Redes neurais. Perguntas dos especialistas. - página 5
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
De acordo. Era isso que eu estava perguntando, qual é a relação entre erro e lucro, de preferência em OOS....))
Demasiado joo você disse que o resultado matizado poderia ser devido à normalização dos dados, eu respondi que não havia nenhum.
Concordo com Leo que nem sempre é o critério de erro que determina o lucro final, mas é o erro que importa na tarefa que tenho diante de mim agora. Vou postar a previsão feita pela rede esta noite para obter a opinião de outros sobre a qualidade da previsão e possíveis melhorias)
Хорошо, чуть позже (часа через 2-3), попробую обоснованно показать, каким образом профит (или что то другое, не важно, что мы хотим получить от сети) зависит от фитнес функции.
А гарантию того, что мы получим профит в будующем, конечно, никто дать никогда не сможет. А вот к чему стремится должна сетка, пожалуй, мы должны определять для неё однозначно.
Você não precisa perder seu tempo, porque a diferença entre "querer" e "obter" não é nada filosófica, embora seja formulada em termos filosóficos de "subjetivo" e "objetivo".
O fato de que os resultados no ajuste são inversamente proporcionais ao erro raiz-meios-quadrado é algo que sabemos sem você.
Inquivocamente, a rede deve visar um lucro sobre o OOS. Caso contrário, não há sentido.
То, что результаты на подгонке обратно пропорциональны среднеквадратичной ошибке - это мы и без Вас знаем.
Você também está usando o erro quadrático médio de raiz? Você é o pai da rede emc. :)
Reshetov escreveu(a) >>
Definitivamente, a rede deve visar um lucro sobre o OOS. Caso contrário, não há sentido.
É compreensível. Outra questão é como ela deve se esforçar para isso.
Вы тоже что ли используете среднеквадратичную ошибку? Отец эмкуэльных сетей Вы наш. :)
Это и ежу понятно. Другой вопрос, как она должна к этому стремится.
Eu não utilizo o erro raiz-medoquadrado para o comércio, pois ele apenas caracteriza a qualidade do ajuste.
Portanto, o erro na amostra não deve, de forma alguma, tender a
Como prometido, estou publicando uma foto e uma explicação sobre isso. Rede: MLP uma camada oculta. 2000 pontos em treinamento. 1000 na saída do amostrador) Recebi corrente e pré EMA da primeira foto e pré-encerramento da primeira e da segunda. Isso é tudo! Por que tudo e tão pouco? Porque o número crescente de neurônios, camadas, insumos, etc. não influencia em nada o resultado. Isto é o que me assusta) E o que é mostrado como uma previsão, você pode obter, bem, uma fórmula muito simples, que é calculada à mão. Por que isso não é tão claro para mim. O que devo mudar? Pode ser feito melhor?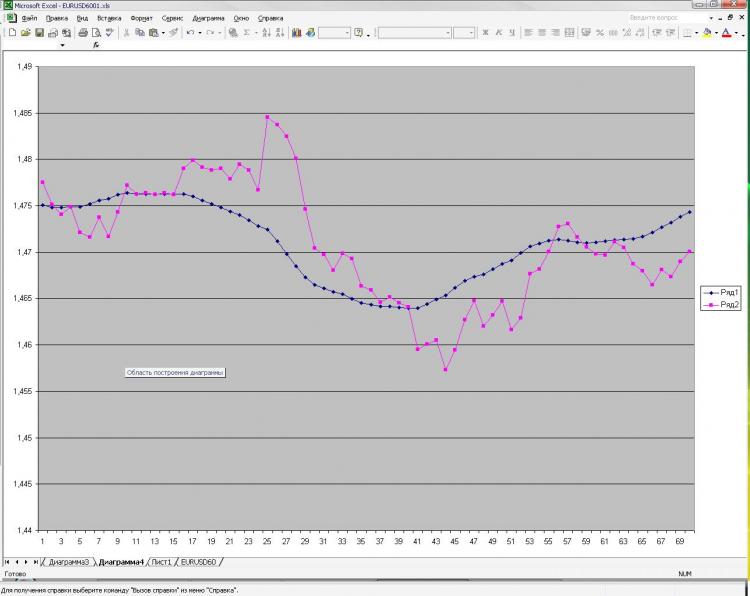
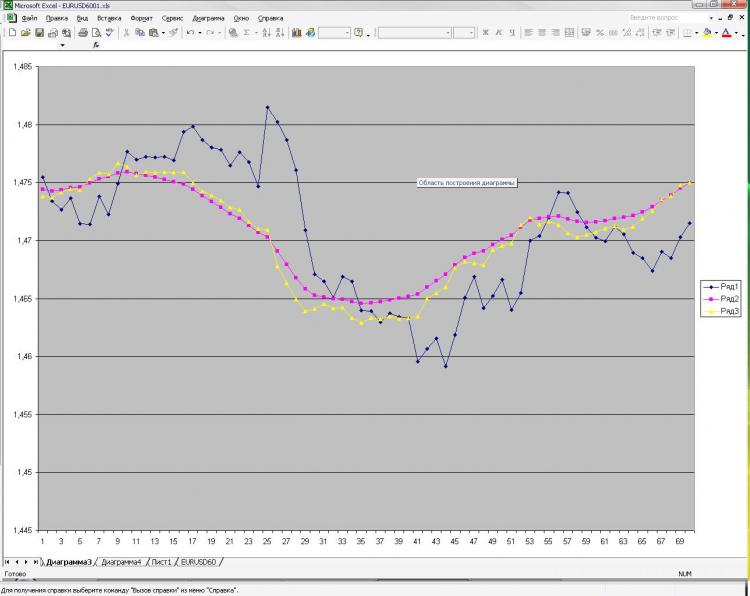
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?
O senhor descreveu o problema da aproximação. Dois pontos de "referência" não são suficientes para descrever a forma. Além disso, você fornece mais um ponto de influência cada um, que não só não descreve a curvatura, mas também uma linha reta. Tente pelo menos 3 pontos de cada conjunto de parâmetros de entrada. Isto é, três pontos EMA e três pontos de cláusula, portanto 6 neurônios de entrada, com 6 a 12 neurônios na camada oculta. Um número maior de neurônios na camada oculta não é razoável para este problema.
Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
Dê-me uma amostra aqui, eu vou tentar no Statistica