die dargestellte Grafik zeigt eindeutig eine Tendenz zum Kapitalwachstum. Allerdings gibt es auch einige unrentable Bereiche.


In den 5 Monaten des Trainingszeitraums erwirtschaftete der EA 16 % Gewinn bei einem maximalen Drawdown von 8,41 % des Eigenkapitals. In der Bilanz war der Drawdown etwas geringer und betrug 6,68 %. Insgesamt wurden 99 Handelsgeschäfte getätigt, von denen 51,5 % mit einem Gewinn abgeschlossen wurden. Die Zahl der gewinnbringenden Geschäfte ist fast genauso hoch wie die Zahl der unrentablen. Aber der durchschnittliche Gewinn ist fast 50 % größer als der durchschnittliche Verlust. Der Gewinnfaktor lag bei 1,53 und der Indikator für den Wiedergewinnungsfaktor lag fast auf demselben Niveau.
Wir trainieren das Modell jedoch nicht nur für den Strategietester, sondern auch für die künftige Verwendung. Daher ist es für uns wichtiger, das Modell mit Daten außerhalb des Trainingssatzes zu testen. Wir haben das gleiche Modell mit historischen Daten vom Juni 2023 getestet. Alle anderen Prüfparameter blieben unverändert.


Die Ergebnisse des Tests des Modells auf neuen Daten sind mit den Ergebnissen des Trainingssatzes vergleichbar. In einem Monat erwirtschaftete der EA etwas mehr als 3 % Gewinn, was durchaus vergleichbar ist mit 16 % in 5 Monaten des Trainingsbeispiels. 11 Abschlüsse wurden getätigt, was niedriger ist als der entsprechende Indikator in der Ausbildungsstichprobe. Leider ist auch der Anteil der profitablen Handelsgeschäfte geringer als in der Trainingsstichprobe und beträgt nur 36,4 %. Allerdings ist der durchschnittliche Gewinn fast sechsmal höher als der durchschnittliche Verlust. Dadurch stieg der Gewinnfaktor auf 3,12.
Schlussfolgerung
In diesem Artikel haben wir einen anderen Algorithmus für das Training des Models Behavior-Guided Actor-Critic untersucht. Wie die Soft-Actor-Critic-Methode gehört sie zur großen Familie der Actor-Critic-Algorithmen und ist eine Alternative zur Soft-Actor-Critic-Methode. Zu den Vorteilen des betrachteten Algorithmus gehört die Fähigkeit, sowohl stochastische als auch deterministische Modelle in einem kontinuierlichen Aktionsraum zu trainieren. Die Anwendung dieser Methode bringt keine Einschränkungen bei der Konstruktion von trainierten Modellen mit sich.
Im praktischen Teil dieses Artikels wurde der vorgeschlagene Algorithmus mit MQL5 implementiert. Die Effizienz unserer Implementierung wird durch Testergebnisse bestätigt.
Ich möchte noch einmal darauf hinweisen, dass alle vorgestellten Programme lediglich die Möglichkeit der Nutzung der Technologie aufzeigen. Sie sind nicht für den Einsatz auf realen Finanzmärkten geeignet. Die EAs müssen verfeinert und zusätzlich getestet werden, bevor sie auf einem realen Markt eingeführt werden.
Links
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Trainings-EA des Agenten |
| 3 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 6 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13024
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.