
Начало по ссылкам:
https://www.mql5.com/ru/blogs/post/659572
https://www.mql5.com/ru/blogs/post/659929
Важно: в прошлый раз я удалил несколько записей из массива, в которых было заглядывание в значения ряда другой пары (эффект соединения вместе историй 5-ти пар). Но сделал я это только для регрессоров. Сегодня, анализируя графики, я увидел, что для заглядывания в будущее также есть такая проблема. Поэтому предыдущий код нужно дополнить следующими строками:
dat_train_final <- subset(dat_train_final, dat_train_final$future_lag_724 < 0.05 & dat_train_final$future_lag_724 > -0.05) dat_test_final <- subset(dat_test_final, dat_test_final$future_lag_724 < 0.05 & dat_test_final$future_lag_724 > -0.05)
В силу того, что вектора в массиве для обучения и валидации идут с разницей 724 +- 50 шагов, то удалить достаточно только выбросы на переменной с шагом 724.
Сегодня: разведывательный анализ данных, графическое изучение, статистическая проверка разнородности данных на обучающей и валидационной выборках.
Код на сегодня:
### loading working data dat_train_final <- read.csv('C:/R_study/fx/dat_train_final.csv' , sep = ',' , dec = '.') dat_test_final <- read.csv('C:/R_study/fx/dat_test_final.csv' , sep = ',' , dec = '.') ### charts require(ggplot2) chart_names <- c('price lags', 'mean differences', 'max differences', 'min differences', 'standard deviation', 'price range', 'future price lags') # time series for (i in 0:6){ plot_data <- as.data.frame(c(dat_train_final[, 1 + i * 18] , dat_train_final[, 2 + i * 18] , dat_train_final[, 3 + i * 18] , dat_train_final[, 4 + i * 18] , dat_train_final[, 5 + i * 18] , dat_train_final[, 6 + i * 18] , dat_train_final[, 7 + i * 18] , dat_train_final[, 8 + i * 18] , dat_train_final[, 9 + i * 18] , dat_train_final[, 10 + i * 18] , dat_train_final[, 11 + i * 18] , dat_train_final[, 12 + i * 18] , dat_train_final[, 13 + i * 18] , dat_train_final[, 14 + i * 18] , dat_train_final[, 15 + i * 18] , dat_train_final[, 16 + i * 18] , dat_train_final[, 17 + i * 18] , dat_train_final[, 18 + i * 18])) plot_data$group <- c(rep(names(dat_train_final)[1 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[2 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[3 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[4 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[5 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[6 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[7 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[8 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[9 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[10 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[11 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[12 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[13 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[14 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[15 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[16 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[17 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[18 + i * 18], nrow(dat_train_final))) plot_data$points <- c(seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final)) , seq(1:nrow(dat_train_final))) colnames(plot_data) <- c('values', 'lags', 'points') ch <- ggplot(plot_data, aes(x = points, y = values, colour = lags, group = lags)) + geom_line(alpha = 0.3) + ggtitle(chart_names[i + 1]) print(ch) } # density for (i in 0:6){ plot_data <- as.data.frame(c(dat_train_final[, 1 + i * 18] , dat_train_final[, 2 + i * 18] , dat_train_final[, 3 + i * 18] , dat_train_final[, 4 + i * 18] , dat_train_final[, 5 + i * 18] , dat_train_final[, 6 + i * 18] , dat_train_final[, 7 + i * 18] , dat_train_final[, 8 + i * 18] , dat_train_final[, 9 + i * 18] , dat_train_final[, 10 + i * 18] , dat_train_final[, 11 + i * 18] , dat_train_final[, 12 + i * 18] , dat_train_final[, 13 + i * 18] , dat_train_final[, 14 + i * 18] , dat_train_final[, 15 + i * 18] , dat_train_final[, 16 + i * 18] , dat_train_final[, 17 + i * 18] , dat_train_final[, 18 + i * 18])) plot_data$group <- c(rep(names(dat_train_final)[1 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[2 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[3 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[4 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[5 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[6 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[7 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[8 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[9 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[10 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[11 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[12 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[13 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[14 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[15 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[16 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[17 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[18 + i * 18], nrow(dat_train_final))) colnames(plot_data) <- c('values', 'lags') ch <- ggplot(plot_data, aes(x = values, fill = lags)) + geom_density(alpha = 0.3) + ggtitle(paste('density of ', chart_names[i + 1])) print(ch) } # boxplot for (i in 0:6){ plot_data <- as.data.frame(c(dat_train_final[, 1 + i * 18] , dat_train_final[, 2 + i * 18] , dat_train_final[, 3 + i * 18] , dat_train_final[, 4 + i * 18] , dat_train_final[, 5 + i * 18] , dat_train_final[, 6 + i * 18] , dat_train_final[, 7 + i * 18] , dat_train_final[, 