Discussing the article: "Neural networks made easy (Part 45): Training state exploration skills"
How to run tests without using OpenCL?
Because the processor supports OpenCL, but the video card does not and neither test nor optimisation starts....
Because the processor supports OpenCL, but the video card does not and neither test nor optimisation starts....
Good day, Oleg.
This implementation works only with OpenCL. To disable it you need to redesign the whole network algorithm. But if it can be run on a processor, if it supports OpenCL and the corresponding drivers are installed.
Good afternoon, Oleg.
This implementation works only with OpenCL. To disable it, you need to redesign the whole network algorithm. But if it can be run on the processor, if it supports OpenCL and the corresponding drivers are installed.
This is the error I get (see the screenshot). On the screenshot you can see that the video card does not support OpenCL, but the processor is fine. How can I bypass this and run it in a tester or optimiser? What can you advise?

This is the error I get (see screenshot). The screenshot shows that the video card does not support OpenCL, but the processor is fine. How can I bypass this and run it in a tester or optimiser? What can you advise?
The problem is that you are running "tester.ex5" It checks the quality of trained models and you don't have them yet. First you need to run Research.mq5 to create a database of examples. Then StudyModel.mq5, which will train the autoencoder. The actor is trained in StudyActor.mq5 or StudyActor2.mq5 (different reward function. And only then tester.ex5 will work. Note, in the parameters of the latter you need to specify the actor model Act or Act2. Depends on the Expert Advisor used to study Actor.
This is the error I get (see screenshot). The screenshot shows that the video card does not support OpenCL, but everything is in order with the processor. How can I get around this and run it in a tester or optimiser? What can you advise?
You are out of luck buddy. I encounter the same issue with my i5-12400
Apparently some Intel 12th gen and 13th gen doesn't support fp64 calculation.
Intel secretly exclude fp64 from those two gen of processor though fp64 will be back on 14th gen.
The problem is that you run "tester.ex5". It checks the quality of trained models, and you don't have them yet. First you need to run Research.mq5 to create a database of examples. Then StudyModel.mq5, which will train the autoencoder. The actor is trained in StudyActor.mq5 or StudyActor2.mq5 (different reward function. And only then tester.ex5 will work. Note, in the parameters of the latter you need to specify the actor model Act or Act2. Depends on the Expert Advisor used to study Actor.
Started optimising Research.
As a result, it writes the following in the log:
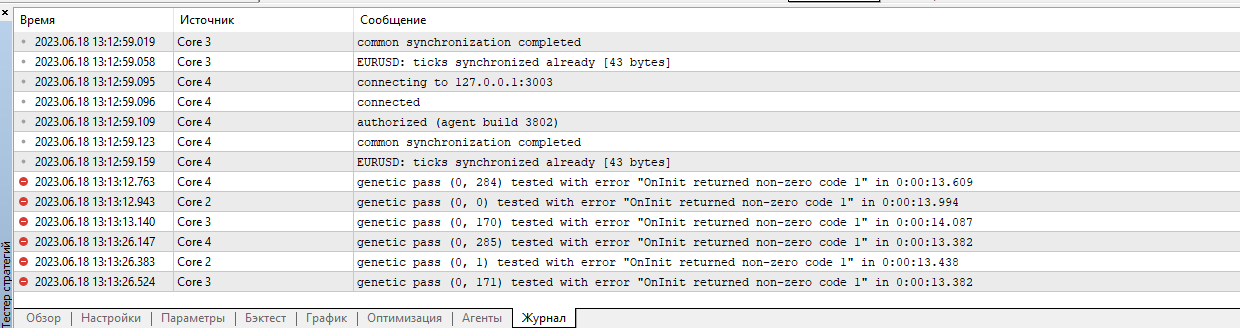
Am I getting something wrong again?
You are out of luck buddy. I encounter the same issue with my i5-12400
Apparently some Intel 12th gen and 13th gen doesn't support fp64 calculation.
Intel secretly exclude fp64 from those two gen of processor though fp64 will be back on 14th gen.
This version don't use fp64. Only fp32. I have tested it at Iris Xe i7-1165

Any messages in the test agent log? At some stages of initialisation interruption the EA displays messages.
I cleared all tester logs and ran Research optimisation for the first 4 months of 2023 on EURUSD H1.
I ran it on real ticks:
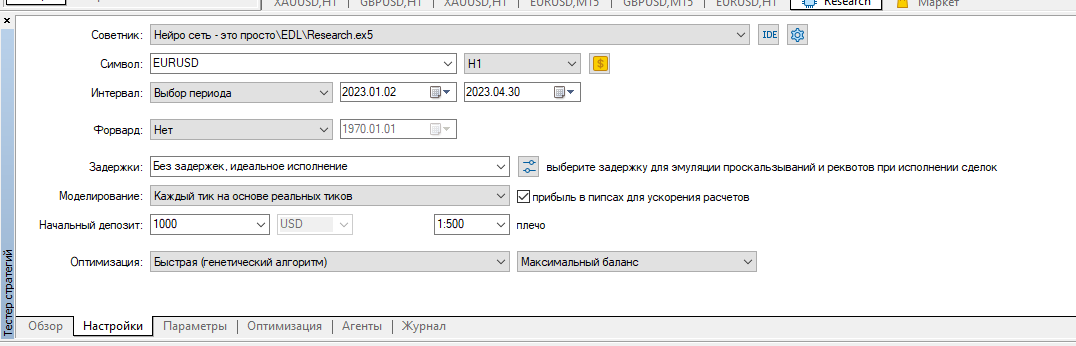
Result: only 4 samples, 2 in plus and 2 in minus:

Maybe I'm doing something wrong, optimising the wrong parameters or something wrong with my terminal? It's not clear... I am trying to repeat your results as in the article...
The errors start at the very beginning.
The set and the result of optimisation, as well as the logs of agents and tester are attached in the Research.zip archive.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Check out the new article: Neural networks made easy (Part 45): Training state exploration skills.
Training useful skills without an explicit reward function is one of the main challenges in hierarchical reinforcement learning. Previously, we already got acquainted with two algorithms for solving this problem. But the question of the completeness of environmental research remains open. This article demonstrates a different approach to skill training, the use of which directly depends on the current state of the system.
The first results were worse than our expectations. Positive results include a fairly uniform distribution of the skills used in the test sample. This is where the positive results of our test end. After a number of iterations of training the auto encoder and the agent, we were still unable to obtain a model capable of generating profit on the training set. Apparently, the problem was the auto encoder's inability to predict states with sufficient accuracy. As a result, the balance curve is far from the desired result.
To test our assumption, an alternative agent training EA "EDL\StudyActor2.mq5" was created. The only difference between the alternative option and the previously considered one is the algorithm for generating the reward. We also used the cycle to predict changes in account status. This time we used the relative balance change indicator as a reward.
The agent trained using the modified reward function showed a fairly flat increase in profitability throughout the testing period.
Author: Dmitriy Gizlyk