Support and Resistance AI by K clustering MT4
- Индикаторы
- Minh Truong Pham
- Версия: 1.3
- Активации: 5
█ OVERVIEW
K-means is a clustering algorithm commonly used in machine learning to group data points into distinct clusters based on their similarities. While K-means is not typically used directly for identifying support and resistance levels in financial markets, it can serve as a tool in a broader analysis approach.
Support and resistance levels are price levels in financial markets where the price tends to react or reverse. Support is a level where the price tends to stop falling and might start to rise, while resistance is a level where the price tends to stop rising and might start to fall. Traders and analysts often look for these levels as they can provide insights into potential price movements and trading opportunities.
█ BACKGROUND
The K-means algorithm has been around since the late 1950s, making it more than six decades old. The algorithm was introduced by Stuart Lloyd in his 1957 research paper "Least squares quantization in PCM" for telecommunications applications. However, it wasn't widely known or recognized until James MacQueen's 1967 paper "Some Methods for Classification and Analysis of Multivariate Observations," where he formalized the algorithm and referred to it as the "K-means" clustering method.
So, while K-means has been around for a considerable amount of time, it continues to be a widely used and influential algorithm in the fields of machine learning, data analysis, and pattern recognition due to its simplicity and effectiveness in clustering tasks.
█ COMPARE AND CONTRAST SUPPORT AND RESISTANCE METHODS
1) K-means Approach:
2) Traditional Approach:
The key difference lies in the approach and the foundation of these methods. Traditional methods are based on well-established principles of technical analysis and market psychology, while the K-means approach involves clustering price behavior without necessarily incorporating market sentiment or specific price patterns.
It's important to note that while the K-means approach might provide an interesting way to analyze price data, it should be used cautiously and in conjunction with other traditional methods. Financial markets are influenced by a wide range of factors beyond just price behavior, and the effectiveness of any method for identifying support and resistance levels should be thoroughly tested and validated. Additionally, developments in trading strategies and analysis techniques could have occurred since my last update.
█ K MEANS ALGORITHM
The algorithm for K means is as follows:
█ LIMITATIONS OF K MEANS
There are 3 main limitations of this algorithm:
█ LIMITATIONS IN APPLICATION OF K MEANS IN TRADING
Trading data often exhibits characteristics that can pose challenges when applying indicators and analysis techniques. Here's how the limitations of outliers, varying scales, and unequal variance can impact the use of indicators in trading:
█ APPLICATION OF THIS INDICATOR
This indicator can be used in 2 ways:
1) Make a directional trade:
General Settings:
Features:
Besides the support and resistance levels and standard deviation bands, this indicator gives a table in the upper right hand corner to show the density of each cluster (support and resistance level) and is color coded to the cluster line on the chart. Higher density clusters mean price has been there previously more than lower density clusters and could mean a higher likelihood of a reversal when price reaches these areas.
█ WORKS CITED
K-means is a clustering algorithm commonly used in machine learning to group data points into distinct clusters based on their similarities. While K-means is not typically used directly for identifying support and resistance levels in financial markets, it can serve as a tool in a broader analysis approach.
Support and resistance levels are price levels in financial markets where the price tends to react or reverse. Support is a level where the price tends to stop falling and might start to rise, while resistance is a level where the price tends to stop rising and might start to fall. Traders and analysts often look for these levels as they can provide insights into potential price movements and trading opportunities.
█ BACKGROUND
The K-means algorithm has been around since the late 1950s, making it more than six decades old. The algorithm was introduced by Stuart Lloyd in his 1957 research paper "Least squares quantization in PCM" for telecommunications applications. However, it wasn't widely known or recognized until James MacQueen's 1967 paper "Some Methods for Classification and Analysis of Multivariate Observations," where he formalized the algorithm and referred to it as the "K-means" clustering method.
So, while K-means has been around for a considerable amount of time, it continues to be a widely used and influential algorithm in the fields of machine learning, data analysis, and pattern recognition due to its simplicity and effectiveness in clustering tasks.
