알고리즘 최적화.
주
우선, 코드를 다음으로 가져와야 한다고 생각합니다.
1. 컴파일된 보기.
2. 읽을 수 있습니다.
3. 댓글.
원칙적으로 주제는 흥미롭고 긴급합니다.
주
시작하려면 코드를 다음으로 가져와야 한다고 생각합니다.
1. 컴파일된 보기.
2. 읽을 수 있습니다.
3. 댓글.
확인.
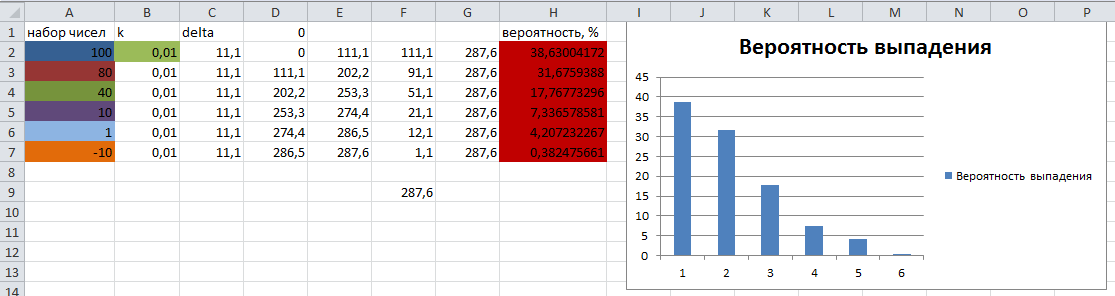
정렬된 실수 배열이 있습니다. 가상의 룰렛 섹터의 크기에 해당하는 확률로 배열의 셀을 선택해야 합니다.
숫자의 테스트 세트와 떨어지는 이론적 확률은 Excel에서 계산되었으며 다음 그림의 알고리즘 결과와 비교하기 위해 표시되었습니다.
알고리즘 실행 결과:
2012.04.04 21:35:12 룰렛 (EURUSD,H1) h0 38618465 38.618465
2012.04.04 21:35:12 룰렛 (EURUSD,H1) h1 31685360 31.68536
2012.04.04 21:35:12 룰렛 (EURUSD,H1) h3 7334754 7.334754
2012.04.04 21:35:12 룰렛 (EURUSD,H1) h4 4205492 4.205492
2012.04.04 21:35:12 룰렛 (EURUSD,H1) h5 385095 0.385095
2012.04.04 21:35:12 룰렛 (EURUSD,H1) 12028ms - 실행시간
보시다시피 해당 섹터에서 "볼"이 떨어질 확률의 결과는 이론적으로 계산된 결과와 거의 일치합니다.
#property script_show_inputs //--- input parameters input int StartCount= 100000000 ; // Границы соответствующих секторов рулетки double select1[]; // начало сектора double select2[]; // конец сектора //—————————————————————————————————————————————————————————————————————————————— void OnStart () { MathSrand (( int ) TimeLocal ()); // сброс генератора // массив с тестовым набором чисел double array[ 6 ]={ 100.0 , 80.0 , 40.0 , 10.0 , 1.0 ,- 10.0 }; ArrayResize (select1, 6 ); ArrayInitialize (select1, 0.0 ); ArrayResize (select2, 6 ); ArrayInitialize (select2, 0.0 ); // счетчики для подсчета выпадений соответствующего числа из тестового набора int h0= 0 ,h1= 0 ,h2= 0 ,h3= 0 ,h4= 0 ,h5= 0 ; // нажмём кнопочку секундомера int time_start=( int ) GetTickCount (); // проведём серию испытаний for ( int i= 0 ;i<StartCount;i++) { switch (Roulette(array, 6 )) { case 0 : h0++; break ; case 1 : h1++; break ; case 2 : h2++; break ; case 3 : h3++; break ; case 4 : h4++; break ; default : h5++; break ; } } Print (( int ) GetTickCount ()-time_start, " мс - Время исполнения" ); Print ( "h5 " ,h5, " " ,h5* 100.0 /StartCount); Print ( "h4 " ,h4, " " ,h4* 100.0 /StartCount); Print ( "h3 " ,h3, " " ,h3* 100.0 /StartCount); Print ( "h1 " ,h1, " " ,h1* 100.0 /StartCount); Print ( "h0 " ,h0, " " ,h0* 100.0 /StartCount); Print ( "----------------" ); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Рулетка. int Roulette( double &array[], int SizeOfPop) { int i= 0 ,u= 0 ; double p= 0.0 ,start= 0.0 ; double delta=(array[ 0 ]-array[SizeOfPop- 1 ])* 0.01 -array[SizeOfPop- 1 ]; //------------------------------------------------------------------------------ // зададим границы секторов for (i= 0 ;i<SizeOfPop;i++) { select1[i]=start; select2[i]=start+ MathAbs (array[i]+delta); start=select2[i]; } // бросим "шарик" p=RNDfromCI(select1[ 0 ],select2[SizeOfPop- 1 ]); // посмотрим, на какой сектор упал "шарик" for (u= 0 ;u<SizeOfPop;u++) if ((select1[u]<=p && p<select2[u]) || p==select2[u]) break ; //------------------------------------------------------------------------------ return (u); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Генератор случайных чисел из заданного интервала. double RNDfromCI( double min, double max) { return (min+((max-min)* MathRand ()/ 32767.0 ));} //——————————————————————————————————————————————————————————————————————————————
확인.
