C'è uno schema nel caos? Proviamo a trovarlo! Apprendimento automatico sull'esempio di un campione specifico. - pagina 11
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Questo è il punto, è migliore di un fattore 2 rispetto alle caratteristiche 5000+.
Risulta che tutti gli altri chip da 5000+ peggiorano solo il risultato. Tuttavia, se li si seleziona, se ne troveranno sicuramente alcuni che migliorano.
È interessante confrontare ciò che il modello mostrerà con questi due.
Ho mat. aspettativa un po 'più di uno, il profitto entro 5 mila, la precisione scrive 51% - cioè i risultati sono chiaramente peggio.
Sì, e sul campione di prova ho ottenuto una perdita in tutti i 100 modelli.Ho mat. aspettativa un po 'più di uno, il profitto entro 5 mila, la precisione dice 51% - cioè, i risultati sono chiaramente peggio.
Sì, e sul campione di prova c'è stata una perdita in tutti i 100 modelli.Ma anche sul primo sta perdendo.
Sul secondo campione H1? Sto migliorando in quello.
E anche sul primo sto perdendo.
Sì, sto parlando del campione H1. Inizialmente sono addestrato su train.csv, mi fermo su test.csv e controllo indipendente su exam.csv, quindi la variante con due colonne fallisce su test.csv. Anche le varianti di ieri erano in perdita, ma c'erano anche quelle che guadagnavano un po'.
Quindi, che tipo di grafici miracolosi avete?E questo è il modo in cui il valving avanza con la formazione su 20000 linee in 10000 linee. Cioè il grafico non mostra 2 anni, ma 5. 2 anni di cui 2 di drawdown, poi un altro anno senza profitto, a causa del quale la vincita media è scesa a 0,00002 per trade. Anche questo non va bene per il trading.
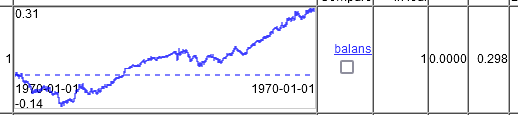
Solo su 2 colonne temporali.
Le stesse impostazioni su tutte le oltre 5000 colonne. Leggermente meglio. 0,00003 per operazione.
Profitto 0,20600, in media 0,00004 per operazione. Commisurato allo spread
Sì, la cifra è già impressionante. Tuttavia, l'obiettivo è segnato per vendere, e lì l'intero periodo su un TF grande è la vendita, penso che anche artificialmente migliora il risultato.
È superiore a 0,00002 su tutte le colonne, ma come ho detto prima "Spread, slippage, ecc. si mangiano tutto il guadagno". Teriminal mostra lo spread minimo per barra (cioè durante l'intera ora), ma al momento dell'operazione può essere di 5-10 pts, e sulle notizie può essere di 20 e più.
Quindi il markup che ho è preso su barre di minuti, gli spread si allargano di solito in un periodo di tempo, cioè in un minuto ci sarà probabilmente un grande spread per tutto il tempo, o non è così ora? Non ho ancora capito come funziona lo spread in 5 - lo trovo più comodo per i test in 4.
Dovresti cercare modelli con vincite medie di almeno 0,00020 per operazione. Poi nel trading reale si può arrivare a 0,00010. Questo è per EURUSD, su altre coppie come AUD NZD anche 50 pts non saranno sufficienti, gli spread sono di 20-30 pts.
Sono d'accordo. Il primo esempio in questo thread dà un'aspettativa di 30 pips. Ecco perché rimango dell'idea che il markup dovrebbe essere intelligente.
Beh, ancora una volta questo è il miglior grafico sul campione d'esame. Come trayne scegliere le impostazioni che poi daranno il miglior equilibrio su quello dell'esame è una domanda senza soluzione. Si sceglie in base al test. Mi sono allenato su traine+test. In pratica, quello che voi avete un esame, io ho un test.
Penso che si dovrebbe iniziare con il far superare alla maggioranza del campione la soglia di selezione. Inoltre, potrebbe avere senso scegliere il modello meno addestrato di tutti - ha meno fitting.
E questo è il modo in cui si procede con l'addestramento su 20000 righe in 10000 righe. Cioè sul grafico non 2 anni, ma 5. 2 anni di questi dovranno rimanere in drawdown, poi un altro anno senza profitto, a causa di questo la vincita media è scesa a 0,00002 per trade. Anche questo non va bene per il trading.