█ COMPARE AND CONTRAST SUPPORT AND RESISTANCE METHODS
1) K-means Approach:
- Cluster Formation: After applying the K-means algorithm to historical price change data and visualizing the resulting clusters, traders can identify distinct regions on the price chart where clusters are formed. Each cluster represents a group of similar price change patterns.
- Cluster Analysis: Analyze the clusters to identify areas where clusters tend to form. These areas might correspond to regions of price behavior that repeat over time and could be indicative of support and resistance levels.
- Potential Support and Resistance Levels: Based on the identified areas of cluster formation, traders can consider these regions as potential support and resistance levels. A cluster forming at a specific price level could suggest that this level has been historically significant, causing similar price behavior in the past.
- Cluster Standard Deviation: In addition to looking at the means (centroids) of the clusters, traders can also calculate the standard deviation of price changes within each cluster. Standard deviation is a measure of the dispersion or volatility of data points around the mean. A higher standard deviation indicates greater price volatility within a cluster.
- Low Standard Deviation: If a cluster has a low standard deviation, it suggests that prices within that cluster are relatively stable and less likely to exhibit sudden and large price movements. Traders might consider placing tighter stop-loss orders for trades within these clusters.
- High Standard Deviation: Conversely, if a cluster has a high standard deviation, it indicates greater price volatility within that cluster. Traders might opt for wider stop-loss orders to allow for potential price fluctuations without getting stopped out prematurely.
- Cluster Density: Each data point is assigned to a cluster so a cluster that is more dense will act more like gravity and
2) Traditional Approach:
- Trendlines: Draw trendlines connecting significant highs or lows on a price chart to identify potential support and resistance levels.
- Chart Patterns: Identify chart patterns like double tops, double bottoms, head and shoulders, and triangles that often indicate potential reversal points.
- Moving Averages: Use moving averages to identify levels where the price might find support or resistance based on the average price over a specific period.
- Psychological Levels: Identify round numbers or levels that traders often pay attention to, which can act as support and resistance.
- Previous Highs and Lows: Identify significant previous price highs and lows that might act as support or resistance.
The key difference lies in the approach and the foundation of these methods. Traditional methods are based on well-established principles of technical analysis and market psychology, while the K-means approach involves clustering price behavior without necessarily incorporating market sentiment or specific price patterns.
It's important to note that while the K-means approach might provide an interesting way to analyze price data, it should be used cautiously and in conjunction with other traditional methods. Financial markets are influenced by a wide range of factors beyond just price behavior, and the effectiveness of any method for identifying support and resistance levels should be thoroughly tested and validated. Additionally, developments in trading strategies and analysis techniques could have occurred since my last update.
█ K MEANS ALGORITHM
The algorithm for K means is as follows:
- Initialize cluster centers
- assign data to clusters based on minimum distance
- calculate cluster center by taking the average or median of the clusters
- repeat steps 1-3 until cluster centers stop moving
█ LIMITATIONS OF K MEANS
There are 3 main limitations of this algorithm:
- Sensitive to Initializations: K-means is sensitive to the initial placement of centroids. Different initializations can lead to different cluster assignments and final results.
- Assumption of Equal Sizes and Variances: K-means assumes that clusters have roughly equal sizes and spherical shapes. This may not hold true for all types of data. It can struggle with identifying clusters with uneven densities, sizes, or shapes.
- Impact of Outliers: K-means is sensitive to outliers, as a single outlier can significantly affect the position of cluster centroids. Outliers can lead to the creation of spurious clusters or distortion of the true cluster structure.
█ LIMITATIONS IN APPLICATION OF K MEANS IN TRADING
Trading data often exhibits characteristics that can pose challenges when applying indicators and analysis techniques. Here's how the limitations of outliers, varying scales, and unequal variance can impact the use of indicators in trading:
- Outliers are data points that significantly deviate from the rest of the dataset. In trading, outliers can represent extreme price movements caused by rare events, news, or market anomalies. Outliers can have a significant impact on trading indicators and analyses:
Indicator Distortion: Outliers can skew the calculations of indicators, leading to misleading signals. For instance, a single extreme price spike could cause indicators like moving averages or RSI (Relative Strength Index) to give false signals.
