Indice Hearst - pagina 20
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
C'è anche la possibilità di dividere permanentemente il segmento a metà.
Hm, e i punti per i quali la differenza Close[i+1]-Close[i] = 0 e la deviazione standard 0, semplicemente non sono considerati quando si costruisce una linea retta?
C'è anche l'opinione che si dovrebbe usare la cosiddetta RANSAC( http://en.wikipedia.org/wiki/RANSAC ) invece del solito ISC per calcolare il coefficiente di Hurst perché i punti "fuori dal numero totale", cioè i più lontani dalla massa totale, possono influenzare il coefficiente di pendenza della linea retta con il solito ISC.
понял. Я брал среднее геометрическое из High и Low. Сейчас посмотрю что будет на разнице. Я пока не могу решить что целесообразнее - брать код для MT4 и переделывать под Си или искать ошибки у себя ;) У меня данные это дневные бары(5ти минутки), всего их 78. Я точки стоил по значениям для 3,4...78и. - МТ4 моментально обсчитает 78 баров, даже до десятка тысяч считает быстро. А вот для каждого бара расчитывать Херста на многотысячной выборке - это уже долго, если баров тоже тыщи.
Есть еще вроде вариант постоянного деления отрезка пополам. - не совсем представляю о чем вы, но если длина выборки - степень двойки, то да, работает. В любом случае предпочтительнее иметь выборку с длиной имеющей как можно больше делителей.
Хм, а точки для которых разница Close[i+1]-Close[i] = 0 и среднеквадратичное отклонение 0, просто не рассматриваются при построении прямой? - (Close[i+1]-Close[i]) - это входные данные, прямая строится не по ним, а по коэффициентам, которые получаются из этих данных при R/S анализе.
Еще есть мнение что подсчета коэффициента Херста нужно использовать не обычный МНК, а т.н. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), т.к. при обычном МНК на коэффициент наклона прямой могут влиять точки, "выбивающиеся из общего числа", т.е. наиболее удаленные от общей массы. - Не представляю на основании какой модели, можно решить, что некоторые возвраты подлежат выбросу из выборки?
(Close[i+1]-Close[i]) = 0 => log(d[i]/d[i-1]) = INF - Non capisco cosa fare con questo. RS = R/S - e come calcolare quando S = 0, supponiamo che anche R = 0? poi di nuovo log(R) = INF e di nuovo non capisco cosa fare. OK. Ecco un semplice esempio - qual è il coefficiente H
e se (Close[i+1]-Close[i]) = const per tutti i su un dato intervallo?
Non ho idea sulla base di quale modello, si può decidere che alcuni rendimenti devono essere scartati dal campione? -Se, per esempio, c'era un errore in diversi valori nel flusso di dati di stock (54,5 invece di 14,4)
la funzione RS prende come input un array di Close[i]-Close[i-1] e il numero di elementi dell'array
1. S[i-1] = Close[i]-Close[i-1] Per tutti gli i da 0 a N
2. h[i] = log(S[i]/S[i-1])
3. hn = Somma di h[i] h_cp = arith. Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5. Allora sto m-n punti con il valore di log RS(i) e log i per i da n_min a qualche N e le MNC stanno una linea retta
В общем давайте я расскажу свой алгоритм обсчета словами, а вы мне скажете пж где ошибка, а то мы так долго друг друга чуствую не поймем.
функция RS на вход принимает массив из Close[i]-Close[i-1] и число элементов массива
1. S[i-1] = Close[i]-Close[i-1] Для всех i от 0 до N
2. h[i] = log(S[i]/S[i-1]) - не стоит так делать, т.к. п.1 и п.2 в принципе одно и тоже в смысле подготовки данных для алгоритма. Действительно, вместо возвратов на вход можно подавать log(Close[i]/Close[i-1]), но подавать на вход логарифм отношения возвратов - это перебор, по-моему. Достаточно подавать что-нибудь одно - либо разницу цен, либо логарифм их отношений.
3. Hn = Сумма h[i] h_cp = ср.ариф. Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5. Далее стою м-во точек со значением log RS(i) и log i для i от n_min до некоторого N и МНК стоют прямую
в п.3-5 для начала не вижу оператора или описания, что вся выборка делится на N кусков размером M, что для каждого этого куска считается rs = (максимум наращиваемой суммы отклонений от среднего - минимум наращиваемой суммы отклонений от среднего) / сумму квадратов отклонений от среднего, и все они, эти rs, складываются, а потом делятся на N. Теперь Log(RS) и log(N) - это одна точка для МНК, которых надо насобирать побольше, подбирая разные N и М так, чтобы N*M=длина выборки всегда. На мой взгляд, запись п.4 полностью неверна.
Da quanto ho capito non ha senso calcolare il coefficiente per 78 valori - cioè per una barra di un giorno? Inoltre non ho ancora capito cosa fare se alcuni valori sono uguali a zero. Per esempio se inserisco la differenza di prezzo, è chiaro che la differenza in 5 minuti può essere inferiore o uguale a 0, ma poi il log non viene preso. Ho un'idea per prendere il modulo del valore nel caso sia negativo (cioè la differenza assoluta) e nel caso di 0 non inserire questo valore nella serie h.