Solo su 2 colonne temporali.
Le stesse impostazioni su tutte le oltre 5000 colonne. Leggermente meglio. 0,00003 per operazione.
Tuttavia, è emerso che anche gli altri predittori possono essere utili. Si può provare ad aggiungerli in gruppi, si possono prima vagliare le correlazioni e ridurle leggermente.
Per quanto riguarda la matrice delle aspettative, forse in questa strategia è più redditizio entrare non all'apertura della candela, ma a 30 pip dal prezzo di apertura - le candele senza coda sono rare.
Quindi il markup che ho è preso su barre di minuti, gli spread si allargano di solito in un periodo di tempo, cioè entro un minuto ci sarà probabilmente un grande spread per tutto il tempo, o non è così ora? Non ho ancora capito come funziona lo spread in 5 - per me è più conveniente fare dei test in 4.
E anche su M1 viene mantenuto lo spread minimo per il tempo della barra. Sui conti ECH quasi tutte le barre M1 hanno 0,00001...0,00002 raramente di più. Tutte le barre senior sono costruite a partire da M1, quindi lo spread minimo sarà lo stesso. È necessario aggiungere 4 pts. di commissione per ogni giro (altri centri di brokeraggio possono avere altre commissioni).
Tuttavia, si scopre che anche gli altri predittori possono essere utili. Si può provare ad aggiungerli in gruppi, si possono prima vagliare le correlazioni e ridurle leggermente.
Forse dovremmo selezionarli. Ma se aggiungere 5000+ a 2 aggiunge un piccolo miglioramento, potrebbe essere più veloce selezionare 10 pezzi con la forza bruta con l'addestramento del modello. Penso che sarà più veloce che aspettare la correlazione per 24 ore. Solo che è necessario automatizzare la riqualificazione in un ciclo direttamente dal terminale.
Katbusta non ha una versione DLL? La DLL può essere richiamata direttamente dal terminale. C'era un articolo con degli esempi qui. https://www.mql5.com/ru/articles/18 e https://www.mql5.com/ru/articles/5798.
Forse dovremmo selezionare. Ma se l'aggiunta di 5000+ ai 2 dà un piccolo miglioramento, potrebbe essere più veloce selezionare 10 pezzi con la forza bruta e l'addestramento del modello. Penso che sarebbe più veloce che aspettare la correlazione per 24 ore.
Sì, all'inizio è meglio farlo a gruppi: si possono fare, ad esempio, 10 gruppi e allenarsi con le loro combinazioni, valutare i modelli, eliminare i gruppi che non hanno avuto successo e raggruppare quelli rimanenti, cioè ridurre il numero di predittori nel gruppo e allenarsi di nuovo. Ho già usato questo metodo in passato: l'effetto c'è, ma non è veloce.
Solo che è necessario automatizzare il re-training in un ciclo direttamente dal terminale.
Catbust non ha una versione DLL? La DLL può essere chiamata direttamente dal terminale. C'era un articolo con degli esempi qui. https://www.mql5.com/ru/articles/18 e https://www.mql5.com/ru/articles/5798.
Sarebbe bello avere un controllo completo dell'apprendimento tramite terminale, ma a quanto ho capito non c'è una soluzione pronta. Esiste una libreria catboostmodel.dll che applica solo il modello, ma non so come implementarla in MQL5. In teoria, ovviamente, è possibile creare un'interfaccia sotto forma di libreria per l'addestramento - il codice è aperto, ma non posso permettermelo.
Sì, all'inizio è meglio in gruppi: si possono creare, ad esempio, 10 gruppi e addestrarli in combinazioni, valutare i modelli, eliminare i gruppi che non hanno avuto successo e raggruppare i rimanenti, cioè ridurre il numero di predittori nel gruppo e addestrarli di nuovo. Ho già usato questo metodo in passato: l'effetto c'è, ma non è veloce.
Propongo qualcosa di diverso. Aggiungiamo le caratteristiche al modello una per una. E selezioniamo le migliori.
1) Addestrare 5000+ modelli su una caratteristica: ciascuna delle 5000+ caratteristiche. Prendere il migliore dal test.
2) Addestrare (5000+ -1) modelli su 2 caratteristiche: la prima caratteristica migliore e( 5000+ -1) le altre. Trovare la seconda migliore.