Risk Management: Outliers can lead to overly aggressive trading decisions if not properly accounted for. Ignoring outliers might result in unexpected losses or missed opportunities to adjust trading strategies. - Different Scales: Trading data often includes multiple indicators with varying units and scales. For example, prices are typically in dollars, volume in units traded, and oscillators have their own scale. Mixing indicators with different scales can complicate analysis:
Normalization: Indicators on different scales need to be normalized or standardized to ensure they contribute equally to the analysis. Failure to do so can lead to one indicator dominating the analysis due to its larger magnitude.
Comparability: Without normalization, it's challenging to directly compare the significance of indicators. Some indicators might have a larger numerical range and could overshadow others. - Unequal Variance: Unequal variance in trading data refers to the fact that some indicators might exhibit higher volatility than others. This can impact the interpretation of signals and the performance of trading strategies:
Volatility Adjustment: When combining indicators with varying volatility, it's essential to adjust for their relative volatilities. Failure to do so might lead to overemphasizing or underestimating the importance of certain indicators in the trading strategy.
Risk Assessment: Unequal variance can impact risk assessment. Indicators with higher volatility might lead to riskier trading decisions if not properly taken into account.
█ APPLICATION OF THIS INDICATOR
This indicator can be used in 2 ways:
1) Make a directional trade:
