OpenCL: pruebas de implementación interna en MQL5 - página 29
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
...
--
Haz 512 y mira lo que consigues. No tengas miedo de machacar el programa, sólo lo mejorará. :) Cuando lo hayas hecho, publícalo aquí.
¡BIEN! Con 512 pases y 144000 bares:
Bueno y si 60 es lo óptimo, pues en general genial:
//---
Es decir, en el portátil más débil presentado en este hilo, este es el resultado. Es muy prometedor.
//---
Desgraciadamente, no puedo hablar del tema con libertad, ya que ni siquiera me he metido en el artículo de joo y las redes neuronales, mientras que nunca he escarbado en OpenCL. No puedo usar este o aquel código sin entender cada línea de código. Quiero saberlo todo. ))) Todavía estoy trabajando en el motor del programa de comercio. Hay tanto que hacer que mi cabeza ya está dando vueltas. )))
Aumento de CountBars por un factor de 30 (a 4.320.000), decidió probar la resistencia de la piedra a la carga.
No importa: funciona, se calienta, pero no suda demasiado. La temperatura sube lentamente, pero ya ha alcanzado la saturación.
La línea roja es la temperatura, la línea verde es la carga de los núcleos.
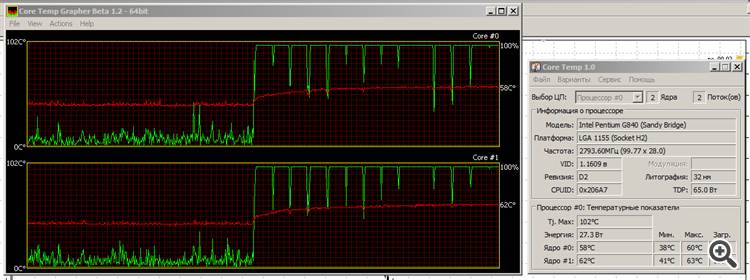
Por eso me encanta el ejemplar Sandy Bridge de Intel: es "verde". Sí, los gráficos no son geniales, pero ya veremos en qué se convierte Ivy Bridge......
Por eso me encanta el modelo Sandy Bridge de Intel: es "verde". Sí, los gráficos no son muy buenos, pero ya veremos en qué se convierte Ivy Bridge...Oh. Eso sí que es una prueba de esfuerzo. :) El mío probablemente ya estaría muerto.
Luego que un Haswell y luego un Rockwell un poco más tarde... )))
Un ejemplo de implementación del helecho de Barnsley en OpenCL.
El cálculo se basa en el algoritmo Chaos Game(ejemplo) y utiliza un generador de números aleatorios con una base de generación que depende del ID del hilo y devuelve get_global_id(0) para crear trayectorias únicas.
Al escalar, el número de puntos necesarios para mantener la calidad de la imagen crece cuadráticamente, por lo que esta implementación asume que cada instancia del núcleo dibuja un número fijo de puntos que caen dentro del área visible.
El número de hilos estimados se especifica en la línea 191:
el número de puntos está en la línea 233:
UPD
IFS-fern.mq5 - CPU análoga
A escala=1000:
He hecho tres capas de neuronas de 16x7x3. En realidad, lo he hecho anteayer, lo he depurado hoy. Antes de eso los resultados no encajaban al comprobarlo con la CPU - no describiré aquí las razones, al menos no ahora - tengo demasiado sueño. :)
Características temporales :
Mañana haré el optimizador para esta rejilla. Luego me ocuparé de cargar datos reales y terminar el probador hasta cálculos realistas verificables con MT5-tester. Luego me ocuparé del generador MLP+cl-codes de las rejillas para su optimización.
No publico el código fuente por avaricia, pero se incluye el ex5 para aquellos que quieran probarlo en su hardware.
Estoy tan estable como bajo Putin:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
Por cierto, presta atención: en tiempo de ejecución de la CPU la diferencia entre tu sistema y el mío (basado en Pentium G840) no es tan grande.
¿Es rápida su memoria RAM? Tengo 1333 MHz.
Una cosa más: es interesante que ambos núcleos se carguen en la CPU durante los cálculos. La brusca caída de la carga al final es posterior al final de los cálculos. ¿Qué significa eso?
Estoy tan estable como bajo Putin:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
1. Por cierto, fíjate en la diferencia entre tu sistema y el mío (basado en Pentium G840) en el tiempo de ejecución de la CPU.
2. ¿Es rápida su memoria RAM? Tengo 1333 MHz.
1. He estado restaurando mi overclocking en mi tiempo libre. Una vez tuve un fallo muy grave (descubrí después que el cable de alimentación de la unidad se había caído), así que pulsé el botón "MemoryOK" de la placa base en busca de un milagro. Después de eso, seguía sin funcionar, sólo que la configuración de la CMOS se restableció a los valores predeterminados. Ahora, he vuelto a overclockear el procesador a 3840 MHz, por lo que ahora funciona de forma más inteligente.
2. Todavía no puedo entenderlo. :) En particular, el benchmark, al que Renat mostró el enlace, muestra 1600MHz. El Windows muestra incluso 1033MHz :)))), a pesar de que la memoria en sí es de 2GHz, pero mi madre puede tirar hasta 1866 (figuradamente).
Una cosa más: es interesante que tenga los dos núcleos cargados al calcular en la CPU. La brusca caída de la carga al final es posterior al final de los cálculos. ¿Qué significaría?
Así que tal vez no es en la GPU en absoluto? El conductor es hasta, pero ... Mi única explicación es que el cálculo se realiza en CPU-OpenCL, sólo que, por supuesto, en todos los núcleos disponibles y utilizando instrucciones vectoriales SSE. :)
La segunda variante es que cuente simultáneamente con la CPU y el CPU. No sé cómo se implementa este soporte (CPU-LPU) por el controlador, pero en principio no excluyo tal variante de inicio de procesamiento de opentCL también.
Esta es mi especulación, en todo caso. O, como está de moda escribir ahora, "IMHO". ;)
Lo dudo. Sobre todo porque sólo tengo dos núcleos. ¿De dónde sale entonces el beneficio de 25 veces?
Si tienes Intel Math Kernel Library o Intel Performance Primitives (no los he descargado), es posible... en algunos casos. Pero es poco probable, ya que pesan cientos de megas.
Tendré que ver qué dice Google al respecto.
Mathemat: También, curiosamente, mis cálculos de la CPU tienen ambos núcleos cargados.
No, me refería a la computación pura de la CPU sin ningún tipo de OpenCL. La carga está justo por debajo del 100%, donde cada núcleo tiene valores de carga comparables. Pero cuando se ejecuta código OpenCL, sube al 100%, lo que puede explicarse fácilmente por el funcionamiento de la GPU.