3) Addestrare (5000+ -2) modelli su 3 caratteristiche: la 1a, la 2a migliore caratteristica e( 5000+ -2) le rimanenti. Trovare la terza migliore.
Ripetere finché il modello non migliora.
Di solito ho smesso di migliorare il modello dopo 6-10 caratteristiche aggiunte. Si può anche arrivare a 10-20 o al numero di caratteristiche che si desidera aggiungere.
Ma credo che la selezione delle caratteristiche in base al test consista nell'adattare il modello alla sezione di test dei dati. Esiste una variante di selezione per trayne con peso 0,3 e test con peso 0,7. Ma credo che anche questo sia un adattamento.
Volevo fare il roll forward, poi il fitting sarà per molte sezioni di test, ci vorrà più tempo per contare, ma mi sembra che questa sia l'opzione migliore.
Anche se non si dispone di automazione per l'esecuzione di catbuster.... 50+ mila volte, sarebbe difficile riqualificare manualmente i modelli per ottenere 10 caratteristiche.Questo è più o meno il motivo per cui preferisco il mio mestiere a Catbust. Anche se funziona 5-10 volte più lentamente di Cutbust. Tu hai avuto un modello per 3 minuti, io ne ho avuti 22.
Non è quello che sto suggerendo. Aggiungiamo le caratteristiche al modello una per una. E selezioniamo le migliori.
1) Addestrare 5000+ modelli su una caratteristica: ciascuna delle 5000+ caratteristiche. Prendere il migliore dal test.
2) Addestrare (5000+ -1) modelli su 2 caratteristiche: la prima caratteristica migliore e( 5000+ -1) le altre. Trovare la seconda migliore.
3) Addestrare (5000+ -2) modelli su 3 caratteristiche: la prima, la seconda migliore caratteristica e( 5000+ -2) le rimanenti. Trovare la terza migliore.
Ripetere finché il modello non migliora.
Di solito ho smesso di migliorare il modello dopo 6-10 caratteristiche aggiunte. Si può anche arrivare a 10-20 o al numero di caratteristiche che si desidera aggiungere.
Gli approcci possono essere diversi - la loro essenza è la stessa in generale, ma lo svantaggio è ovviamente comune: costi computazionali troppo elevati.
Ma credo che la selezione delle caratteristiche per test sia un adattamento del modello alla sezione di test dei dati. Esiste una variante di selezione per trayne con peso 0,3 e test con peso 0,7. Ma credo che anche questo sia un adattamento.
Vorrei fare il valving in avanti, quindi il fitting sarà per molte sezioni di test, ci vorrà più tempo per calcolarlo, ma mi sembra che questa sia l'opzione migliore.
Per questo motivo sto cercando qualche grano razionale all'interno della funzione per giustificare la sua selezione. Finora ho scelto la frequenza di ricorrenza degli eventi e lo spostamento della probabilità della classe. In media, l'effetto è positivo, ma questo metodo valuta effettivamente il primo split, senza tenere conto dei predittori correlati. Ma credo che si dovrebbe provare lo stesso metodo anche per il secondo split, eliminando dal campione le righe sui punteggi dei predittori con una forte predisposizione negativa.
Anche se non hai l'automazione per eseguire catbusters.... 50+ mila volte, sarebbe difficile riqualificare manualmente i modelli per ottenere 10 tratti.
Questo è più o meno il motivo per cui preferisco il mio mestiere al catbuster. Anche se funziona 5-10 volte più lentamente di Cutbust. Tu avevi un modello che richiedeva 3 minuti per essere contato, io ne avevo 22.
Comunque, leggi il mio articolo.... Ora tutto funziona in forma semi-automatica - i task vengono generati e il bootnik viene lanciato (compresi i task per il numero di caratteristiche da utilizzare nell'addestramento, cioè è possibile generare tutte le varianti in una volta e lanciarle). In sostanza è necessario insegnare al terminale a eseguire il file bat, cosa che credo sia possibile, e controllare la fine dell'addestramento, quindi analizzare il risultato ed eseguire un altro task basato sui risultati.
Solo modificando il tasso di apprendimento è stato possibile ottenere due modelli su 100 che soddisfacessero il criterio stabilito.
Il primo.
Il secondo.
È emerso che, sì, CatBoost può fare molto, ma sembra necessario regolare le impostazioni in modo più aggressivo.
Selezionate questi modelli in base ai migliori del test?
O tra i migliori del test - i migliori dell'esame?