Existe um padrão para o caos? Vamos tentar encontrá-lo! Aprendizado de máquina com o exemplo de uma amostra específica. - página 21
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Cortei mais dois anos dessa amostra e a média no Exame já se tornou -485 (era 1214) e o número de modelos que ultrapassaram o limite de 3000 pontos se tornou 884 (era 277 da última vez).
No entanto, os resultados na amostra do teste se deterioraram de uma média de 2115 para 186 pontos, ou seja, significativamente. O que é isso? Há menos exemplos na amostra de trem semelhantes aos da amostra de teste?
O número médio de árvores diminuiu de 10 para 7.
A quebra de zero no gráfico deslocou a distribuição de equilíbrio para o centro.
Qual é a base para a afirmação de que o resultado deve ser semelhante ao teste? Presumo que as amostras não sejam homogêneas - não há um número comparável de exemplos semelhantes nelas, e acho que as distribuições de probabilidade sobre os quanta diferem um pouco.
Traine. Estou falando de dados em que há bons padrões. Se você alimentar o treinamento com 1.000 variantes da tabuada de multiplicação, novas variantes que nunca correspondem à linha de base (mas dentro dos limites da linha de base) também serão computadas muito bem. Uma árvore fornecerá a variante mais próxima, uma floresta aleatória calculará a média de cem variantes mais próximas e provavelmente dará uma resposta mais precisa do que a de uma árvore.
Se for possível encontrar preditores com regularidade para o mercado, então o OOS também será semelhante a um rastreamento. Mas não como agora, mais da metade dos modelos são negativos e um terço são positivos. Todos os modelos bem-sucedidos se tornaram assim por acaso, a partir de sementes aleatórias.
A semente deve alterar apenas ligeiramente o sucesso do modelo e, em geral, todos eles devem ser bem-sucedidos. Agora, verifica-se que nenhum padrão foi encontrado (excesso ou falta de treinamento).
Ele está envolvido apenas no controle da interrupção do treinamento, ou seja, se não houver melhoria no teste durante o treinamento no trem, o treinamento será interrompido e as árvores serão removidas até o ponto em que houve a última melhoria no modelo de teste.
Assim, fica claro por que os testes também são bons. Basicamente, ele se ajusta ao teste. Parei de fazer isso para 1 treinamento. Faço o valving para frente, colo todos os OOCs juntos e, em seguida, escolho os melhores hiperparâmetros do modelo (profundidade, número de árvores etc.) entre as muitas variantes de OOCs colados. Presumo que o exame será praticamente o mesmo que a colagem selecionada de todos os OOCs. Nessa variante, ao longo de 5 anos, eu treinei novamente uma vez por semana - são centenas de treinamentos e pedaços de OOCs.
Aparentemente, não indiquei claramente a amostra que usei - esta é a sexta (última) amostra do experimento descrito aqui, portanto, há apenas 61 preditores.
estratégias primitivas, especialmente em áreas de mercado plano.Bem, você escolheu esses 61 entre mais de 5.000. Meu número total é menor e o número de selecionados é menor. E ao adicionar um de cada vez, depois de 3-4 selecionados, a adição adicional de sinais só piora o resultado no OOS.
Em geral, posso adicionar mais preditores, porque agora eles são usados apenas com 3 TFs, com algumas exceções - acho que mais alguns milhares podem ser adicionados, mas é duvidoso que todos sejam usados adequadamente no treinamento, já que 10.000 variantes de semente para 61 preditores dão essa propagação....
E, é claro, você precisa fazer uma pré-triagem dos preditores, o que acelerará o treinamento.
Se todos eles forem praticamente iguais, é improvável que se encontre algo que melhore seriamente o resultado. Você pode tentar dados completamente novos ou indicadores exclusivos.
A triagem preliminar também é um trabalho longo, adicionar um de cada vez é muitas vezes mais demorado, até mesmo até 3 recursos e, se for até 10, são muitos dias. Mas não faz sentido, pois depois de 3-4 recursos geralmente não há melhoria. Mas, ocasionalmente, há, mas o aumento é pequeno. Não foram encontrados avanços lá (em meus experimentos, alguém pode encontrar).
É lógico que os outliers são outliers, mas acho que são ineficiências que devem ser aprendidas com a remoção do ruído branco. Em outras áreas, as estratégias primitivas simples geralmente funcionam, especialmente em áreas de mercado plano.
