"New Neural" es un proyecto de motor de red neuronal de código abierto para la plataforma MetaTrader 5. - página 56
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Sí, eso es exactamente lo que quería saber.
A mql5
SZ La principal preocupación en este momento es si será necesario copiar los datos en matrices especiales de la CPU o si se podrá pasar una matriz como parámetro en una función normal. Esta cuestión puede cambiar fundamentalmente todo el proyecto.
ZZY ¿puede responder en sus planes a sólo dar la API OpenCL, o está planeando envolverlo en sus propias envolturas?
2) Habrá un wrapper, sólo se soportarán las GPUs HW (con soporte OpenCL 1.1).
La selección de múltiples GPUs, si la hay, sólo será posible a través de la configuración del terminal.
OpenCL se utilizará de forma sincrónica.
Sí, eso es exactamente lo que quería saber.
A mql5
SZ La principal preocupación en este momento es si será necesario copiar los datos en matrices especiales de la CPU o si se podrá pasar una matriz como parámetro en una función normal. Esta cuestión puede cambiar fundamentalmente todo el proyecto.
ZZZY ¿puede responder en los planes de sólo dar la API OpenCL o está planeando envolverlo en sus propias envolturas?
A juzgar por:
mql5:
De hecho, podrá utilizar las funciones de la biblioteca OpenCL.dll directamente sin tener que conectar las DLL de terceros.
Las funciones de OpenCL.dll estarán disponibles como si fueran funciones nativas de MQL5 mientras que el compilador redirigirá las llamadas por sí mismo.
De esto se puede concluir que las funciones de OpenCL.dll ya se pueden establecer (llamadas ficticias).
Renat y mql5, ¿he entendido bien el "entorno"?
A juzgar por:
Las funciones de OpenCL.dll se pueden utilizar como si fueran funciones nativas de MQL5 y el propio compilador redirigirá las llamadas.
De esto se puede concluir que las funciones de OpenCL.dll ya se pueden establecer (llamadas ficticias).
Renat y mql5, ¿he entendido bien la "situación"?
Hasta aquí el esquema del proyecto:
Los objetos son rectángulos, los métodos son elipses.Los métodos de procesamiento se dividen en 4 categorías:
Estos cuatro métodos describen todo el procesamiento a través de todas las capas, los métodos se importan en el procesamiento a través de objetos de método, que se heredan de la clase base y se sobrecargan según sea necesario en función del tipo de neurona.
Nikolai, ya conoces el eslogan: la optimización prematura es la raíz de todos los males.
Olvídate de OpenCL por ahora, tendrás que hacer algo decente sin ella. Siempre tendrá tiempo para transponerlo, sobre todo si aún no está disponible.
Nikolay, conoces una frase muy popular: la optimización prematura es la raíz de todos los males.
Olvídate de OpenCL por ahora; podrías haber escrito algo decente sin ella. Además, todavía no hay una función interna.
Sí, es una frase popular y la última vez estuve a punto de coincidir con ella, pero después de analizarla me di cuenta de que no podía simplemente planificarla y luego rediseñarla para la GPU, tiene necesidades muy específicas.
Si planeamos sin GPU, entonces sería lógico hacer un objeto Neuron, que sería responsable tanto de las operaciones dentro de una neurona, como de la asignación de los datos de cálculo en las celdas de memoria requeridas, heredando una clase de ancestro común podríamos conectar fácilmente el tipo de neurona requerida y así sucesivamente,
Pero después de haber trabajado con mi cerebro un poco, inmediatamente entendí, que este enfoque va a destruir por completo los cálculos de GPU, el niño por nacer está condenado a arrastrarse.
Pero sospecho que mi post de arriba te ha confundido. Por "método de cálculo paralelo" allí me refiero a la operación bastante específica de multiplicar las entradas con los pesos en*wg, por método de cálculo sucesivo me refiero a suma+=a[i] y así sucesivamente.
Sólo para una mejor compatibilidad con la GPU en el futuro, propongo derivar las operaciones de las neuronas y combinarlas en un solo movimiento en un objeto de capa, y las neuronas sólo suministrarían información de dónde tomar donde ponerlas.