정렬된 실수 배열이 있습니다. 가상의 룰렛 섹터의 크기에 해당하는 확률로 배열의 셀을 선택해야 합니다.
"섹터 너비"를 설정하는 원리를 설명합니다. 배열의 값과 일치합니까? 아니면 따로 설정되나요?
이것은 가장 어두운 질문이며 다른 모든 것은 문제가 되지 않습니다.
두 번째 질문: 숫자 0.01은 무엇입니까? 그것은 어디에서 가져온 것입니까?
간단히 말해서: 떨어지는 섹터의 정확한 확률을 어디에서 얻을 수 있는지 알려주십시오(너비(둘레의 분수)).
각 섹터의 크기를 조정할 수 있습니다. 기본적으로 음수 차원은 본질적으로 존재하지 않습니다. 카지노에서도. ;)
"섹터 너비"를 설정하는 원리를 설명합니다. 배열의 값과 일치합니까? 아니면 따로 설정되나요?
섹터의 너비는 배열의 값과 일치할 수 없습니다. 그렇지 않으면 알고리즘이 숫자에 대해 작동하지 않습니다.
숫자 사이의 거리가 중요합니다. 모든 숫자가 첫 번째 숫자에서 멀수록 떨어질 가능성이 적습니다. 사실, 우리는 숫자 사이의 거리에 비례하는 숫자의 직선 부분을 따로 설정하고 0.01의 비율로 조정하여 마지막 숫자가 첫 번째 숫자에서 가장 멀리 떨어져 있을 때 0과 같지 않은 확률을 갖도록 합니다. 계수가 높을수록 섹터가 더 평등합니다. 첨부된 엑셀파일, 실험.
메타드라이버 :
1. 간단히 말해서: 떨어지는 섹터의 정확한 확률을 어디에서 얻을 수 있는지 알려주십시오(폭의 분수로 표시).
2. 각 섹터의 크기를 저스트할 수 있습니다. 기본적으로 음수 차원은 본질적으로 존재하지 않습니다. 카지노에서도. ;)1. 이론적 확률 계산은 Excel로 제공됩니다. 첫 번째 숫자는 가장 높은 확률이고 마지막 숫자는 가장 낮은 확률이지만 0이 아닙니다.
2. 음수 섹터 크기는 집합이 내림차순으로 정렬된 경우 숫자 집합에 대해 발생하지 않습니다. 첫 번째 숫자가 가장 큽니다(집합에서 가장 큰 숫자와 작동하지만 음수임).
섹터의 너비는 배열의 값과 일치할 수 없습니다. 그렇지 않으면 알고리즘이 숫자에 대해 작동하지 않습니다.
zyu: 숫자 사이의 거리가 중요합니다. 모든 숫자가 첫 번째 숫자에서 멀수록 떨어질 가능성이 적습니다. 사실, 우리는 숫자 사이의 거리에 비례하는 숫자 직선 세그먼트를 따로 설정하고 0.01의 계수로 조정하여 마지막 숫자가 첫 번째 숫자에서 가장 멀리 떨어져 있을 때 0과 같지 않은 확률로 떨어질 확률을 갖습니다. 계수가 높을수록 섹터가 더 평등합니다. 첨부된 엑셀파일, 실험.
1. 이론적 확률의 계산은 Excel로 제공됩니다. 첫 번째 숫자는 가장 높은 확률이고 마지막 숫자는 가장 낮은 확률이지만 0이 아닙니다.
2. 음수 섹터 크기는 집합이 내림차순으로 정렬된 경우 숫자 집합에 대해 발생하지 않습니다. 첫 번째 숫자가 가장 큽니다(집합에서 가장 큰 숫자와 작동하지만 음수임).
귀하의 계획에서 "불도저에서"는 가장 작은 시간 ( vmch ) 의 확률로 제공됩니다 . 합리적인 근거가 없습니다.
// "정당화"하기 어렵기 때문입니다. 모든 것이 정상입니다. N개의 못 사이에 N-1개의 틈만 있습니다.
따라서 ( vmch ) 또한 "불도저에서" 가져온 "계수"에 따라 달라집니다. 왜 0.01인가? 왜 0.001이 아니죠?