A imagem inferior é lucrativa, mas em 5 anos houve apenas 2 períodos em 2017 com forte crescimento (aparentemente houve uma forte tendência previsível), o modelo ganhou mais dinheiro nesses 2 períodos. E seria bom ter um crescimento uniforme ao longo do tempo. Eu desligaria esse modelo depois de um mês de inatividade.
É claro que você pode criar um EA - esperando por cisnes brancos. Mas eu preferiria uma negociação ativa.
Corte mais dois anos dessa amostra e a média no Exame já se tornou -485 (era - 1214), e o número de modelos que ultrapassaram o limite de 3.000 pontos se tornou 884 (era 277 da última vez).
No entanto, os resultados na amostra de teste se deterioraram de uma média de 2115 para 186 pontos, ou seja, significativamente. O que é isso? Há menos exemplos na amostra de trem semelhantes aos da amostra de teste?
O número médio de árvores diminuiu de 10 para 7.
A quebra de zero no gráfico deslocou a distribuição de equilíbrio para o centro.
Você pode postar os arquivos da primeira postagem, pois também quero tentar uma ideia.
Traine. Estou falando de dados em que há bons padrões. Se você enviar 1.000 variantes da tabuada de multiplicação para treinamento, novas variantes que nunca coincidirem com a linha de base (mas dentro dos limites da linha de base) também serão bem calculadas. Uma árvore fornecerá a variante mais próxima, uma floresta aleatória calculará a média de cem variantes mais próximas e provavelmente dará uma resposta mais precisa do que a de uma árvore.
Se for possível encontrar preditores com regularidade para o mercado, então o OOS também será semelhante a um traço. Mas não como agora, mais da metade dos modelos são negativos e um terço é positivo. Todos os modelos bem-sucedidos se tornaram assim por acidente, a partir de uma semente aleatória.
A semente deve alterar apenas ligeiramente o sucesso do modelo e, em geral, todos eles devem ser bem-sucedidos. Agora, verifica-se que nenhum padrão foi encontrado (excesso ou falta de treinamento).
Ninguém está argumentando que, com bons dados, tudo provavelmente funcionará perfeitamente. Mas, como não é possível obter esses dados, é preciso pensar no que é possível extrair do que se tem.
O fato de que é possível obter modelos eficazes aleatoriamente, que serão eficazes com novos dados, me faz pensar em como reduzir essa aleatoriedade, ou seja, se há alguma métrica regular para segmentos quânticos, com base na qual o modelo foi construído de forma consistente. Ou seja, estamos falando de métricas adicionais além da ganância no alvo. Se essas dependências puderem ser estabelecidas, os modelos também poderão ser criados com maior probabilidade de sucesso. É claro que isso deve funcionar em amostras diferentes.
Então, posso ver por que os testes também são bons. Basicamente, ele se ajusta ao teste. Parei de fazer isso em um estudo. Faço o valving para frente, colo todos os OOCs juntos e, em seguida, escolho os melhores hiperparâmetros do modelo (profundidade, número de árvores etc.) entre as muitas variantes de OOCs colados. Presumo que o exame será praticamente o mesmo que a colagem selecionada de todos os OOCs. Nessa variante, ao longo de cinco anos, treinei novamente uma vez por semana, o que representa centenas de treinamentos e blocos de OOCs.
O principal é não separar a última seção do exame.
Ajuste de hiperparâmetros e avaliação do resultado com base em quê? Acho que é o mesmo ajuste com um elemento de média, se seguirmos sua lógica.
A lógica do CatBoost é que, se for impossível aprimorar o modelo (pelo Logloss), então não faz sentido continuar o treinamento. Nesse caso, não há garantias de que o modelo acabou sendo bom, é claro.
Bem, esses 61 você escolheu entre mais de 5.000. Tenho o número total e o número de selecionados. E ao adicionar um de cada vez, depois de 3 a 4 selecionados, a adição adicional de recursos só piora o resultado em OOS.
Não, eu não os escolhi - eu os retirei do modelo ao treinar em todos os preditores.
Veja, geralmente considero o preditor como um conjunto de segmentos quânticos. E, por esse motivo, seleciono segmentos quânticos; em geral, posso até decompor todos os preditores em binários - o resultado é um pouco pior, mas comparável. Talvez seja necessário um método especial de treinamento para preditores binários descarregados.
