Discusión sobre el artículo "Redes neuronales: así de sencillo (Parte 45): Entrenando habilidades de exploración de estados"
¿Cómo ejecutar pruebas sin utilizar OpenCL?
Porque el procesador es compatible con OpenCL, pero la tarjeta de vídeo no y no se inicia ni la prueba ni la optimización....
Porque el procesador es compatible con OpenCL, pero la tarjeta de vídeo no y no se ejecuta ni la prueba ni la optimización....
Buenos días, Oleg.
Esta implementación sólo funciona con OpenCL. Para desactivarla hay que rediseñar todo el algoritmo de red. Pero si se puede ejecutar en un procesador, si este soporta OpenCL y se instalan los drivers correspondientes.
Buenas tardes, Oleg.
Esta implementación sólo funciona con OpenCL. Para desactivarla hay que rediseñar todo el algoritmo de red. Pero si se puede ejecutar en el procesador, si soporta OpenCL y se instalan los drivers correspondientes.
Este es el error que obtengo (ver la captura de pantalla). En la captura se puede ver que la tarjeta de video no soporta OpenCL, pero el procesador está bien. ¿Cómo puedo evitar esto y ejecutarlo en un tester u optimizador? ¿Qué me pueden aconsejar?

Este es el error que obtengo (ver captura de pantalla). La captura de pantalla muestra que la tarjeta de vídeo no es compatible con OpenCL, pero el procesador está bien. ¿Cómo puedo evitar esto y ejecutarlo en un probador u optimizador? ¿Qué me pueden aconsejar?
El problema es que estás ejecutando "tester.ex5", que comprueba la calidad de los modelos entrenados y aún no los tienes. Primero tienes que ejecutar Research.mq5 para crear una base de datos de ejemplos. Luego StudyModel.mq5, que entrenará el autoencoder. El actor se entrena en StudyActor.mq5 o StudyActor2.mq5 (función de recompensa diferente. Y sólo entonces funcionará tester.ex5. Tenga en cuenta que en los parámetros de este último debe especificar el modelo de actor Act o Act2. Depende del Asesor Experto utilizado para estudiar Actor.
Este es el error que obtengo (ver captura de pantalla). La captura de pantalla muestra que la tarjeta de vídeo no es compatible con OpenCL, pero todo está en orden con el procesador. ¿Cómo puedo evitar esto y ejecutarlo en un probador u optimizador? ¿Qué me pueden aconsejar?
No tienes suerte amigo. Me encuentro con el mismo problema con mi i5-12400
Al parecer, algunos Intel 12 gen y 13 gen no es compatible con el cálculo fp64.
Intel secretamente excluir fp64 de esos dos gen de procesador aunque fp64 estará de vuelta en 14 gen.
El problema es que ejecutas "tester.ex5", que comprueba la calidad de los modelos entrenados, y aún no los tienes. Primero tienes que ejecutar Research.mq5 para crear una base de datos de ejemplos. Después StudyModel.mq5, que entrenará el autoencoder. El actor se entrena en StudyActor.mq5 o StudyActor2.mq5 (función de recompensa diferente. Y sólo entonces funcionará tester.ex5. Tenga en cuenta que en los parámetros de este último debe especificar el modelo de actor Act o Act2. Depende del Asesor Experto utilizado para estudiar Actor.
Comienza a optimizar la Investigación.
Como resultado, escribe lo siguiente en el log:
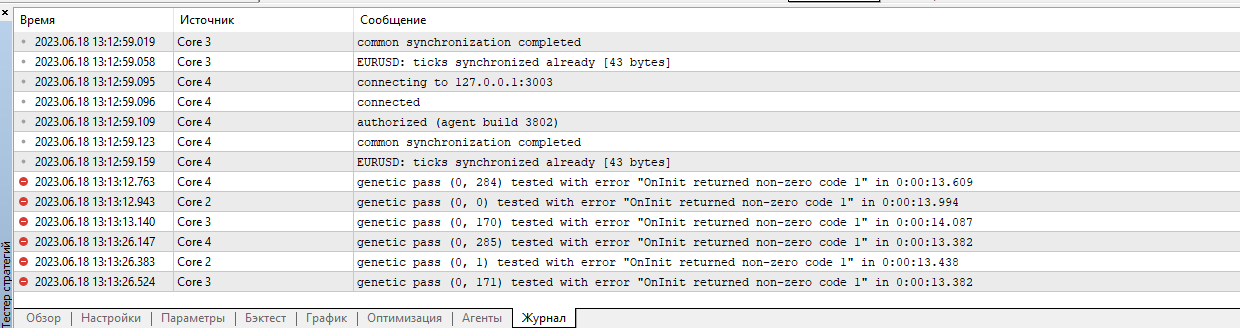
¿Estoy haciendo algo mal otra vez?
No tienes suerte amigo. Me encuentro con el mismo problema con mi i5-12400
Al parecer algunos Intel 12 gen y 13 gen no soporta el cálculo fp64.
Intel secretamente excluir fp64 de esos dos gen de procesador aunque fp64 estará de vuelta en 14 gen.
Esta versión no utiliza fp64. Sólo fp32. Lo he probado en Iris Xe i7-1165

