Les réseaux neuronaux. Questions des experts. - page 5
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
D'accord. C'est ce que je demandais, quelle est la relation entre l'erreur et le profit, de préférence sur OOS....)).
Trop joo vous avez dit que le résultat nu pourrait être dû à la normalisation des données, j'ai répondu qu'il n'y en avait pas.
Je suis d'accord avec Leo pour dire que ce n'est pas toujours le critère de l'erreur qui détermine le bénéfice final, mais c'est l'erreur qui compte dans la tâche que j'ai devant moi maintenant. Je posterai la prévision faite par la grille ce soir pour avoir l'avis des autres sur la qualité de la prévision et les améliorations possibles).
Хорошо, чуть позже (часа через 2-3), попробую обоснованно показать, каким образом профит (или что то другое, не важно, что мы хотим получить от сети) зависит от фитнес функции.
А гарантию того, что мы получим профит в будующем, конечно, никто дать никогда не сможет. А вот к чему стремится должна сетка, пожалуй, мы должны определять для неё однозначно.
Vous ne devez pas perdre votre temps, car la différence entre "vouloir" et "obtenir" n'est pas du tout philosophique, même si elle est formulée en termes philosophiques de "subjectif" et "objectif".
Le fait que les résultats de l'ajustement soient inversement proportionnels à l'erreur quadratique moyenne est quelque chose que nous savons sans vous.
Sans équivoque, le filet doit viser un profit sur l'OOS. Sinon, cela ne sert à rien.
То, что результаты на подгонке обратно пропорциональны среднеквадратичной ошибке - это мы и без Вас знаем.
Utilisez-vous également l'erreur quadratique moyenne ? Vous êtes le père de la mise en réseau des CEM. :)
Reshetov a écrit (a) >>
Il est certain que le réseau doit viser un profit sur l'OOS. Sinon, cela n'a aucun sens.
C'est compréhensible. Une autre question est de savoir comment elle doit s'y prendre pour y parvenir.
Вы тоже что ли используете среднеквадратичную ошибку? Отец эмкуэльных сетей Вы наш. :)
Это и ежу понятно. Другой вопрос, как она должна к этому стремится.
Je n'utilise pas l'erreur quadratique moyenne pour le commerce, car elle caractérise uniquement la qualité de l'ajustement.
Par conséquent, l'erreur dans l'échantillon ne doit en aucun cas tendre à
Comme promis, je poste une photo et une explication. Réseau : MLP une couche cachée. 2000 points en formation. 1000 sur la sortie de l'échantillonneur) j'ai reçu l'EMA actuel et le pré EMA de la première image et le pré-close de la première et de la deuxième. C'est tout ! Pourquoi tout et si peu ? Parce que l'augmentation du nombre de neurones, de couches, d'entrées, etc. n'influence pas du tout le résultat. C'est ce qui me fait peur) Et ce qui est montré comme une prédiction, vous pouvez obtenir, eh bien, une formule très simple, qui est calculé à la main. Pourquoi est-ce si peu clair pour moi. Que dois-je changer ? Peut-on faire mieux ?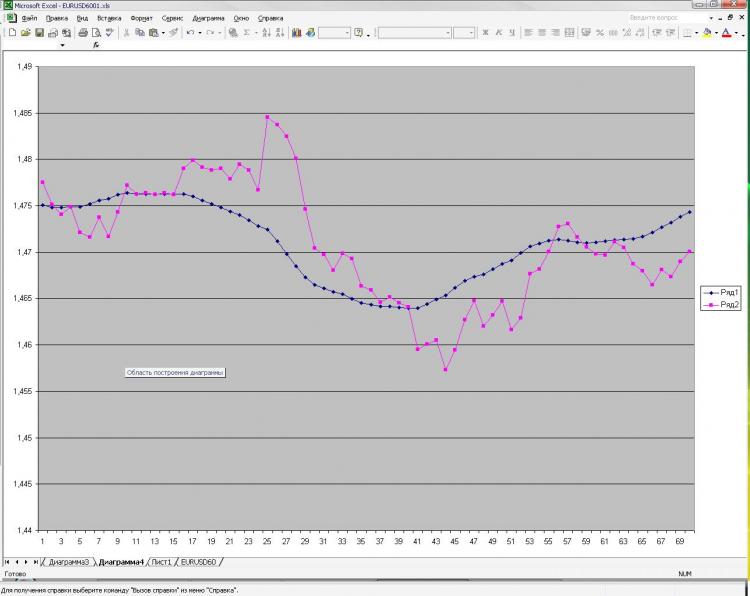
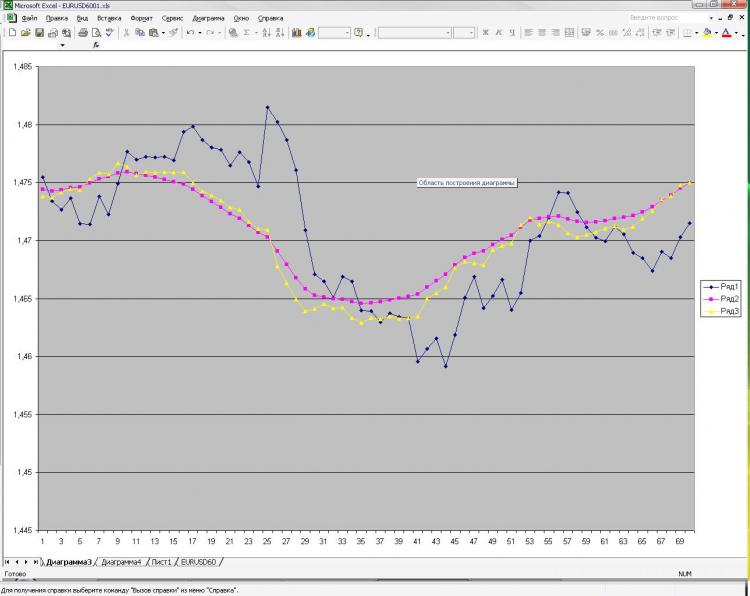
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?
Vous avez décrit le problème de l'approximation. Deux points de "référence" ne suffisent pas à décrire la forme. En outre, vous fournissez un point d'accroche supplémentaire chacun, qui non seulement ne décrit pas la courbure, mais aussi une ligne droite. Essayez au moins 3 points de chaque ensemble de paramètres d'entrée. C'est-à-dire trois points EMA et trois points de clause, donc 6 neurones d'entrée, avec 6 à 12 neurones dans la couche cachée. Un plus grand nombre de neurones dans la couche cachée n'est pas raisonnable pour ce problème.
Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
Donnez-moi un échantillon ici, je vais l'essayer dans Statistica.