Il file di prova stesso. H~0.72
Il tuo indicatore zHursttExponent.mq4 mostra 0,1647 sul tuo file di test brown72.txt. Di cosa si tratta?
Per quanto ho capito, questo indicatore calcola il valore Hurst per ogni tick delle ultime 2520 barre e lo stampa. È così?
Cosa significano allora i 4 bins di questo indicatore e a cosa servono in una finestra separata?
E un'altra domanda.
for(int i=0; i<limit; i++)
{
}
//---- done
Qual è il significato di questo pezzo nel codice dell'indicatore?
Ваш индикатор zHursttExponent.mq4 на вашем же тестовом файле brown72.txt выдает 0.1647. К чему бы это ?
Насколько я понял, этот индикатор считает показатель Херста на каждом тике для последних 2520 баров и выдает значение на печать. Так ?
А что тогда означают 4 буфера этого индикатора и зачем они нужны в отдельном окне ?
И еще один вопрос.
for(int i=0; i<limit; i++)
{
}
//---- done
Какой смысл имеет этот кусок в коде индикатора ?
1. Non può ripetere il suo risultato = 0,1647. Il mio è così (=0,7241):
2) Sì, questo indicatore considera l'indice Hurst su ogni tick per le ultime 2520 barre e stampa il valore e disegna i punti r/s (linea bianca), sui quali viene disegnata la linea retta di approssimazione (linea rossa), la cui pendenza è l'indice cercato - per chiarezza, ma per me - per una stima visiva qualitativa della correttezza dell'algoritmo. Tutto questo è vero quando cRSGraphic = true, altrimenti l'indicatore considera l'indice Hurst per le ultime 250 barre.
3. 4 buffer sono una ridondanza apparente, una reliquia lasciata dal tempo del debug e dei test.
4. Empty loop - lo stesso problema del punto 3.
Подниму ка тему) Спасибо Vita - написал win32api под c++ и все пашет как надо. Вопрос к людям которые часто применяли этот метод - есть какие-нибудь оценки погрешностей от числа входящих данных, дисперсии, корреляции и мб других стат.величин.
Как я понял вообще смысла особого нет считать коэффициент для 78 величин - т.е для однодневного бара? Так же по прежнему не понимаю что делать если какие-то величины равны нулю. Ну например если на вход подаю разность цен - понятное дело что разность за 5ть минут мб меньше или равны 0, но log тогда не берется. У меня есть идея брать модуль величины в случае если она отрицательна(т.е абсолютную разницу) а в случае 0 не заносить это значение в ряд h.
Ecco una variante in cui l'errore viene contato. Purtroppo, non riesco a trovare dove ho rubato la fonte C di questa meraviglia, ma sostiene di contare da Feder E. Fractals. Per lui Test H=0,6807 per lo stesso file. Sembra che non sia male.
Per 78 valori è il più difficile. Un sacco di lavoro è dedicato a come stimare Hurst su mezzo centinaio di osservazioni. Anche senza capire i calcoli, si ottengono risultati molto diversi da un autore all'altro. Non c'è nulla di sorprendente in questo. Tanti algoritmi quanti sono gli indicatori :). Oh, e un altro problema - nella versione allegata su 1000 osservazioni con l'errore preso in considerazione non possiamo dire nulla sul prezzo - è coerente o no al momento, perché 0,5 si trova proprio tra il canale di errore (linee rosse a cRSGraphic=false).
L'input dovrebbe essere la differenza di prezzo o il logaritmo del rapporto di prezzo.
1. Non può ripetere il suo risultato = 0,1647. Il mio è così (=0,7241):
Hai allegato il file brown72.txt. Tuttavia, il tuo indicatore testa il file brown72.csv. Per mancanza di altre istruzioni, l'ho semplicemente rinominato e messo nella cartella \experts\files. Ecco il risultato:
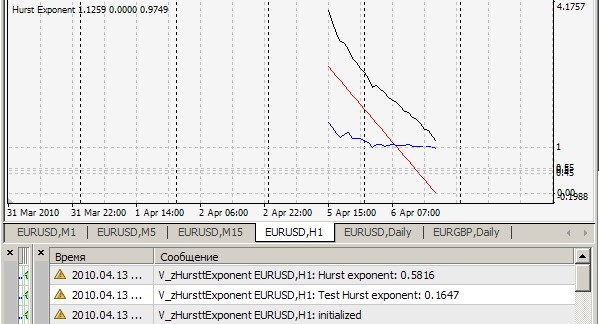
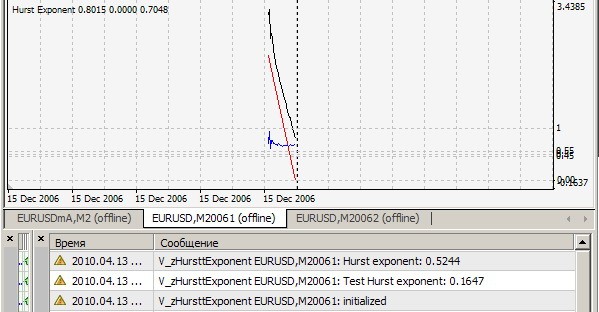
Su H1:
Sulle zecche:
Il tuo file contiene 1024 valori. Ecco i primi 4:
45.47422
42.55601
46.5188
41.61502