Conferencia 1 aquí https://www.mql5.com/ru/forum/4956/page23
Conferencia 2 aquí https://www.mql5.com/ru/forum/4956/page34
Conferencia 3 aquí https://www.mql5.com/ru/forum/4956/page36
Conferencia 4 aquí https://www.mql5.com/ru/forum/4956/page46
Conferencia 5 (última). Codificación dispersa
Este tema es el más interesante, y lo iré escribiendo poco a poco. Por lo tanto, no te olvides de revisar este post de vez en cuando.
En general, nuestra tarea consiste en presentar la cotización del precio (vector x) en las últimas N barras como una descomposición lineal en funciones base (series de la matriz A):
donde s son los coeficientes de nuestra transformación lineal que queremos encontrar y utilizar como entradas a la siguiente capa de la red neuronal (por ejemplo, SVM). En la mayoría de los casos, conocemos las funciones base A , es decir, las elegimos de antemano. Pueden ser senos y cosenos de diferentes frecuencias (obtenemos la transformada de Fourier), funciones de Gabor, Hammotons, wavelets, curlets, polinomios o cualquier otra función. Si conocemos de antemano estas funciones, la codificación dispersa se reduce a encontrar un vector de coeficientes s de forma que la mayoría de estos coeficientes sean cero (vector disperso). La idea es que la mayoría de las señales de información tienen una estructura que se describe con un número de funciones base menor que el número de muestras de la señal. Estas funciones base incluidas en la descripción dispersa de la señal son sus características necesarias que pueden utilizarse para la clasificación de la señal.
El problema de encontrar la transformación lineal descargada de la información original se llama Compressed Sensing (http://ru.wikipedia.org/wiki/Compressive_sensing). En general, el problema se formula como sigue:
minimizar la norma L0 de s, sujeto a As = x
donde la norma L0 es igual al número de valores no nulos del vector s. El método más común para resolver este problema es la sustitución de la norma L0 por la norma L1, que constituye la base del método de búsqueda de bases(https://en.wikipedia.org/wiki/Basis_pursuit):
minimizar la norma L1 de s, sujeto a As = x
donde la norma L1 se calcula como |s_1|+|s_2|+...+|s_L|. Este problema se reduce a una optimización lineal
Otro método popular para encontrar el vector disperso s es el matching pursuit(https://en.wikipedia.org/wiki/Matching_pursuit). La esencia de este método es encontrar la primera función base a_i de una matriz dada A tal que se ajuste al vector de entrada x con el mayor coeficiente s_i en comparación con otras funciones base.Después de restar a_i*s_i del vector de entrada, añadimos la siguiente función base al residuo resultante, y así sucesivamente, hasta alcanzar el error dado. Un ejemplo del método de búsqueda de coincidencias es el siguiente indicador, que inscribe un seno tras otro en el vector de entrada con el menor residuo: https://www.mql5.com/ru/code/130.
Si las funciones baseA(diccionario) no las conocemos de antemano, tenemos que encontrarlas a partir de los datos de entradax utilizando métodos denominados colectivamente aprendizaje de diccionario. Esta es la parte más difícil (y para mí la más interesante) del método de codificación dispersa. En mi conferencia anterior mostré cómo estas funciones pueden, por ejemplo, ser encontradas por la regla de Ogi, que hace que estas funciones sean vectores principales de citas de entrada. Desgraciadamente, este tipo de funciones base no conduce a una descripción disjunta de los datos de entrada (es decir, el vector s no es disperso).
Los métodos existentes de aprendizaje de diccionarios que conducen a transformaciones lineales disjuntas se dividen en
Losmétodos probabilísticos para encontrar funciones base se reducen a maximizar la máxima probabilidad:
maximizar P(x|A) sobre A.
