Existe um padrão para o caos? Vamos tentar encontrá-lo! Aprendizado de máquina com o exemplo de uma amostra específica. - página 18
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Random é fixo :) Parece que essa semente é calculada de uma maneira complicada, ou seja, todos os preditores permitidos para a construção do modelo provavelmente estão envolvidos, e a alteração do número deles também altera o resultado da seleção.
A semente inicial é fixa. E, em seguida, um novo número aparece a cada chamada do HSC. É por isso que, com um número diferente de preditores e o número de DSTs, não cairá no mesmo preditor que com o número total de preditores.
Por que isso está se ajustando, ou melhor, em que você vê isso? Tendo a pensar que a amostra de teste difere do exame mais do que o exame do treinamento, ou seja, há diferentes distribuições de probabilidade dos preditores.
Bem, você pega as melhores variantes do exame, esperando que elas sejam boas no teste. Você seleciona os preditores com base no melhor exame. Mas eles são os melhores apenas para o exame.
O que é a métrica "err_"?
err_ oob - erro no OOB (você tem o exame), err_trn - erro no trem. Pela fórmula, obteremos um erro comum aos dois locais de amostra.
A propósito, na discussão, trocamos teste e exame. No início, planejamos verificações intermediárias no teste e verificações finais no exame. Mas o contexto deixa claro o que é o quê, embora os nomes tenham sido trocados.
O número inicial é fixo. E, em seguida, um novo número aparece a cada chamada do DST. Portanto, em um número diferente de preditores e números de DSTs não cairão no mesmo preditor que no número total de preditores.
Nah, as variantes são reproduzidas lá se os preditores usados para treinamento forem deixados no mesmo número.
Bem, você escolhe as melhores variantes do exame, esperando que elas sejam boas no teste. Os preditores são selecionados pelo melhor exame. Mas eles são os melhores apenas para o exame.
Acontece que essa variante foi a mais equilibrada, com um lucro decente no teste e no exame. Abaixo na imagem está o modelo inicialmente selecionado - "Was" e o modelo mais equilibrado após 10 mil treinamentos - "Became". Em geral, o resultado é melhor, e menos preditores são usados, de modo que o ruído é eliminado. E aqui a questão é como evitar esse ruído antes do treinamento.
Assim, a lógica é que o treinamento é interrompido no teste, portanto, é mais provável que haja um resultado positivo nesse teste do que na amostra que não participa do treinamento, portanto, a ênfase é colocada no último.
err_ oob - erro no OOB (você tem o exame), err_trn - erro no trn. Pela fórmula, obteremos um erro comum aos dois locais de amostra.
Quero dizer, não sei como "err" é contado - é Precisão? E por que exame e não teste, porque no exame de abordagem básica não saberemos.
A propósito, trocamos teste e exame na discussão. Inicialmente, foi planejado ter testes intermediários no teste e testes finais no exame. Mas, pelo contexto, fica claro o que é o quê, embora os nomes tenham sido alterados.
Eu não mudei nada (talvez eu tenha me descrito em algum lugar?) - é exatamente como está - em train - treinamento, test - controle de interrupção do treinamento, e exam - seção não envolvida em nenhum tipo de treinamento.
Estou apenas avaliando a eficácia da abordagem pela média de todos os modelos, incluindo o lucro médio - é mais provável que ele seja obtido do que as bordas com um bom resultado.
E ainda há a questão de como evitar esse ruído antes de começar a treinar.
Aparentemente, não é possível. Essa é a tarefa de filtrar o ruído e aprender com os dados corretos.
Quero dizer que não sei como "err" é considerado - é Precisão?
É uma maneira de obter um erro combinado/resumido em uma linha com um teste. Qualquer tipo de erro pode ser somado. E (1-precisão) e RMS e AvgRel e AvgCE etc.
Eu não mudei nada(talvez eu tenha me descrito em algum lugar?) - é assim que é - no trem - treinamento, teste - controle da interrupção do treinamento e exame - seção não envolvida em nenhum tipo de treinamento.
Pelas fotos, me pareceu que exame significa teste
Por exemplo, aqui.
E na tabela acima, os resultados do exame são melhores do que os do teste. Certamente é possível, mas deveria ser o contrário.
Aparentemente, não. Esse é o desafio de eliminar o ruído e aprender com os dados corretos.
Não, tem que haver uma maneira, caso contrário, tudo será inútil/aleatório.
Essa é uma maneira de obter o erro combinado/resumido em uma linha com um teste. Qualquer tipo de erro pode ser somado. E (1-precisão) e RMS e AvgRel e AvgCE etc.
