Кодировки...
Вот пример скрипта, демонстрирующего работу с этими функциями:
#import "kernel32.dll" int MultiByteToWideChar(int CodePage, int dwFlags, string lpMultiByteStr, int cbMultiByte, int& lpWideCharStr[], int cchWideChar); int WideCharToMultiByte(int CodePage, int dwFlags, int lpWideCharStr[], int cchWideChar, string lpMultiByteStr, int cbMultiByte, int lpDefaultChar, int lpUsedDefaultChar); #import void start() { string in_lpMultiByteStr = "MetaQuotes::MetaTrader::4.00"; //ANSI строка string out_lpMultiByteStr = " "; int cchWideChar, lpWideCharStr[]; //---- определяем количество символов, необходимых для хранения Unicode-версии строки cchWideChar = MultiByteToWideChar(0, 0, in_lpMultiByteStr, -1, lpWideCharStr, 0); //---- задаем размер массива для Unicode строки ArrayResize(lpWideCharStr,cchWideChar/2); //---- преобразуем ANSI-версию строки в Unicode MultiByteToWideChar(0, 0, in_lpMultiByteStr, -1, lpWideCharStr, cchWideChar); //---- для проверки запишем массив, содержащий Unicode строку, в бинарный файл int handle = FileOpen("wchar.bin",FILE_BIN|FILE_WRITE); FileWriteArray(handle,lpWideCharStr,0,ArraySize(lpWideCharStr)); FileClose(handle); //---- преобразуем Unicode-версию строки обратно в ANSI WideCharToMultiByte(0, 0, lpWideCharStr, cchWideChar, out_lpMultiByteStr, StringLen(out_lpMultiByteStr)+1, 0, 0); Print(out_lpMultiByteStr); }
Здесь ANSI-версия строки объявлена как строковая переменная in_lpMultiByteStr, а Unicode-версия - как массив целых чисел lpWideCharStr[].
Для проверки корректности преобразования массив, содержащий Unicode символы, записывается в двоичный файл wchar.bin.
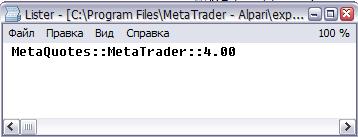
Вот как выглядит содержание файла при различных режимах просмотра:
1) Hex
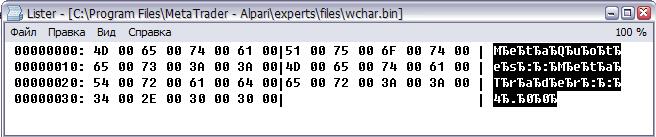
2) Unicode
Спасибо огромнейшее!!!!!!!!!!!!!!
есть над чем поработать...
Однако что-то мне кажется не в том месте я начал копать.
*
Для чего это надо:
1. Читать загруженое с сайта, а это довольно часто кодировки UTF-8 или KOI-8r
2. Отравлять на сайт сформрованый файл в кодировке UTF-8
(сейчас приходится вручную конвертировать каждый раз...)
*
Если п.2 не столь важен, то п.1 весьма нужен...
Спасибо огромнейшее!!!!!!!!!!!!!!
есть над чем поработать...
Однако что-то мне кажется не в том месте я начал копать.
*
Для чего это надо:
1. Читать загруженое с сайта, а это довольно часто кодировки UTF-8 или KOI-8r
2. Отравлять на сайт сформрованый файл в кодировке UTF-8
(сейчас приходится вручную конвертировать каждый раз...)
*
Если п.2 не столь важен, то п.1 весьма нужен...
В API Win32 имеется два способа представления текста: в форме традиционных 8-битных кодовых страниц, и в виде Unicode UTF-16.
Один символ в кодировке UTF-16 представляется последовательностью из двух байт. Функции MultiByteToWideChar() предназначена для
преобразования из одно- и многобайтовых кодировок в UTF-16, а WideCharToMultiByte() - соответственно наоборот.
Возможно эти функции можно применить для решения Вашей задачи. Посмотрите здесь пример на Си, где показано как переводить строку из UTF-8 в ANSI.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Узнал что можно перекодировать при помощи:
MultiByteToWideChar(codepage_id,....)
WideCharToMultiByte(codepage_id,....)
поиск на сайте\форуме мкл практически ничего не дал,
но возможно кто-то это использовал...
*
Если не сложно, плизззз, поделитесь тем как импортировать эти функции.