
Redes neurais de maneira fácil (Parte 43): Dominando habilidades sem função de recompensa

Introdução
O aprendizado por reforço (reinforcement learning) é uma abordagem poderosa no campo do aprendizado de máquina, que permite que um agente aprenda de forma autônoma, interagindo com o ambiente circundante e recebendo feedback na forma de uma função de recompensa. No entanto, uma das questões-chave no aprendizado por reforço é a necessidade de definir uma função de recompensa que elabore o comportamento desejado do agente.
Definir uma função de recompensa pode ser uma arte complexa, especialmente em tarefas que envolvem a conquista de múltiplos objetivos ou situações ambíguas. Além disso, algumas tarefas podem não possuir uma função de recompensa explícita, o que dificulta a aplicação de métodos tradicionais de aprendizado por reforço.
Neste artigo, apresentamos o conceito de "Diversity is All You Need" (diversidade é tudo o que você precisa), que permite que um modelo seja treinado em habilidades sem a necessidade de uma função de recompensa explícita. A diversidade de ações, a exploração do ambiente e a maximização da variabilidade nas interações com o ambiente são fatores-chave para ensinar ao agente um comportamento eficaz.
Essa abordagem oferece uma nova perspectiva sobre o aprendizado sem uma função de recompensa e pode ser útil para resolver desafios complexos em que a definição de uma função de recompensa clara é difícil ou impossível.
1. O Conceito de "Diversity is All You Need"
Na vida real, para que um executor inicie funções específicas, são necessários conhecimentos e habilidades específicas. Da mesma forma, ao treinar um modelo, buscamos desenvolver as habilidades necessárias para resolver a tarefa proposta.
No aprendizado por reforço, a principal ferramenta para motivar o modelo é a função de recompensa. Ela permite que o agente compreenda o quão bem-sucedidas foram suas ações. No entanto, frequentemente, as recompensas são raras, e abordagens adicionais são necessárias para encontrar soluções ótimas. Já discutimos alguns métodos para incentivar a exploração do ambiente pelo modelo, mas nem sempre eles são eficazes.
Modelos treinados de maneira tradicional são altamente especializados e só podem lidar com tarefas específicas. Pequenas mudanças na formulação da tarefa exigem uma reestruturação completa do modelo, mesmo que as habilidades existentes possam ser úteis. O mesmo ocorre ao mudar o ambiente circundante.
Uma possível solução para esse problema é a utilização de modelos hierárquicos compostos por vários blocos. Nessas abordagens, criamos modelos individuais para diferentes habilidades e um planejador que gerencia a utilização dessas habilidades. Treinar o planejador permite resolver novas tarefas com base nas habilidades previamente aprendidas. No entanto, surgem questões sobre a suficiência e qualidade das habilidades pré-aprendidas, já que novas tarefas podem exigir habilidades adicionais.
O conceito de "Diversity is All You Need" propõe o uso de modelos hierárquicos com habilidades individuais e um planejador. Ele enfatiza a diversidade máxima de ações e a exploração do ambiente, permitindo que o agente aprenda e se adapte de forma eficaz. Ao treinar habilidades distintas, o modelo se torna mais flexível e adaptável, capaz de empregar estratégias diversas em diferentes situações. Essa abordagem é útil quando a definição de recompensas explícitas é uma tarefa complexa, permitindo que o modelo explore autonomamente e descubra novas soluções.
A ideia central desse conceito é utilizar a diversidade como uma ferramenta de aprendizado. A diversidade nas ações e no comportamento do modelo permite que ele explore o espaço de estados e descubra novas oportunidades. Essa diversidade não se limita a ações aleatórias ou ineficazes; ela é direcionada para identificar várias estratégias úteis que podem ser aplicadas em diferentes situações.
O princípio "Diversity is All You Need" sugere que a diversidade é um componente-chave para o sucesso do aprendizado sem uma função de recompensa explícita. Um modelo treinado em habilidades diversas se torna mais flexível e adaptável, capaz de aplicar estratégias diferentes de acordo com o contexto e as demandas da tarefa.
Essa abordagem possui potencial para enfrentar desafios complexos em que a definição de uma função de recompensa explícita é difícil ou inacessível. Ela permite que o modelo explore o ambiente de maneira autônoma, aprendendo várias habilidades e estratégias, o que pode levar à descoberta de novos caminhos e soluções.