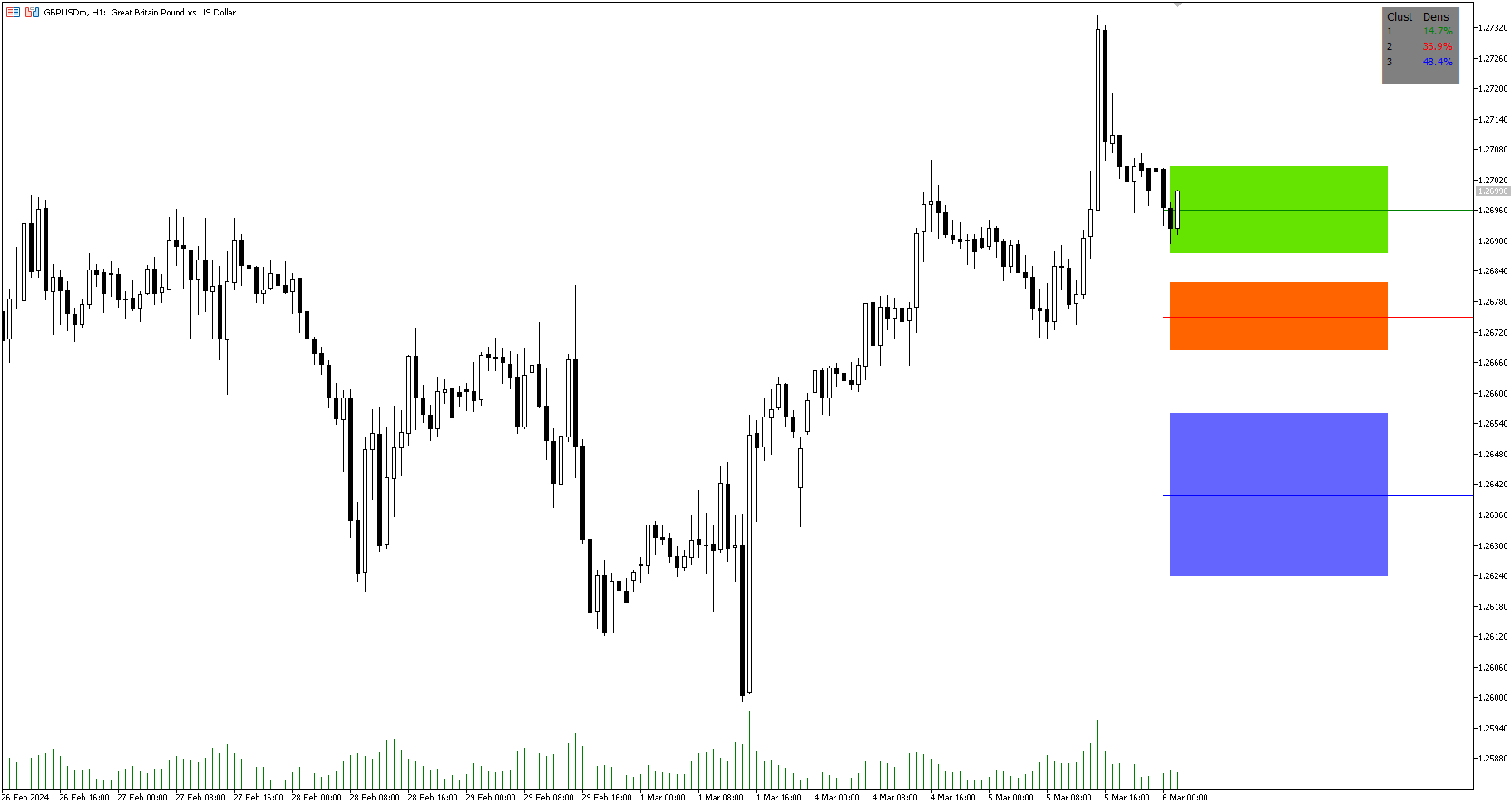
- If a trader thinks price will go higher or lower and price is within a cluster zone, The trader can take a position and place a stop on the 1 sd band around the cluster. As one can see below, the trader can go long the green arrow and place a stop on the one standard deviation mark for that cluster below it at the red arrow. using this we can calculate a risk to reward ratio.
- Calculating risk to reward: targeting a risk reward ratio of 2:1, the trader could clearly make that given that the next resistance area above that in the orange cluster exceeds this risk reward ratio.
Image 1
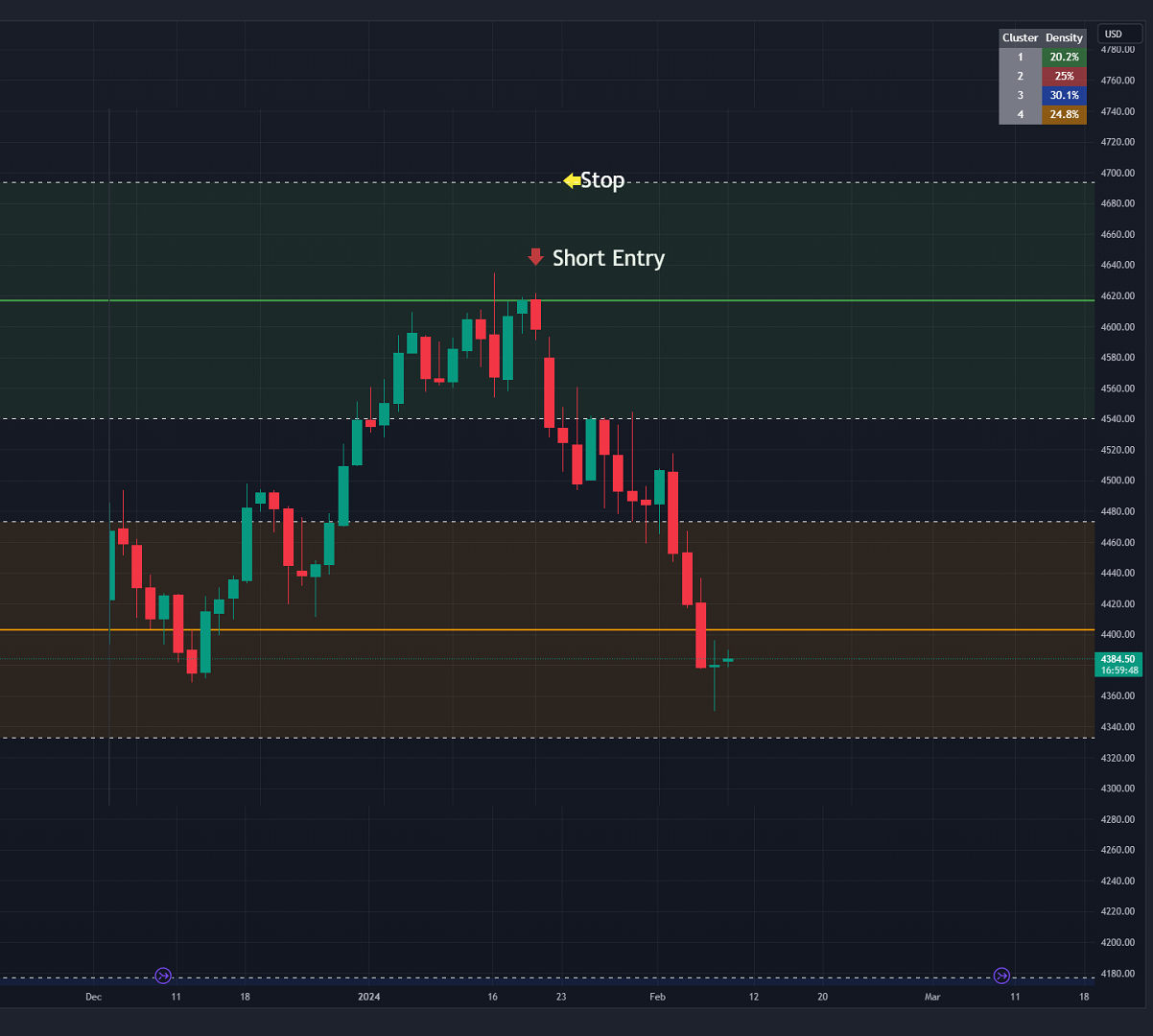
2) Take a reversal Trade:- We can use cluster centers (support and resistance levels) to go in the opposite direction that price is currently moving in hopes of price forming a pivot and reversing off this level.
- Similar to the directional trade, we can use the standard deviation of the cluster to place a stop just in case we are wrong.
- In this example below we can see that shorting on the red arrow and placing a stop at the one standard deviation above this cluster would give us a profitable trade with minimal risk.
- Using the cluster density table in the upper right informs the trader just how dense the cluster is. Higher density clusters will give a higher likelihood of a pivot forming at these levels and price being rejected and switching direction with a larger move.
Image 2
█ FEATURES & SETTINGSGeneral Settings:
- Number of clusters: The user can select from 3 to five clusters. A good rule of thumb is that if you are trading intraday, less is more (Think 3 rather than 5). For daily 4 to 5 clusters is good.