Entendi, mas isso não funciona em meus dados - deve haver alguma correlação, pelo menos :)
Pelas fotos, me pareceu que o exame significava teste
Por exemplo, aqui
E na tabela acima, os resultados do exame são melhores do que os do teste.
Sim, parece que o exame tem mais chances de render mais dinheiro para os modeladores - eu mesmo não entendo completamente a situação.
Infelizmente, agora percebi que em algum momento misturei a amostra total (linhas) e agora os exemplos de 2022 estão no trem :(.
Vou refazer tudo - acho que terei o resultado em algumas semanas - vamos ver se o quadro geral muda.
Infelizmente, agora percebi que em algum momento misturei a amostra total (linhas) e agora o trem inclui exemplos de 2022 :(
Vou refazê-lo - acho que terei o resultado em algumas semanas - para ver se o quadro geral muda.
Não faz diferença se a avaliação foi feita por exame ou teste. O principal é que o site de avaliação não foi usado nem no treinamento nem na avaliação inicial.
2 semanas. Estou impressionado com sua resistência. Eu também fico irritado com 3 horas de cálculos..... E já passei um total de 5 anos no MO, quase o mesmo que você.
Em resumo, começaremos a ganhar alguma coisa na aposentadoria )))) Talvez.
Infelizmente, percebi agora que, em algum momento, misturei a amostra geral (linhas) e agora o trem está preenchido com exemplos de 2022 :(
Tenho tudo colado em uma matriz sequencial. E depois separo a quantidade certa dela. Dessa forma, nada se mistura.
Não faz diferença se foi avaliado por exame ou teste. O principal é que o site de avaliação não foi usado nem no treinamento nem na avaliação inicial.
Estou me perguntando se é melhor fazer o treinamento final como o Maxim, pegando uma amostra pré-histórica para controle, ou se é melhor pegar toda a amostra disponível e limitar o número de árvores, como na média dos melhores modelos.
2 semanas... Estou impressionado com sua resistência. Também acho que 3 horas de cálculos são irritantes..... E já passei um total de 5 anos no MO, quase o mesmo que você.
É claro que você sempre quer obter resultados mais rápidos. Tento carregar o hardware de modo que meus cálculos não interfiram em outras coisas - muitas vezes não uso o computador principal de trabalho. Em paralelo, posso implementar outras ideias no código - tenho ideias mais rapidamente do que tenho tempo para verificá-las no código.
Em resumo, começaremos a ganhar alguma coisa na aposentadoria )))) Talvez.
Concordo - a perspectiva é triste. Se eu não visse progresso em minha pesquisa, embora lento, provavelmente já teria terminado o trabalho.
Tenho tudo colado em uma matriz sequencial. E, a partir dessa matriz, separo a quantidade certa. Dessa forma, nada se mistura.
Sim, converti a amostra em um arquivo binário e, no script, coloquei uma caixa de seleção por acidente, aparentemente, responsável por misturar a amostra - portanto, não é um problema, e o CatBoost exige 3 amostras separadas - eles não fizeram a seleção no intervalo de linhas, embora tenham uma validação cruzada integrada.
Também estou me perguntando se é melhor fazer o treinamento final como o Maxim, pegando uma amostra pré-histórica para controle, ou se é melhor pegar toda a amostra disponível e limitar o número de árvores, como na média dos melhores modelos.
Para mim, o pré-treinamento e os testes são uma oportunidade de selecionar, em média, os melhores hiperparâmetros (número de árvores, etc.) e preditores. E mesmo sem um teste, você pode treiná-los na linha de base e começar a negociar imediatamente.
A ideia da amostragem pré-histórica funcionará se os padrões não mudarem, talvez sim. Mas há um risco de que eles mudem. Portanto, prefiro não correr riscos e testar em uma amostragem futura.
Outra questão é há quanto tempo foi feita essa amostragem pré-histórica: há seis meses ou há 15 anos? Seis meses atrás pode funcionar, mas o mercado de 15 anos atrás não é o mesmo de agora. Mas isso não é certo. Talvez existam padrões que estejam funcionando há décadas.Descreverei os resultados obtidos usando o mesmo algoritmo que descrevi aqui, mas com a amostra não misturada, ou seja, permanecendo em ordem cronológica.
A única coisa que mudei é que agora o treinamento de 10.000 modelos foi realizado não em toda a amostra com os preditores excluídos participando dela, mas em uma amostra reformulada na qual as colunas com preditores excluídos foram removidas, o que acelerou o processo de treinamento (aparentemente, bombear um arquivo grande leva muito tempo). Devido a essas alterações, consegui executar consistentemente 6 etapas de triagem de preditores.
