C'è uno schema nel caos? Proviamo a trovarlo! Apprendimento automatico sull'esempio di un campione specifico. - pagina 18
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Il random è fisso :) Sembra che questo seme sia calcolato in modo complicato, cioè tutti i predittori consentiti per la costruzione del modello sono probabilmente coinvolti e la modifica del loro numero cambia anche il risultato della selezione.
Il seme iniziale è fisso. E poi un nuovo numero appare a ogni chiamata dell'HSC. Ecco perché con un numero diverso di predittori e un numero diverso di DST non cadrà sullo stesso predittore come con il numero completo di predittori.
Perché questo adattamento, o meglio in cosa lo vedi? Tendo a pensare che il campione di prova differisca dall'esame più che l'esame dal treno, cioè che ci siano distribuzioni di probabilità diverse dei predittori.
Si prendono le migliori varianti dell'esame, sperando che vadano bene anche nel test. Si selezionano i predittori in base all'esame migliore. Ma sono i migliori solo per l'esame.
Che cos'è la metrica "err_"?
err_ oob - errore su OOB (avete l'esame), err_trn - errore sul treno. Con la formula otterremo un errore comune a entrambi i siti campione.
A proposito, nella discussione abbiamo scambiato test ed esame. All'inizio avevamo previsto verifiche intermedie sul test e verifiche finali sull'esame. Ma il contesto chiarisce cosa sia, anche se i nomi sono cambiati.
Il numero iniziale è fisso. Ad ogni chiamata del DST compare un nuovo numero. Pertanto, con un numero diverso di predittori e di DST non cadrà sullo stesso predittore come con un numero completo di predittori.
Nah, le varianti vengono riprodotte se i predittori utilizzati per l'addestramento vengono lasciati nello stesso numero.
Beh, si prendono le migliori varianti d'esame, sperando che siano buone nel test. I predittori sono selezionati dall'esame migliore. Ma sono i migliori solo per l'esame.
È accaduto che questa variante fosse la più equilibrata, con un discreto profitto sia al test che all'esame. Nell'immagine in basso è riportato il modello inizialmente selezionato - "Was" e il modello meglio bilanciato dopo 10k di allenamento - "Became". In generale, il risultato è migliore e vengono utilizzati meno predittori, eliminando così il rumore. La domanda è come evitare questo rumore prima dell'addestramento.
La logica è che l'addestramento si ferma al test, quindi è più probabile che si ottenga un risultato positivo in questo caso che nel campione che non partecipa affatto all'addestramento, quindi l'enfasi è posta su quest'ultimo.
err_ oob - errore su OOB (avete l'esame), err_trn - errore su trn. Dalla formula otterremo alcuni errori comuni a entrambi i siti campione.
Cioè, non so come venga conteggiato "err": è l'accuratezza? E perché l'esame e non il test, perché nell'approccio di base l'esame non lo sapremo.
A proposito, nella discussione abbiamo scambiato test ed esame. All'inizio si pensava di avere i test intermedi nel test e i test finali nell'esame. Ma dal contesto è chiaro cosa sia, anche se hanno cambiato i nomi.
Non ho cambiato nulla (forse mi sono descritto da qualche parte?) - è proprio così: su train - formazione, su test - controllo dell'interruzione della formazione, e su exam - sezione non coinvolta in alcun tipo di formazione.
Sto solo valutando l'efficacia dell'approccio in base alla media di tutti i modelli, compreso il profitto medio - è più probabile ottenere dei bordi con un buon risultato.
E poi c'è la questione di come evitare quel rumore prima di iniziare l'allenamento.
A quanto pare non è possibile. Questo è il compito di filtrare il rumore e imparare dai dati corretti.
Intendo dire che non so come venga considerato "err": è l'accuratezza?
È un modo per ottenere un errore combinato/sommario su una traccia con un test. Qualsiasi tipo di errore può essere sommato. E (1-accuracy) e RMS e AvgRel e AvgCE ecc.
Non ho cambiato nulla(forse mi sono descritto da qualche parte?) - è così che funziona: treno - formazione, test - controllo dell'interruzione della formazione ed esame - sezione non coinvolta in alcun tipo di formazione.
Dalle immagini mi è sembrato che esame significhi test
Per esempio qui.
E nella tabella precedente i risultati dell'esame sono migliori di quelli del test. È certamente possibile, ma dovrebbe essere il contrario.
A quanto pare, no. È proprio questa la sfida: tagliare il rumore e imparare dai dati giusti.
No, deve esserci un modo, altrimenti è tutto inutile/casuale.
Questo è un modo per ottenere l'errore combinato/sommario su una traccia con un test. È possibile sommare qualsiasi tipo di errore. E (1-accuracy) e RMS e AvgRel e AvgCE ecc.