- Cluster Method: To get around the outlier limitation of k means clustering, The median was added. This gives the user the ability to choose either k means or k median clustering. K means is the preferred method if the user things there are no large outliers, and if there appears to be large outliers or it is assumed there are then K medians is preferred.
- Bars back To train on: This will be the amount of bars to include in the clustering. This number is important so that the user includes bars that are recent but not so far back that they are out of the scope of where price can be. For example the last 2 years we have been in a range on the sp500 so 505 days in this setting would be more relevant than say looking back 5 years ago because price would have to move far to get there.
- Show SD Bands: Select this to show the 1 standard deviation bands around the support and resistance level or unselect this to just show the support and resistance level by itself.
- Show Panel: Display panel to show infor of zones.
Features:
Besides the support and resistance levels and standard deviation bands, this indicator gives a table in the upper right hand corner to show the density of each cluster (support and resistance level) and is color coded to the cluster line on the chart. Higher density clusters mean price has been there previously more than lower density clusters and could mean a higher likelihood of a reversal when price reaches these areas.
█ WORKS CITED
- Victor Sim, "Using K-means Clustering to Create Support and Resistance", 2020, towardsdatascience.c...sistance-b13fdeeba12
- Chris Piech, "K means", stanford.edu/~cpiech...handouts/kmeans.html