L'apprentissage automatique dans la négociation : théorie, modèles, pratique et algo-trading - page 2476
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
il s'agit de la responsabilité du même développeur - je ne crois pas et ne vois aucune raison d'inclure des modèles financiers issus de livres/blogs/articles (et des distributions traitées statistiquement) dans l'analyse financière lors de l'approximation/interpolation du chaos... pour extrapoler davantage la sortie
Oui c'est la base, vous voyez le truc, les gens ont créé ces formules et modèles sans référence au problème, ils ont essayé de faire quelque chose d'universel, en pensant naïvement que ça s'applique à tout. Pour une raison ou une autre, tout le monde aime jeter des mots comme Laplace, Fourier, Taylor, distribution normale, et penser que si l'on intègre tout cela dans un système, alors tout devrait fonctionner pour une raison ou une autre. J'étais doué pour cela, j'avais l'habitude de dériver la formule de Tsiolkovsky sur mon genou et personne ne pouvait comprendre comment je le faisais... J'ai eu cette expérience, j'étais J'ai essayé de prédire la prochaine bougie dans mon conseiller expert en utilisant des systèmes d'équations linéaires, j'ai fait d'énormes matrices, j'ai calculé les déterminants et d'autres choses, et j'ai pensé que c'était tellement cool, que personne ne l'avait, mais quand je l'ai testé, il s'est avéré que c'était de la merde, je pensais que c'était tellement cool et que personne d'autre ne l'avait, mais quand je l'ai testé, il s'est avéré que c'était de la merde totale. bien que selon mon estimation, j'aurais dû devenir le gourou du marché dans un instant, c'était probablement il y a 5 ans, je venais juste de terminer l'université (au fait, je connaissais très bien les mathématiques et la physique), je veux dire que connaître des formules et des théorèmes géniaux ne nous rend pas plus forts que le trader moyen, et si nous nous occupons des aspects pratiques, nous sommes encore plus faibles à la fin... Il faut d'abord se poser la question de savoir sur quoi nous comptons, y répondre en termes humains simples, puis transformer le tout en critères mathématiques. Maintenant, je sais que pour faire cela, il ne faut pas penser au modèle original et à la façon de le construire, mais il faut aller de la fin au début, si le modèle produit les bons chiffres, alors après cela, on peut essayer de le comprendre, mais tout se résume à l'IA, et plus le système est intelligent, plus il va embêter les maths, j'ai surmonté cette barrière et dans mon travail, j'essaie de déléguer autant que possible à la machine.
J'ai trouvé votre réponse plus tôt... J'ai peut-être été hâtif avec mon message précédent... il faudrait probablement au moins partir d'une parabole comme fonction décrivant le mouvement avec vitesse et accélération... (J'ai même vu ce type de graphiques et de grecques (delta et gamma) d'options quelque part - je ne m'en souviens pas et je ne peux pas le trouver - et je n'en ai pas besoin - parce que nous avons besoin d'une analyse temporelle - horizontale, pas verticale)
J'ai simplement donné la parabole comme exemple de la façon dont un nombre infini de données peut être comprimé en un nombre fini, il y a un nombre infini de points sur le graphique, et il peut être réduit à une formule avec seulement 3 coefficients. Je comprends ce que vous pensez. Vous pouvez prendre n'importe quelle fonction comme :
A[1]*X^0+A[2]*X^1+ ... + A [N]*X^N, c'est dans le cas général une série de Taylor (série fonctionnelle), sauf que A[i] > 0 pour tout i = 1...N cela donne dans le cas général une croissance constante de la dérivée première, pour le dire clairement:
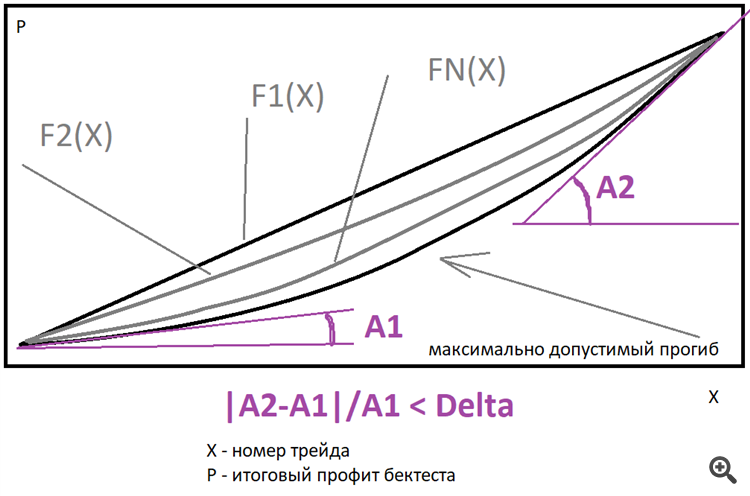
Idéalement, une ligne droite est préférable, mais vous pouvez utiliser une famille de fonctions de puissance du type que j'ai décrit ci-dessus pour estimer les écarts. Il suffit de préciser combien de fois la dérivée finale peut être supérieure à la dérivée de départ. Il est possible d'approcher le graphique final près d'une telle famille, de trouver la meilleure fonction et de rechercher la déviation du graphique réel par rapport à cette fonction. Je n'utilise que la ligne droite, mais peut-être que j'étendrai la fonctionnalité plus tard, cela donnera un gain d'efficacité et, par conséquent, peut diminuer le besoin d'installations informatiques dans le cas d'une approche intelligente.
Evgeniy Ilin # :
réduire le besoin de puissance de calcul avec la bonne approche.
Obtenez une bibliothèque sur les méthodes numériques et vous obtiendrez une augmentation de la puissance, peut-être même sur les processeurs.