8 + i * 18] , dat_train_final[, 9 + i * 18] , dat_train_final[, 10 + i * 18] , dat_train_final[, 11 + i * 18] , dat_train_final[, 12 + i * 18] , dat_train_final[, 13 + i * 18] , dat_train_final[, 14 + i * 18] , dat_train_final[, 15 + i * 18] , dat_train_final[, 16 + i * 18] , dat_train_final[, 17 + i * 18] , dat_train_final[, 18 + i * 18])) plot_data$group <- c(rep(names(dat_train_final)[1 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[2 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[3 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[4 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[5 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[6 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[7 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[8 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[9 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[10 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[11 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[12 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[13 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[14 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[15 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[16 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[17 + i * 18], nrow(dat_train_final)) , rep(names(dat_train_final)[18 + i * 18], nrow(dat_train_final))) plot_data$group <- as.factor(plot_data$group) colnames(plot_data) <- c('values', 'lags') ch <- ggplot(plot_data, aes(x = lags, y = values, fill = lags)) + geom_boxplot(show_guide = FALSE) + xlab('lags') + ylab('differences') + ggtitle(paste('boxplot of ', chart_names[i + 1])) print(ch) } # density comparison for train and test distr_compare <- data.frame() plot_list <- list() for (i in 1:126){ plot_data <- as.data.frame(c(dat_train_final[, i] , dat_test_final[, i])) plot_data$group <- c(rep(paste('train_', names(dat_train_final)[i], nrow(dat_train_final))) , (paste('test_', names(dat_test_final)[i], nrow(dat_test_final)))) colnames(plot_data) <- c('values', 'lags') pval <- round(ks.test(dat_train_final[, i] + rnorm(n = nrow(dat_train_final), mean = 0, sd = 0.00001) , dat_test_final[, i] + rnorm(n = nrow(dat_test_final), mean = 0, sd = 0.00001) , alternative = 'two.sided')$p.value, digits = 4) distr_compare[i, 1] <- names(dat_train_final)[i] distr_compare[i, 2] <- pval plot_list[[i]] <- ggplot(plot_data, aes(x = values, fill = lags)) + geom_density(alpha = 0.3) + ggtitle(paste('density of train and test for variable ', names(dat_train_final[i]), 'with distribution equality p-value = ', pval)) } colnames(distr_compare) <- c('variable_name','ks.tests p-value') plot(distr_compare$`ks.tests p-value`, type = 's') plot_list[[1]]
Рассмотрим подробнее. Нам понадобиться установить пакет ggplot2.
Напомню, что мы сформировали входной вектор из 108 переменных и выходной из 18 переменных.
Все входы делятся на 6 частей согласно логике их формирования:
1) приращения ряда взятые с разным лагом
2) разница последней цены со скользящей средней
3) разница последней цены со скользящим максимумом
4) разница последней цены со скользящим минимумом
5) скользящее стандартное отклонение
6) скользящий размах данных
Выходы это разница между ценой на n шагов вперед и последней известной ценой.
Шаги (лаги): 2, 3, 4, 6, 8, 11, 16, 23, 32, 35, 64, 91, 128, 181, 256, 362, 512, 724.
Напомню, что это 2 ^ (from 1 to 9.5 with step = 0.5).
Также напомню, что для обучения мы брали 2/3 истории из каждой валютной пары (то есть самое дальнее прошлое) и 1/3 каждой пары оставили для валидации. Проверка модели, таким образом, будет идти на будущих значениях ценовых рядов.
Сперва посмотрим на очень информативную но громоздкую выжимку о наших данных.
summary(dat_train_final) lag_diff_2 lag_diff_3 lag_diff_4 lag_diff_6 lag_diff_8 lag_diff_11 lag_diff_16 Min. :-1.164e-02 Min. :-1.176e-02 Min. :-1.416e-02 Min. :-1.517e-02 Min. :-1.491e-02 Min. :-1.545e-02 Min. :-1.493e-02 1st Qu.:-2.000e-04 1st Qu.:-2.000e-04 1st Qu.:-2.000e-04 1st Qu.:-3.000e-04 1st Qu.:-3.000e-04 1st Qu.:-4.000e-04 1st Qu.:-4.000e-04 Median : 0.000e+00 Median : 0.000e+00 Median : 0.000e+00 Median : 0.000e+00 Median : 0.000e+00 Median : 0.000e+00 Median : 0.000e+00 Mean :-2.165e-06 Mean :-2.373e-06 Mean :-5.480e-07 Mean :-3.982e-06 Mean :-4.110e-06 Mean : 7.570e-07 Mean : 3.493e-06 3rd Qu.: 2.000e-04 3rd Qu.: 2.000e-04 3rd Qu.: 2.000e-04 3rd Qu.: 3.000e-04 3rd Qu.: 3.000e-04 3rd Qu.: 4.000e-04 3rd Qu.: 4.000e-04 Max. : 8.900e-03 Max. : 8.700e-03 Max. : 8.900e-03 Max. : 9.100e-03 Max. : 9.500e-03 Max. : 9.500e-03 Max. : 1.030e-02 lag_diff_23 lag_diff_32 lag_diff_45 lag_diff_64 lag_diff_91 lag_diff_128 lag_diff_181 Min. :-1.382e-02 Min. :-1.420e-02 Min. :-1.710e-02 Min. :-1.99e-02 Min. :-2.020e-02 Min. :-0.024000 Min. :-2.850e-02 1st Qu.:-5.000e-04 1st Qu.:-6.000e-04 1st Qu.:-7.000e-04 1st Qu.:-8.20e-04 1st Qu.:-1.000e-03 1st Qu.:-0.001200 1st Qu.:-1.400e-03 Median : 0.000e+00 Median : 0.000e+00 Median : 0.000e+00 Median : 0.00e+00 Median : 0.000e+00 Median : 0.000000 Median : 0.000e+00 Mean : 5.935e-06 Mean : 5.528e-06 Mean :-2.476e-06 Mean :-2.15e-07 Mean : 1.225e-05 Mean : 0.000008 Mean : 1.832e-05 3rd Qu.: 5.000e-04 3rd Qu.: 6.000e-04 3rd Qu.: 7.000e-04 3rd Qu.: 8.00e-04 3rd Qu.: 1.010e-03 3rd Qu.: 0.001200 3rd Qu.: 1.500e-03 Max. : 1.470e-02 Max. : 1.560e-02 Max. : 2.430e-02 Max. : 2.60e-02 Max. : 3.290e-02 Max. : 0.034920 Max. : 3.588e-02 lag_diff_256 lag_diff_362 lag_diff_512 lag_diff_724
# etc.
Функция summary дает представление о параметрах распределения и очень полезна всегда.
