p_bo ( 백테스트에서 과훈련 확률)는 0에 가까워야 하며, 이는 과훈련의 위험이 낮음을 나타냅니다.
slope ( 선형 회귀의 기울기 계수)는 1에 가까워야 하며, 이는 학습과 테스트 하위 집합의 성능 지표 값 간에 강한 선형 관계가 있음을 나타냅니다.
ar^2 ( 조정된 결정 계수)는 1에 가까워야 하며, 이는 선형 회귀 정확도가 양호함을 나타냅니다.
p_loss ( 테스트 하위 집합의 성능 지표 값 중 주어진 임계값 미만인 비율)는 0에 가까워야 하며, 이는 테스트 하위 집합의 성능 지표 값 대부분이 주어진 임계값 이상임을 나타냅니다.
그러나 이러한 값은 선택한 성능 지표와 임계값에 따라 달라질 수 있다는 점에 유의해야 합니다.
이 매개변수가 무엇인지 이해하기에는 너무 짧습니다. 다음은 기사 13페이지의 추가 내용입니다(패키지가 기사의 방법을 완전히 재현하지만 다른 것을 추가/제외한 경우)
과적합 통계 섹션 2에서 소개한 프레임워크를 사용하면네 가지 보완 분석 측면에서 전략의 백테스트의 관련성 을특성화할 수 있습니다: 1.백테스트 과적합 확률(PBO): 최적의 IS로 선택된 모델 구성이 N모델 구성의 평균보다성능이 저하 될 확률입니다. 2.성능 저하: 이는 더 큰성능당 IS가 어느 정도성능 저하로 이어지는지를 결정하며, 이는베일리 등[1]에서 논의된 메모리 효과와관련된 발생을 의미합니다.[ 3.손실 확률: 최적의 IS로 선택된 모델이손실 OOS를 제공할 확률입니다. 4.확률적 우세:이 분석은전략 IS를 선택하는 데 사용된프로세스 가 N대안중에서 하나의 모델 구성을무작위로 선택하는 것보다 바람직한지여부를 결정합니다.
지금까지 8페이지입니다. 그리고 이것은 여전히 소개입니다)))
교차 유효성 검사에 대한 Sharpe의 비교인 것 같습니다(하지만 다른 지표를 사용할 수 있다고 적혀 있습니다).
내가 알기로는 4 개의 매개 변수가 최적화되어야합니다.
그러나 이러한 값은 선택한 성능 지표 및 임계값에 따라 달라질 수 있다는 점에 유의해야 합니다.
다중 기준 파레토 앞뒤 다중 기준 최적화가 필요한 경우
제가 알기로는 최적화해야 할 4가지 매개 변수가 있습니다.
그러나 이러한 값은 선택한 성능 지표와 임계값에 따라 달라질 수 있다는 점에 유의해야 합니다.
이 매개변수가 무엇인지 이해하기에는 너무 짧습니다. 다음은 기사 13페이지의 추가 내용입니다(패키지가 기사의 방법을 완전히 재현하지만 다른 것을 추가/제외한 경우)
과적합 통계
섹션 2에서 소개한 프레임워크를 사용하면네 가지 보완 분석 측면에서 전략의 백테스트의 관련성
을특성화할 수 있습니다:
1. 백테스트 과적합 확률 (PBO):
최적의 IS로 선택된
모델 구성이 N 모델 구성의 평균보다성능이 저하 될 확률입니다.
2. 성능 저하: 이는 더 큰성능당
IS가 어느 정도성능 저하로 이어지는지를 결정하며, 이는베일리 등[1]에서 논의된 메모리 효과와관련된
발생을 의미합니다.[
3. 손실 확률: 최적의
IS로 선택된 모델이손실 OOS를 제공할 확률입니다.
4. 확률적 우세: 이 분석은전략 IS를 선택하는 데 사용된프로세스
가 N 대안중에서
하나의 모델 구성을무작위로 선택하는 것보다 바람직한지여부를 결정합니다.
각 항목은 아래에서 자세히 설명합니다.
이 매개 변수가 무엇인지 이해하기에는 너무 짧습니다. 다음은 문서 13페이지의 자세한 내용입니다(패키지가 문서에 있는 방법을 완전히 재현했지만 다른 것이 추가/제거되었을 수 있음).
패키지가 끔찍하고 몇 년 동안 그런 파타크를 본 적이 없습니다.
코드가 끔찍합니다.