Se todos eles forem praticamente iguais, é improvável que já seja possível encontrar algo que melhore seriamente o resultado. Você pode tentar dados completamente novos ou indicadores exclusivos.
O que você quer dizer com "quase o mesmo"? Presumo que esteja falando de métricas ou o quê? É claro que você pode tentar dados diferentes, usar uma ferramenta diferente, por exemplo.
A pré-triagem também é um trabalho longo, adicionar um a um leva muito mais tempo, mesmo com até 3 recursos, e se for até 10, leva muitos dias. Mas, ocasionalmente, há, mas o aumento é pequeno. Não foram encontrados avanços (em meus experimentos, alguém pode encontrar).
A variante de que você está falando é um jogo longo, e é por isso que eu não jogo (bem, não tenho automação completa). Mas não concordo que não haja efeito - fiz desistências em grupos, com a redução de grupos - o resultado foi positivo. Mas ainda atribuo essas ações ao ajuste ou à aleatoriedade - não há justificativa para a escolha dos preditores.
A figura inferior é lucrativa, mas em 5 anos houve apenas 2 períodos em 2017 com forte crescimento (aparentemente houve uma forte tendência previsível), o modelo ganhou mais dinheiro nesses 2 períodos. E seria bom ter um crescimento uniforme ao longo do tempo. Eu desligaria esse modelo após um mês de inatividade.
É claro que você pode criar um Expert Advisor - esperando por cisnes brancos. Mas eu preferiria uma negociação ativa.
É por isso que sou a favor do uso de conjuntos de modelos, pois entendo que cada um pode captar seus próprios padrões não frequentes.
Bem, em geral, o objetivo é que o erro na linha de base e no teste seja praticamente o mesmo. Aqui, seu exame está se movendo em direção à linha de treinamento e ao teste, ou seja, para cima, e eles estão em direção ao teste, ou seja, para baixo. O excesso de treinamento diminui.
E por qual métrica eles são semelhantes?
Veja, por exemplo, se pegarmos a métrica Precisão, subtrairmos esse indicador da amostra de teste do trem, - obteremos o delta (eixo y) e, por x, observaremos o lucro na amostra de exame.
Não há nenhuma dependência especial, ou o quê?
Abaixo estão duas métricas para cada amostra - os dados são obtidos à medida que novas árvores são adicionadas ao modelo.
Aqui estão as características desse modelo
E aqui estão as métricas de outro modelo, com perdas em duas amostras
Aqui estão as características do modelo
É inconveniente responder no estilo do fórum, clicando várias vezes em responder. Abaixo, minhas respostas estão destacadas em cores.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> Há muito tempo, observei como os quanta são construídos, variantes básicas. Primeiro, a coluna é classificada.
1) por intervalo, passo uniforme (por exemplo, de 0 a 1 com passo de valor exatamente através de 0,1, totalizando 10 quanta 0,1, 0,2, 0,3 ... 0,9)
2) percentil - ou seja, pelo número de exemplos. Se dividirmos por 10 quanta, em cada quantum colocaremos 10% do número de todas as linhas. Se houver muitas duplas, alguns quanta serão mais de 10%, porque as duplas não devem cair em outros quanta, por exemplo, se as duplas forem 30% da amostra, então nesse quantum todas cairão. Dependendo do número de amostras em cada quantum, a distribuição poderia ser 0,001, 0,12,0,45,0,51,0,74, .... 0,98.
3) há uma combinação dos dois tipos
Portanto, não há nada de muito inteligente na construção de quanta. Eu mesmo criei esses dois métodos de quantificação. E, como sempre, fiz algo da maneira que considero melhor. Talvez eu tenha cometido um erro. E geralmente faço cálculos sem quantificação, mas com dados flutuantes.
Se você tornar todos os preditores binários, haverá apenas dois quantums, um com todos os 0s e o outro com todos os 1s.
Você ajusta os hiperparâmetros e avalia o resultado com base em quê? Acho que é o mesmo ajuste com um elemento de média, se você seguir sua lógica.
> Eu analiso os gráficos de saldo e os drawdowns. Ainda não consegui automatizar a seleção. Sim, o ajuste é para uma melhor colagem de OOS. Mas não o modelo em si (ou seja, não o traço), mas a seleção dos melhores hiperparâmetros do modelo.