Теперь перейдем к графическому анализу
Сначала я строю для каждого блока переменных набор графиков типа "линия" - то есть в каждом графике будет по 18 переменных, соответствующих лагам.
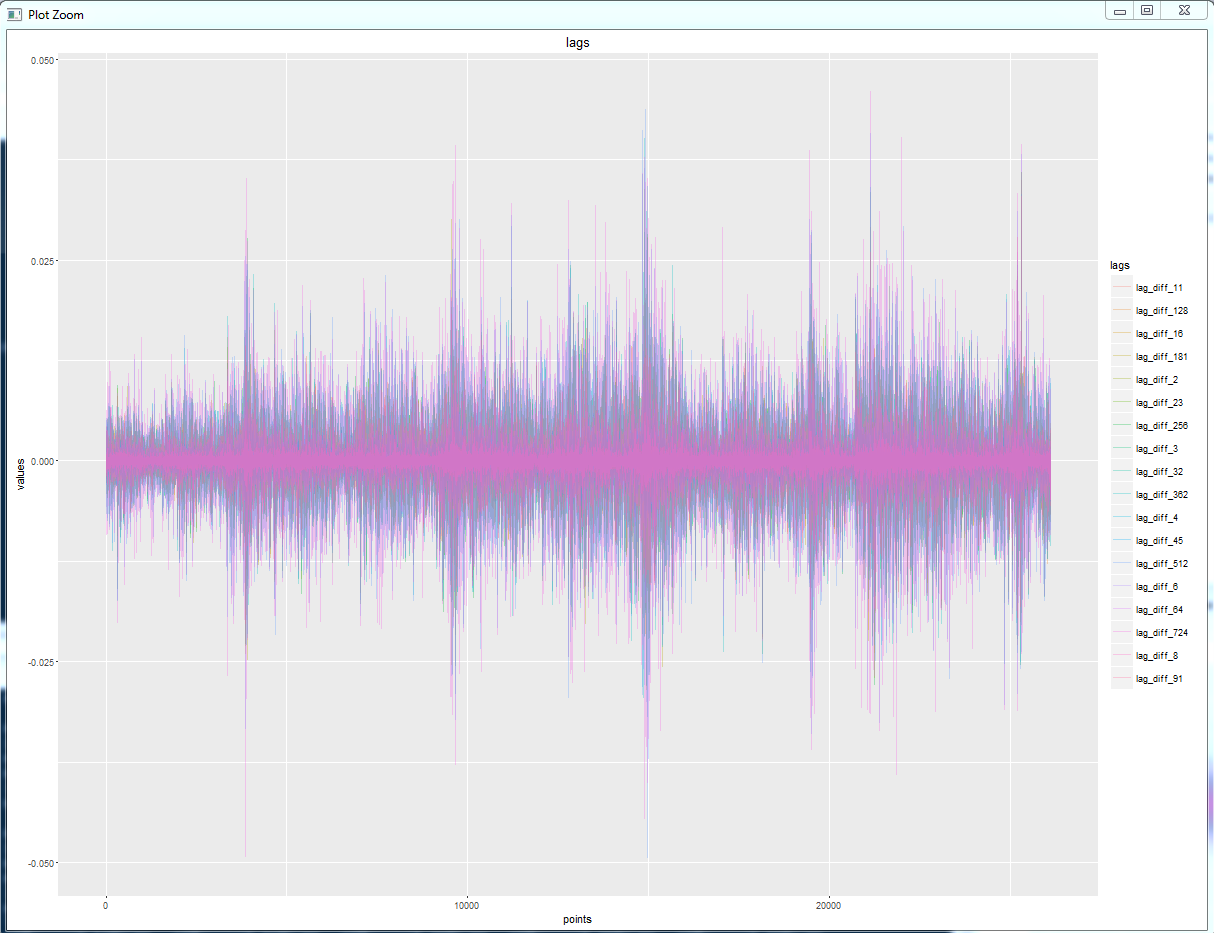
Вот так, например, выглядят разницы цен (price[t] - price[t - k]).
А теперь посмотрим на плотности вероятности этих же переменных.