문서는 사실상 쓸모가 없습니다.
어떻게 CRAN에 들어갔는지 이해가 되지 않습니다.
여전히 이해할 수 없습니다. 하나의 거래 시스템이 배치로 나뉘어 조사됩니까, 아니면 여러 TS (이 라이브러리에서)입니까?
나는 여전히 이해할 수 없으며, 하나의 거래 시스템이 배치로 나뉘어 연구되거나 여러 TS (이 라이브러리에서)입니다.
다른 매개 변수 / 하이퍼 파라미터로 얻은 모델 세트 중에서 최상의 모델을 선택합니다. 입력은 행렬이며 각 열은 모델 중 하나의 예측입니다.
아니면 아닐 수도 있습니다. 저도 아직 알아내지 못했습니다.다양한 파라미터/하이퍼파라미터에서 얻은 모델 세트 중에서 가장 적합한 모델을 선택합니다. 입력은 각 열이 모델 중 하나의 예측인 행렬입니다.
나는 이미 이것을 알아 냈습니다.
결과 작업 방법을 이해하지 못합니다.
하나의 열(하나의 TS)을 제공합니다.
결과
5개의 열(5개의 TC)을 제공합니다.
나는 또한 하나의 행을 얻습니다.
5 개의 행이 있거나 가장 좋은 TS의 결과 인 경우 가장 좋은 것의 mndex가 있어야합니다 ...
나는이 저자를 죽일 것이다
다양한 파라미터/하이퍼파라미터에서 얻은 모델 세트 중에서 가장 적합한 모델을 선택합니다. 입력은 각 열이 모델 중 하나의 예측인 행렬입니다.
아니면 아닐 수도 있습니다. 저도 아직 파악하지 못했습니다.서로 다른 시장 구간 (파라미터/하이퍼파라미터 )에서 TS 수익률을 가져오는 것으로 해석할 수 있습니다. ????
다른 시장 섹션 == 파라미터/하이퍼파라미터?
이는 시장의 다른 부분 (파라미터/하이퍼파라미터 )에서 TC 수익의 수익을 가져가는 것으로 해석할 수 있습니다. ????
정확한 수익 리턴.
시장의 다른 부분 == 파라미터/하이퍼파라미터?
내가 정확히 설정을 이해했듯이 : MA, SL 등의 다른 기간.
나는 또한 한 줄을 얻습니다.
5 줄이 있어야하거나 최고의 TC라면 최고의 mndex가 있어야합니다...
결과적으로 모델(및 아마도 예측자 및 대상 데이터)에 대한 전반적인 평가를 얻게 됩니다
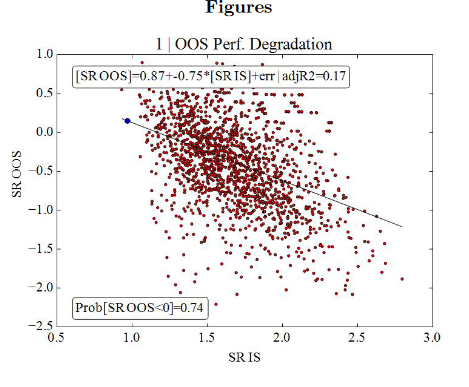
나쁜 모델은 이러한 결과를 제공합니다(0을 초과하는 OOS 결과의 17%만).
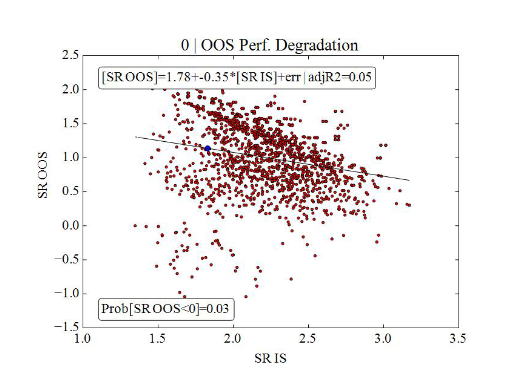
양호한 모델 - 0을 초과하는 OOS 결과의 95%
도착한 것은 바로 귀국자들입니다.
이익과 손실이 있잖아요, 그렇죠?
그래서 우리는 포지션이 열려있을 때 주들의 리턴을받습니다.
제가 알기로는 MA, SL 등의 다른 기간과 같은 설정입니다.
TS의 다른 설정 대신 다른 영역에서 거래를하면 동일 할 수 있다고 생각합니다.