알고리즘을 수행하기 전에 모든 섹터의 "너비" 계산을 결정해야 합니다.
zyu: "숫자 사이의 거리"를 계산하는 공식을 제공하십시오. 어떤 숫자가 "첫 번째"입니까? 얼마나 멀리 떨어져 있습니까? 엑셀로 보내지 마세요, 제가 거기 있었습니다. 모든 것이 이념적 차원에서 혼란스럽다. 보정 계수는 어디에서 왔으며 정확히 왜 옵니까?
빨간색으로 강조 표시된 것은 전혀 사실이 아닙니다. :)
이것은 매우 빠를 것입니다:
int Selection() { return (RNDfromCI(1,SizeOfPop); }
알고리즘의 품질은 전체적으로 영향을 받지 않아야 합니다.
그리고 약간의 영향을 미치더라도 속도로 인해이 옵션은 품질을 추월합니다.
1. 귀하의 계획에서 "불도저에서"는 가장 작은 숫자 ( wmch ) 의 확률로 제공됩니다 . 합리적인 근거가 없습니다. 따라서 ( vmch ) 또한 "불도저에서" 가져온 "계수"에 따라 달라집니다. 왜 0.01인가? 왜 0.001이 아닌가요?
2. 알고리즘을 수행하기 전에 모든 섹터의 "너비" 계산을 결정해야 합니다.
3. zyu: "숫자 사이의 거리"를 계산하는 공식을 제공하십시오. 어떤 숫자가 "첫 번째"입니까? 얼마나 멀리 떨어져 있습니까? 엑셀로 보내지 마세요, 제가 거기 있었습니다. 모든 것이 이념적 차원에서 혼란스럽다. 보정 계수는 어디에서 왔으며 정확히 왜 옵니까?
4. 빨간색으로 강조 표시된 것은 전혀 사실이 아닙니다. :)
1. 예, 불도저에서. 나는 이 비율을 좋아한다. 다른 하나가 마음에 들면 다른 하나를 사용합니다. 알고리즘의 속도는 변경되지 않습니다.
2. 확실성이 확보되었습니다.
3. 알았어. 정렬된 숫자 배열이 있습니다 - array[], 여기서 가장 큰 숫자는 array[0]에 있고 시작점이 0.0인 숫자 빔(다른 점은 선택 가능 - 아무것도 변경되지 않음)이 양수 방향으로 향합니다. 방향. 다음과 같은 방법으로 빔에 세그먼트를 따로 설정합니다.
start0=0 end0=start0+|배열[0]+델타|
start1=end0 end1=start1+|배열[1]+델타|
start2=end1 end2=start2+|배열[2]+델타|
......
start5=end4 end5=start5+|배열[5]+델타|
어디:
delta=(array[ 0 ]-array[5])* 0.01 -array[5];
그게 다 산수입니다. :)
이제 표시된 빔에 "공"을 던지면 특정 세그먼트를 칠 확률은 이 세그먼트의 길이에 비례합니다.
4. 당신이 (모두는 아니지만) 선택하지 않았기 때문입니다. 다음과 같이 강조 표시해야 합니다. " 사실, 우리는 0.01의 계수로 조정된 숫자 사이의 거리에 비례하는 숫자 선분을 따로 설정하여 마지막 숫자가 0이 아닌 떨어질 확률을 갖도록 합니다. "
이것은 매우 빠를 것입니다:
int Selection() { return (RNDfromCI(1,SizeOfPop); }
알고리즘의 품질은 전체적으로 영향을 받지 않아야 합니다.
그리고 약간의 영향을 미치더라도 속도로 인해이 옵션은 품질을 추월합니다.
:)
무작위로 배열 요소를 선택하도록 제안하고 있습니까? - 이것은 배열 번호 사이의 거리를 고려하지 않으므로 귀하의 버전은 쓸모가 없습니다.
- www.mql5.com
확인하는 것은 어렵지 않습니다.
사용할 수 없다는 것이 실험적으로 확인되었습니까?
사용할 수 없다는 것이 실험적으로 확인되었습니까?
나는 알고리즘 논리의 최적 구성의 문제를 논의하기 위해 여기에서 제안합니다.
누군가가 그의 알고리즘이 속도(또는 가시성) 면에서 최적의 논리를 가지고 있다고 의심한다면 환영합니다.
나는 또한 알고리즘을 연습하고 다른 사람들을 돕고자 하는 사람들을 이 스레드에서 환영합니다.
나는 원래 "찻주전자의 질문" 스레드에서 내 질문을 했지만 거기에 속하지 않는다는 것을 깨달았습니다.
따라서 다음보다 더 빠른 버전의 "룰렛" 알고리즘을 제안하십시오.
배열이 매번 선언되지 않고 크기가 조정되지 않도록 함수에서 제거할 수 있다는 것은 분명하지만 더 혁신적인 솔루션이 필요합니다. :)