Outra premissa fundamental subjacente ao conceito "Diversity is All You Need" é a suposição de que o estado atual do modelo depende não apenas da ação específica escolhida, mas também da habilidade utilizada. Em vez de simplesmente associar ações a estados, o modelo aprende a associar estados específicos a habilidades específicas.
Um dos possíveis métodos para abordar essa questão é o uso de modelos hierárquicos compostos por vários blocos. Nesse tipo de modelo, criamos modelos individuais para diversas habilidades, além de um planejador que gerencia a utilização dessas habilidades. No início, o treinamento não é guiado e se concentra em desenvolver várias habilidades independentemente de tarefas específicas, o que possibilita uma compreensão aprofundada do ambiente e a ampliação do repertório comportamental do agente. Em seguida, passamos para o estágio de treinamento controlado por reforço, onde a meta é alcançar a máxima eficácia do modelo na execução de tarefas específicas.
Na primeira fase, realizamos o treinamento do modelo de habilidades. Os dados de entrada do modelo consistem no estado atual do ambiente e na habilidade específica selecionada para ser aplicada. O modelo gera a ação correspondente, que é então executada. O resultado dessa ação é a transição para um novo estado do ambiente. Nesta fase, estamos interessados apenas nesse novo estado, sem utilizar recompensas externas.
Em vez disso, aplicamos um modelo de discriminador ao novo estado, que tenta determinar qual habilidade foi usada na etapa anterior. A entropia cruzada entre os resultados do discriminador e o vetor one-hot correspondente à habilidade aplicada serve como recompensa para o nosso modelo de habilidades.
O treinamento do modelo de habilidades é realizado por meio de métodos de aprendizado por reforço, como o Ator-Crítico. O modelo de discriminador, por outro lado, é treinado usando métodos clássicos de aprendizado supervisionado.
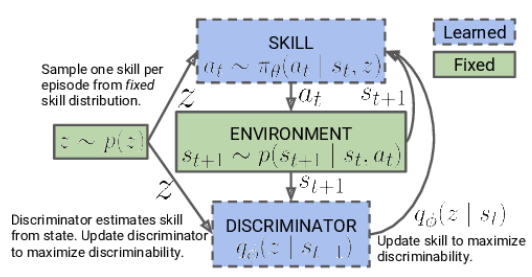
No início do treinamento do modelo de habilidades, trabalhamos com uma base fixa de habilidades, que não depende do estado atual. Isso ocorre porque ainda não possuímos informações sobre as habilidades e sua utilidade em diferentes estados. Nossa tarefa é aprender essas habilidades. Ao projetar a arquitetura do modelo, determinamos a quantidade de habilidades que serão treinadas.
Durante o processo de treinamento do modelo de habilidades, o agente explora ativamente e preenche cada habilidade com base nas informações obtidas do ambiente. Introduzimos identificadores de habilidades no modelo de forma aleatória, permitindo que ele aprenda e preencha cada habilidade independentemente das outras.
O modelo utiliza os identificadores de habilidades obtidos e o estado atual do ambiente para determinar a ação correspondente a ser executada. Ele aprende a associar habilidades específicas a estados específicos e a escolher ações para cada habilidade.
É importante ressaltar que, no início do treinamento, o modelo não possui conhecimento prévio sobre as habilidades ou sua utilidade em estados específicos. Ele aprende e identifica independentemente as relações entre habilidades e estados durante o processo de treinamento. Para isso, utilizamos uma função de recompensa que promove a máxima diversidade no comportamento do agente, dependendo da habilidade aplicada.
Após concluir a etapa de treinamento do modelo de habilidades, passamos para a próxima fase, que consiste em um treinamento controlado por reforço. Nessa etapa, treinamos o modelo do planejador visando maximizar um objetivo específico ou obter a maior recompensa dentro de uma tarefa específica. Nesse processo, podemos utilizar um modelo de habilidades fixo, acelerando assim o treinamento do modelo do planejador.
Dessa forma, a abordagem de dois estágios para o treinamento do modelo de habilidades, começando com o preenchimento não guiado das habilidades e finalizando com o treinamento controlado por reforço, permite que o modelo aprenda e utilize habilidades de forma autônoma para diferentes tarefas.
Observe que, em nossa abordagem, alteramos o processo de tomada de decisão hierárquica em comparação ao modelo hierárquico discutido anteriormente. Anteriormente, usamos vários agentes, cada um com suas próprias habilidades. Esses agentes ofereciam opções de ações e, em seguida, o planejador avaliava essas opções e tomava uma decisão final.