O que você quer dizer com "quase o mesmo"? Presumo que esteja se referindo a algumas métricas ou o quê? É claro que você pode tentar outros dados, usar outra ferramenta, por exemplo.
> Todas elas são feitas com base em preços e mashups.
Em uma pergunta antiga.
Qual é a base para a afirmação de que o resultado deve ser semelhante ao trem? Estou presumindo que as amostras não são homogêneas - não há um número comparável de exemplos semelhantes, e acho que as distribuições de probabilidade dos quanta são ligeiramente diferentes.
> Exemplos aqui https://www.mql5.com/ru/articles/3473
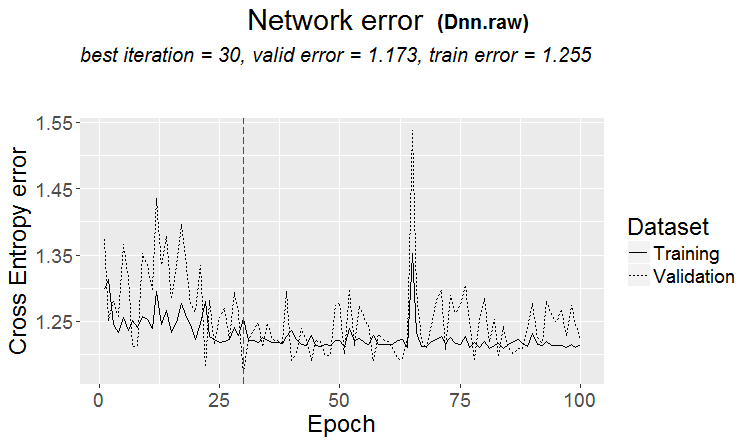
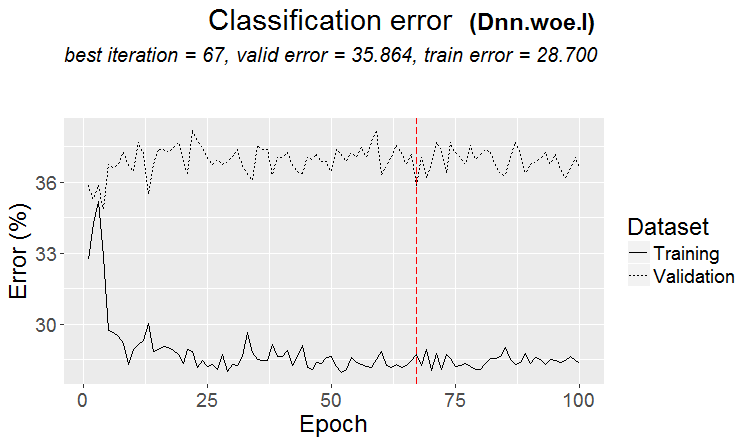
Uma boa variante é quando um padrão é encontrado: o ternário e o teste têm quase o mesmo erro
Nos mercados, o que acontece com mais frequência é o seguinte: um bom teste, mas após alguma etapa do treinamento (na figura, após a terceira etapa), o retreinamento começa e o erro do teste começa a crescer. As figuras se referem a redes neurais, mas também há algo parecido com florestas e boosts, quando o modelo fica supertreinado.
Por qual métrica eles são semelhantes?
Mas isso não significa que suas métricas sejam ruins.
Portanto, não há nada de muito inteligente na construção quântica. Eu mesmo criei esses dois métodos de quantificação. E, como sempre, fiz algo da maneira que considero melhor. Talvez eu tenha cometido um erro. E geralmente faço cálculos sem quantificação, mas usando dados de flutuação.
É claro que existem métodos diferentes, eu uso cerca de 900 tabelas quânticas atualmente.
A questão não está no método, mas na escolha do intervalo do preditor no qual o valor médio do alvo binário é maior do que na amostra (agora coloco um mínimo de 5% mais critérios sobre o número de exemplos - também um mínimo de 5%), o que indica informações úteis no preditor. Se não houver tais informações, você pode esperar que elas apareçam em algumas divisões, mas acho que isso é menos provável.
De fato, acontece que há um ou dois desses gráficos, mas raramente há muitos. E aqui você pode pegar apenas esses gráficos ou apenas os preditores com esses gráficos, escolhendo a melhor tabela quântica.
