Regressione bayesiana - Qualcuno ha fatto un EA usando questo algoritmo? - pagina 40
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
E la mia anima continua a voler scavare nell'argomento delle citazioni incrementali presumibilmente distribuite normalmente.
Se qualcuno è a favore, darò degli argomenti per cui questo processo non può essere normale. E questi argomenti saranno comprensibili a tutti, pur essendo coerenti con la CPT. E questi argomenti sono così banali che non dovrebbero esserci dubbi.
E cosa esprimerà la probabilità, la previsione per la prossima barra o il vettore di movimento delle prossime barre?
La probabilità esprime la previsione del prossimo tick (incremento). Voglio solo farlo:
- calcola i valori dei futuri tick Ybayes per i quali la probabilità secondo la formula di Bayes sarà massima.
- Confrontate Ybayes con le zecche Yreal che arrivano. Raccogliere ed elaborare le statistiche.
Se la differenza di valori è entro un intervallo ragionevole, allora posterò il codice e chiederò cosa fare dopo. Regressione? Vettore? Scalping?
La probabilità esprimerà la previsione del prossimo tick (incremento). Voglio solo farlo:
Perché scendere a zecche? Puoi imparare a prevedere le direzioni dei tick in 5 minuti con una precisione del 70%, ma 100 tick più avanti, sai che la precisione calerà.
Prova con incrementi di mezz'ora o un'ora prima. È interessante anche per me, forse posso aiutare in qualche modo.
La probabilità esprimerà la previsione del prossimo tick (incremento). Voglio solo farlo:
- calcola i valori dei futuri tick Ybayes per i quali la probabilità secondo la formula di Bayes sarà massima.
- Confrontate Ybayes con le zecche Yreal che arrivano. Raccogliere ed elaborare le statistiche.
Se la differenza di valori è entro un intervallo ragionevole, posterò il codice e chiederò cosa fare dopo. Regressione? Vettore? Curva? Scalping?
Cosa c'è di sbagliato nell'ARIMA? Nei pacchetti il numero di diff (incrementi di incrementi) è calcolato automaticamente a seconda del flusso di ingresso. Molte sottigliezze relative alla stazionarietà sono nascoste all'interno del pacchetto.
Se vuoi davvero andare così in profondità, allora qualche ARCH?
L'ho provato una volta. Il problema è questo. L'incremento può essere calcolato facilmente. Ma se aggiungiamo l'intervallo di confidenza di questo incremento all'incremento stesso, sarà o COMPRARE o VENDERE poiché il valore del prezzo precedente cade all'interno dell'intervallo di confidenza.
Sì, l'approccio classico, come scrive SanSanych, è l'analisi dei dati, i requisiti dei dati e gli errori del sistema.
Ma questo thread è su Bayes e sto cercando di pensare in termini bayesiani, come il soldato in trincea che calcola la probabilità posteriore (dopo l'esperienza). Ho dato un esempio del soldato sopra.
Una delle questioni principali è cosa prendere come probabilità a priori. In altre parole, chi dovremmo mettere dietro la tenda del futuro, a destra della barra dello zero? Gauss? Laplace? Wiener? Cosa scrivono qui i matematici professionisti (per me una "foresta" oscura)?
Scelgo Gauss perché ho un'idea della distribuzione normale e ci credo. Se non "sparerà" allora è possibile prendere altre leggi e sostituire Gauss al posto della formula di Bayes, o insieme a Gauss come prodotto di due probabilità. Prova a fare una rete bayesiana, se ho capito bene.
Naturalmente, non posso farlo da solo. Vorrei risolvere il problema con Gauss, che ho formulato sotto il bouquet. Se qualcuno è disposto a unirsi a me su base volontaria, lo faccia per favore. Ecco un problema reale.
Dato: МТ4 generatore di numeri casuali.
Necessità: Scrivere il codice MQL4 come funzione FP() convertendo la matrice МТ4[] formata dalla RNG standard nella matrice ND[] con distribuzione normale.
Vasily (non so il mio patronimico) Sokolov mi ha mostrato le formule di trasformazione in https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
L'altruismo e la gentilezza saranno una rappresentazione grafica dei risultati, anche se posso ingrandire i grafici degli array calcolati direttamente nella finestra di MT4. Lo facevo nei miei progetti.
Capisco che molte persone qui possono risolvere questo problema con un paio di clic in pacchetti matematici, ma voglio parlare in un linguaggio MQL4, che è comunemente compreso da commercianti, programmatori, economisti e filosofi.
Sì, l'approccio classico, come scrive SanSanych, è l'analisi dei dati, i requisiti dei dati e gli errori del sistema.
Ma questo thread è su Bayes e sto cercando di pensare in termini bayesiani, come il soldato in trincea che calcola la probabilità posteriore (dopo l'esperienza). Ho dato un esempio del soldato sopra.