Na abordagem atual, invertemos essa sequência. Agora, o planejador analisa a situação atual e decide qual habilidade é mais adequada. Em seguida, o agente toma a decisão de ação com base na habilidade escolhida.
Dessa forma, invertemos o processo hierárquico: o planejador toma a decisão sobre a habilidade a ser usada e, em seguida, o agente executa a ação correspondente à habilidade escolhida. Essa mudança nos permite gerenciar e usar habilidades de maneira eficaz, dependendo da situação atual.
2. Implementação em MQL5
Após a visão teórica, passamos à implementação prática de nosso trabalho. Assim como no artigo anterior, começamos criando uma base de exemplos que usaremos para treinar o modelo. A coleta de dados é realizada pelo Expert Advisor especialista "DIAYN\Research.mq5", que é uma versão modificada do Expert Advisor do artigo anterior. No entanto, no algoritmo atual, existem algumas diferenças.
A primeira mudança que fizemos está relacionada à arquitetura dos modelos. Fizemos modificações na arquitetura para atender às novas exigências e ideias decorrentes do conceito "Diversity is All You Need".
Durante o processo de treinamento, usamos três modelos:
- Modelo do agente (habilidades). Este é responsável pelo aprendizado e execução de várias habilidades de acordo com o estado atual do ambiente.
- O planejador, que toma decisões com base na avaliação da situação e seleciona a habilidade apropriada para a realização da tarefa. O planejador trabalha em colaboração com o modelo de habilidades e gerencia a tomada de decisões em um nível mais elevado.
- O discriminador, que é usado apenas durante o processo de treinamento do modelo de habilidades e não é aplicado em tempo real. Ele é usado para fornecer feedback e é usado para calcular recompensas durante o treinamento.
É importante destacar que o modelo de habilidades e o planejador são os principais modelos empregados no processo de operação e resolução de problemas. O discriminador, por sua vez, é usado apenas para aprimorar o treinamento do modelo de habilidades e não é aplicado na operação real do sistema.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler, CArrayObj *discriminator) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- if(!discriminator) { scheduler = new CArrayObj(); if(!scheduler) return false; }
De acordo com o algoritmo "Diversity is All You Need", os modelos de agente (modelos de habilidades) recebem uma entrada de buffer de dados contendo descrições do estado atual e o identificador da habilidade utilizada. No contexto do nosso trabalho, fornecemos as seguintes informações:
- Dados históricos de movimentação de preços e indicadores: Esses dados fornecem informações sobre alterações passadas nos preços do mercado e nos valores de diversos indicadores. Eles servem como contexto importante para as decisões do modelo de agente.
- Informações sobre o estado atual da conta e posições abertas: Esses dados incluem informações sobre o saldo atual da conta, posições abertas, tamanho das posições e outros indicadores financeiros. Eles auxiliam o modelo de agente a levar em consideração a situação atual e as restrições ao tomar decisões.
- Vetor one-hot de identificação da habilidade: Esse vetor representa uma representação binária do identificador da habilidade utilizada. Ele aponta para uma habilidade específica que o modelo de agente deve aplicar nesse estado.
Para processar tal entrada, é necessário um conjunto de dados iniciais de tamanho suficiente, permitindo que o modelo do agente obtenha todas as informações necessárias sobre o estado do mercado, dados financeiros e a habilidade selecionada para tomar decisões otimizadas.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Após obter os dados iniciais, criamos uma camada de normalização de dados, que desempenha um papel crucial no processamento dos dados de entrada antes de serem fornecidos ao modelo do agente. Essa camada permite padronizar diferentes recursos iniciais em uma escala única, garantindo estabilidade e coerência dos dados. Isso é essencial para o funcionamento eficaz do modelo do agente e para a obtenção de resultados de alta qualidade.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os dados iniciais preparados podem ser processados usando blocos de camadas convolucionais.
As camadas convolucionais são componentes-chave na arquitetura de modelos de aprendizado profundo, especialmente em tarefas de processamento de imagens e sequências. Elas permitem extrair dependências espaciais e locais dos dados iniciais.
No caso do nosso algoritmo "Diversity is All You Need", as camadas convolucionais podem ser aplicadas aos dados históricos de movimento de preços e indicadores para extrair padrões e tendências relevantes. Isso ajuda o agente a identificar as relações entre diferentes etapas temporais e tomar decisões com base nos padrões identificados.