Pessoalmente, vi que os preditores, pelo menos os meus, não têm transições suaves de probabilidade, mas que isso acontece de forma descontínua e muda para o desvio oposto, ou seja, era +5 e imediatamente se tornou -5. Acho até que, se essas probabilidades forem ordenadas, o modelo será mais fácil de treinar, pois ele é treinado em intervalos. Esse é o motivo pelo qual faz sentido excluir áreas não informativas e separar as conflitantes.
Se você tornar todos os preditores binários, haverá apenas dois quanta, um com todos os 0s e outro com todos os 1s.
Na verdade, haverá um - 0,5 :) Mas, dessa forma, você pode decompor o preditor em intervalos úteis (contendo informações potencialmente úteis).
> Analisando gráficos de equilíbrio e drawdowns. Automatizar a seleção ainda não deu certo. Sim, ajuste - para obter a melhor colagem OOS. Mas não o modelo em si (ou seja, não o traço), mas a seleção dos melhores hiperparâmetros do modelo.
Bem, isso é compreensível, mas não canônico - acho que as métricas do modelo também são importantes.
> Tudo isso é feito com base em preços e mashups.
Em teoria sim, e isso se você usar redes neurais, mas na verdade - não - dependências muito complexas devem ser pesquisadas com cálculos diferentes, pois isso simplesmente não tem o poder de computação dos usuários comuns.
Sobre uma pergunta antiga.
> Exemplos aqui https://www.mql5.com/ru/articles/3473
Uma boa variante é quando um padrão é encontrado: o ternário e o teste têm quase o mesmo erro
Nos mercados, o que acontece com mais frequência é o seguinte: um bom teste, mas após alguma etapa de treinamento (na figura após a terceira), o retreinamento começa e o erro do teste começa a aumentar. As figuras se referem a redes neurais, mas também há algo parecido com florestas e boosts, quando o modelo fica supertreinado.
A regularidade é sempre encontrada - esse é o princípio - a questão é se essa regularidade continuará a aparecer ou não.
Não sei que tipo de amostra você tinha. Já tive casos em que o teste aprende mais rápido do que o treinamento, mas com mais frequência acontece o contrário e há um delta perceptível entre eles. Em condições ideais, a diferença será pequena, é claro.
Posso dizer com certeza que os modelos são subtreinados apenas porque as amostras não são muito semelhantes e o treinamento é interrompido quando não há melhoria.
Um dia mostrarei como a amostra retreinada se parece graficamente - são duas protuberâncias separadas por cantos....
Corte a amostra de treinamento ainda mais pela metade.
Há apenas 306 modelos, e o lucro médio por exame é de -2791 pontos.
Mas eu consegui este modelo
Com estas características
A expectativa de esteira certamente caiu, mas o Recall cresceu duas vezes - devido a isso e a esse gráfico com um grande número de negócios.
Esses preditores foram usados:
E há 9 deles a menos do que na amostra - tentarei pegar apenas eles e treinar em toda a amostra (em todas as linhas de trem).
As divisões são feitas somente até o quantum. Tudo dentro do quantum é considerado como tendo os mesmos valores e não é mais dividido. Não entendo por que você está procurando algo no quantum, sua principal finalidade é acelerar os cálculos (a finalidade secundária é carregar/generalizar o modelo para que não haja mais divisões, mas você pode simplesmente limitar a profundidade dos dados flutuantes). Fiz a quantificação em 65.000 partes - o resultado é absolutamente o mesmo que o modelo sem quantificação.
Pessoalmente, vi que os preditores, pelo menos os meus, não têm transições suaves de probabilidade, mas que isso acontece abruptamente e muda para o desvio oposto, ou seja, era +5 e imediatamente se tornou -5.
Também notei algo parecido com isso. Aumentar a profundidade em 1 altera drasticamente a lucratividade, às vezes em +, às vezes em -.
De fato, haverá um - 0,5 :) Mas, dessa forma, será possível dividir o preditor em intervalos úteis (contendo informações potencialmente úteis).
Haverá uma divisão que dividirá os dados em dois setores - um com todos os 0s e o outro com todos os 1s. Não sei o que é chamado de quanta, mas acho que quanta é o número de setores obtidos após a quantificação. Talvez seja o número de divisões, como você quis dizer.