Normalmente se supone que el error de aproximación tiene una distribución gaussiana, lo que nos lleva a resolver el siguiente problema de optimización:
(1)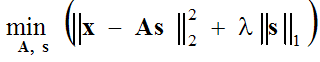 ,
,
que se resuelve en dos pasos: (1-paso de codificación dispersa) con las funciones de base A fijas, la expresión entre paréntesis se minimiza con respecto al vector s, y (2-paso de actualización del diccionario) el vector encontrados se fija y la expresión entre paréntesis se minimiza con respecto a las funciones de base A utilizando el método de descenso de gradiente:
(2)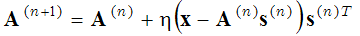
donde (n+1) y (n) en el superíndice denotan los números de iteración. Estos dos pasos (paso de codificación dispersa y paso de aprendizaje del diccionario) se repiten hasta que se alcanza un mínimo local. Este método probabilístico de búsqueda de funciones base se utiliza, por ejemplo, en
Olshausen, B. A., & Field, D. J. (1996). Emergencia de las propiedades del campo receptivo de las células simples mediante el aprendizaje de un código disperso para las imágenes naturales. Nature, 381(6583), 607-609.
Lewicki, M. S., y Sejnowski, T. J. (1999). Aprendizaje de representaciones sobrecompletas. Neural Comput, 12(2), 337-365.
El Método de las Direcciones Óptimas (MOD) utiliza los mismos dos pasos de optimización (paso de codificación dispersa y paso de aprendizaje del diccionario), pero en el segundo paso de optimización (paso de actualización del diccionario) las funciones base se calculan igualando a cero la derivada de la expresión entre paréntesis (1) con respecto a A:
donde obtenemos
(3)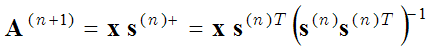 ,
,
donde s+ es una matriz pseudoinversa. Este es un cálculo más preciso de la matriz base que el método de descenso de gradiente (2). El método MOD se describe con más detalle aquí:
K. Engan, S.O. Aase, y J.H. Hakon-Husoy. Método de direcciones óptimas para el diseño de marcos. IEEE International Conference on Acoustics, Speech, and Signal Processing. vol. 5, pp. 2443-2446, 1999.
Calcular las matrices pseudoinversas es engorroso. El método k-SVD evita hacerlo, pero aún no lo he resuelto. Puede leerlo aquí:
M. Aharon, M. Elad, A. Bruckstein. K-SVD: un algoritmo para diseñar diccionarios sobrecompletos para la representación dispersa. IEEE Trans. Signal Processing, 54(11), noviembre de 2006.
Tampoco he descubierto aún los métodos de agrupación y en línea para encontrar el diccionario. Los lectores interesados pueden consultar la siguiente encuesta:
R. Rubinstein, A. M. Bruckstein y M. Elad, "Dictionaries for sparse representation modeling", Proc. of IEEE , 98(6), pp. 1045-1057, junio de 2010.
Aquí hay algunas interesantes conferencias en vídeo sobre este tema:
http://videolectures.net/mlss09us_candes_ocsssrl1m/
http://videolectures.net/mlss09us_sapiro_ldias/
http://videolectures.net/nips09_bach_smm/
http://videolectures.net/icml09_mairal_odlsc/
Eso es todo por ahora. Ampliaré este tema en futuros posts a medida que pueda y que los visitantes de este foro estén interesados.
Nikolai, ya conoces la frase popular: la optimización prematura es la raíz de todos los males.
Es una frase tan común para los desarrolladores para encubrir su inutilidad, que te pueden dar un tirón de orejas por cada vez que la uses.
La frase es fundamentalmente perjudicial y absolutamente errónea, si hablamos de desarrollo de software de calidad con un ciclo de vida largo y orientado directamente a la alta velocidad y las altas cargas.
Lo he comprobado muchas veces en mis muchos años de práctica de la gestión de proyectos.
Es una frase tan común para encubrir las cagadas de los desarrolladores que te pueden dar un tirón de orejas por cada vez que la uses.
Así que hay que tener en cuenta algunas características que aparecerán quién sabe cuándo con quién sabe qué interfaz de antemano porque te da un plus de rendimiento?
He comprobado esto muchas veces en mis años de práctica de gestión de proyectos.