Cada camada convolucional consiste em 4 filtros, que exploram os dados de entrada com uma janela específica. Após a aplicação das operações de convolução, um conjunto de mapas de características é gerado, destacando aspectos importantes dos dados. Essas transformações permitem que o modelo do agente detecte e leve em consideração características cruciais dos dados no contexto do aprendizado por reforço.
As camadas convolucionais proporcionam à modelo do agente a capacidade de "ver" e se concentrar nos aspectos significativos dos dados, o que é um passo importante no processo de tomada de decisões e execução das ações pertinentes dentro do conceito "Diversity is All You Need".
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Após passar pelo conjunto de camadas convolucionais, os dados são processados no bloco de tomada de decisões, que consiste em três camadas totalmente conectadas. Ao atravessar essas camadas totalmente conectadas, o modelo do agente é capaz de aprender dependências complexas e identificar conexões entre diferentes aspectos dos dados.
A saída do bloco de tomada de decisões utiliza a FQF (Fully Parameterized Quantile Function). Esse modelo é usado para avaliar os quantis da distribuição de recompensas futuras ou variáveis-alvo. Ele permite que o modelo do agente obtenha estimativas não apenas das médias, mas também preveja diversos quantis, o que é útil para modelar incertezas e tomar decisões em cenários estocásticos.
O uso do modelo FQF totalmente parametrizado na saída do bloco de tomada de decisões permite que o modelo do agente obtenha previsões mais flexíveis e precisas, que podem ser utilizadas para escolher ações de forma otimizada no âmbito do conceito "Diversity is All You Need".
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O modelo do planejador realiza a classificação do estado atual do ambiente para determinar a habilidade a ser usada. Ao contrário do modelo do agente, o planejador tem uma arquitetura simplificada, sem o uso de camadas convolucionais para o pré-processamento de dados, o que ajuda a economizar recursos.
Os dados de entrada para o planejador são semelhantes aos do agente, exceto pelo vetor de identificação da habilidade. O planejador recebe a descrição do estado atual do ambiente, incluindo dados históricos do movimento dos preços, indicadores e informações sobre o estado atual da conta e das posições abertas.
A classificação do estado do ambiente e a determinação da habilidade a ser usada são realizadas passando os dados por meio de camadas totalmente conectadas e o bloco FQF. Os resultados são normalizados usando a função SoftMax, o que resulta em um vetor de probabilidades refletindo a probabilidade do estado pertencer a cada habilidade possível.
Dessa forma, o modelo do planejador permite determinar qual habilidade deve ser usada com base no estado atual do ambiente. Isso, por sua vez, ajuda o modelo do agente a tomar a decisão adequada e escolher a ação ótima de acordo com o conceito "Diversity is All You Need".
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Para diversificar as habilidades, utilizamos um terceiro modelo: o Discriminador. Sua função é recompensar ações mais inesperadas, promovendo a variedade de comportamento do Agente. Não é necessário que essa modelagem seja altamente precisa, então decidimos simplificar ainda mais sua arquitetura e remover o bloco FQF.
Na arquitetura do Discriminador, utilizamos apenas a camada de normalização e camadas totalmente conectadas. Isso permite reduzir os recursos computacionais necessários, mantendo a capacidade da modelagem de classificação. Na saída do modelo, aplicamos a função SoftMax para obter as probabilidades de associação das ações às diferentes habilidades.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- return true; }
Após descrever as arquiteturas dos modelos, podemos passar para a organização do processo de coleta de dados para treinamento. Na primeira etapa da coleta de dados, usaremos apenas o modelo do Agente, já que não temos informações primárias sobre o ambiente circundante. Em vez disso, podemos efetivamente usar um vetor de identificação de habilidade gerado aleatoriamente, o qual fornecerá resultados comparáveis com o uso de um modelo não treinado. Isso também nos permitirá reduzir significativamente o uso de recursos computacionais.
No método OnTick, é preparado o processo direto de coleta de dados. No início do método, verificamos se ocorreu um evento de abertura de uma nova barra e, se sim, carregamos os dados históricos.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Da mesma forma que o artigo anterior, carregamos informações sobre o estado atual em dois arrays: o array de dados históricos "state" e o array de informações sobre o estado da conta "account" da estrutura "sState".
MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
Salvamos a estrutura obtida na base de exemplos para treinar posteriormente os modelos. Para passar os dados iniciais para o modelo do Agente, é necessário criar um buffer de dados. Nesse caso, começamos carregando os dados históricos nesse buffer.
State1.AssignArray(sState.state);
Para garantir que o funcionamento do modelo seja mais estável e eficaz, independentemente do tamanho das contas, decidimos normalizar as informações sobre o estado da conta em unidades relativas. Para isso, faremos algumas modificações nos indicadores do estado da conta.
Em vez do valor absoluto do saldo, usaremos o coeficiente de variação do saldo. Isso levará em consideração a variação relativa do saldo ao longo do tempo.
Também substituiremos o indicador de patrimônio líquido pela relação entre o patrimônio líquido e o saldo. Isso ajudará a considerar a proporção relativa do patrimônio líquido em relação ao saldo, tornando o indicador mais comparável entre diferentes contas.
Além disso, adicionaremos a relação de variação do patrimônio líquido para o saldo, o que permitirá considerar a mudança relativa do patrimônio líquido ao longo do tempo.
Finalmente, introduziremos a relação dos lucros/perdas acumulados para o saldo, a fim de considerar a magnitude relativa dos resultados de negociação acumulados em relação ao saldo da conta.
Essas mudanças permitirão criar um modelo mais versátil, capaz de operar eficientemente com contas de tamanhos diferentes e levar em conta seu estado relativo.
State1.Add((sState.account[0] - prev_balance) / prev_balance); State1.Add(sState.account[1] / prev_balance); State1.Add((sState.account[1] - prev_equity) / prev_equity); State1.Add(sState.account[3] / 100.0f); State1.Add(sState.account[4] / prev_balance); State1.Add(sState.account[5]); State1.Add(sState.account[6]); State1.Add(sState.account[7] / prev_balance); State1.Add(sState.account[8] / prev_balance);
Ao concluir a preparação dos dados para o modelo, criaremos um vetor one-hot aleatório, que servirá como identificador de habilidade. Um vetor one-hot é um vetor binário em que apenas um elemento é igual a 1, enquanto os outros elementos são iguais a 0. Isso permite que o modelo distinga e identifique habilidades diferentes com base no valor do elemento correspondente a uma habilidade específica.
A criação do vetor one-hot aleatório garante diversidade e diferenciação dos identificadores de habilidade em cada exemplo de dados, de acordo com nossa concepção de "Diversity is All You Need".
vector<float> one_hot = vector<float>::Zeros(NSkills); int skill=(int)MathRound(MathRand()/32767.0*(NSkills-1)); one_hot[skill] = 1; State1.AddArray(one_hot);
Nesta etapa, transmitimos os dados de entrada preparados para o modelo do Ator e realizamos uma propagação através do modelo. A propagação é o processo de transmitir os dados de entrada pelas camadas do modelo e obter os respectivos valores de saída.
Após a conclusão da propagação, obtemos os resultados do modelo, que representam as probabilidades para cada ação, determinadas pelo modelo do Ator. Para escolher a ação a ser realizada, amostramos (escolhemos aleatoriamente com base nas probabilidades) uma das possíveis ações com base nas probabilidades obtidas.
A amostragem de ações permite que o Ator explore ao máximo o ambiente, considerando cada habilidade. Isso aumenta a diversidade das ações que o modelo pode tomar e ajuda a evitar a escolha excessivamente frequente das mesmas ações. Esse abordagem proporciona maior flexibilidade ao modelo e a capacidade de se adaptar a várias situações no ambiente.
if(!Actor.feedForward(GetPointer(State1), 1, false)) return; int act = Actor.getSample();
O código adicional do método foi retirado da versão anterior do EA sem quaisquer alterações. O código completo do EA, incluindo todos os seus métodos, pode ser encontrado no arquivo anexo.
Os artigos anteriores já descreveram detalhadamente o processo de coleta do banco de dados de exemplos, portanto não nos repetiremos e procederemos imediatamente ao desenvolvimento do EA "DIAYN\Study.mq5" para treinamento de modelos. Em grande parte, utilizamos o código desenvolvido anteriormente, porém fizemos mudanças significativas no método de treinamento denominado Train.
É importante observar que nos afastamos um pouco do algoritmo original proposto pelos autores do método. No nosso Expert Advisor, estamos treinando simultaneamente o modelo de habilidades e o planejador. É claro que o discriminador também é treinado, de acordo com o conceito de "Diversity is All You Need".
