記事"強化学習におけるモンテカルロ法の応用"についてのディスカッション 新しいコメント MetaQuotes 2019.03.26 12:07 新しい記事 強化学習におけるモンテカルロ法の応用 はパブリッシュされました:自己学習を行うEAを作成するためのReinforcement learningの適用。前回の記事では、Random Decision Forestアルゴリズムを学び、Reinforcement learning(強化学習)に基づく簡単な自己学習EAを作成しました。このアプローチの主な利点は、取引アルゴリズムを書くことの単純さと『学習」の高速性でした。強化学習(以下、単にRL)は、どのEAにも簡単に組み込むことができ、最適化のスピードを上げられます。 最適化を停止したら、シングルテストモードをオンにします(最良のモデルがファイルに書き込まれ、それだけがロードされるため)。 2か月前の履歴をスクロールして、モデルが4か月全体にわたってどのように機能するかを見てみましょう。 結果として得られたモデルは、8月に故障し、もう1か月(ほぼ9月全体)続いたことがわかります。作者: Maxim Dmitrievsky 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
新しい記事 強化学習におけるモンテカルロ法の応用 はパブリッシュされました:
自己学習を行うEAを作成するためのReinforcement learningの適用。前回の記事では、Random Decision Forestアルゴリズムを学び、Reinforcement learning(強化学習)に基づく簡単な自己学習EAを作成しました。このアプローチの主な利点は、取引アルゴリズムを書くことの単純さと『学習」の高速性でした。強化学習(以下、単にRL)は、どのEAにも簡単に組み込むことができ、最適化のスピードを上げられます。
最適化を停止したら、シングルテストモードをオンにします(最良のモデルがファイルに書き込まれ、それだけがロードされるため)。
2か月前の履歴をスクロールして、モデルが4か月全体にわたってどのように機能するかを見てみましょう。
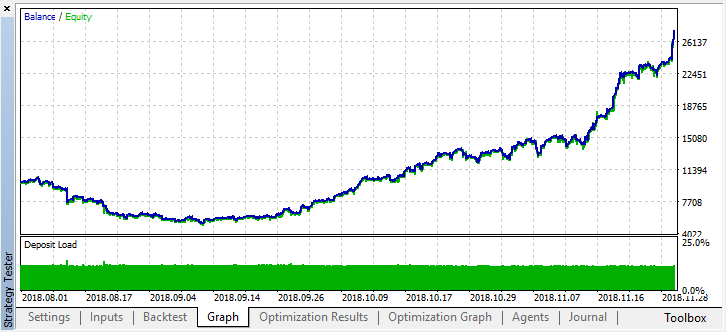
結果として得られたモデルは、8月に故障し、もう1か月(ほぼ9月全体)続いたことがわかります。作者: Maxim Dmitrievsky