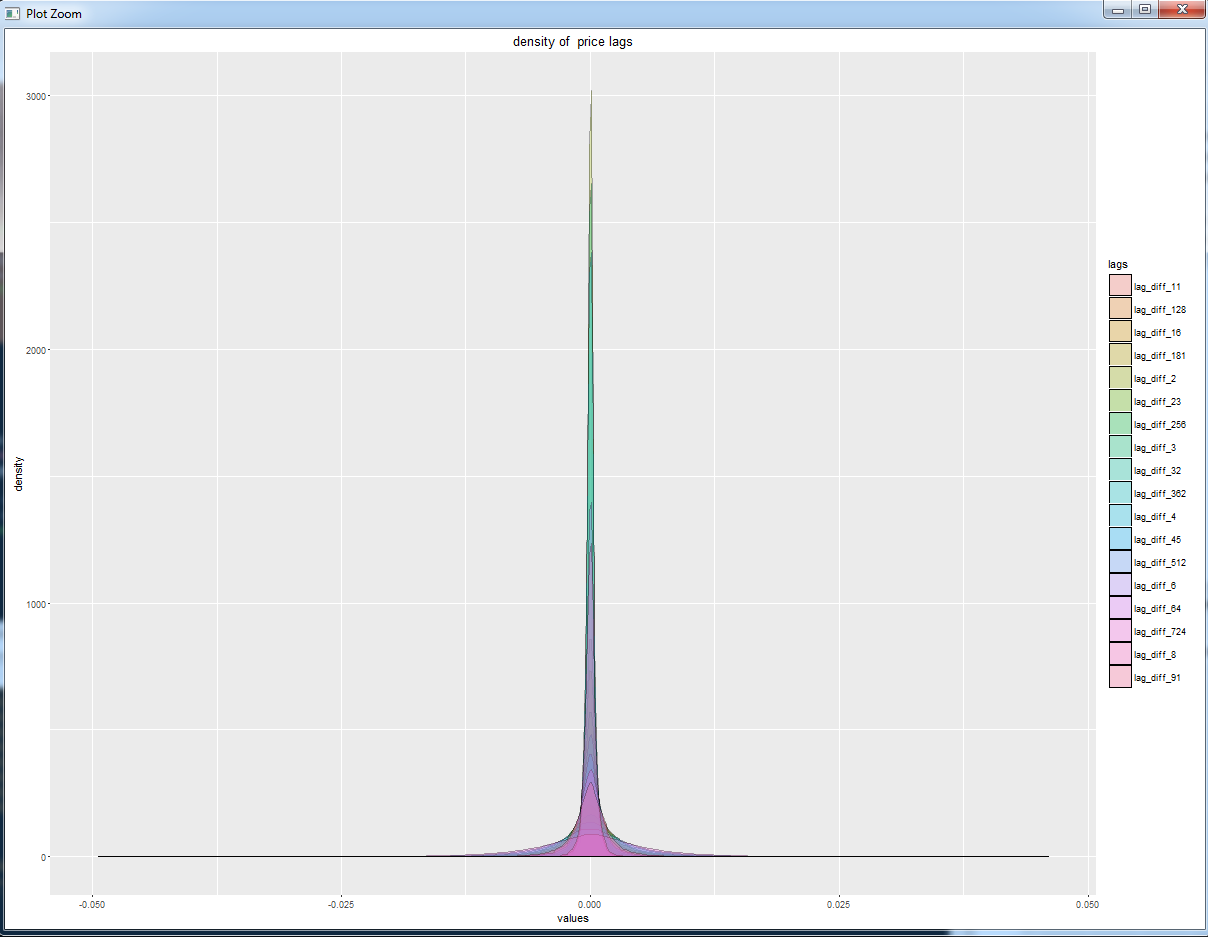
Зайдем с другой стороны. Посмотрим boxplot - ящик с усами для все тех же переменных.
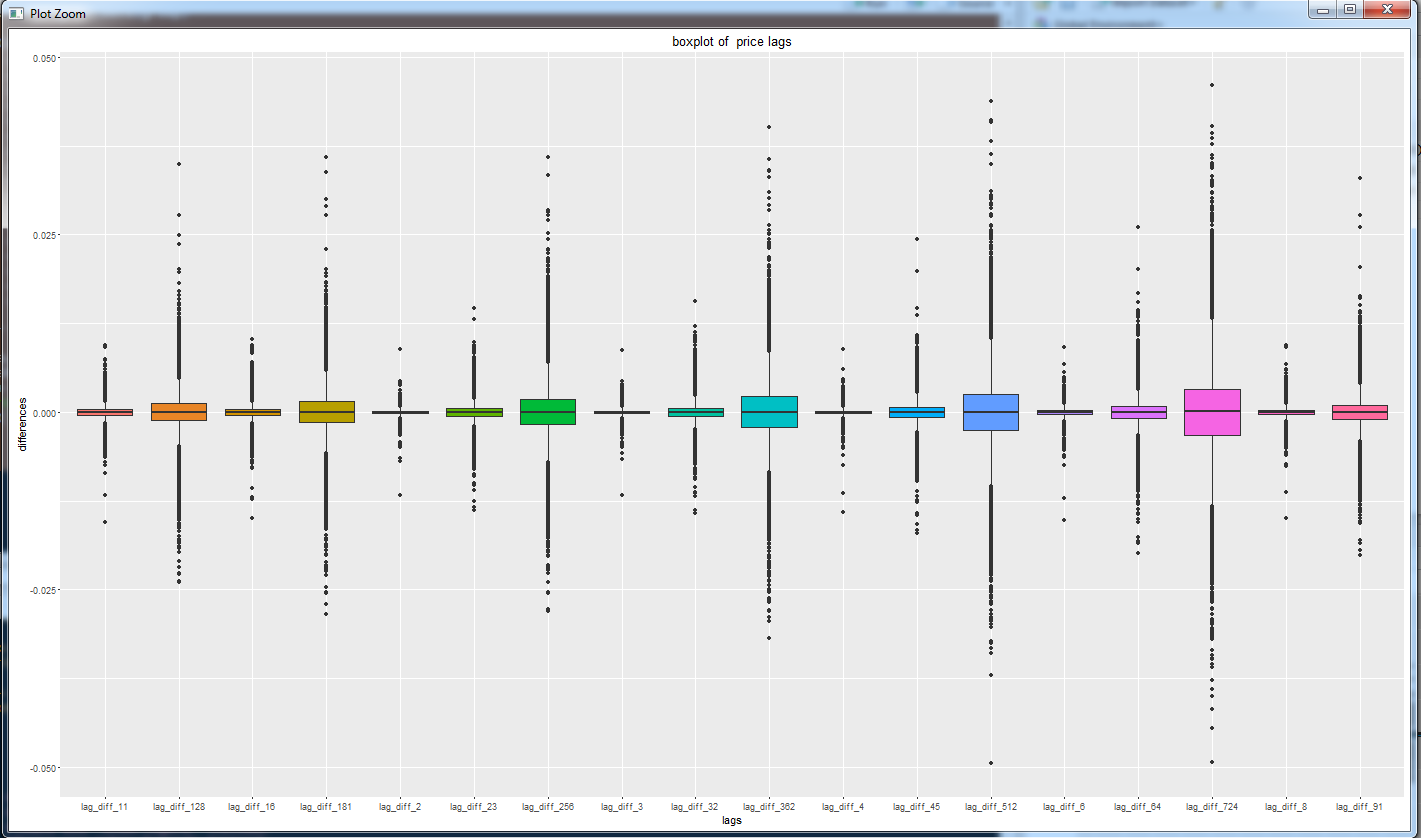
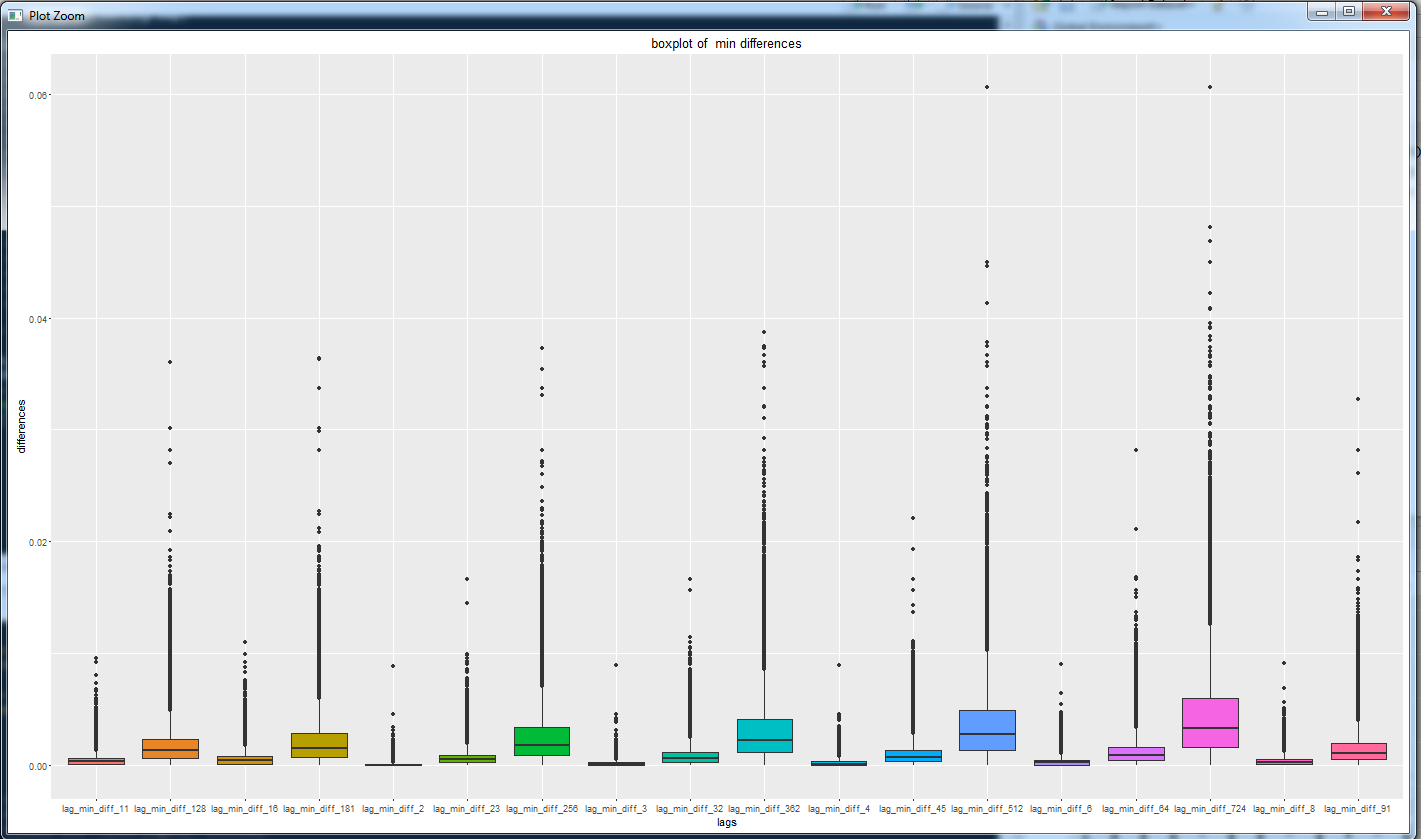
Вот здесь интересно: медиана (полоска внутри прямоугольника) больше нуля. Это сравнение последней цены со скользящим минимумом. И надо заметить, что медианное значение растет по мере увеличения лага. То есть, чем глубже мы берем минимум, тем больше мы ожидаем значение разницы с этим значением.