¿Algún mensaje en el registro del agente de pruebas? En algunas etapas de la interrupción de la inicialización, el EA muestra mensajes.
He borrado todos los registros del probador y corrí la optimización de Investigación para los primeros 4 meses de 2023 en EURUSD H1.
Lo ejecuté en ticks reales:
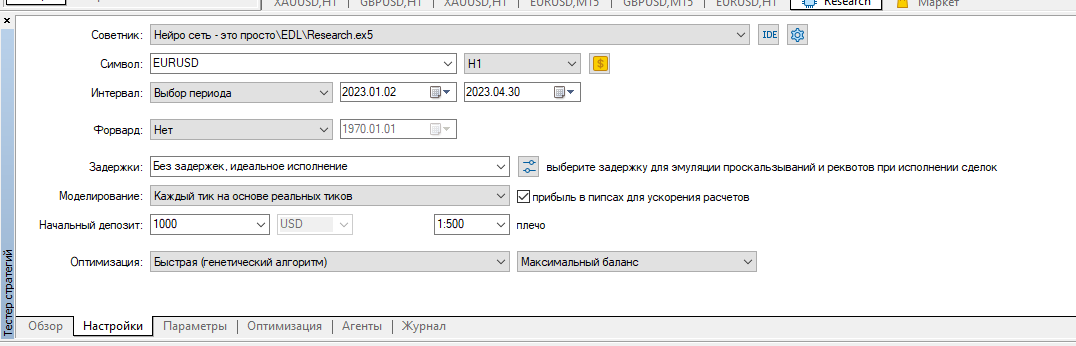
Resultado: sólo 4 muestras, 2 en más y 2 en menos:

Tal vez estoy haciendo algo mal, la optimización de los parámetros equivocados o algo mal con mi terminal? No está claro... Estoy intentando repetir tus resultados como en el artículo...
Los errores empiezan desde el principio.
El conjunto y el resultado de la optimización, así como los registros de los agentes y el probador se adjuntan en el archivo Research.zip.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Redes neuronales: así de sencillo (Parte 45): Entrenando habilidades de exploración de estados:
El entrenamiento de habilidades útiles sin una función de recompensa explícita es uno de los principales desafíos del aprendizaje por refuerzo jerárquico. Ya nos hemos familiarizado antes con dos algoritmos para resolver este problema, pero el tema de la exploración del entorno sigue abierto. En este artículo, veremos un enfoque distinto en el entrenamiento de habilidades, cuyo uso dependerá directamente del estado actual del sistema.
Debemos decir que los primeros resultados han sido peores de lo que esperábamos. Los resultados positivos incluyen una distribución bastante uniforme de las habilidades utilizadas en la muestra de prueba, pero aquí terminan los resultados positivos de nuestras pruebas. Tras varias iteraciones de entrenamiento del autocodificador y del agente, todavía no hemos podido obtener un modelo capaz de generar ganancias en el conjunto de entrenamiento. Aparentemente el problema reside en la incapacidad del autocodificador para predecir estados con suficiente precisión. Como resultado, la curva de balance se encuentra lejos del resultado deseado.
Para probar nuestra suposición, hemos creado un asesor alternativo de entrenamiento de agentes, "EDL\StudyActor2.mq5". La única diferencia entre la opción alternativa y la comentada anteriormente es el algoritmo para generar la recompensa. También hemos utilizado un ciclo para predecir los cambios en el estado de la cuenta. Solo que esta vez hemos usado el indicador de cambio de balance relativo como recompensa.
El agente que hemos entrenado usando la función de recompensa modificada ha mostrado un aumento bastante regular en la rentabilidad durante todo el periodo de prueba.
Autor: Dmitriy Gizlyk