Dessa forma, buscamos alcançar diversidade nas habilidades e comportamentos dos modelos, visando obter resultados mais robustos e eficientes.
Como antes, o treinamento dos modelos ocorre dentro de um laço. O número de iterações desse laço é determinado pelos parâmetros externos do Expert Advisor.
Em cada iteração do laço de treinamento, escolhemos aleatoriamente uma trajetória e um estado da base de exemplos. Após a seleção do estado, carregamos os dados históricos de movimentação de preços e indicadores em um buffer de dados, da mesma forma que é feito no Expert Advisor para a coleta de dados.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State1.AssignArray(Buffer[tr].States[i].state);
Também adicionamos os dados do estado da conta e das posições abertas no mesmo buffer de dados. Conforme mencionado anteriormente, convertemos esses dados em unidades relativas para garantir um funcionamento mais estável dos modelos com diferentes tamanhos de contas. Isso nos permite padronizar a representação do estado da conta e das posições abertas no modelo, assegurando comparabilidade para fins de treinamento.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State1.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State1.Add(Buffer[tr].States[i].account[1] / PrevBalance); State1.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State1.Add(Buffer[tr].States[i].account[3] / 100.0f); State1.Add(Buffer[tr].States[i].account[4] / PrevBalance); State1.Add(Buffer[tr].States[i].account[5]); State1.Add(Buffer[tr].States[i].account[6]); State1.Add(Buffer[tr].States[i].account[7] / PrevBalance); State1.Add(Buffer[tr].States[i].account[8] / PrevBalance);
Os dados preparados são suficientes para o modelo do planejador, e podemos realizar uma propagação pela modelo para determinar qual habilidade será usada.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Scheduler.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Após a conclusão da propagação pelo modelo do planejador e a obtenção do vetor de probabilidades, formamos o vetor one-hot de identificação da habilidade. Aqui temos duas opções para escolher a habilidade: o método "ganancioso", que escolhe a habilidade com a maior probabilidade, e a amostragem, onde escolhemos uma habilidade aleatoriamente, levando em consideração as probabilidades.
Durante a fase de treinamento, é recomendável usar amostragem para explorar ao máximo o ambiente. Isso permite que o modelo explore diferentes habilidades e descubra oportunidades e estratégias ocultas. Durante o treinamento, a amostragem ajuda a evitar convergência prematura para uma habilidade específica e garante ações de exploração mais diversificadas, contribuindo para o treinamento de um modelo mais flexível e adaptável.
int skill = Scheduler.getSample(); SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; State1.AddArray(SchedulerResult);
O vetor resultante de identificação da habilidade é adicionado ao buffer de dados de entrada, que é alimentado ao modelo do Agente. Em seguida, uma propagação pelo modelo do Agente é executada para gerar uma ação. A distribuição de probabilidade obtida a partir do modelo é usada para a amostragem da ação.
Amostrar uma ação a partir da distribuição de probabilidade permite que o modelo do Agente tome decisões diversas, baseadas nas probabilidades de cada ação. Isso promove a exploração de diferentes estratégias e opções de comportamento, além de ajudar o modelo a evitar a fixação prematura em uma ação específica.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } int action = Actor.getSample();
Após a conclusão da propagação pelo modelo do Agente, passamos à formação do buffer de dados para a propagação pelo modelo do Discriminador, onde descreveremos o próximo estado do sistema. Semelhante ao passo anterior, começamos carregando os dados históricos no buffer. Nesse caso, simplesmente copiamos os dados históricos da base de exemplos para o buffer de dados sem problemas, uma vez que esses indicadores não dependem do modelo e das habilidades usadas.
State1.AssignArray(Buffer[tr].States[i + 1].state);
Encontramos algumas complexidades ao lidar com a descrição do estado da conta. Não podemos simplesmente pegar os dados da base de exemplos, já que raramente corresponderiam à ação escolhida. Da mesma forma, não podemos apenas inserir a ação da base de exemplos, pois o discriminador analisará o estado de entrada e o relacionará à habilidade usada. Aqui está a discrepância.
No entanto, é importante notar que o resultado do discriminador é usado apenas como uma função de recompensa. Não precisamos de alta precisão na descrição do novo estado da conta. Em vez disso, precisamos que os dados sejam comparáveis ao realizar diferentes ações. Portanto, podemos fazer uma estimativa aproximada dos valores dos indicadores do estado da conta com base no estado anterior, considerando o tamanho da última vela e a ação escolhida. Todos os dados necessários para o cálculo já estão disponíveis.