Capito, ma non funziona con i miei dati - dovrebbe esserci almeno una correlazione :)
Dalle immagini mi sembrava che l'esame si riferisse al test
Per esempio qui
E nella tabella qui sopra i risultati dell'esame sono migliori di quelli del test.
Sì, risulta che l'esame è più probabile che faccia guadagnare più soldi ai modellisti - io stesso non ho capito bene la situazione.
Purtroppo, ora ho notato che a un certo punto ho confuso il campione totale (righe) e ora gli esempi del 2022 sono nel treno :(.
Rifarò tutto - penso che avrò il risultato in un paio di settimane - vediamo se il quadro generale cambia.
Purtroppo, ora ho notato che a un certo punto ho confuso il campione totale (righe), e ora il treno include esempi del 2022 :(
Lo rifarò - penso che avrò il risultato tra un paio di settimane - per vedere se il quadro generale cambia.
Non fa alcuna differenza se è stato valutato tramite esame o test. L'importante è che il sito di valutazione non sia stato utilizzato né nella formazione né nella valutazione iniziale.
2 settimane. Mi stupisce la tua resistenza. Anche a me danno fastidio 3 ore di calcoli..... E ho già trascorso un totale di 5 anni in MO, più o meno come te.
Insomma, cominceremo a guadagnare qualcosa in pensione )))) Forse.
Purtroppo mi sono accorto che a un certo punto ho confuso il campione complessivo (righe) e ora il treno è popolato da esempi del 2022 :(
Ho tutto incollato in 1 array sequenziale. E poi separo la quantità giusta da esso. In questo modo non si confonde nulla.
Non fa alcuna differenza se la valutazione è avvenuta tramite esame o test. L'importante è che il sito di valutazione non sia stato utilizzato né nella formazione né nella valutazione iniziale.
Mi chiedo se sia meglio fare la formazione finale come Maxim - prendendo un campione preistorico per il controllo, o se sia meglio prendere l'intero campione disponibile e limitare il numero di alberi, come in media nei modelli migliori.
2 settimane... Sono stupito dalla tua resistenza. Anch'io trovo fastidiose 3 ore di calcoli..... E ho già trascorso un totale di 5 anni su MO, più o meno come te.
Naturalmente, si vuole sempre ottenere risultati più velocemente. Cerco di caricare l'hardware in modo che i miei calcoli non interferiscano con altre cose - spesso non uso il computer principale per lavorare. In parallelo posso implementare altre idee nel codice - mi vengono in mente idee più velocemente di quanto abbia il tempo di verificarle nel codice.
In breve, inizieremo a guadagnare qualcosa in pensione )))) Forse.
Sono d'accordo: la prospettiva è triste. Se non vedessi dei progressi nella mia ricerca, anche se lenti, probabilmente avrei già finito il lavoro.
Ho incollato tutto in un array sequenziale. E poi, da questa matrice, separo la giusta quantità. In questo modo non si confonde nulla.
Sì, ho convertito il campione in un file binario, e nello script ho inserito per sbaglio una casella di controllo, a quanto pare, responsabile della miscelazione del campione - quindi non è un problema, e CatBoost richiede 3 campioni separati - non hanno fatto la selezione sull'intervallo di righe, anche se hanno una convalida incrociata incorporata.
Mi chiedo anche se sia meglio fare l'addestramento finale come Maxim - prendendo un campione preistorico per il controllo, o se sia meglio prendere l'intero campione disponibile e limitare il numero di alberi, come in media nei modelli migliori.
Per me, il pre-training e i test sono un'opportunità per selezionare in media i migliori iperparametri (numero di alberi, ecc.) e predittori. E anche senza un test è possibile allenarsi su di essi sulla linea e passare immediatamente al trading.
L'idea del campionamento preistorico funziona se i modelli non cambiano, forse sì. Ma c'è il rischio che cambino. Preferisco quindi non correre rischi e testare il campionamento futuro.
Un'altra domanda è: quanto tempo fa era questo campione preistorico: sei mesi fa o 15 anni fa? Sei mesi fa potrebbe funzionare, ma il mercato di 15 anni fa non è lo stesso di adesso. Ma non è certo. Forse ci sono schemi che funzionano da decenni.Descriverò i risultati ottenuti utilizzando lo stesso algoritmo che ho descritto qui, ma con il campione non mescolato, cioè rimanendo in ordine cronologico.
L'unica cosa che ho cambiato è che ora l'addestramento di 10000 modelli non è stato eseguito sull'intero campione con i predittori esclusi, ma su un campione riformato in cui le colonne con i predittori esclusi sono state rimosse, il che ha accelerato il processo di addestramento (apparentemente pompare un file di grandi dimensioni richiede molto tempo). Grazie a queste modifiche sono stato in grado di eseguire costantemente 6 fasi di screening dei predittori.