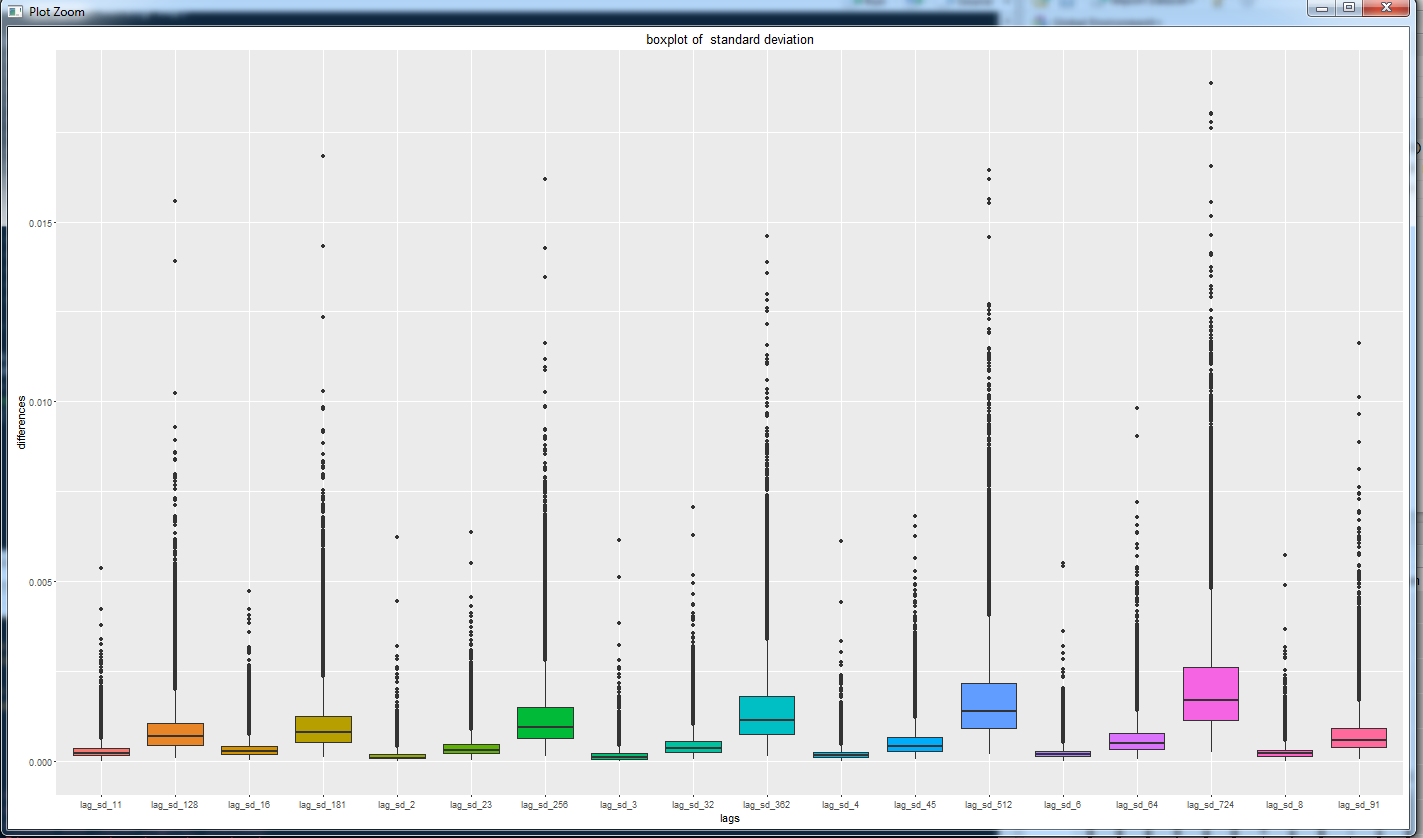
Это сжатая информация о значениях стандартных отклонений с разными лагами.
Теперь займемся сравнением данных в обучающей выборке с валидационной выборкой.
Таким компактным образом мы переберем все 126 колонок массивов и сделаем графическое сравнение плотностей, одновременно проводя тест на равенство распределений (нулевая гипотеза, что они равны).
Я пользуюсь критерием согласия Колмогорова-Смирнова для двух выборок: https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test
Обратите внимание, что когда я провожу тест, я ввожу нормальный шум в данные (ср.знач. = 0, ст.откл. = 0,00001) с целью убрать пересекающиеся значения в обоих выборках, так как они смещают оценку статистики теста, но при этом данный шум не вносит систематического сдвига в данные (bias).
Получаем, что для всех переменных распределение (кумулятивное) в обучающей и валидационной выборках сильно различается. p values очень близки к нулю и мы не можем принять нулевую гипотезу о равенстве распределений. И это плохая новость, так как различие в данных делает все нестационарным ))).
Построим несколько графиков с плотностью.