Obtenez une bibliothèque pour les méthodes numériques et il y aura une augmentation de la puissance, peut-être même sur le gpu.
L'idée n'est pas mauvaise, mais pour autant que je sache pour vidyuha besoin d'écrire du code d'une manière très étrange, comme tout fonctionne un peu différemment, bibliothèque prête à l'emploi est peu susceptible de travailler, très probablement vous aurez à écrire vous-même. Au fait, peut-être que je mettrai la main dessus un jour.
Donc, comme toujours, toute différenciation se résume à MNC... et toute la prédiction du futur à la fonction cible, qui devrait être dérivée de cette LOC... merci pour les images...
Je vais réfléchir à la manière d'estimer l'offre et la demande pour le moment (la liquidité réelle est plus importante pour moi que les régularités non découvertes, que je ne suis pas encore prêt à confier à une machine à probabilité statistique)...
mais je me souviendrai de la responsabilité du développeur de choisir les fonctionnalités qui sont importantes pour lui ... Et ensuite, selon le modèle : normaliser les entrées, calculer les probabilités, probablement regrouper (s'il y a beaucoup de données), construire un gradient, trouver tous les creux (en utilisant OLS), normaliser tous les creux et résumer dans une fonction commune... comme je l'ai dit "jusqu'à ce que le visage soit bleu"... mais l'assistance par machine est plus rapide...
Idéalement, une ligne droite est la meilleure, mais vous pouvez utiliser une famille de fonctions de puissance comme celle que j'ai décrite ci-dessus pour estimer les valeurs aberrantes. Il suffit de préciser combien de fois la dérivée finale peut être supérieure à la dérivée de départ.
La famille des fonctions de puissance se transforme-t-elle en une distribution log-normale ou la reflète-t-elle ?... désolé si la question est idiote
question supprimée, la réponse est probablement non .
En fait, je ne comprends pas grand-chose. Disons-le ainsi :
1) Quelle est la fonction cible et pourquoi en avez-vous besoin ?
2) Pourquoi avez-vous besoin de la distribution lognormale et pourquoi pensez-vous en avoir besoin ?
3) Je ne comprends pas bien comment une "famille" de fonctions peut se transformer en une seule fonction prototypique, même une distribution lognormale.
4) La distribution lognormale de quoi ? Quelle est la variable aléatoire de votre distribution ?
5 ) Qu'est-ce qu'un MNC ?
Essayez de poser la question dans un langage simple et d'obtenir une réponse simple (désolé, le cas échéant).
En fait, je ne comprends pas grand-chose. Disons-le ainsi :
1) Quelle est la fonction cible et pourquoi en avez-vous besoin ?
2) Pourquoi avez-vous besoin de la distribution lognormale et pourquoi pensez-vous en avoir besoin ?
3) Je ne comprends pas bien comment une "famille" de fonctions peut se transformer en une seule fonction prototypique, même une distribution lognormale.
4) La distribution lognormale de quoi ? Quelle est la variable aléatoire de votre distribution ?
5 ) Qu'est-ce qu'un MNC ?
Essayez de poser une question dans un langage simple et obtenez une réponse simple (désolé, si c'est le cas).
1) la sortie est une fonction de prédiction (dans ce contexte, pas pour les niveaux du réseau neuronal)
2) parce qu'il y a une asymétrie (introduite par %rate*time et les acheteurs vendeurs eux-mêmes)
3) ... parce qu'ils sont du même type - pourquoi le prototype devrait-il être différent ?...allez, je vois que la distribution de puissance est un indicateur de dépendance inverse
4) le prix est une variable aléatoire
5) la méthode des moindres carrés
la question était à l'origine (dans mon esprit) "déterminer le déséquilibre cumulé Débit-Crédit" (aussi désolé pour l'expression) en Gamme (et à l'horizon) -- ici, sans apprentissage, il faut compter pour l'instant... Mais merci pour le rappel sur la modélisation - je ne suis pas physicien, je suis écologiste - c'est plus facile pour nous (sans fonctions et modélisation, mais avec des distributions, des faits et des probabilités ; nous ne prédisons pas l'écosystème, bien qu'il serait bon d'évaluer les risques parfois ; nous n'avons pas creusé profondément dans la théorie) - c'était juste intéressant ce que nous pourrions faire avec ces probabilités plus tard (avec profit)
En fait, je ne comprends pas grand-chose. Disons-le ainsi :
1) Quelle est la fonction cible et pourquoi en avez-vous besoin ?
2) Pourquoi avez-vous besoin de la distribution lognormale et pourquoi pensez-vous en avoir besoin ?
3) Je ne comprends pas bien comment une "famille" de fonctions peut se transformer en une seule fonction prototypique, même une distribution lognormale.
4) La distribution lognormale de quoi ? Quelle est la variable aléatoire de votre distribution ?
5 ) Qu'est-ce qu'un MNC ?
Essayez de poser la question dans un langage simple et vous obtiendrez une réponse simple (désolé, le cas échéant).
1) la cible ou la fonction d'aptitude est une mesure quantitative des performances de votre algorithme.
Si vous entraînez par exemple la régression, la fonction cible est une fonction/formule utilisée pour calculer une erreur pour l'algorithme, même chose avec l'algorithme génétique ou tout autre algorithme qui minimise/maximise presque tout algorithme MO
https://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BB%D0%B5%D0%B2%D0%B0%D1%8F_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F
5) la méthode des moindres carrés
- Je l'ai - pour optimiser n'importe quel TS sur n'importe quel indice (en s'entraînant pendant n'importe quelle période, au choix du développeur)... - pour obtenir les conditions pour entrer avec une erreur minime dans votre propre indu...
(bien que ces probabilités soient différentes de celles auxquelles je pensais en tant qu'écologiste, en évaluant l'environnement et les conditions).