Figura 1: Histograma de lucro no exame de amostra após o treinamento de 100 modelos em todos os preditores da amostra.
Figura 2: Histograma de lucro na amostra do exame após o treinamento de 10 mil modelos em preditores de amostra selecionados - etapa 1.
Figura3: Histograma de lucro na amostra do exame após o treinamento de 10 mil modelos em preditores de amostras selecionadas - etapa 2.
Figura 4: Histograma de lucros para a amostra do exame após o treinamento de 10 mil modelos em preditores de amostras selecionadas - etapa 3.
Figura 5: Histograma de lucros para a amostra do exame após o treinamento de 10 mil modelos em preditores de amostras selecionadas - etapa 4.
Figura 6: histograma de lucros para a amostra do exame após o treinamento de 10 mil modelos em preditores de amostras selecionadas - etapa 5.
Figura 7: Histograma de lucro para a amostra do exame após o treinamento de 10 mil modelos em preditores de amostras selecionadas - etapa 6.
Figura 8: Tabela com as características dos modelos que foram selecionados para formar amostras subsequentes com um número decrescente de preditores (recursos).
Vamos considerar o modelo com as seguintes características obtidas na 6ª etapa da seleção de preditores.
Figura 9: Características do modelo.
Figura 10. Visualização do modelo sobre o exame de amostra como uma distribuição sobre a probabilidade de classificação - eixo x - probabilidades obtidas do modelo, e y - porcentagem de todas as amostras.
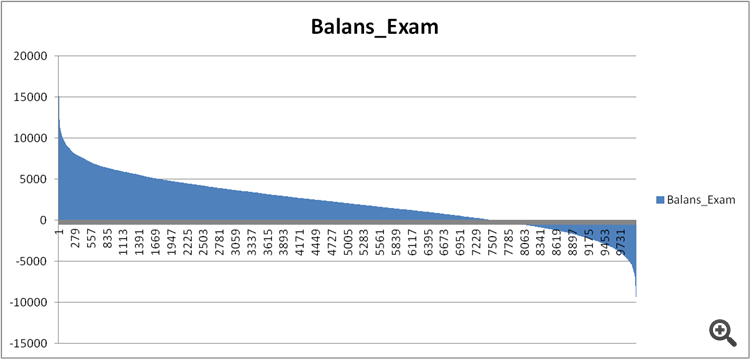
Figura 11. Equilíbrio do modelo na amostra do exame.
Agora vamos comparar os preditores nos modelos razoavelmente bons e extremamente ruins obtidos na etapa 6 da seleção de preditores.
Figura 12. Comparação das características dos modelos.
Podemos ver agora quais preditores são tão ruins para o resultado financeiro e prejudicam o treinamento?
Figura 13. Ponderação dos preditores nos dois modelos.
A Figura 13 mostra que quase todos os preditores disponíveis são usados, com exceção de um, mas duvido que essa seja a raiz do problema. Então, não se trata tanto de uma questão de uso, mas sim da sequência de uso na construção do modelo?
Fiz uma comparação de duas tabelas, atribuindo um número ordinal de importância em vez de um índice, e vi como essa importância é classificada de forma diferente nos modelos.
Figura 14: Tabela comparando a importância (uso) dos preditores nos dois modelos.
Os desvios em menos significam que o preditor do segundo modelo (não lucrativo) foi usado mais tarde, e em mais - mais cedo.
Figura 15. Desvios de significância dos preditores nos modelos.
Pode-se ver que há desvios fortes, talvez esse seja o caso, mas como descobrir/provar isso? Talvez seja necessária alguma abordagem complexa de comparação dos modelos com o benchmark - alguma ideia?
Existe algum tipo de índice de confusão para descrever o viés geral, talvez levando em conta a importância dos preditores para o primeiro modelo, ou seja, com um coeficiente decrescente?
Que conclusões podem ser tiradas?
Meu palpite é o seguinte:
1. Os resultados foram muito melhores na amostra do passado. Presumo que isso se deva às informações que "vazaram" sobre eventos do futuro ao misturar a cronologia da amostra. A questão é se os modelos serão mais estáveis obtidos em uma amostra misturada ou em uma amostra normal.
2. É necessário criar uma estrutura de importância dos preditores para sua posterior aplicação nos modelos, ou seja, além dos números, é necessário estabelecer a lógica, caso contrário, a dispersão dos resultados dos modelos será muito grande, mesmo com um pequeno número de preditores.