Una delle questioni principali è cosa prendere come probabilità a priori. In altre parole, chi dovremmo mettere dietro la tenda del futuro, a destra della barra dello zero? Gauss? Laplace? Wiener? Cosa scrivono qui i matematici professionisti (per me una "foresta" oscura)?
Scelgo Gauss perché ho un'idea della distribuzione normale e ci credo. Se non "sparerà" allora è possibile prendere altre leggi e sostituire Gauss al posto della formula di Bayes, o insieme a Gauss come prodotto di due probabilità. Prova a fare una rete bayesiana, se ho capito bene.
Naturalmente, non posso farlo da solo. Vorrei risolvere il problema con Gauss, che ho formulato sotto il bouquet. Se qualcuno è disposto a unirsi a me su base volontaria, lo faccia per favore. Ecco un problema reale.
Dato: МТ4 generatore di numeri casuali.
Necessità: Scrivere il codice MQL4 come funzione FP() convertendo l'array MT4[] formato dalla RNG standard in array ND[] con distribuzione normale.
Vasily (non so il mio patronimico) Sokolov mi ha mostrato le formule di trasformazione in https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
Tuttavia posso e posso ridimensionare i grafici degli array calcolati direttamente nella finestra di MT4. Lo stavo facendo nei miei progetti.
Capisco che molti trader possono risolvere questo problema in pacchetti matematici con due click, ma io voglio usare il linguaggio MQL4, che è generalmente accessibile a trader, programmatori, economisti e filosofi.
Ecco un generatore con diverse distribuzioni, compresa quella normale:
https://www.mql5.com/ru/articles/273
Breve analisi della distribuzione in R:
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189Abbiamo stimato i parametri della distribuzione normale dagli incrementi di prezzo di apertura delle barre dell'orologio disponibili e abbiamo tracciato per confrontare la frequenza e la densità per la serie originale e la serie normale con le stesse distribuzioni. Come si può vedere anche a occhio, la serie originale di incrementi di barre orarie è lontana dall'essere normale.
E comunque, non siamo in un tempio di Dio. Non è necessario e persino dannoso credere.
Ecco una linea curiosa dal post sopra, che fa eco a quello che ho scritto sopra
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-076.900e-04 6.849e-02
Per quanto ho capito nei quadranti, il 50% di tutti gli incrementi sull'o'clock sono meno di 7 pips! E gli incrementi più decenti sono nelle code spesse, cioè dall'altra parte del bene e del male.
Come sarà il TS? Questo è il problema, non il bayesiano e altri, altri, altri....
O dovrebbe essere inteso in qualche altro modo?
Ecco una linea curiosa dal post sopra, che fa eco a quello che ho scritto sopra
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-076.900e-04 6.849e-02
Per quanto ho capito nei quadranti, il 50% di tutti gli incrementi sull'orario sono inferiori a 7 pips! E gli incrementi più decenti sono nelle code spesse, cioè dall'altra parte del bene e del male.
Come sarà il TS? Questo è il problema, non il bayesiano e altri, altri, altri....
O dovrebbe essere inteso in qualche altro modo?
SanSanych, sì!
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')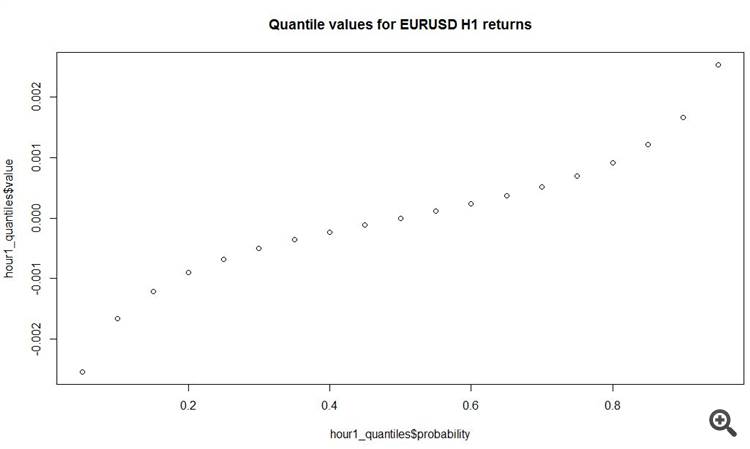
E un'altra cosa interessante è che l'incremento medio assoluto sulle barre orarie è di 11 pips! Totale.
Dovrai farlo per molto tempo, perché hai bisogno di ritrasformazione e... E a Box-Cox non piace molto)))) È solo un peccato che se non hai
È solo un peccato che se non hai dei predittori normali, non avrà molto effetto sul risultato finale...