Figura 1: Istogramma del profitto dell'esame campione dopo l'addestramento di 100 modelli su tutti i predittori del campione.
Figura 2: Istogramma del profitto sul campione d'esame dopo l'addestramento di 10k modelli sui predittori selezionati del campione - fase 1.
Figura3. Istogramma del profitto sul campione d'esame dopo l'addestramento di 10k modelli sui predittori del campione selezionato - fase 2.
Figura 4: Istogramma dei profitti per il campione d'esame dopo l'addestramento di 10k modelli sui predittori del campione selezionato - fase 3.
Figura 5: Istogramma dei profitti per il campione d'esame dopo l'addestramento di 10k modelli sui predittori del campione selezionato - fase 4.
Figura 6: Istogramma dei profitti per il campione d'esame dopo l'addestramento di 10k modelli sui predittori del campione selezionato - fase 5.
Figura 7: Istogramma dei profitti per il campione d'esame dopo l'addestramento di 10k modelli sui predittori del campione selezionato - fase 6.
Figura 8. Tabella con le caratteristiche dei modelli selezionati per formare i campioni successivi con un numero decrescente di predittori (caratteristiche).
Consideriamo il modello con le seguenti caratteristiche ottenuto al 6° passo di selezione dei predittori.
Figura 9: Caratteristiche del modello.
Figura 10. Visualizzazione del modello sull'esame del campione come distribuzione della probabilità di classificazione - asse x - probabilità ottenuta dal modello e y - percentuale di tutti i campioni.
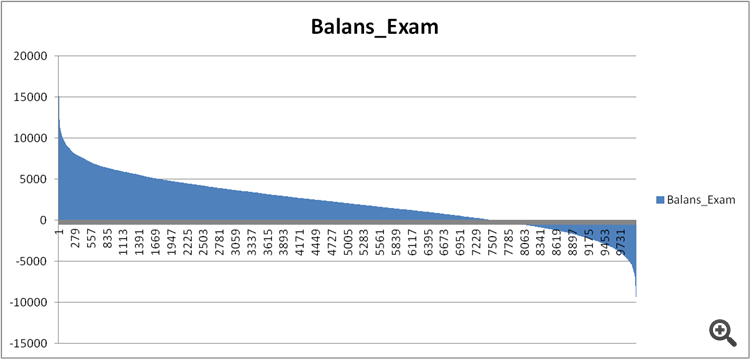
Figura 11. Bilancio del modello sul campione d'esame.
Confrontiamo ora i predittori nei modelli ragionevolmente buoni ed estremamente cattivi ottenuti al passo 6 della selezione dei predittori.
Figura 12. Confronto delle caratteristiche dei modelli.
Possiamo ora vedere quali predittori hanno un effetto negativo sul risultato finanziario e rovinano la formazione?
Figura 13. Ponderazione dei predittori nei due modelli.
La Figura 13 mostra che vengono utilizzati quasi tutti i predittori disponibili, tranne uno, ma dubito che sia questa la radice del problema. Quindi non è tanto una questione di utilizzo, quanto piuttosto di sequenza di utilizzo nella costruzione del modello?
Ho fatto un confronto tra due tabelle, assegnando un numero ordinale di significatività invece di un indice, e ho visto come questa significatività sia classificata in modo diverso nei modelli.
Figura 14: Tabella di confronto della significatività (uso) dei predittori nei due modelli.
Gli scostamenti in meno significano che il predittore del secondo modello (non redditizio) è stato utilizzato più tardi, mentre quelli in più sono stati utilizzati prima.
Figura 15. Deviazioni di significatività dei predittori nei modelli.
Si può notare che ci sono forti deviazioni, forse è questo il caso, ma come scoprirlo/provarlo? Forse è necessario un approccio complesso per confrontare i modelli con il benchmark - qualche idea?
Esiste un qualche tipo di indice di confondimento per descrivere il bias complessivo, magari tenendo conto della significatività dei predittori per il primo modello - cioè con un coefficiente decrescente?
Quali conclusioni si possono trarre?
La mia ipotesi è questa:
1. I risultati sono stati molto migliori nel campione del passato; presumo che ciò sia dovuto alle informazioni che sono "trapelate" sugli eventi del futuro mescolando la cronologia del campione. La questione è se i modelli saranno più stabili con un campione confuso o con un campione normale.
2. È necessario costruire una struttura di significatività dei predittori per la loro ulteriore applicazione nei modelli, cioè oltre ai numeri è necessario stabilire una logica, altrimenti la dispersione dei risultati dei modelli è troppo grande anche su un piccolo numero di predittori.