Na primeira etapa, copiamos os dados da conta do estado anterior e calculamos o lucro para uma posição longa ao mover o preço pelo tamanho da última vela. Aqui, não consideramos o volume específico da posição e sua direção, isso será considerado mais tarde.
vector<float> account; account.Assign(Buffer[tr].States[i].account); int bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT);
Em seguida, fazemos ajustes nos dados do estado da conta com base na ação escolhida. O caso mais simples é o fechamento das posições. Simplesmente adicionamos o lucro ou a perda acumulados ao estado atual da conta. O valor resultante é então transferido para os elementos de capital líquido e margem livre, enquanto os outros indicadores são zerados.
Ao executar uma operação de negociação, precisamos aumentar a posição correspondente. Dado que todas as transações são realizadas com um lote mínimo, aumentamos o tamanho da posição apropriada em um lote mínimo.
Para calcular o lucro ou prejuízo acumulado em cada direção, multiplicamos o lucro previamente calculado para um lote pelo tamanho da posição correspondente. Como já calculamos o lucro para uma posição longa, adicionamos esse valor ao lucro acumulado anterior para posições longas e subtraímos para posições curtas. O lucro total da conta é obtido somando os lucros em diferentes direções.
O patrimônio líquido é calculado como a soma do saldo e do lucro acumulado.
Os indicadores de margem permanecem inalterados, uma vez que a alteração em um lote mínimo será insignificante.
No caso de manter uma posição, a abordagem é semelhante, exceto pelo ajuste do tamanho da posição.
switch(action) { case 0: account[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 1: account[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 2: account[0] += account[4]; account[1] = account[0]; account[2] = account[0]; for(bar = 3; bar < AccountDescr; bar++) account[bar] = 0; break; case 3: account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; }
Após a correção dos dados do estado da conta e posições abertas, adicionamos esses dados ao buffer. Da mesma forma que antes, convertemos seus valores em unidades relativas e realizamos a propagação pelo modelo do discriminador.
PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; State1.Add((account[0] - PrevBalance) / PrevBalance); State1.Add(account[1] / PrevBalance); State1.Add((account[1] - PrevEquity) / PrevEquity); State1.Add(account[3] / 100.0f); State1.Add(account[4] / PrevBalance); State1.Add(account[5]); State1.Add(account[6]); State1.Add(account[7] / PrevBalance); State1.Add(account[8] / PrevBalance); //--- if(!Discriminator.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Após a propagação pelo discriminador, comparamos seus resultados com o vetor one-hot que contém a identificação da habilidade usada na propagação pelo agente.
Discriminator.getResults(DiscriminatorResult);
Actor.getResults(ActorResult);
ActorResult[action] = DiscriminatorResult.Loss(SchedulerResult, LOSS_CCE);
O valor da entropia cruzada obtido ao comparar os dois vetores é usado como recompensa para a ação escolhida. Essa recompensa nos permite realizar uma retropropagação pelo modelo do agente e atualizar seus pesos para melhorar as escolhas de ações futuras.
Result.AssignArray(ActorResult); State1.AddArray(SchedulerResult); if(!Actor.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
O vetor one-hot de identificação da habilidade usada é o valor alvo no treinamento do modelo do discriminador. Usamos esse vetor como alvo para ensinar o discriminador a classificar corretamente os estados do sistema de acordo com a habilidade escolhida.
Result.AssignArray(SchedulerResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Como recompensa para o planejador, usamos apenas a alteração no saldo da conta. Calculamos esse valor com precisão e o transmitimos como valores relativos. No entanto, ao contrário do agente, que recebe recompensa apenas pela ação escolhida, distribuímos a recompensa do planejador entre todas as habilidades, com base nas probabilidades de escolha de cada habilidade. Assim, a recompensa do planejador é dividida entre as habilidades de acordo com suas probabilidades de escolha.
Result.AssignArray(SchedulerResult * ((account[0] - PrevBalance) / PrevBalance)); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Após cada iteração do laço de treinamento, geramos uma mensagem informativa contendo dados sobre o processo de treinamento. Essa mensagem é exibida no gráfico para visualização do processo. Em seguida, avançamos para a próxima iteração, continuando o processo de treinamento.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Ao concluir o processo de treinamento, limpamos as mensagens no gráfico, removendo os dados informativos anteriores. Em seguida, iniciamos o encerramento do funcionamento do Expert Advisor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Discriminator", Discriminator.getRecentAverageError()); ExpertRemove(); //--- }
Em anexo, você encontrará o código completo de todos os métodos e funções utilizados no Expert Advisor. Você pode revisá-lo para obter informações detalhadas.