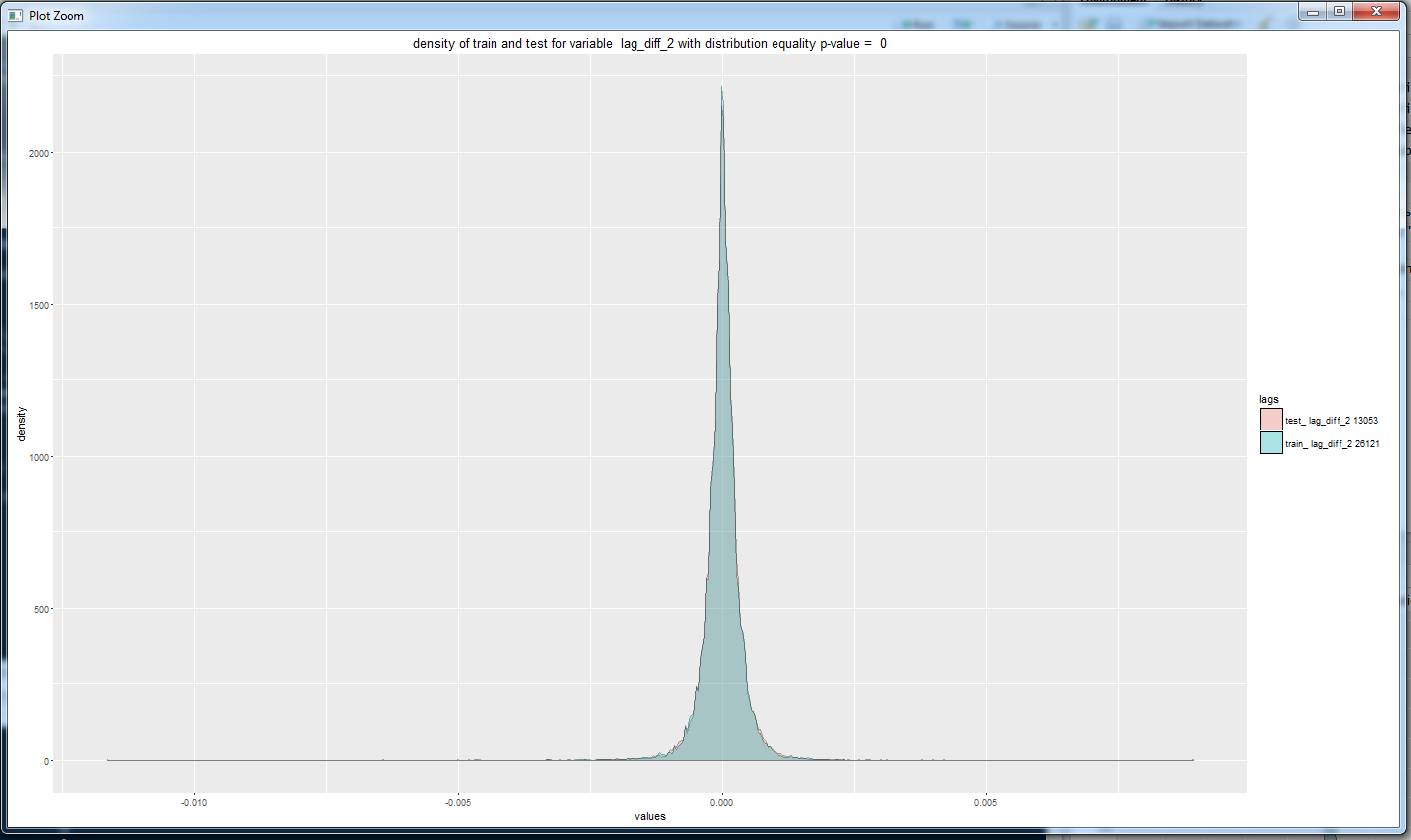
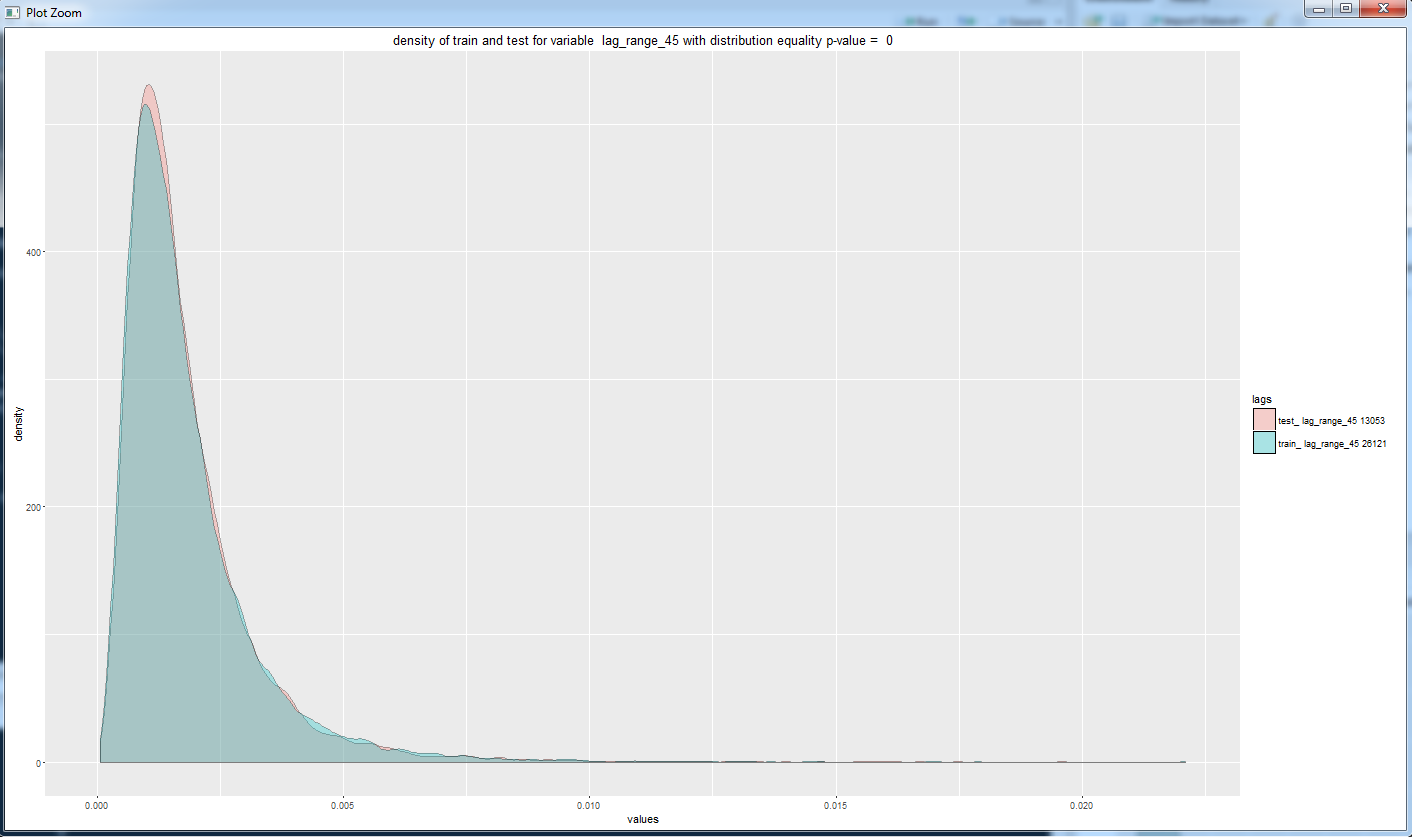
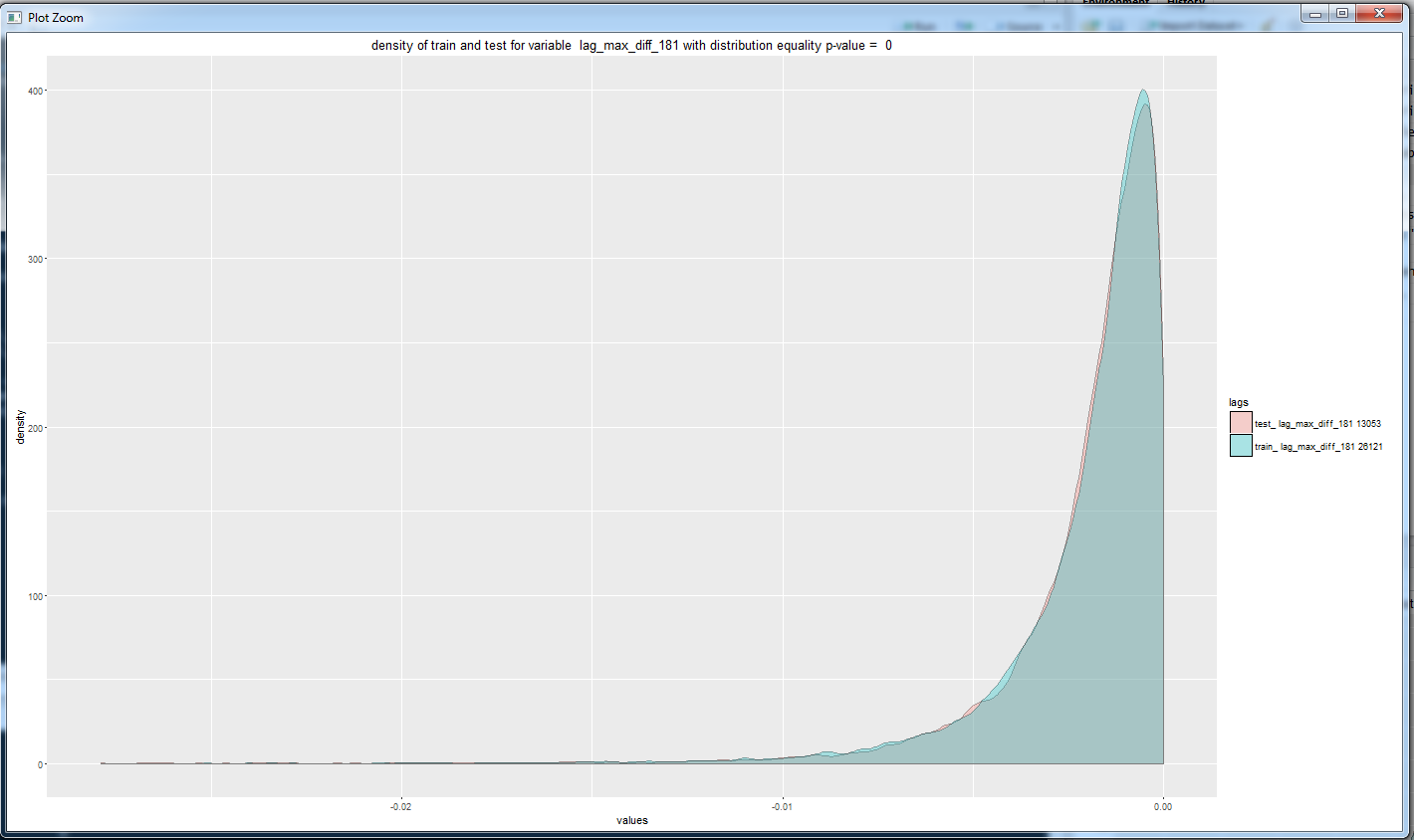
На сегодня все. Мы увидели, что данные форекса меняются с течением времени, и этот момент осложняет построение модели, которая будет вести себя как мы ожидаем на новых данных. Также мы просто посмотрели с разных сторон на наши данные.
В следующий раз займемся обучением машины и собственно предсказанием ценовых движений.
Пока. Следите за обновлениями.



")
 на 18-02-2025")