3. Teste
O modelo foi treinado em dados históricos do instrumento EURUSD com um intervalo de tempo de H1 durante os primeiros quatro meses de 2023. Durante o processo de treinamento, foi identificado um erro não representativo relacionado à política de recompensas do modelo do agente, o qual poderia resultar em crescimento de recompensa não limitado. No entanto, o processo de treinamento ainda é controlado pelos indicadores dos modelos do planejador e do discriminador.
Uma segunda característica do processo é a falta de dependência direta entre a escolha do planejador e a ação realizada. A escolha do planejador influencia mais a escolha de estratégia do que uma ação específica. Isso significa que o planejador determina a abordagem geral de tomada de decisões, enquanto a ação específica é escolhida pelo modelo do agente com base no estado atual e na habilidade selecionada.
Para verificar a funcionalidade do modelo treinado, utilizamos dados das duas primeiras semanas de maio de 2023, que não foram incluídas no conjunto de treinamento, mas seguem de perto o período de treinamento. Esse método nos permite avaliar o desempenho do modelo em novos dados, enquanto mantemos a comparabilidade dos dados, já que não há intervalo de tempo entre os conjuntos de treinamento e teste.
Para o teste, utilizamos o Expert Advisor modificado "DIAYN\Test.mq5". As alterações feitas afetaram apenas os algoritmos de preparação de dados de acordo com a arquitetura dos modelos e o processo de preparação de dados iniciais. A sequência de chamadas para as propagações dos modelos também foi alterada. O processo foi construído de maneira semelhante aos Expert Advisors descritos anteriormente para coleta de dados de base e treinamento de modelos. O código detalhado do Expert Advisor está disponível no anexo.


Como resultado do teste do modelo treinado, um pequeno lucro foi obtido, com um fator de lucro de 1.61 e um fator de recuperação de 3.21. Durante o período de teste de 240 barras, o modelo realizou 119 negociações, sendo que quase 55% delas foram encerradas com lucro.
O planejador desempenhou um papel significativo na obtenção desses resultados, distribuindo uniformemente o uso de todas as habilidades. É importante observar que foi utilizada uma estratégia gananciosa para a escolha de ações e habilidades. O modelo escolheu a ação mais lucrativa com base no estado atual.

Considerações finais
Este artigo apresentou uma abordagem para treinar um modelo de negociação baseado no método DIAYN (Diversity Is All You Need), que permite treinar o modelo em diversas habilidades sem estar vinculado a uma tarefa específica.
O modelo foi treinado em dados históricos do instrumento EURUSD usando o intervalo de tempo H1 durante os primeiros 4 meses de 2023.
Durante o processo de treinamento, foi identificada a ausência de uma dependência direta entre a escolha do planejador e a ação realizada. No entanto, o processo de treinamento permaneceu controlado e demonstrou alguma capacidade do modelo de negociação lucrativa.
Após a conclusão do treinamento, o modelo foi testado em novos dados que não foram incluídos no conjunto de treinamento. Os resultados dos testes mostraram um pequeno lucro, com um fator de lucro de 1.61 e um fator de recuperação de 3.21. No entanto, para alcançar resultados mais estáveis e elevados, é necessário continuar otimizando e aprimorando a estratégia do modelo.
Um aspecto importante do funcionamento do modelo foi o planejador, que distribuiu uniformemente o uso de todas as habilidades. Isso destaca a importância do desenvolvimento de estratégias eficazes de tomada de decisão para alcançar resultados bem-sucedidos na negociação.
Em resumo, a abordagem apresentada para treinar um modelo de negociação com base no método DIAYN oferece perspectivas interessantes para o desenvolvimento do comércio automatizado. Pesquisas e melhorias contínuas nessa abordagem podem levar à criação de modelos de negociação mais eficazes e lucrativos.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | Study.mql5 | EA | EA para treinamento de modelos |
| 3 | Test.mq5 | EA | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | FQF.mqh | Biblioteca de classe | Biblioteca de classes de preparação de modelos totalmente parametrizada |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para a criação de uma rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/12698
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso